

Newcomers to T-SQL often come to online forums asking how to "best" do something in T-SQL. The answer they often receive is "It depends." The phrase has become almost cliché. T-shirts are printed with "It Depends" on the front.
Frustrated T-SQL novices want answers they can rely on with assurance, and may find "It depends." to be an unsatisfactory answer. "It depends" may be the answer given for questions regarding configuration options, backups, or any of a number of topics. This article is intended to demonstrate to the new T-SQL developer why often it is the only honest answer in the context of T-SQL coding .
While the word "best" can include such considerations as readability and maintainability of code, this article focuses only on efficiency of execution. Perhaps the most important point to remember is that the person writing a T-SQL query is not the only player in the quest for performance. Efficient queries are the product of a successful collaboration between the database designer, the developer, and the optimizer.
There are often a number of different ways to produce a desired result, and the optimizer is responsible for examining the query and determining the most efficient execution plan to deliver it. Each database server keeps a set of internal tables containing statistics about the data in tables which inform the optimizer with respect to the volume of data involved, the presence of any useful indexes, the distribution of data within those indexes, the potential for parallel operations, and the estimated effort involved in employing a given operation. As any of these variables change, the optimizer may determine that a different execution plan will be more efficient.
The person writing a query has limited control over this process, since there are multiple ways to ask for what is essentially the same result set. However the key point is that, due to changes in the number of rows or the creation or modification of indexes, one execution plan will not always be superior to another. This phenomenon will be demonstrated by testing three different coding techniques to solve a common database problem, which is to display detailed information for only the first row of a group.
Retrieving Detail of Last Sale(s) Of All Products
The three techniques were written to run against a sales detail table with the following schema. A tiny sample of data follows the CREATE TABLE code.
CREATE TABLE [dbo].[SalesDetail](
[ID] [int] IDENTITY(1,1) NOT NULL,
[Product] [int] NULL,
[SaleQuantity] [int] NULL,
[SalePrice] [numeric](6, 2) NULL,
[SaleDate] [datetime] NULL,
[SaleComments] [varchar](110) NULL,
CONSTRAINT [PK_SalesDetail table] PRIMARY KEY CLUSTERED
(
[ID] ASC
)
)
Retrieving Detail of Last Sale(s) Of All Products
The three techniques were written to run against a sales detail table with the following schema. A tiny sample of data follows the CREATE TABLE code.
CREATE TABLE [dbo].[SalesDetail](
[ID] [int] IDENTITY(1,1) NOT NULL,
[Product] [int] NULL,
[SaleQuantity] [int] NULL,
[SalePrice] [numeric](6, 2) NULL,
[SaleDate] [datetime] NULL,
[SaleComments] [varchar](110) NULL,
CONSTRAINT [PK_SalesDetail table] PRIMARY KEY CLUSTERED
(
[ID] ASC
)
)
| ID | Product | SaleQuantity | SalePrice | SaleDate | SaleComments |
| 1 | 65 | 83 | 51.81 | 2008-08-04 23:01:05.757 | ID 1, Product 65 etc etc etc |
| 2 | 90 | 89 | 82.06 | 2007-08-28 23:45:57.833 | ID 2, Product 90 etc etc etc |
| 3 | 86 | 102 | 8.77 | 2007-08-01 23:52:24.370 | ID 3, Product 86 etc etc etc |
| 4 | 26 | 99 | 50.55 | 2009-04-23 22:33:11.060 | ID 4, Product 26 etc etc etc |
In the SalesDetail table, the [ID] column is an identity column, but it bears no relationship to the timestamp stored in the [SaleDate] column. This means that although the [ID] of one row is greater than another, it does not mean the [SaleDate] will be greater. One hundred (100) different products are represented in the SalesDetail table. The problem is to retrieve only the detail of the row containing the latest sale data for each of these products.
There are a number of ways to approach this problem. For purposes of this article, we may assume that there will not be more than one order having the exact same date/time stamp and, by definition, the latest sales date is the maximum [SaleDate] for each product. So, an obvious way to solve this problem is to first determine the maximum sales date for each product, then use a JOIN to find the rows which have [SaleDate] equal to the maximum sale date for those products. The following example illustrates this approach using a CTE to produce a derived table with the max SaleDate for each product.
------------------------------------------------------------
-- Join Detail to MAX([SaleDate])
------------------------------------------------------------
;with cte as ( select product, max(SaleDate) as LastDate
from dbo.SalesDetail
group by product
)
select s.*
from dbo.SalesDetail s
join cte c on c.product = s.product
and s.SaleDate = c.lastDate
Another approach is to view the maximum [SaleDate] as the first row of a result set sorted in descending order. The second example gets a list of all the products, then for each product retrieves only the top row sorted by [Product] and by [SaleDate] descending within each product.
------------------------------------------------------------
-- select top 1 for each product by SaleDate desc
------------------------------------------------------------
;with cte as (select distinct product
from dbo.SalesDetail )
select ca.*
from cte c
cross apply ( select top(1)*
from dbo.SalesDetail s
where s.product = c.product
order by SaleDate desc
) ca
The final, and perhaps simplest, technique uses the ROW_NUMBER() function to assign a sequence ID (seqID) to all rows, again sorting by [Product] and then [SalesDate]. It then selects only those rows having [seqID]= 1.
--------------------------------------------------------------------
-- use ROW_NUMBER() function to assign sequence IDs to rows
--------------------------------------------------------------------
;with cte as ( select *,
row_number()
over (partition by product
order by SaleDate desc) as seqID
from dbo.SalesDetail
)
select *
from cte
where seqID = 1
Please note that other approaches are possible within SQL. Testing was limited to these examples only because the purpose of this article is to illustrate the efficiency of different query plans at different volumes, not to exhaustively cover all techniques for solving a given problem.
Testing environment
Before reviewing the results of the tests run against of the above techniques, some comments are in order about general testing principles. First, wherever possible, testing should be done in a controlled environment, with all variations being tested under identical conditions. Results can be skewed by other jobs running concurrently so a dedicated system is preferable. Also, major slowdowns occur due to initial compilation of the execution plan and due to the physical I/O necessary to load pages into memory from disk, so be aware that the first run of a new query or stored procedure may be far slower than subsequent runs, and should not be included in your results.
In addition, testing should focus on the amount of work SQL takes to accomplish its task without clouding the picture with issues such as network traffic. For this reason, it’s a good testing habit to write test results to a temporary table rather than send all results to a screen. More advanced users may choose to block output altogether, to SET STATISTICS TIME ON, and/or to SET STATISTICS IO ON to get additional information, but discussion of those topics is at a slightly higher level than the focus of this article. Certainly testing strategy is worthy of an article or two all by itself. That said, let’s review the testing environment.
Comparisons were run on a laptop with the following configuration:
- CPU: 1.83ghz, 2GB of ram.
- OS: Windows XP Professional Version 2, Service Pack 3.
- SQL: Microsoft SQL Server 2005 - 9.00.3068.00 (Intel X86) Express Edition
Use of the laptop provided a controlled environment in which other development or testing work did not affect the test runs. While it did not provide an opportunity for the optimizer to use parallelism in processing, it ensured that each query had the dedicated resources of the entire system while running. Non-essential applications and processes were shut down or otherwise disabled to prevent contention for resources.
For simplicity’s sake, each of the three examples used only the single SalesDetail table. All three techniques were tested at varying volumes. To be sure that each version was tested for the same number of rows, the three different queries were combined into a single job, in which each query begins by reading a variable number of rows from the SalesDetail table. Result sets from each query technique were written to temporary tables and a simple timing made of the number of milliseconds each query took to execute. The query times posted below represent the average over fifty(50) loops through each technique and number of rows.
------------------------------------------------------------
-- Testing All Three Techniques
------------------------------------------------------------
DECLARE @results table (Technique varchar(20),RowsCount int, Millisecs int)
DECLARE @timer datetime
DECLARE @rows int
DECLARE @loop int
SET @rows = 1000 -- will be incremented X10 up to a million
WHILE @rows <= 1000000
BEGIN -- OUTER LOOP based on number of rows
SET @loop = 1
WHILE @loop <= 50 -- INNER LOOP based on count to 10
BEGIN
------------------------------------------------------------
-- Join Detail to MAX([SaleDate])
------------------------------------------------------------
SET @timer =getdate()
;WITH cte1 AS (SELECT TOP(@rows) * FROM dbo.SalesDetail)
,cte2 AS ( SELECT product, max(SaleDate)AS LastDate
FROM cte1
group by product
)
SELECT s.*
INTO #results1
FROM dbo.SalesDetail s
join cte2 c on c.product = s.product and s.SaleDate = c.lastDate
INSERT INTO @results
SELECT 'Match MAX()', @rows, datediff(ms,@timer,getdate())
------------------------------------------------------------
-- SELECT TOP 1 for each product by SaleDate desc
------------------------------------------------------------
SET @timer =getdate()
;WITH cte1 AS(SELECT TOP(@rows) * FROM dbo.SalesDetail)
,cte2 AS (SELECT distinct product FROM cte1 )
SELECT ca.*
INTO #results2
FROM cte2 c
cross apply (
SELECT TOP (1) *
FROM dbo.SalesDetail s
WHERE s.product = c.product
ORDER BY SaleDate desc
) ca
INSERT INTO @results
SELECT 'Top (1)', @rows, datediff(ms,@timer,getdate())
--------------------------------------------------------------------
-- use ROW_NUMBER() function to assign sequence IDs to rows
--------------------------------------------------------------------
SET @timer =getdate()
;WITH cte1 AS( SELECT TOP(@rows) * FROM dbo.SalesDetail)
,cte2 AS (
SELECT *,row_number()OVER(PARTITIONBY product ORDER BY SaleDate DESC) AS seqID
FROM cte1
)
SELECT *
INTO #results3
FROM cte2
WHERE seqID = 1
INSERT INTO @results
SELECT 'Row_Number()', @rows, datediff(ms,@timer,getdate())
-- note: prior to adding loops, the queries were tested to ensure
-- they were producing identical result sets
drop table #results1
drop table #results2
drop table #results3
SET @loop = @loop + 1
END -- INNER LOOP
SET @rows = @rows*10
END -- INNER LOOP
----------------------------------------------------------
select Technique,RowsCount,avg(1.0 * Millisecs) as AvgMS
from @results
group by Technique,RowsCount
Results of Testing at 1,000 Rows
With @rows = 1000, the execution times were as follows:
| Technique | Execution Time in Milliseconds | |||
| 1,000 Rows | 10,000 Rows | 100,000 Rows | One Million Rows | |
| Match MAX() | 489.6 | |||
| Row_Number() | 4.28 | |||
| Top (1) | 6902.94 | |||
At a thousand rows, it certainly looked like a no-brainer in terms of efficiency. Getting the MAX ([SaleDate]) for each product in the thousand rows and then using a join back to the SalesDetail table was over 10 times faster than taking the TOP (1) rows for each product. But the ROW_NUMBER() technique ran almost instantly, and so was the clearly the most efficient for only a small amount of data.
Results of Testing at 10,000 Rows
However, a different picture began to emerge as the volume increased to 10,000 rows:
| Technique | Execution Time in Milliseconds | |||
| 1,000 Rows | 10,000 Rows | 100,000 Rows | One Million Rows | |
| Match MAX() | 489.6 | 515.18 | ||
| Row_Number() | 4.28 | 70.3 | ||
| Top (1) | 6902.94 | 6911.56 | ||
As can be seen, an interesting thing happened. The runtime for the MAX() technique increased slightly, but the runtime for the TOP(1) technique increased hardly at all. Meanwhile the runtime for the ROW_NUMBER() technique increased dramatically from four milliseconds to 70 but even so, at this volume, the ROW_NUMBER() technique was still clearly the most efficient.
Results of Testing at 100,000 Rows
But the testing wasn’t done yet. Here are the results at 100,000 rows:
| Technique | Execution Time in Milliseconds | |||
| 1,000 Rows | 10,000 Rows | 100,000 Rows | One Million Rows | |
| Match MAX() | 489.6 | 515.18 | 937.06 | |
| Row_Number() | 4.28 | 70.3 | 2121.12 | |
| Top (1) | 6902.94 | 6911.56 | 7066 | |
Obviously, the trend noted at 10,000 rows continued. The MAX() technique took almost twice as much time, but the TOP(1) technique took only about a tenth of a second to go from processing 10,000 to processing 100,000 rows. Meanwhile, the ROW_NUMBER() runtime exploded! At this level the MAX() technique now ran in under half the time needed by the ROW_NUMBER() technique! Somewhere between 10,000 and 100,000 rows, there came a break-even point (or a "pain point" if you prefer) where the cost of using the ROW_NUMBER technique exceeded the cost of using the MAX technique.

We could do additional testing at increments of 10,000 or even 1,000 rows to determine more closely where that pain point occurs, but the important thing to understand is that when that point is reached, the ROW_NUMBER() technique becomes less efficient than the MAX technique under these conditions. Nothing has changed in the code, or in the structure of the table. Only the volume of data is different. This demonstrates why the answer to the question of which is the more efficient technique is: "It depends."
Results at One Million Rows
The final test ran at the full table size of one millions rows:
| Technique | Execution Time in Milliseconds | |||
| 1,000 Rows | 10,000 Rows | 100,000 Rows | One Million Rows | |
| Match MAX() | 489.6 | 515.18 | 937.06 | 15526.08 |
| Row_Number() | 4.28 | 70.3 | 2121.12 | 63764.18 |
| Top (1) | 6902.94 | 6911.56 | 7066 | 8479.36 |
At last, the TOP(1) technique proved itself. Although clearly less efficient at one thousand rows, it was the most efficient at one million because it required only a little additional time for every tenfold increase in rows. Somewhere between one hundred thousand and a million rows, the MAX technique reached a pain point where it became less efficient. Once again, we see that knowing which technique is the most efficient depends on the number of rows involved.
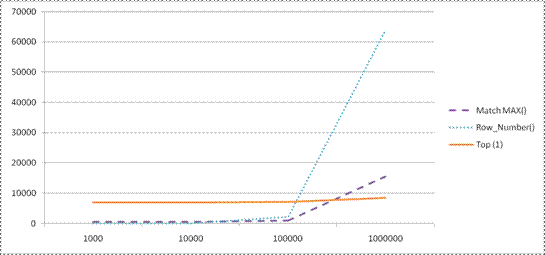
The results established that for the full million rows, the TOP(1) technique was the most efficient. The ROW_NUMBER() technique was a sprinter that was excellent for low volume queries, and the MAX() technique was the winner for some range in between. But the analysis doesn’t end there.
Changing the Environment By Creation of a New Index
All of the above measurements were taken with a SalesDetail table that had a primary key/clustered index that was of absolutely no help to any execution plan based around the [Product] and [SaleDate] columns. But that may not represent a real world environment. If a query were going to be run frequently and fast execution time was critical, then it would be appropriate to create a non-clustered index to help the query along. An obvious non-clustered index for our three examples would be one based simply on product id and date (descending). So such an index was created and the tests run again.
create unique nonclusteredindex IX_SalesDetail_product_SaleDate on dbo.SalesDetail (product,SaleDate desc, ID)
| Technique | Average Execution Time in Milliseconds Using A Non-Clustered, Non-Covering Index | |||
| 1,000 Rows | 10,000 Rows | 100,000 Rows | One Million Rows | |
| Match MAX() | 2.22 | 12.94 | 113.96 | 1120.96 |
| Row_Number() | 4.48 | 49.9 | 2169.44 | 61470.84 |
| Top (1) | 1.92 | 10.6 | 99.22 | 975.18 |
As you can see, with a proper index in place, the TOP(1) technique was consistently the winner, but the difference between it and MATCH MAX() technique was very small.
The differences in performance can be attributed to nuances in the execution plans. Visual representations of the query plans are available through SSMS. Entire books have been written on understanding execution plans and these nuances are beyond the scope of an article for newcomers to T-SQL, but any developers who are serious about getting optimal performance out of their database(s) will eventually make the effort to thoroughly understand execution plans and their components. But they will also first understand that performance depends not only upon good code, but upon a good structure in the database design and the indexes provided.
Conclusion
For the newcomer it is enough to understand that a number of variables effect query performance. Because of these variables, the only way to be sure a query is efficient is to compare it to alternative techniques, using real-world schema, at expected real world volumes. This analysis considered only differences in volumes and indexing, but these two variables alone were sufficient to illustrate that no "best" approach can be determined without anticipating production volumes, giving some forethought to the table and index structures needed to support efficient queries, and testing, testing, testing.
In developing the tests for this article, I made the interesting discovery that (in my laptop environment) the above non-clustered index performed better for these particular queries than a "covering" index which contained all columns necessary to satisfy the queries. Covering indexes place more of a maintenance load on the system as rows are added, updated, and deleted. But a covering index could perform better for future queries which display all sales within product. So which index type is better?
By now, you should know the answer:
"It depends."
Thanks to Jason Brimhall and Jon Crawford for their proofreading assistance and their constructive criticism.
