

Introduction
In this article, I would like to explore the FILLFACTOR (FF) option, which is sometimes overlooked and just left set to the default engine setting.
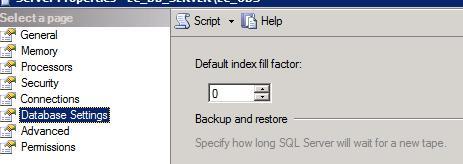
The Fill Factor specifies how much the leaf pages of an index get filled up, while the Pad Index specifies if the Intermediate Index pages will use the same fill factor value as specified for the Index. By default, the Index fill factor is retrieved from the Instance Database settings as displayed below. The default value is 0 which means that the SQL Server engine will totally fill up all the index page with data, same as setting it to 100%. The image below shows where the default setting is changed.
Setting and finding the ideal FF for your database is not so easy and straightforward. It's not a case of setting magical numbers for your database to work in all scenarios all the time, but it requires thought and testing to ensure that the values you've come up with will work satisfactorily. A high FF will ensure more rows are packed on each data page but there is a big chance that page splits will increase, especially in a transactional system. This is something that is not desirable since the less page splits the better for performance. On the other hand, a low FF will store less rows per data page, which will decrease page splits but will require more resources, such as IO, to read the same amount of data since the data is spread across more data pages.
Apart from setting a FF for the whole database, each index can individually be assigned a specific FF setting. This is applied when any of these occur:
- On Index Rebuild
- On Index Reorganize
- On Index Creation.
The Fill Factor for the index is computed and only applied during one of the operations listed above. During normal operations, i.e. DML statements being fired against the database, the fill factor setting is ignored and the engine will try to fill up the index pages as full as it can. When eventually a page split occurs, the engine will generally move half the original page to a new page, irrespective of the FF setting. More details can be found here.
Test Scenarios
In the attached script, I'm creating two one-column tables named _TEST1 and _TEST2 respectively. (Please refer to the next table for an illustration).
On table _TEST1, an index INDEX1 is created on column col_1 with a 100% fill factor.
On table _TEST2, an index INDEX2 is created on column col_2 with a 50% fill factor.
Both tables contain 8 records.
| Table Name | Index Name | Column Name | FILL FACTOR |
|---|---|---|---|
| _TEST1 | INDEX1 (CLUSTERED) | Col_1 char(900) | 100% |
| _TEST2 | INDEX2 (CLUSTERED) | Col_2 char(900) | 50% |
Running the script below, we can easily verify the data distribution.
USE tempdb
GO SELECT CAST(OBJECT_NAME(S.object_id, DB_ID('tempdb')) AS VARCHAR(20)) AS 'Table Name',
I.name As IndexName,
CAST(index_type_desc AS VARCHAR(20)) AS 'Index Type',
CASE WHEN I.fill_factor in (0,100) THEN
100
ELSE
I.fill_factor
END As fill_factor,
CASE WHEN I.is_padded = 1 THEN
'On'
ELSE
'Off'
END As 'Pad Index',
avg_fragmentation_in_percent As 'Avg % Fragmentation',
record_count As 'RecordCount',
page_count As 'Pages Allocated',
avg_page_space_used_in_percent As 'Avg % Page Space Used',
avg_record_size_in_bytes,
Case When Index_level = 0 Then
'Leaf'
Else
'Intermediate'
End As 'Index Level'
FROM sys.dm_db_index_physical_stats (DB_ID('tempdb'),OBJECT_ID('_TEST'),NULL,NULL,'DETAILED' ) S
INNER JOIN sys.indexes I On (I.object_id = S.object_id And I.index_id = S.index_id)
and below is the output...

Table: _TEST1. INDEX1
For this table, the FF was specified as 100% and therefore the engine filled up the whole data page (8060 bytes available). The 8 records present in the table all fit in one leaf page (as displayed above). If we do some math:
Average Size of record = 914bytes
Records which will fit in page = 8060/914 = 8.818 rounded down to 8 records since a record can't be split across multiple pages.
Avg % Page Space used = 90.511. The engine tried to use the full data page (FF = 100%). however, the remaining 10% could not be utilized because adding an extra record will not fit in the remaining space which is (8060 - (8 x 914)) = 748 bytes!
Table: _TEST2. INDEX2
For this table, the FF was specified as 50% and therefore the engine filled up half the data pages (4030 bytes used per page). The 8 records present in the table didn't fit in one page and in this case, two leaf and one intermediate pages were needed: the leaf pages to store the records while the intermediate page to store the pointers to the leaf data pages.
Average Size of record = 914bytes
Effective free space per page = 8060/2 (50% FF) = 4030bytes
Records which will fit in page = 4030/914 = 4.409 i.e. 4 records
No of pages needed to store 8 records = Total number of records / Records stored per page = 8/4 = 2
Avg % Page Space used = 45.24. The engine tried to use 50% of the data page, however the remaining 5% could not be utilized because adding an extra record could not fit in the remaining space which is (4030 - (4x 914)) = 374 bytes remaining.
Select Performance
Now lets analyse the SELECT performance for both tables/indexes. The SET STATISTICS IO option is enabled which will return IO information, needed to analyse the performance difference.
-- Select Performance...
Print 'Running First Statement... using INDEX 1'
SET STATISTICS IO ON;
select col_1 From _TEST1 Where col_1 = 'Test Data - Column 1'
Print ''
Print 'Running Second Statement... using INDEX 2'
select col_2 From _TEST2 Where col_2 = 'Test Data - Column 2'
SET STATISTICS IO OFF;
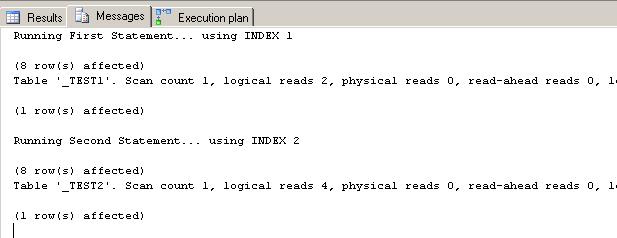
Running the above scripts will generate the statistics shown below. As expected, since INDEX1 (100% FF) is more compact, only 2 logical reads were needed, while 4 logical reads were needed to select the same amount of data but from INDEX2 (50% FF)
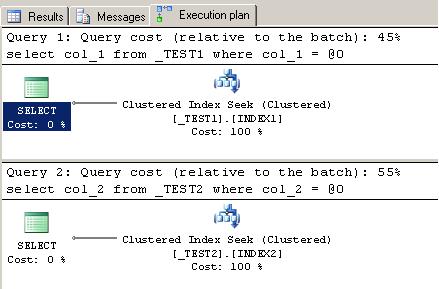
If we look at the execution plans, we can verify that the first SELECT used INDEX1, while the second SELECT used INDEX2 to read the data from the index data pages.
Page Splits
Now, I've added a new row to both tables.
SET STATISTICS IO ON;
INSERT INTO _TEST1 (Col_1)
Values ('A Test Data - Column 1')
INSERT INTO _TEST2 (Col_2)
Values ('A Test Data - Column 2')
SET STATISTICS IO OFF;
From the above observations, a new record will not fit into the same data page for table _TEST1 - INDEX1 and therefore the engine will be forced to introduce an intermediate page and start a new leaf page.
On the other hand, since INDEX2 on table _TEST2 was created with a FF of 50%, there is free space in both leaf data pages to accommodate the new record.
And here is what the distribution will look like after inserting the records and running the SQL Script for the sys.dm_db_Index_physical_stats DMV.

Taking at look at the STATISTICS IO, it is clearly evident that more logical reads were introduced to update INDEX1. The reason being that since a new data page was needed to accommodate the new row, the engine split the data from the existing page and on creating a new data page, moved half the rows to this new page, in fact that's why the increase in the number of logical reads.
On the other hand, inserts to INDEX2, resulted in fewer logical reads because there was free space on both existing data pages and therefore the engine just updated the leaf and intermediate page with the new entry.

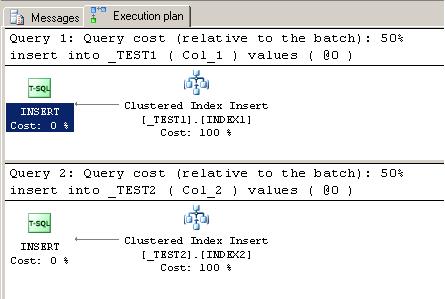
and below are the execution plans for both SELECTS.
Although out of scope of this article, I would like to draw your attention to the discrepancy between the above STATISTICS IO and the execution plan below. Although three times more logical reads are needed for updating INDEX1, this was undetected by the optimizer, since both operations have been costed exactly the same!
Running a couple more INSERT statements will not incur additional logical reads for both Indexes, until the existing pages fill up and new data pages are needed.
Conclusion
From the above results, it is clear that a high FF will improve SELECT but will penalize DML due to more page splits, while a low FF will improve DML statements but will penalize SELECT statements.
Having read all this, DO NOT run to your production server and quickly modify the FF of your indexes of your database if you're having problems with DML statements performance. There is never a 'one way work all solution' to all problems.However, from the tests performed, it's clear that by carefully monitoring the Index fragmentation of heavily updated tables, the FF option will help in reducing page splits and index fragmentation, thus speeding up DML statements. The best value is the one which will find the right balance between SELECTS and DML operations.


