

Introduction
- 4 E's
- Performance
- Security
- Recoverability
- Maintainability
- Scalability
- Conformity
- Learn SQL Azure developing a federation of geographically partitioned databases
- The purpose of which would be to reduce food waste, feed people
- The system also providing the winning entry an Ordnance Survey (geographic) Open Data competition

The OS Data is available in two formats, vector and raster. Each arrives as a collection of approximately 8 CD's containing in excess of 20 GB of data.
Importing the OS Data requires specialist ETL tools, search for GIS Data ETL tools supporting SQL Server on Google. This is as good free one http://www.sharpgis.net/page/Shape2SQL.aspx , FME Desktop is the most feature rich and expensive option - http://www.safe.com/ give you 14 day trial.
Vector data
'Shape' file data can be imported into SQL geometric and geographic data types.
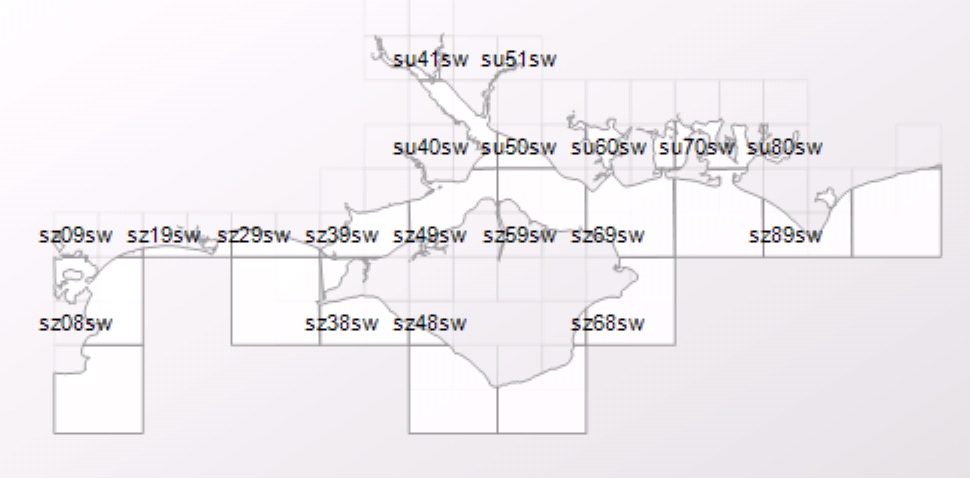
The diagrams below (part of SU & SZ in National Grid) show the effect of using the STOverlaps method - http://msdn.microsoft.com/en-us/library/bb933960.aspx.
Unfiltered Grid and Ventor Data

Below the Grid data is filtered using STOverlaying of Vector data. The 2 blank grid cells in the middle of the Isle of Wight are due to OverLay only, not Intersect methods being used.

Each 1 KM square cell was calculated based on Raster data coordinates imported from TAB files.
Raster Data
The OS Raster data is effectively a collection of arial/satelite images with accompanying metadata files. Microsoft Reporting Services Maps don't support them unfortunately, they would look great underlying semi-transparent Vector data
It's straight forward importing the images into a SQL File Stream table for future use or for custom coding purposes. Each image file comes with an accompanying 'TAB' file containing coordinate information which can be used to construct an initial set of grid coordinates.
Reports
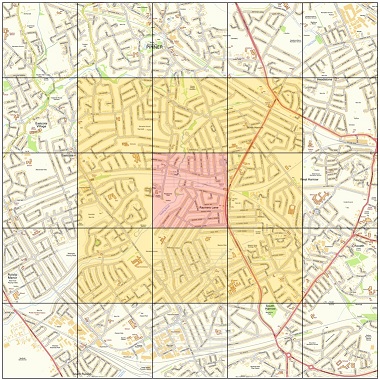
The report below shows an area on the UK shoreline imported from the Vector data CD's. Underlying this is a section of the grid, constructed from the imported TAB files. It's labelling just the South West Corners of 10KM square cells to avoid cluttering the screen but show the cross referencing.
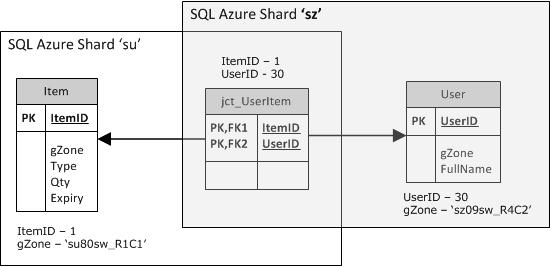
The grid is useful as the position and area are easy to quantify, irregular polygons and lines are not so easily interpretted, the grid also corresponds to the RASTER satelite images. Food demand and availability information is stored at item level by a grid reference (EG su80sw_R1C1) which represents a defined area of 1 KM within the parent cell. The SQL Azure Sharding/Partitioning key also lies at another, higher level in this grid/cell parent hierarchy.
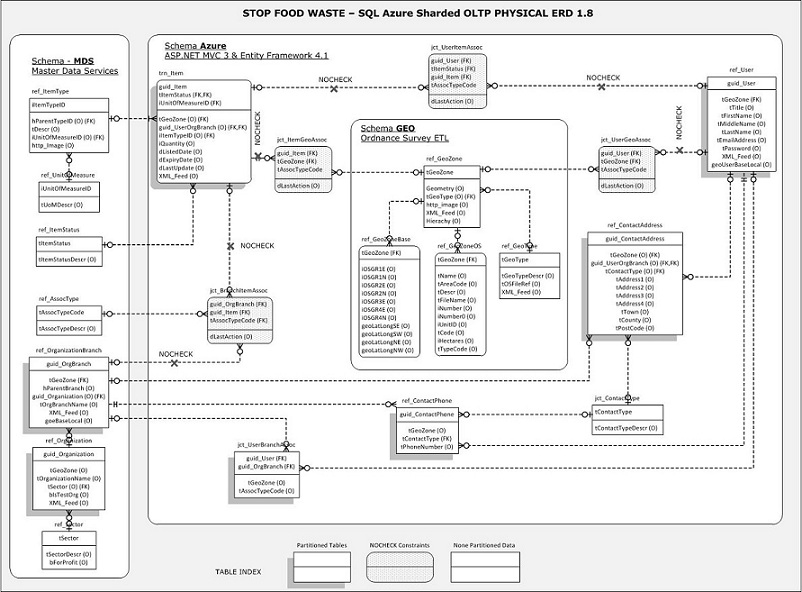
Stop Food Waste - SQL Azure Partitioned Database Schema
To support and scale the system, the SQL Azure Sharding feature looks good for partitioning supermarkets and homeless shelters in proximity according to an OS National Grid derived key. If the system became popular it would be possible to add new federations (by sub-dividing existing grids) as discussed in this whitepaper - http://social.technet.microsoft.com/wiki/contents/articles/1926.how-to-shard-with-sql-azure.aspx .
The use of 'No Check' constraints on certain 'jct' Junction table foreign key's is in case the rows they reference exist only in another partition/SQL Azure federation table. The sharding policy is by GeoZone, if not participating in the sharding policy the junction tables appear in all Sharded instances. I'm not sure if this is how it works or not to be honest.
3 schema's are used, MDS, Azure and Geo, each with update permissions on owned tables, select permissions on tables owned by other schema's.
- Azure - The 'tGeoZone' column Sharding, GUID's used for primary key on tables updated in Azure to ensure uniqueness across federations.
- MDS - Master Data Services in SQL Server 2012, hierarchical and relatively static reference data, pushed to Azure as required.
- GEO - Imported Ordnance Survey Open Data is physically too large for Azure so Azure clients would need a connection to the local database for maps and other geographic information, via XML / GML
Developer Edition) and involves a lot more XML/GML using the SQL geospatial methods. It's enjoyable but time consuming, progress is slow.
I'm not an expert database designer and am completely unfamiliar with SQL Azure making assumptions based on the whitepaper and how that would be physically implemented.
The database schema above is an old one, the OS Data is best stored in the format supplied on the CD's, no ETL transformation necessary. This schema was intended for SQL Azure partitioning and the effect this might have with foreign key constraints on non partitioned JCT intersect type tables.
The main lesson's learnt ready for Version 2 are:
- Don't try and tackle all the OS Data at once, pick a workable area of a few miles.
- Upload just the VECTOR shape files for an area, each to it's own simple table using this http://www.sharpgis.net/page/Shape2SQL.aspx
- Upload the TAB files (on the RASTER format CD) for coordination.
- Develop the database out from the OS Data tables and functions around them. Don't ETL OS Data to fit new table structures, use the supplied formats.
- Keep possible future partitioning strategies in mind but not as the main driver.
References ready for Version 2
- Michael Coles - PRO SQL Server 2008 XML
- http://jasonfollas.com/blog/archive/2008/03/14/sql-server-2008-spatial-data-part-1.aspx This is an excellent set of articles about using geospatial methods, does not include the new 2012 methods though.-
- http://www.sqlservercentral.com/articles/SQL+Server+2008+R2/72530/ - 1st published a year ago, guidance for Version 2 of this project.
- http://sqlmcm.quickstart.com/SQLSkills MCM Study Labs.
- A friend reviewed this article and pointed out a company in Australia who are doing the same thing - http://www.microsoft.com/casestudies/Microsoft-SQL-Server-2012-Enterprise/Maptel/Software-Developer-Speeds-Time-to-Market-and-Improves-Scalability-with-Hybrid-Cloud/710000000156
