

With relational databases, there is power in the tunability and speed of querying normalized relational data. But that speed is not realized without some language learning curve and a good understanding of internals. Query optimizers can be fickle things, and when not coded correctly, a query can easily consume every resource you have.
I wanted to share some of my experiences working with SQL Server and Hibernate in a mixed Java/SQL Server environment. My expertise is in SQL Server, but when Hibernate is interacting with your database, you will find yourself doing a LOT of reading online about the subject.
What is Hibernate
Hibernate is an Object Relational Mapping (ORM) solution for Java. It models relational data tables to Java classes, and Java data types to SQL data types. It obscures the data layer, and if you want, it will handle writing all the queries for you. A Java developer can quickly develop data driven applications without worrying about the underlying data model. In fact, Hibernate can even generate the data model directly from the Java object model layer.
Hibernate is database agnostic. It doesn’t care if you use Oracle, SQL Server, MySQL, or about a dozen other relational databases. I have heard this as an argument in support of using an ORM, but I have rarely known companies to change the data technology, and keep the same old application code. It is usually a “clean house” situation. Keep this in mind for later.
Here is an example. From within the application, the developer will write some code to get the user object for a userID. They might write something like this:
Query query = session.createQuery("from User where userID = :userID ");
query.setParameter("userID", "1234");
List list = query.list();Hibernate will issue this query to the database:
(@P0 INT)
SELECT applicatio1_.user_identifier AS user_ide1_8_0_
,applicatio1_.alternate_email_identifier AS alternat5_8_0_
,applicatio1_.communication_preference_code AS communi10_8_0_
,applicatio1_.contact_phone_number AS contact11_8_0_
,applicatio1_.created_by AS created12_8_0_
,applicatio1_.created_date AS created13_8_0_
,applicatio1_.user_creation_type_code AS user_cr56_8_0_
,applicatio1_.user_display_name AS user_di57_8_0_
,applicatio1_.user_email_identifier AS user_em58_8_0_
,applicatio1_.user_first_name AS user_fi59_8_0_
,applicatio1_.user_group_code AS user_gr69_8_0_
,applicatio1_.user_is_deleted_indicator AS user_is60_8_0_
,applicatio1_.user_last_name AS user_la61_8_0_
,applicatio1_.user_middle_name AS user_mi62_8_0_
,applicatio1_.security_question_identifier AS securit70_8_0_
,applicatio1_.user_source_reference_identifier AS user_so63_8_0_
,applicatio1_.user_status_code AS user_st64_8_0_
,applicatio1_.user_type_code AS user_ty65_8_0_
FROM AppUser.application_user applicatio1_
WHERE applicatio1_.user_identifier = @P0In doing a lot of reading online, you can find some good resources for Hibernate. I will list a few, but my focus will be on actual scenarios that I have experience with.
First, some best practices:
- Do not use built-in connection pooling. It is not intended for production use.
- Do not use default caching. It too is not intended for production use.
- For complicated queries, use inline SQL or stored procedures. Hibernate is not made to cover every scenario.
Here are some issues to be aware of:
Scans
It seems that because an ORM obfuscates the database altogether; developers almost forget that there is a database underneath the application. It is easy to grab data from an object in any way that you want it. Developers may use predicates that are not indexed. Adding nonindexed columns as your predicates can cause table scans, locking, blocking, and all kinds of nasty stuff.
I worked at a company that had about 4 million rows in the users table. That is not a very high number. Some code was checked in that used a non-indexed column as a predicate in the user table, along with a join to the product table. This caused a scan of the user table, AND the scan was executed 8 times per page load. This query was reading 32 million rows of data per page load. Typical DBAs would think of such things, but Java developers will see that they invoked the user and product objects with a “where columnA =” and the result set was about 20 rows. No harm done. But the app is a little slow in QA.
Once the code was in production, it did not take very long for a small number of concurrent page loads to cause lock timeouts. The result is that the DBA now must react with an index after the damage is done. There is a habit of creating too many indexes when the business is screaming at the DBA to get the database up and running again because we are losing sales. I saw a table with 15 indexes because of this (not the worst I have seen, but not good). The table was too wide, and the application was querying it so many ways.
The query below was created when the application team used a non-indexed column as the predicate for the query.
select distinct applicatio0_.user_identifier as col_0_0_,
applicatio0_.user_first_name as col_1_0_, applicatio0_.user_last_name as col_2_0_, applicatio0_.user_status_code as col_3_0_, applicatio0_.user_type_code as col_4_0_
from App.application_user applicatio0_
where applicatio0_.non_indexed_column
in (select commission1_.non_indexed_columnfrom App.table_a commission1_) order by applicatio0_.user_last_name ascThe plan created by the query above with a non-indexed column as a predicate.
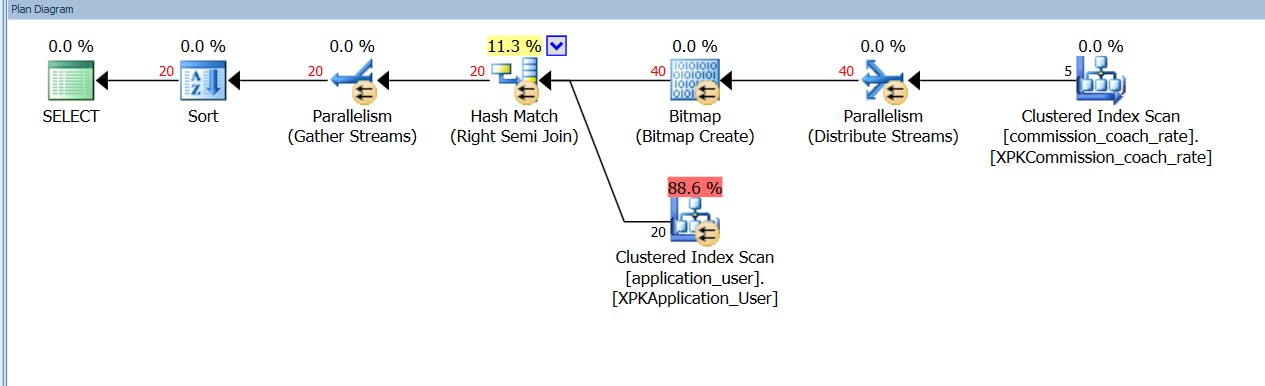
To remedy situations like this, a DBA or DBE should be involved BEFORE the developement is begun. Just because the database is obscured behind the ORM layer, doesn’t mean that you can omit the data team from the development cycle. Have a set process that involves both the app teams and the data teams. On the surface, it seems like a speed bump. But, in my experience it is much more efficient to identify potential issues as early in the process as possible.
Key Lookup
Hibernate typically loads all the columns from the table. If indexes are not created to cover all the columns in the table, the query will cause a key lookup. The nonclustered index does not contain all the columns asked for by the query, so the Query Optimizer uses a key lookup to get the additional columns. Key lookups can cause deadlocks and a few other nasty things.
The system I inherited was having such issues with deadlocks that it was decided to put the database into snapshot transaction isolation level. This system had high wait stats from blocking and temp DB contention from snapshot isolation.
The remedy for the key lookups is to try to understanding just how Hibernate reads the data. Architects can better model, and DBAs can better index the data. But, creating a cover index with all the columns in the underlying table is essentially the same as creating an additional table. As stated above, this requires close collaboration between developers and DBAs. It also requires DBAs in this environment to educate themselves on Hibernate. Do you see a running theme?
Lots of cached plans to choose from, and most of them bad.
When passing arrays as predicates to a Hibernate query, SQL Server uses a hash of literal string to cache the plan. That means that in some cases you will have a newly generated, and cached plan for every different set of predicate values. This is hard to troubleshoot because if you take the same query and run it in SSMS, it is easily cached. Java lends itself to using arrays as predicates rather than joins. The query uses a list with an “in” or “not in” clause.
The developer passes in an array of IDs.
Criteria customerCriteria = session.createCriteria(customerTO.class);
customerCriteria.add(Restrictions.in("userID", userIDLists)); //userIDLists is an Arraylist contains 250 Strings
customerCriteria.setProjection(Projections.projectionList().add(Projections.property("customerId")));
List<Long> customerIds = new ArrayList<Long>();
List<Long> results = (ArrayList<Long>) customerCriteria.list();
if (results != null && results.size() > 0) {
customerIds.addAll(results);
}
return customerIds;The query passed to SQL Server is:
(Hibernate passes parameters as "?", and the array has 250 values)
select this_.customer_Id as y0_ from customer_table this_ where this_.User_id in (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?,?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?,?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
SQL Server will cache a new plan for executions with different values, or even worse pick one of the existing plans that may be bad.
If you inherit a system that has code like this, you are probably better off flushing the plan cache daily until the offending code can be rewritten. The performance benefit that you typically gain from reusing plans is not realized with queries like this, even though they are prepared statements. Create stored procedures thst insert the array result sets into temp tables or table variables that can be joined to the additional tables for the finsl result. Doing this will allow the plans to be reused.
Simplify Your Data Model
Remember that Hibernate will generate the underlying SQL queries for the developers. Keeping your data model exceedingly simple is crucial. Keep in mind how your data will be queried by an ORM. You want those queries to use efficient and simple plans. So, keep your data model closely aligned to the object model.
Typically when I create a data model, I will go through exercises with business in defining all the entities, the relationships between those entities, and how the data will be queried. With Hibernate, I find myself weighting the latter very heavily. I am almost trying to think about the application first and data second. Simpler is always better here.
Conclusion
ORMs are an extremely powerful tool. But, like any other tool, you must use them correctly. As a DBA, you must try to understand how your data is being queried. As a developer, you must trust in the expertise of your data team. With a good collaborative environment, and developers that a deep understanding of the internals of the tools being used, much can be accomplished in a very short time. Any developer should strive to understand what happens when their code is executed.
Here are my tips, broken down into two sections.
For Developers
- Remember that there is still a database under the covers.
- Understand that databases are eco systems, and one bad query can affect the rest of the application.
- Work with the DBAs and collaborate on features.
- When used correctly, and ORM can make life much easier.
- When abused, and ORM will cost time and productivity.
For DBAs
- Work with the developer to ensure that the data is being used responsibly.
- Read as much online as you can. Others have had the same issues you are having.
- Run targeted traces to see what Hibernate is doing.
Hue Hoang, my principal DBA was very helpful in gathering examples for me. Thank you!
