

SQL Server 2022 is in preview in August 2022. I assume this version will be released later this year, and I have been testing it with the idea that I will be looking at an upgrade sometime in the next year for a few servers. There are a lot of changes in the database platform, but the development changes are most interesting to me.
This article will lightly cover some of the T-SQL changes coming in SQL Server 2022. I will look at DISTINCT FROM, DATE_BUCKET, GENERATE_SERIES, GREATEST/LEAST, STRING_SPLIT, and DATETRUNC. There are a few other language changes I'll look at in another article.
DISTINCT FROM
This wasn't something that was on my list, but when it came out I saw a few examples of where this can be used and I thought it was useful in some code I write. The documentation for IS [NOT] DISTINCT FROM says that this function compares the equality of two expressions and guarantees a true or false, even if there are NULLs. Doesn't sound terribly interesting, but it can be useful.
As an example, let's say I have this code:
DECLARE @a INT, @b INT SELECT @a = 1, @b = 1 IF @a = @b SELECT 'equal', @a, @b ELSE SELECT 'unequal', @a, @b SELECT @a = 1, @b = 2 IF @a = @b SELECT 'equal', @a, @b ELSE SELECT 'unequal', @a, @b SELECT @a = 1, @b = null IF @a = @b SELECT 'equal', @a, @b ELSE SELECT 'unequal', @a, @b
I will get these results, which make sense. Somewhat. In the last one, we don't know if the values are equal.

This code really needs to be written like this:
DECLARE @a INT , @b INT; SELECT @a = 1, @b = 1; IF @a = @b SELECT 'equal', @a, @b; ELSE IF @a IS NULL OR @b IS NULL SELECT 'unknown', @a, @b; ELSE SELECT 'unequal', @a, @b; SELECT @a = 1, @b = 2; IF @a = @b SELECT 'equal', @a, @b; ELSE IF @a IS NULL OR @b IS NULL SELECT 'unknown', @a, @b; ELSE SELECT 'unequal', @a, @b; SELECT @a = 1, @b = NULL; IF @a = @b SELECT 'equal', @a, @b; ELSE IF @a IS NULL OR @b IS NULL SELECT 'unknown', @a, @b; ELSE SELECT 'unequal', @a, @b;
This gives me the proper results of "equal", "unequal", and "unknown". This is the 3 value logic that exists with nulls.
Without this new predicate, we could have true, false, or NULL when we compare these. With this new predicate, we can do this:
DECLARE @a INT , @b INT; SELECT @a = 1, @b = NULL; IF @a IS DISTINCT FROM @b SELECT 'unequal', @a, @b; ELSE SELECT 'equal', @a, @b;
The result here is "unequal" even though one of the values is a NULL. This means I always guarantee a true or false in this expression.
Where this becomes useful is in place where I don't want to try and write some OR expression to check if something IS NULL or is equal to something else. For example, in AdventureWorks, I can write this code:
DECLARE @cc INT = 5618;
SELECT soh.SalesOrderID
, soh.OrderDate
, soh.SalesOrderNumber
, soh.CustomerID
, soh.CreditCardID
, soh.CreditCardApprovalCode
FROM sales.SalesOrderHeader AS soh
WHERE soh.CreditCardID = @ccThis will return me a few orders. However, if I change this to a NULL, I get this:
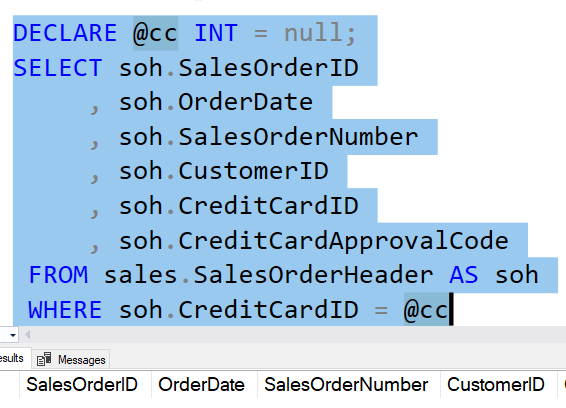
In SQL Server 2022, I can change this. In this case, since I want a match, we use the IS NOT DISTINCT FROM. This gives me code that works and finds the NULL rows.
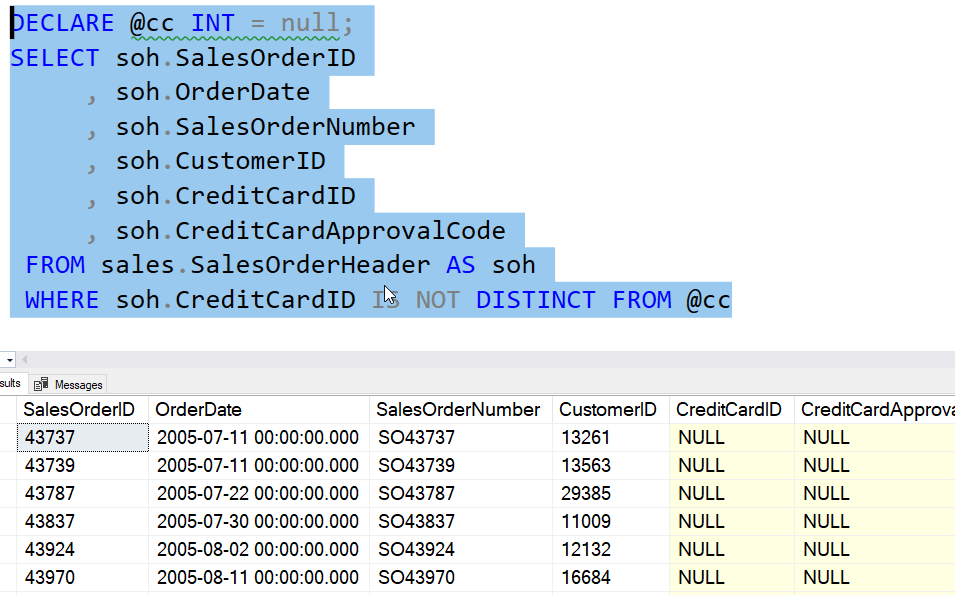
Without this, I would have to write an OR clause that looks for ISNULL or a value, for both the parameter and the value I'm checking. I'd also need to use some sort of magic value, like the largest INT value or another value unlikely to be in the table.
DATE_BUCKET
The DATE_BUCKET function gives you the starting date of some period, based on a window, or bucket, that you specify. I haven't seen a great explanation of this, but I can see this as being useful in understanding situations where you are grouping or calculating periods. It is easier to show this as a few examples, at least, those made sense to me.
Suppose I want to divide the year into 4 week buckets. In 2022, this would mean that there are these buckets to start the year:
- 1 - Jan 1 to Jan 28
- 2 - Jan 29 to Feb 25
- 3 - Feb 26 to Mar 25
- and so on
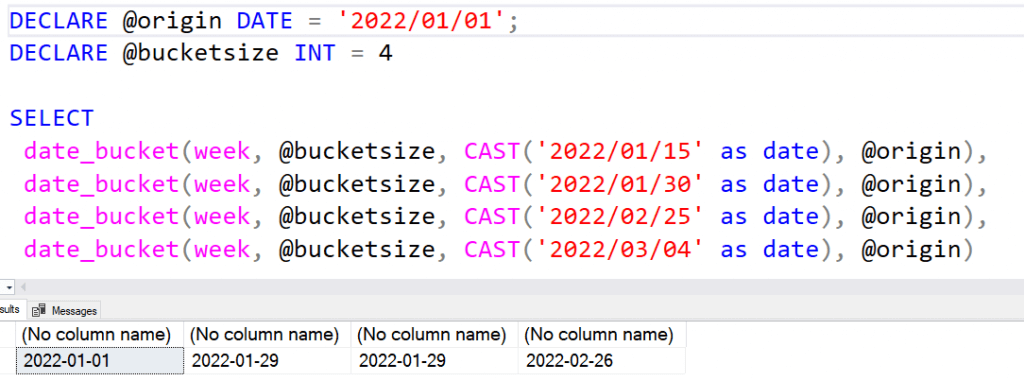
If I set my starting date as Jan 1 and pick a date in an interval, I find that the start of each bucket is returned. I've picked 4 dates in different parts of the first few months to show this. Here is the code:
DECLARE @origin DATE = '2022/01/01';
DECLARE @bucketsize INT = 4
SELECT
date_bucket(week, @bucketsize, CAST('2022/01/15' as date), @origin),
date_bucket(week, @bucketsize, CAST('2022/01/30' as date), @origin),
date_bucket(week, @bucketsize, CAST('2022/02/25' as date), @origin),
date_bucket(week, @bucketsize, CAST('2022/03/04' as date), @origin)
and the results. As you can see, the first day of each 4 week bucket is returned:
If I change the bucket type to month, and shrink the interval to 1, then I get the first day of each month.
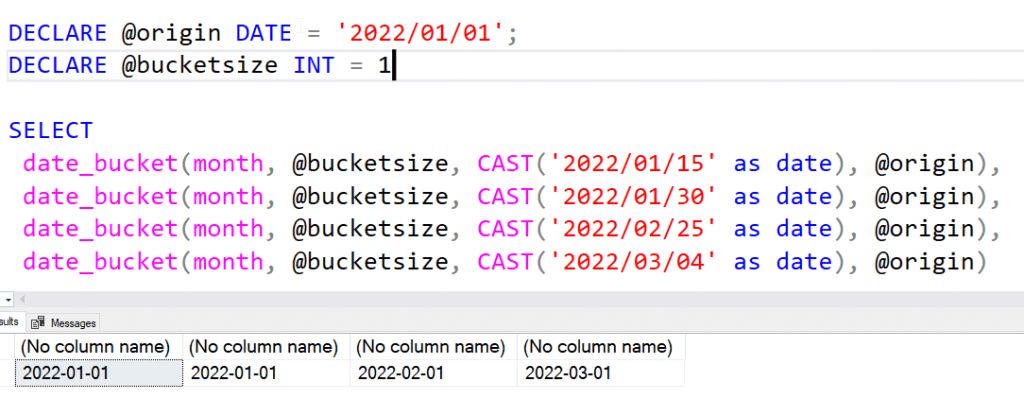
A more detailed explanation of how this works is at SQLPerformance from Itzik Ben-Gan, but I found it a bit confusing. I definitely need to experiment more here in reporting queries and see how this works.
GENERATE_SERIES
I have read about using Tally Tables from Jeff Moden and find them useful in many situations. If you haven't read that article, you should. I had hoped we'd get some virtual tally table in SQL Server, but we haven't. We do get, however, GENERATE_SERIES, which is close.
This returns me a table of numbers I can use as I see fit. The syntax is pretty simple, and there are a few interesting enhancements. The basics are:
GENERATE_SERIES( start, stop [, step])
The default step is 1 if start < stop, otherwise -1. This cannot be zero.
If I want a list of numbers from 1 to 5, I get do this:
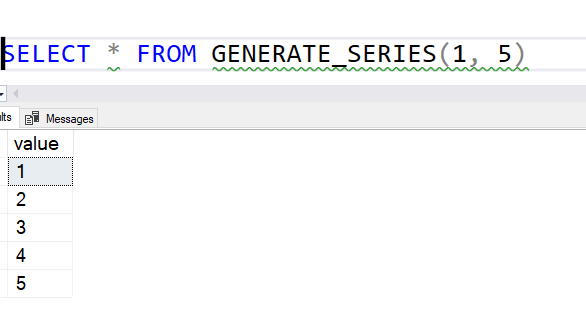
The interesting thing about this function is that you can use it with decimals. Let's say I want to do something with decimals for percentages. I could do this to get a list of the percentages from 1 to 100.
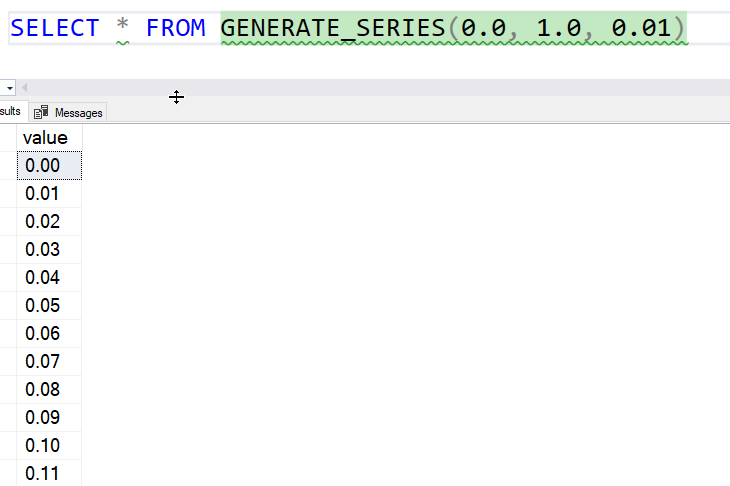
The column name is value, in case you want to use it in the same way as a tally table
GREATEST/LEAST
These are cool functions to me that once again are simple to duplicate, but they make the code so much cleaner. I am glad that GREATEST() and LEAST() got added to the platform. These functions will compare a number of parameters and return the greatest or least of them.
A few examples. First, let's look at numeric values:
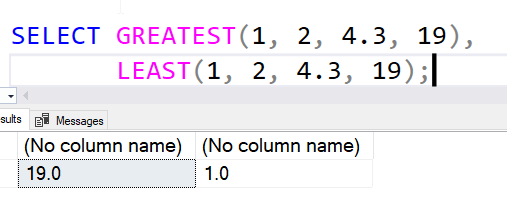
You can see that the biggest and smallest are returned by these functions, but there is a datatype conversion. This is based on datatype precedence.
This also works with strings.
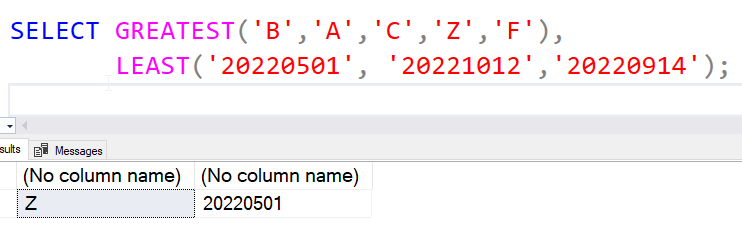
The values in LEAST() are strings, not dates. We can use dates, but need to pass in date typed parameters. All the values passed in need to be able to go through an implicit conversion.
The biggest value for these functions is they ignore NULLs. So if I have a number of dates for an order, like the order, pack, ship, delivery dates, I can get the latest one easily:
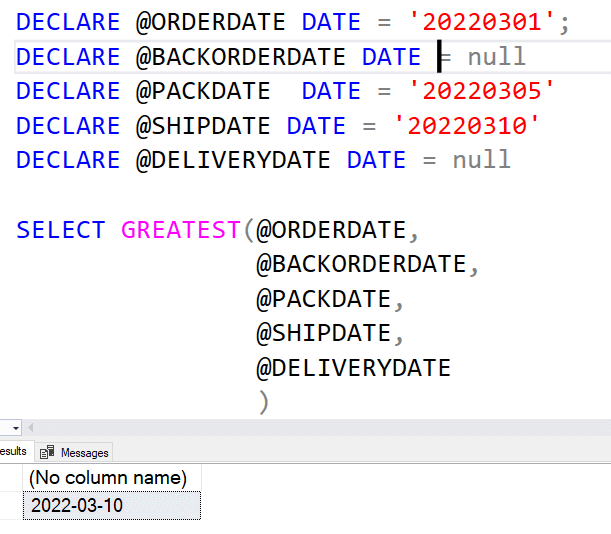
Here I have ordered the dates in the function in the way that they would usually be updated, but I don't need to worry about the NULL values for the backorder and delivery dates. This gives me the latest date this order was touched.
STRING_SPLIT
STRING_SPLIT has been in SQL Server for a few versions, but one of the hassles has been that when you split a string, you had no guarantee of ordering. A fatal mistake, in my opinion. That changes in SQL Server 2022. There is an optional third parameter that you can add as a 1 to get back the ordinal value.
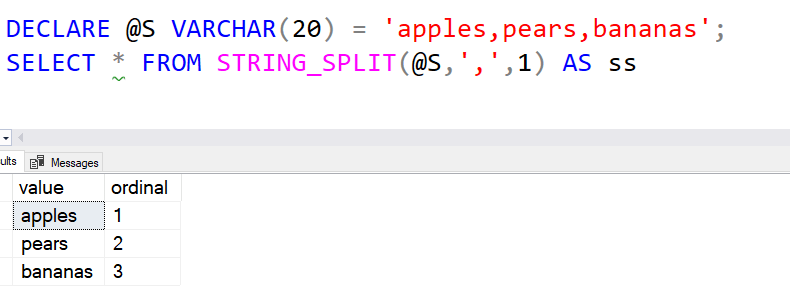
The columns are "value" for the split string and "ordinal" for the position. Make sure you ORDER BY the ordinal.
I can't just split by nothing, meaning a blank separator. Still a hole in the functionality, at least to me.
DATETRUNC
I don't often need DATETRUNC in many situations, but I can see how this would be handy when you only care about the start of some period of a datetime value. What this does is essentially stop at the part of the date you care about and zero out the rest of the datetime value. I can remove the day from a date and get the year and month with 01 as the day. Or remove the month and have Jan 1 of the year. Or remove minutes, seconds, etc.
A few examples in here. I've split this up to get it easier to read the image, but if you look at the various values, you'll see how the datetime is essentially truncated at the value I specified.
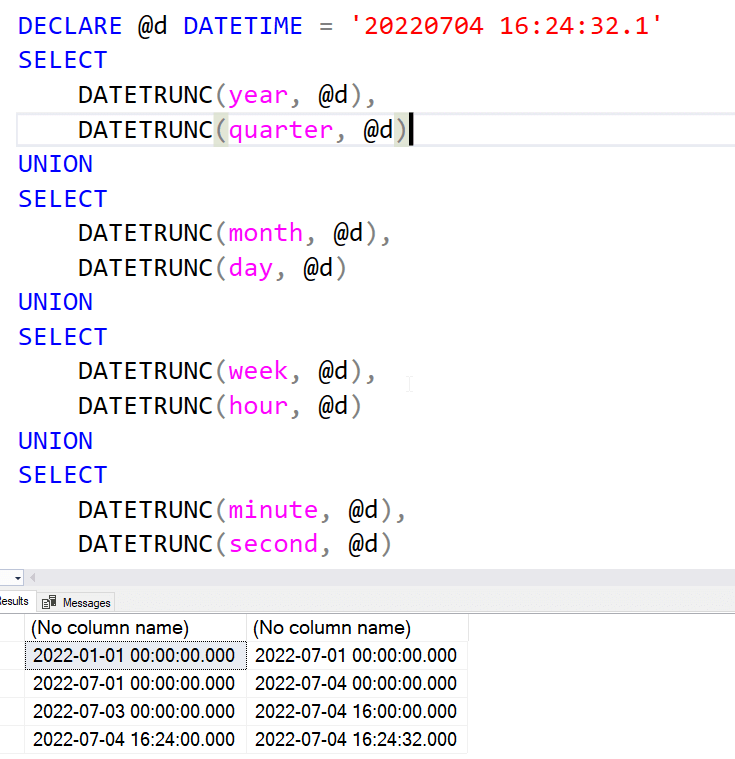
Timezoneoffset is not supported here.
Summary
These are a few of the changes in T-SQL for SQL Server 2022. The GENERATE_SERIES is welcome as I use tally tables and this can replace that. I'm sure I will also start to use the STRING_SPLIT ordinal, but I have some code to change to account for the extra column.
DATE_BUCKET looks interesting, especially for period calculations. Being able to specify various periods will help with finance reports that sometimes use weird period buckets. I don't know about DATETRUNC as my bigger problem is often end dates, so I guess I could use this and add 1, but that feels inefficient.
DISTINCT FROM and GREATEST/LEAST are probably the functions I will the most. I can see lots of report logic that gets simpler with these enhancements.
I'd urge you to play with SQL Server 2022 and develop familiarity with this code. It might be a reason to upgrade, or maybe just the one reason that tips the scales for your organization.