

A common question that arises in SQL Server collation discussions is whether a binary collation (BIN2) is functionally equivalent to a case-sensitive collation that is sensitive to all aspects of sensitivity (for instance, Latin1_General_100_CS_AS). In simpler terms, if we opt for a collation that is case-sensitive, accent-sensitive, and sensitive to all other aspects, would it be the same as a binary collation when comparing the string values?
Sometimes, individuals who require case-sensitive collation opt for BIN2 collation, anticipating improved performance without altering functionality. However, they often wonder if case-sensitive and binary collations will have identical behavior.
The answer is a definitive NO.
While a binary collation is sensitive to all rules (casing, accents, etc.), it is more restrictive than the most restrictive non-binary collation. The primary differences lie in how they handle string data:
- Binary collation: Treats the string as raw binary values (VARBINARY) and compares the codepoints/bytes that physically encode the strings (with a few subtle exceptions like trailing blanks).
- Other collations (Windows/SQL): Adhere to the Unicode standard when comparing strings, and different binary representations might still represent the same characters.
Non-binary collations must comply with Unicode rules, and this is the reason why I will call them Unicode collations in the rest of the article.
Unicode collations must honor some special Unicode rules, for example:
- Combining Characters: Some characters might be represented as a combination of successive independent characters but are still treated as a single character.
- Special formatting characters: Some characters might be visible in words but are ignored in comparison according to Unicode rules.
In this article, we will see how binary and Uncode colations handle these types of characters. This will reveal the difference between binary collations and the Unicode colations that are sensitive to everything.
What are the combining characters?
In Unicode, the combining characters are intended to modify other characters. The main character and the combining character(s) together form a "composite character". They are used to add diacritical marks, such as accents, to the base character.
Consider the character "ä" as an example. This character can be represented in two ways:
- As a single Unicode character "ä" (U+E400).
- As a combination of the character "a" (U+0061) followed by the combining diacritic mark "¨" (U+0308).
The binary representation of these two forms differs:
- The single character "ä" is represented as 0xE400 in UTF-16 or 0xE4 in UTF-8.
- The composite character "ä" is represented as a sequence of two characters 0x61000803.
Despite the difference in binary values, the Unicode standard considers them to be the same character.
How collations in SQL handle combining characters?
In SQL Server, when you compare these two characters using a binary collation (BIN2), they are considered different because the comparison is based on the binary values 0xE400 and 0x61000803. However, if you compare them using a Unicode collation, even with all sensitivity flags enabled (for example, both case-sensitive and accent-sensitive), they are considered the same. This is because non-binary collations in SQL Server adhere to the Unicode standard for character comparison, which treats the two forms of "ä" as the same character. There is no collation flag in the collation names that will prevent some Unicode collation from applying this rule.
Let's illustrate this with the following example:
WITH chars AS (SELECT NCHAR(0xE4) as str1, N'a' + NCHAR(0x308) AS str2) SELECT str1, str2, CAST(str1 AS VARBINARY(10)) str1_binary, CAST(str2 AS VARBINARY(10)) str2_binary, IIF(str1 COLLATE Latin1_General_100_CI_AS_KS_WS_SC_UTF8 = str2, 'true', 'false') AS [CI AS comparison], IIF(str1 COLLATE Latin1_General_100_CS_AS_KS_WS_SC_UTF8 = str2, 'true', 'false') AS [CS AS comparison], IIF(str1 COLLATE Latin1_General_100_CI_AI_KS_WS_SC_UTF8 = str2, 'true', 'false') AS [CI AI comparison], IIF(str1 COLLATE Latin1_General_100_CS_AI_KS_WS_SC_UTF8 = str2, 'true', 'false') AS [CS AI comparison], IIF(str1 COLLATE Latin1_General_100_BIN2_UTF8 = str2, 'true', 'false') AS [BIN comparison] FROM chars
If we execute this script, we will see that the two different representations of the character "ä" are treated as different characters only when they are compared using the binary comparison, but considered as the same if we use any other collation regardless of CI/CS and AI/AS flags.
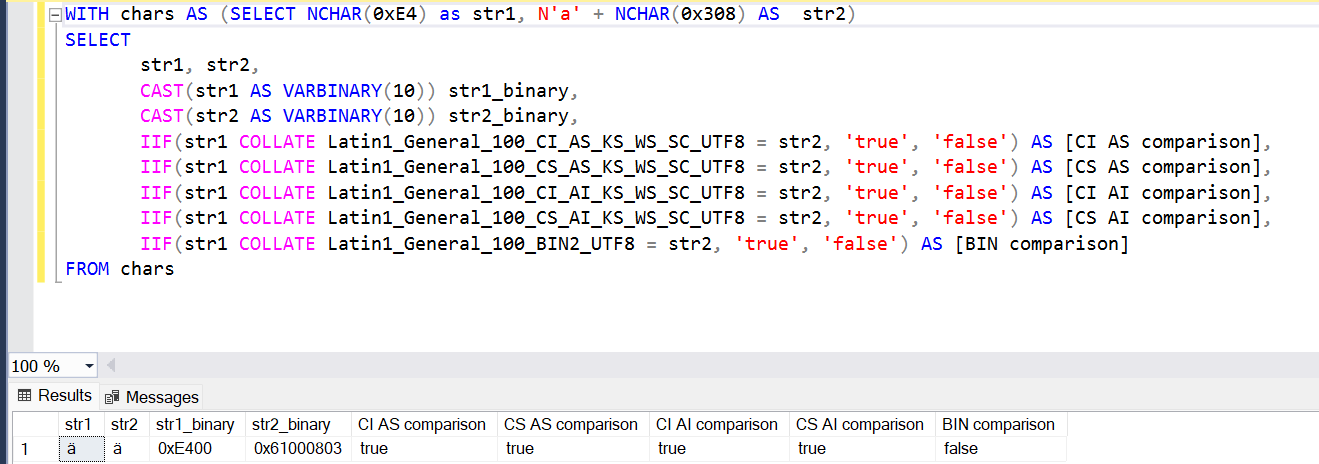
The values in str1 and str2 columns are the same because they are representations of the same character. However, the comparison is different depending on Unicode or BIN2 collations.
Special formatting characters
Some characters like Soft Hyphen (U+00AD) character that have special display and comparison rules. This character should remains invisible unless it's placed at the end of a line, where it defined how the word is broken in the new line.
For instance, the words "cooperate" and "co-operate" (with a soft hyphen) are regarded as the same word, even though they may visually appear different.
How collations in SQL handle formatting characters?
In SQL Server, when you compare two strings using a binary collation (BIN2), the comparison is based on the binary values of the characters. Therefore, "cooperate" and "co-operate" (with a soft hyphen) would be considered different because their binary representations differ.
However, if you compare them using a Unicode collation, even with all sensitivity flags enabled (for example, both case-sensitive and accent-sensitive), they will be considered the same. This is because Unicode collations in SQL Server adhere to the Unicode standard for character comparison, which treats the two forms of "cooperate" (with or without a soft hyphen) as the same word. Let's modify the script above to compare two words with a soft hyphen:
WITH chars AS (SELECT N'cooperate' as str1, N'co' + NCHAR(0xAD) + 'operate' AS str2) SELECT str1, str2, CAST(str1 AS VARBINARY(20)) str1_binary, CAST(str2 AS VARBINARY(20)) str2_binary, IIF(str1 COLLATE Latin1_General_100_CI_AS_KS_WS_SC_UTF8 = str2, 'true', 'false') AS [CI AS comparison], IIF(str1 COLLATE Latin1_General_100_CS_AS_KS_WS_SC_UTF8 = str2, 'true', 'false') AS [CS AS comparison], IIF(str1 COLLATE Latin1_General_100_CI_AI_KS_WS_SC_UTF8 = str2, 'true', 'false') AS [CI AI comparison], IIF(str1 COLLATE Latin1_General_100_CS_AI_KS_WS_SC_UTF8 = str2, 'true', 'false') AS [CS AI comparison], IIF(str1 COLLATE Latin1_General_100_BIN2_UTF8 = str2, 'true', 'false') AS [BIN comparison] FROM chars
Although their binary storage is different, and they visually look different, any Unicode collation will treat them as same characters. This demonstrates how SQL Server's collation system is designed to handle the complexities of text processing in a Unicode-compliant manner.

If you look at the str2_binary column you will see an additional byte 0xAD00 placed between two 0x6F00 characters. These binary values are diferent; however, the Unicode collation treat them as the same string values.
Note the difference between “Cooperate” and “Co-operate” that is written with dash (0x2010) instead of the soft hyphen. In English language both forms are correct, but if you use the dash instead of soft hyphen, SQL will treat them as different words even in Unicode collations, because the dash (0x2010) is not treated as invisible character although visually looks like soft hyphen.
Conclusion
In this article, we've delved into the subtle differences between binary and Unicode collations in SQL Server. We've discovered that even the most sensitive Unicode collation, with case sensitivity enabled, does not compare strings in the same way as a binary (BIN2) collation.
It's a common misconception that choosing a BIN2 collation for case-sensitive comparison will yield the same results as a case-sensitive Unicode collation, but with better performance. While it's true that BIN2 collation may offer faster performance because it compares strings as byte arrays, it does not produce the same results as a true case-sensitive collation. This is because BIN2 collation ignores Unicode rules.
Understanding the difference between a Unicode collation that is sensitive to everything and a true binary collation is crucial when making decisions about collation settings. With BIN2, you may gain performance, but you will lose some Unicode behavior. It's important to be aware of this trade-off and to make an informed decision about whether you are intentionally accepting it.
Remember, the choice of collation can have a significant impact on the behavior of your SQL Server applications. Choose wisely, and always test thoroughly to ensure that your chosen collation meets your application's requirements and expectations.
Happy querying!
