

A little while ago I wrote a piece on why a table does not so much have a clustered index as a table is a clustered index (see the note at the end). Here's a follow up with some SQL code that further strengthens that assertion, at least the way it is implemented in SQL Server.
Let's start by creating a very simple table and inserting one record into it:
create table dbo.test (id int) insert into dbo.test (id) select 1
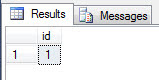
Note that this table is currently a heap, it does not have any indexes of any type. Verify that the table has one record, as shown in the image below:
select * from dbo.test
Here is the execution plan for this select statement:
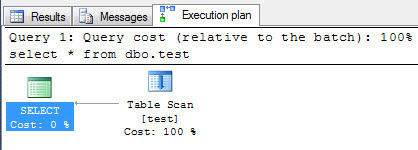
As expected, we have a table scan on the heap. Now let's add a non-clustered index to this table on the id column:
create nonclustered index NCIndex_test on dbo.test (id)
Run the select statement again, and you will see the same result again, as expected. The execution plan, of course, is different. Now the query uses the non-clustered index instead of the table scan (I won't get into seeks vs scans here, different conversation).
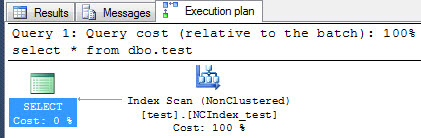
Now let's try disabling (not dropping) the non-clustered index:
Once again, run the select statement. We now see the same result and execution plan as in our first select statement above. The index is ignored, and the table is treated like a heap, resulting in a table scan. Again, so far all of this is as expected.
Now, let's repeat the above exercise with a clustered index. To keep everything else the same between the two exercises, I will drop and recreate the table.
drop table dbo.test create table dbo.test (id int) insert into dbo.test (id) select 1
Now, running our select will again show us the table scan:
select * from dbo.test
Let us now create the clustered index:
create clustered index CIndex_test on dbo.test (id)
Running our select statement again, here's what our execution plan looks like with the clustered index:
select * from dbo.test
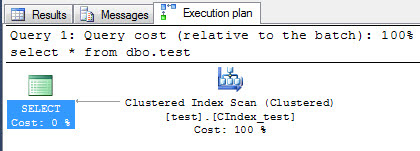
Now let's disable (not drop) the clustered index:
alter index CIndex_test on dbo.test disable
Now if you run the select statement, what do you expect to see? I would have expected to see the table treated as a heap, and a table scan in the execution plan. It seems reasonable to assume that clustered table minus clustered index equals heap, right?
select * from dbo.test

Apparently, not so. Disabling the non-clustered index causes the query to treat the table like a heap, but disabling the clustered index does not have the same effect. Disabling the clustered index disables the table itself.
Thus, when you add a clustered index to a table, the table becomes the clustered index*. A table does not so much have a clustered index as a table is a clustered index.
Note: There is much more to a clustered index, including nodes, leaves, a root, a b-tree structure etc. This is a simplification to help illustrate the point. As an aside, if you drop the clustered index (drop index CIndex_test on dbo.test), the table goes back to being a heap and returns results from the select statement. Here is what Books Online/MSDN has to say on the subject: "Disabling an index prevents user access to the index, and for clustered indexes to the underlying table data... Disabling a clustered index on a table prevents access to the data; the data still remains in the table, but is unavailable for data manipulation language (DML) operations until the index is dropped or rebuilt."


