

Introduction
This article is the fourth in a series. There are links at the bottom of the article to the other parts.
In my last article, I discussed the new HIERARCHYID date type, which allows us to save a hierarchical structure in the database itself. This makes it easier to work with these kinds of data. I also talked about the Large User Defined Type, which allows users to expand the size of defined data types by eliminating the 8KB limit.
In this article I will be discussing the new FILESTREAM data type, which enables SQL Server applications to store unstructured data, such as documents and images, on the file system.
FILESTREAM Data Type (or rather a column attribute)
More and more information is being digitized now-a-days and to handle this data explosion, today’s businesses demand to be able to store external files such as different kinds of documents, audio files, video files, scanned images, and so forth into the database. With this proliferation of new kinds of unstructured data, digital content stored in the database brings many benefits and opportunities for businesses. It also brings challenges to the systems architects, administrators, and application developers who need to incorporate these unstructured data sources into computer applications and services.
To store such unstructured data into your database in previous versions of SQL Server, you had to take one of two approaches:
- You store a pointer to an external share into the database whereas actual data resides in the file system– Though at first glance this approach looks fine, it has inherent problems when it comes to manageability. For example it lacks transactional consistency, it is hard to do backup and restore, and security can be quite cumbersome.
- You store it as a BLOB (binary large object) data directly in the database table – SQL Server has always provided the capability to store BLOB data into a SQL Server varbinary column. But BLOBs have different usage patterns than relational data, and SQL Server's storage engine is primarily concerned with doing I/O on relational data stored in pages and extents, not streaming BLOBs. Because of this, performance degrades dramatically if the size of the data increases beyond a certain limit (more than 1MB). So what I mean to say here is, if streaming access is needed, storing the data inside a SQL Server database may be slower than storing it externally in a location such as the NTFS file system.
Note: For developers who are coming from a SQL Server 2000 background, Microsoft recommends using the MAX data types instead of BLOBs (TEXT, NTEXT and IMAGE) in SQL Server 2008 as BLOBs are being deprecated in future releases of SQL Server. The max clause indicates that the maximum storage size, i.e. 2^31-1 bytes (2GB), is available for a single field. When using the max data type, you can control how the data is physically stored in the data pages of the table by setting the “large value types out of row table” option. When this option is set to ON, all values are stored on separate linked pages and a 16-byte root pointer to these ages is stored on the data page for the row. When this option is set to OFF (Default), values of up to 8,000 bytes are stored in-line in the data page for the row, and if the value grows and does not fit in the data page for the row, a pointer is stored in-row and the data is stored out of row in the LOB storage space. |
The new SQL Server 2008 FILESTREAM data type enables SQL Server applications to store unstructured data, such as documents and images, on the file system with a pointer to the data in the database. This enables client applications to leverage the rich NTFS streaming APIs and performance of the file system while maintaining transactional consistency between the unstructured data and corresponding structured data with same level of security. Backups can include or exclude the binary data, and working with the data is with the standard SELECT, INSERT, UPDATE, and DELETE statements in T-SQL.
FILESTREAM Data Type
FILESTREAM storage is implemented as a varbinary(max) column in which the data is stored as BLOBs in the file system. The sizes of the BLOBs are limited only by the volume size of the file system. The standard varbinary(max) limitation of 2-GB file sizes does not apply to BLOBs that are stored in the file system. To specify that a column should store data on the file system, you specify the FILESTREAM attribute on a varbinary(max) column. This causes the Database Engine to store all data for that column on the file system, but not in the database. Storing the data on the file system brings these key benefits:
- Performance matches the streaming performance of the file system.
- BLOB size is limited only by the file system volume size.
- Transactional consistency
- Integrated security model
Improved unstructured data search is available using the integrated full-text search, which is now fully integrated into the database engine itself. Full-text search works with a FILESTREAM column in the same way as it does with a varbinary(max) column, though FILESTREAM table must have a column that contains the file name extension for each FILESTREAM BLOB.
The column varbinary(max) with FILESTREAM attribute set can be managed just like any other BLOB column in SQL Server, so administrators can use the manageability and security capabilities of SQL Server to integrate BLOB data management with the rest of the data in the relational database—without needing to manage the file system data separately. Defining the data as a FILESTREAM column in SQL Server also ensures data-level consistency between the relational data in the database and the unstructured data that is physically stored on the file system. A FILESTREAM column behaves exactly the same as a BLOB column, which means full integration of maintenance operations such as backup and restore, complete integration with the SQL Server security model, and full-transaction support.
Note: · The FILESTREAM feature does not use the SQL Server buffer cache - it uses the Windows NT system cache for the caching of the FILESTREAM data. This way it helps reduce any effect that FILESTREAM data might have on Database Engine performance. It means since SQL Server buffer pool is not used by FILESTREAM data therefore SQL Server buffer pool is available for query processing and all. · Data stored in NTFS file system can be compressed to save disk space, but at the expense of extra CPU to compress and decompress the data when it is written or read, respectively. Compression is also not useful if the data is essentially uncompressible for example already compressed data. |
Example
Now let’s run through an example to see how it works:
Before accessing the FILESTREAM feature and using it you need to enable the FILESTREAM at Windows level as well as at SQL Server Instance level. There are two different ways to enable FILESTREAM at Windows level.
Enabling it while installing SQL Server 2008– During SQL Server 2008 installation, you provide Database Engine Configuration details, there you can also choose to enable FILESTREAM as shown below.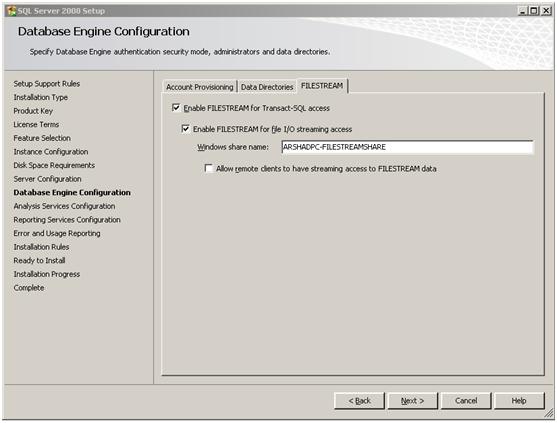
Here you provide the windows share location which will be used to store the FILESTREAM data. Also you can choose to allow remote clients to access on FILESTREAM data.
If you have not enabled FILESTREAM feature during installation, there is no problem you can do so using SQL Server Configuration Manager as discussed below.
Enabling it using SQL Server Configuration Manager – Right click on SQL Server Service, click on Properties and then select FILESTREAM tab. Here a screen with similar options as above will come up like this:
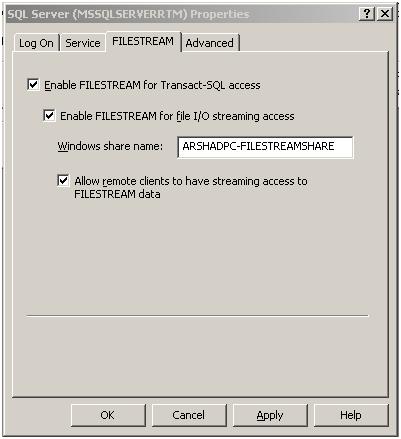
Now the next step is to enable FILESTREAM at SQL ServerInstance level. There are two different ways to enable FILESTREAM at SQL Server Instance level.
Enabling it using SQL Server Management Studio– In object explorer, right click on SQL Server instance, select Properties, choose Advance page and finally set the "Filestream Access Level" property appropriately over here as shown below.
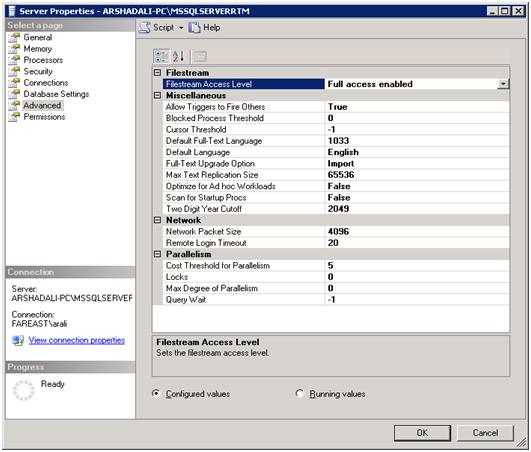
Enabling it using T-SQL statement– You can enable FILESTREAM support using sp_filestream_configure system stored procedure as given below.
USE master GO EXEC sp_configure 'filestream access level', 2 Go RECONFIGURE GO --You can use this statement to see current --config value and running value EXEC sp_configure filestream_access_level; GO
The different values for the filestream access level are:
| Filestream Access Level | Description |
| 0 | Disable FILESTREAM support for this instance |
| 1 | Enable FILESTREAM for Transact-SQL access only |
| 2 | Enable FILESTREAM for Transact-SQL and Win32 streaming access |
Note: You need to be Windows Administrator on local system and have sysadmin rights to configure FILESTREAM. |
Now since the FILESTREAM feature has been enabled at the Windows level as well as the SQL Server instance level, the next step is to create a database whose tables will use this feature. This database will have new special type of filegroup which is called FILESTREAM filegroup. A FILESTREAM filegroup contains file system directories instead of the files themselves. These file system directories are called data containers. Data containers are the interface between Database Engine storage and file system storage.
If you have already a database you can still use FILESTREAM by alter it to include FILESTREAM filegroup.
USE master
GO
IF EXISTS (SELECT name FROM sys.databasesWHERE name = N'LearnFileStream')
DROP DATABASE LearnFileStream
GO
CREATE DATABASE LearnFileStream
--Details of primary file group
ON PRIMARY
( NAME = LearnFileStream_Primary,
FILENAME =N'D:\FSLocation\LearnFileStream_Data.mdf',
SIZE = 10MB,
MAXSIZE = 50MB,
FILEGROWTH = 5MB),
--Details of additional filegroup to be used to store data
FILEGROUP DataGroup
( NAME = LearnFileStream_Data,
FILENAME =N'D:\FSLocation\LearnFileStream_Data.ndf',
SIZE = 10MB,
MAXSIZE = 50MB,
FILEGROWTH = 5MB),
--Details of special filegroup to be used to store FILESTREAM data
FILEGROUP FSDataGroup CONTAINSFILESTREAM
( NAME = FileStream,
--FILENAME refers to the path and not to the actual file name. It
--creates a folder which contains a filestream.hdr file and
--also a folder $FSLOG folder as depicted in image below
FILENAME =N'D:\FSLocation\FSData')
--Details of log file
LOG ON
( NAME = 'LearnFileStream_Log',
FILENAME =N'D:\FSLocation\LearnFileStream_Log.ldf',
SIZE = 5MB,
MAXSIZE = 25MB,
FILEGROWTH = 5MB);
GO
Once you execute the above script, you will notice a folder with these files and sub-folder has been created as shown below.
 If you open the sub-folder you will notice, it contains a filestream.hdr file and an $FSLOG folder.
If you open the sub-folder you will notice, it contains a filestream.hdr file and an $FSLOG folder.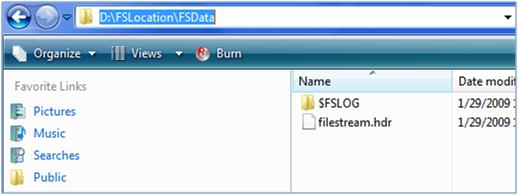
Note: You don’t need to create a database from scratch to use FILESTREAM feature; with an existing database you just need to alter it with ALTER DATABASE command and include a FILESTREAM filegroup and then you are all set to use FILESTREAM attribute with your tables. If you are trying to create/alter a database by specifying a path for the filestream folder/files that is not on NTFS, you will get an error, as NTFS is the requirement. Filestream.hdr is a system file which stores FILESTREAM header information, so DO NOT tamper with it. |
Let’s create a table that uses FILESTREAM. One column of the table must have a ROWGUIDCOL as it is used by the storage engine to keep track of instances in the NTFS file system. The moment you create a table you will notice a new folder has been added in the FILESTREAM data container location parallel to $FSLOG and filestream.hdr file.
USE LearnFileStream
GO
CREATE TABLE Product
(
--One column of the table must have a ROWGUIDCOL as
--it is used by the storage engine to keep track of
--instances in the NTFS file system
ProductID UNIQUEIDENTIFIER ROWGUIDCOL PRIMARY KEY,
ProductName VARCHAR(100),
--The FILESTREAM must be of type VARBINARY(MAX)
ProductCatalog VARBINARY(MAX)FILESTREAM
)
GO
Now we are done with the data definition, so let’s see how to insert data into a table that has a column with the FILESTREAM attribute. Again you will notice, once you start inserting records in the FILESTREAM table, new files are being created in the $FSLOG folder as well as also in the folder created when you created the table in the above step and name of file/folder would be same as GUID in the database.
--Here for simplicity purpose I am inserting text data converted to
--varbinary(max), in real life you would inserting documents, images,
--audio, video etc.
INSERT INTO Product
VALUES(NEWID(),'Product 1', CAST('Product 1 detail goes here...' As VARBINARY(MAX)))
GO
INSERT INTO Product
VALUES(NEWID(),'Product 2', CAST('Product 2 detail goes here...' As VARBINARY(MAX)))
GO
INSERT INTO Product
VALUES(NEWID(),'Product 3', CAST('Product 3 detail goes here...' As VARBINARY(MAX)))
GO
Backup and Restore
Backing up and restoration of database works in same way as a database with non-FILESTREAM enabled one. Additionally FILESTREAM filegroup can be backed up by itself or excluded from other backups as required as shown in the below image.
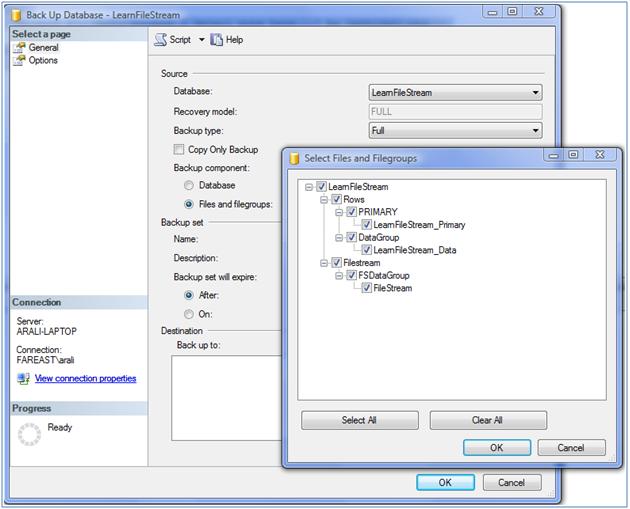
A backup that combines SQL Server database files and a large number of FILESTREAM files will be slower than a backup of just SQL Server database files of an equivalent total size. This is because of the extra overhead of backing up each NTFS file (one per FILESTREAM data value).
Transactional Consistency
When you insert a record, new file will be created to hold FILESTREAM data and link of this file will be stored in the table (basically the GUID of the row is name of the file). Further any change to the BLOB data in the FILESTREAM column will create a whole new FILESTREAM data file and the pointer will be moved to point to this new file if the transaction is committed or else will keep on pointing to the old file. The “old” file must be preserved until it is no longer needed for recovery purposes, likewise files representing deleted FILESTREAM data, or rolled-back inserts of FILESTREAM data, are also similarly preserved.
When a row that contains FILESTREAM data is deleted or a table that contains FILESTREAM data is deleted or truncated, the underlying BLOB data in the file system is also deleted. The actual physical removal of the FILESTREAM files is an asynchronous background process (an automatic garbage collection process) which happens after Database checkpoint, so it may take time since a table is truncated and actual physical files are removed.
Caution: Even though you can access these files if you have required permissions, these files cannot be directly deleted or renamed using the file system. Otherwise the link-level consistency will be lost between the database and the file system as a result of this the database might get corrupted. |
Security
In SQL Server 2008, FILESTREAM data is secured just like other data is secured: by granting permissions at the table or column levels. If a user has permission to the FILESTREAM column in a table, the user can open the associated files. Only the account under which the SQL Server service account runs is granted NTFS permissions to the FILESTREAM data container. When a database is online, SQL Server restricts access to the FILESTREAM data container(s), except when access is made by using the Transact-SQL transactions and OpenSqlFilestream Win32 API. However, when the database is offline, the physical data container is fully available and subject to Windows security check. In this scenario, I would recommend that you secure directories using ACL (Access Control List) that contain FILESTREAM data so that the files cannot be accidentally altered or deleted or tampered with.
Limitations
- SQL Server does not support database snapshots for FILESTREAM filegroups. When you are using FILESTREAM, you can create database snapshots of standard (non-FILESTREAM) filegroups. The FILESTREAM filegroups are marked as offline for those database snapshots.
- Database mirroring does not support FILESTREAM. A FILESTREAM filegroup cannot be created on the principal server. Database mirroring cannot be configured for a database that contains FILESTREAM filegroups. Hence if your requirement is to use database mirroring, you can continue using VARBINARY(MAX) in the same way as you had been doing in SQL Server 2005 for your unstructured data.
- You can use the FILESTREAM feature in a clustered environment but the FILESTREAM filegroup location must be on a shared disk.
- Log shipping is supported but SQL Server instances at both the ends must be running SQL Server 2008 version with FILESTREAM enabled.
- Transparent Data Encryption (TDE) and Table Valued Parameters (TVP) are not supported.
References
SQL Server Books Online - http://msdn.microsoft.com/en-us/library/bb933993(SQL.100).aspx
Conclusion
SQL Server 2008 introduces FILESTREAM data type which enables SQL Server applications to store unstructured data, such as documents and images, on the file system and pointer of the data in the database. This enables client applications to leverage the rich NTFS streaming APIs and performance of the file system while maintaining transactional consistency between the unstructured data and corresponding structured data; with same level of security and improved level of performance because of Win32 API streaming and storing unstructured data inside Windows system cache instead of SQL Server buffer cache.
This article is the fourth in a series. The other articles in the series are:
- SQL Server 2008 T-SQL Enhancements Part - I (Intellisense)
- SQL Server 2008 T-SQL Enhancements Part - II (UDTs and TVPs)
- SQL Server 2008 T-SQL Enhancements Part - III (HierarchyID and Large UDTs)
- SQL Server 2008 T-SQL Enhancements Part - IV (Filestream)
- SQL Server 2008 T-SQL Enhancements Part - V (Spatial)

