

In SQL Server Integration Services (SSIS), the lookup transformation is used to perform look up values in a reference dataset. The reference dataset can be a table or view or simply a SQL SELECT query.
The lookup transformation performs an qui-join between values in the transformation input and values in the reference dataset. If there is no matching record in the reference data, no values are returned from the reference dataset. This results in an error, and the transformation fails, unless it is configured to ignore errors or redirect error rows to the error output.
While the lookup transformation is quite simple and handy, there can be scenarios where this simple and handy transformation can make things complex. But then there is always an alternative!
A Simple Requirement
Let us consider a simple requirement where input column values from source should be validated against a reference dataset before inserting the rows into the target table. If the input value does not exist in the reference dataset, then that row should be written to an exception log instead of inserting it into the target table.
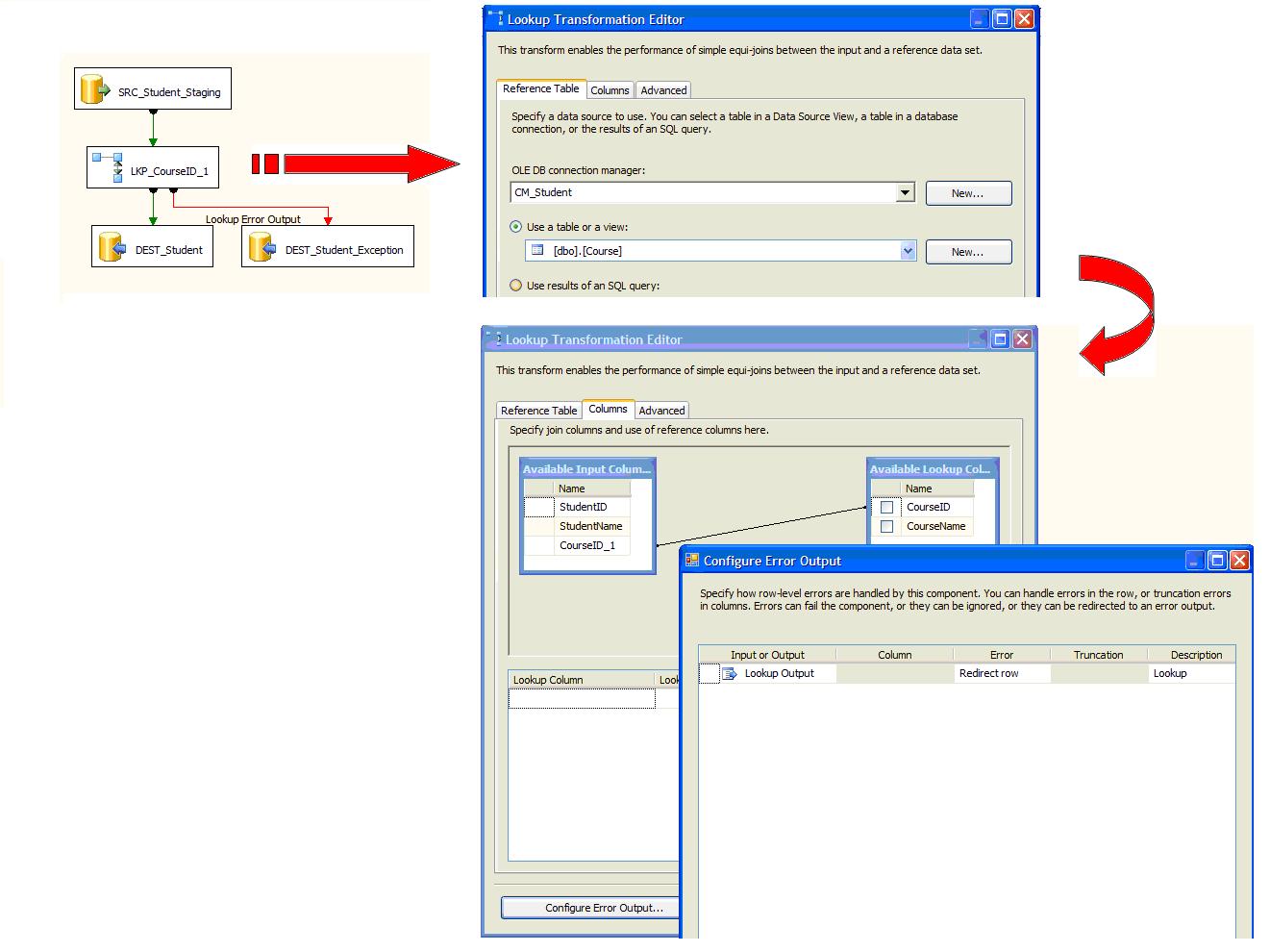
Figure 1 shows an implementation of the above requirement. The incoming CourseID_1 column values from Student_Staging source table will be looked up in the Course reference table. If CourseID_1 value is not found in Course reference table, then the incoming row is redirected to the error output. The error row is written to a table based exception log (Student_Exception).
Figure 1: Implementation of the simple requirement using a lookup transformation
Requirement with a Twist
Now, let us add a twist in the requirement. The requirement is now to validate two input columns CourseID_1 and CourseID_2 from the Student_Staging source table against the Course reference table. And for each row, if either the CourseID_1 column value or the CourseID_2 column value or both column values are not found in the Course reference table, then the incoming row should logged as an exception with a comment that is relevant i.e. "Reference for CourseID_1 not found." or "Reference for CourseID_2 not found." or "Reference for CourseID_1 not found. Reference for CourseID_2 not found." as the case be.
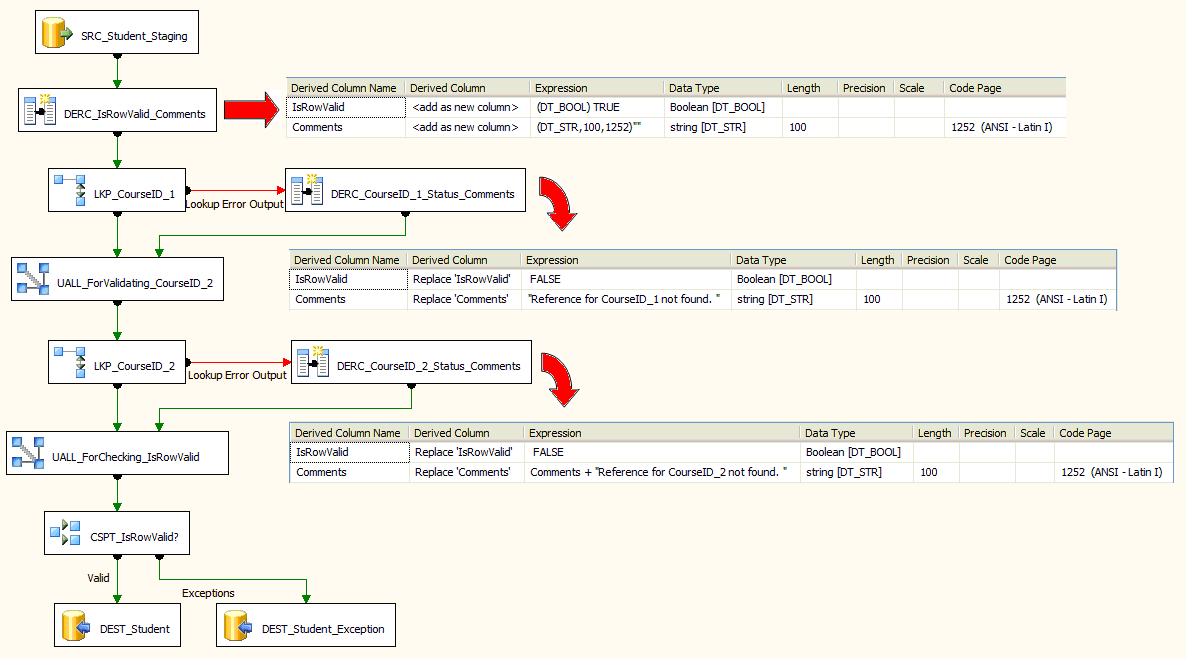
Figure 2 shows the how this requirement is implemented using lookup transformation. To implement the twisted requirement above we add an 'IsRowValid' flag field to track the status of each row after lookup validation (by default we assume the row is valid) and a 'Comments' field to hold the appropriate comments. The input rows are then validated for CourseID_1 column values. If the lookup for CourseID_1 column value fails, the row is directed to error output where the 'IsRowValid' flag is set to 'False' and appropriate comments added. The error output is combined with the original pipeline for validating input CourseID_2 column values. The error output from CourseID_2 column validation in again combined with the original pipeline for checking the row status. All valid rows are inserted into Student table and all invalid rows are logged in Student_Exception table along with comments.
Figure 2: Implementation of the twisted requirement using two lookup transformations
The Challenging Requirement
Just imagine what happens if the requirement is to validate 15 to 20 input columns (say CourseID_1, CourseID_2, and so on till CourseID_20) or maybe more columns on same the reference dataset (Course in our example). And we must still log rows as exceptions with comments for all the column values if they are not found in the reference dataset. Also, what if the input column data type is string column and the values can be in any case (but still Course=COURSE)? Note that lookup transformation is case-sensitive. Does this all sound challenging or ridiculous?
Let me brief you on what I came across. I had to import a file with 15 odd columns to be validated against one reference dataset, almost similar to what I just mentioned above. And the file could have anywhere between 10 to 15 million records. At some point in time the same file was also required to be reformatted slightly differently as a feed for another application, so there was no point in normalizing the target table.
The Approach
After spending a couple of days (and nights), I came up with the following approach that makes uses of a script component to perform the lookup.
The approach requires an ADODB recordset to used in the script component. The ADODB recordset can be created easily with an SSIS variable of type System.Object and populated using the Execute SQL Task's 'Full result set' option.
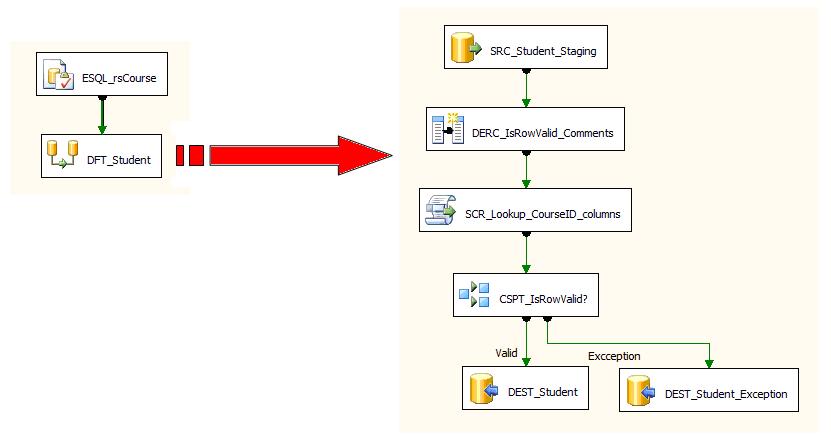
Figure 3 shows the implementation of the approach for the challenging scenario using a script component and Listing 1 shows the script component code that makes it work as a lookup transformation. I am not a .NET guy, so there may be a better way of writing some of the code in the script component.
Figure 3: Implementation of challenging scenario using a Script Component
To make the script component work as a lookup transformation, create a Data.DataTable object at the class level. Override the 'PreExecute()' method of the script component to populate the DataTable object from the ADODB recordset using the Data.ObeDbDataAdapter object. Create a generic function 'LookupCourse' to lookup the input column value in the DataTable object and return True if the value is found and False otherwise. Then in the 'Input0_InputProcessRow()' method, which is called for every row in the input pipeline, call the generic function 'LookupCourse' passing it the input CourseID column's value one at a time. If the 'LookupCourse' functions fails to find the input column value, then set the 'IsRowValid' flag to False and add the appropriate comments.
Listing 1: Script Component code making it work as lookup transformation
Public Class ScriptMain
Inherits UserComponent
Dim dtCourse As New Data.DataTable ''Data.DataTable object to hold the reference dataset
''Override the PreExecute method to intialize the Data.DataTable objects
Public Overrides Sub PreExecute()
MyBase.PreExecute()
''Initialize the Data.DataTable object to hold the reference dataset only if available.
If Not Me.Variables.rsCourse.ToString() = "System.Object" Then
Dim oledb As New Data.OleDb.OleDbDataAdapter
''Fill the Data.DataTable object from the reference dataset populated using the Execute SQL Task
oledb.Fill(dtCourse, Me.Variables.rsCourse)
''Sort the column to enable Find method to lookup for the values in the reference column
dtCourse.DefaultView.Sort = "CourseID ASC"
End If
End Sub
''A generic function to find input value in the reference dataset
Private Function LookupReferenceValue(ByVal strValue As String) As Boolean
''Lookup in reference dataset only if data exists in reference dataset
If dtCourse.Rows.Count > 0 Then
''If the input column value is not found in the reference dataset then return false
If dtCourse.DefaultView.Find(strValue) < 0 Then
Return False
End If
Else
''If the data does not exists in reference dataset then flag the row as invalid
Return False
End If
Return True
End Function
Public Overrides Sub Input0_ProcessInputRow(ByVal Row As Input0Buffer)
''NOTE 1: The input column value can be NULL or zero-length value. In this case there is not need to perform lookup.
''NOTE 2: If input column value is of zero-length, then convert it to NULL. A zero-length value can cause referential integrity errors if FK constraint is implemented for the column.
''CourseID_1
If Not Row.CourseID1_IsNull Then
If Row.CourseID1.Trim.Length > 0 Then
''Lookup input column 'CourseID_1' value. If reference does not exist, then flag the row as invalid
If Not LookupReferenceValue(Row.CourseID1) Then
Row.IsRowValid = False
Row.Comments = "Reference for CourseID_1 not found. "
End If
Else
Row.CourseID1 = Nothing
End If
End If
''CourseID_2
If Not Row.CourseID2_IsNull Then
If Row.CourseID2.Trim.Length > 0 Then
If Not LookupReferenceValue(Row.CourseID2) Then
Row.IsRowValid = False
Row.Comments = Row.Comments + "Reference for CourseID_2 not found. "
End If
Else
Row.CourseID2 = Nothing
End If
End If
End Sub
End Class
To Conclude
Using a script component approach for lookups, I was able to import 10 million records from a file in just around 90 minutes on my local development machine (Intel® Core™2 CPU T5600 @1.83 GHz and 2GB RAM).
While the lookup transformation has different options to cache the reference dataset, the script component approach for lookup will cache all the reference data. Hence this approach may not be an option if the reference dataset volume is very large.
Also, I had to summarize, for the end user, the values that were missing in the reference dataset. This can be achieved by enhancing the script component a little more. I will write about it some other day.
