

Introduction
This article is the third in a series. There are links at the bottom of the article to the other parts.
In my last article, I discussed the new User-Defined Table type and Table-Valued parameters, which together allow a user to pass a result-set to a procedure or to a function and save multiple round-trips to the server and then I discussed about the new Date and Time data types which are efficient enough to save memory requirements by requiring much less memory in case if you have to save either date or time component only and making developers' lives easier working with them.
In this article I will discuss about the new HIERARCHYID date type which allows you to save a hierarchical structure, something like organizational hierarchy, in the database itself, makes easier working with these kinds of data and then I will talk of Large User Defined Type which allows users to expand the size of defined data types by eliminating the 8KB limit.
HIERARCHYID Data Type
A little background on why this is needed. Very often while a designing database you may need to create a table structure to store hierarchical data (Hierarchal data is defined as a set of data items related to one another in a hierarchy, that is, a parent node has a child and so forth). For example,
- To represent organizational hierarchy
- To represent a family tree
- To store BOM (Bills of Material) information which represents collection of sub-components which make up a final component, for example a cycle requires two wheels, rear and front. Each wheel further requires tyre, tube and rim.
Until SQL Server 2005, we had to create a self-referencing table to store hierarchical information, which gradually became more difficult and tedious to work with when hierarchical level grew to more than 2 or 3levels. The more levels, the more difficult to query as it required lot of joins, complex recursive logic. Though with the introduction of CTEs (Common Table Expression) in SQL Server 2005, we were not required to write iterative logic anymore to get a node (i.e. a Manager) and all its child nodes (i.e. all subordinates), but the performance of the CTE method is not that good. Let's see with example how it worked in previous versions; let's assume we have to create a table to store organizational hierarchy as given below.
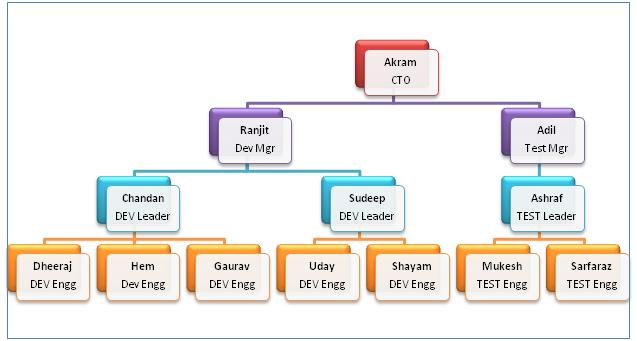
Now let's write script to create a table and insert records for the above tree.
CREATE TABLE Employees_2000_2005
(
EmpID INT PRIMARY KEY NOT NULL IDENTITY,
EmpName VARCHAR(255) NOT NULL,
Title VARCHAR(255) NOT NULL,
ReportsTo INT FOREIGN KEY REFERENCES Employees_2000_2005(EmpID) NULL
)
GO
INSERT INTO Employees_2000_2005(EmpName, Title, ReportsTo)
VALUES ('Akram', 'Chief Technology Officer', NULL)
SELECT @CTO = @@IDENTITY
INSERT INTO Employees_2000_2005(EmpName, Title, ReportsTo)
VALUES ('Ranjit', 'DEV Manager', @CTO)
SELECT @DevManager = @@IDENTITY
INSERT INTO Employees_2000_2005(EmpName, Title, ReportsTo)
VALUES ('Adil', 'TEST Manager', @CTO)
SELECT @TESTManager = @@IDENTITY
INSERT INTO Employees_2000_2005(EmpName, Title, ReportsTo)
VALUES ('Chandan', 'DEV Leader', @DevManager)
SELECT @DevLead1 = @@IDENTITY
INSERT INTO Employees_2000_2005(EmpName, Title, ReportsTo)
VALUES ('Sudeep', 'DEV Leader', @DevManager)
SELECT @DevLead2 = @@IDENTITY
INSERT INTO Employees_2000_2005(EmpName, Title, ReportsTo)
VALUES ('Ashraf', 'TEST Leader', @TESTManager)
SELECT @TESTLead = @@IDENTITY
INSERT INTO Employees_2000_2005(EmpName, Title, ReportsTo)
VALUES ('Dheeraj', 'DEV Engineer', @DevLead1)
INSERT INTO Employees_2000_2005(EmpName, Title, ReportsTo)
VALUES ('Hem', 'DEV Engineer', @DevLead1)
INSERT INTO Employees_2000_2005(EmpName, Title, ReportsTo)
VALUES ('Gaurav', 'DEV Engineer', @DevLead1)
INSERT INTO Employees_2000_2005(EmpName, Title, ReportsTo)
VALUES ('Uday', 'DEV Engineer', @DevLead2)
INSERT INTO Employees_2000_2005(EmpName, Title, ReportsTo)
VALUES ('Shayam', 'DEV Engineer', @DevLead2)
INSERT INTO Employees_2000_2005(EmpName, Title, ReportsTo)
VALUES ('Mukesh', 'TEST Engineer', @TESTLead)
INSERT INTO Employees_2000_2005(EmpName, Title, ReportsTo)
VALUES ('Sarfaraz', 'TEST Engineer', @TESTLead)
--After inserting the records as similar to the above tree, we will have
--a table which will have records something like this
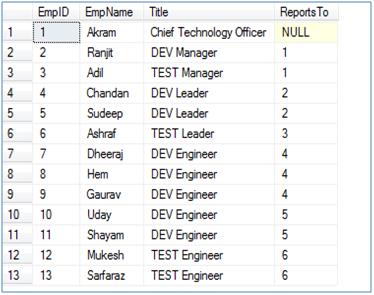
Now the question is given a manager (ReportsTo) ID, get all employees who are directly or indirectly reporting to him, let's see how we can do this in different versions of SQL Server.
In SQL Server 2000
There is no simple way to do this; you will end up writing a recursive stored procedures something as given below or UDF to accomplish this task.
--SQL Server 2000
--Create a temporary table to hold the intermediate resultset
CREATE TABLE ##Emp
(
EmpID INT,
EmpName VARCHAR(255),
Manager VARCHAR(255)
)
GO
--Create a recursive stored procedure(SP) which will take EmpID as
--an input, recursively traverse the hierarchy to find out all
--child nodes and sub-child nodes and store it in a temporary table
CREATE PROC EmployeeHierarchy(@EmpID INT)
AS
BEGIN
DECLARE @LocalEmpID INT, @EmpName VARCHAR(30)
INSERT ##Emp
SELECT EmpID, EmpName, (SELECT EmpName FROM Employees_2000_2005 WHERE EmpID = emp.ReportsTo) AS Manager FROM Employees_2000_2005 emp WHERE EmpID = @EmpID
SET @LocalEmpID = (SELECT MIN(EmpID) FROM Employees_2000_2005 WHERE ReportsTo = @EmpID)
WHILE @LocalEmpID IS NOT NULL
BEGIN
EXEC EmployeeHierarchy @LocalEmpID
SET @LocalEmpID = (SELECT MIN(EmpID) FROM dbo.Employees_2000_2005 WHERE ReportsTo = @EmpID AND EmpID > @LocalEmpID)
END
END
GO
--Truncate table before pushing data into using stored procedure
TRUNCATE TABLE ##Emp
--Call the above created SP and pass EmpID = 2
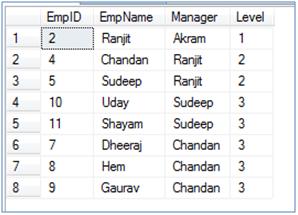
EXECUTE EmployeeHierarchy 2
SELECT * FROM ##Emp ORDER BY 1
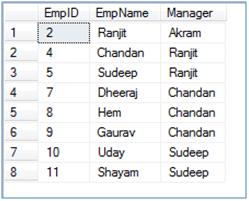
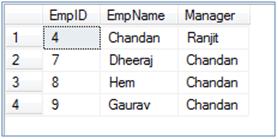
--Truncate table before pushing data into using stored procedure TRUNCATE TABLE ##Emp --Call the above create SP and pass EmpID = 4 this time EXECUTE EmployeeHierarchy 4 SELECT * FROM ##Emp ORDER BY 1
Even though the approach taken above works fine but it is constrained by 32-level nesting of recursive stored procedure. It's not a rare situation, if the hierarchy grows in its level; the nesting level reaches to its limit and starts failing.
SQL Server 2005
You can replace the recursive stored procedure approach taken above with Common Table Expression (CTE) introduced in SQL Server 2005, it does not only simplify the above approach but also you won't be having nesting level constrained as you had before.
--SQL Server 2005
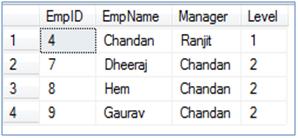
--Get all employees who directly/indirectly report to EmpID = 2
WITH EmployeeHierarchy(EmpID, EmpName, Manager, [Level])
AS
(
SELECT emp.EmpID, emp.EmpName, (SELECT EmpName FROM Employees_2000_2005 WHERE EmpID = emp.ReportsTo) , 1 AS [Level]
FROM Employees_2000_2005 AS emp
--Get all employees who directly/indirectly report to EmpID = 2
WHERE emp.EmpID = 2
UNION ALL
SELECT emp.EmpID, emp.EmpName, Parent.EmpName, Level+1
FROM Employees_2000_2005 AS emp
INNER JOIN EmployeeHierarchy AS Parent ON emp.ReportsTo = parent.EmpID
)
SELECT *
FROM EmployeeHierarchy
--Get all employees who directly/indirectly report to EmpID = 4
WITH EmployeeHierarchy(EmpID, EmpName, Manager, [Level])
AS
(
SELECT emp.EmpID, emp.EmpName, (SELECT EmpName FROM Employees_2000_2005 WHERE EmpID = emp.ReportsTo) , 1 AS [Level]
FROM Employees_2000_2005 AS emp
--Get all employees who directly/indirectly report to EmpID = 4
WHERE emp.EmpID = 4
UNION ALL
SELECT emp.EmpID, emp.EmpName, Parent.EmpName, Level+1
FROM Employees_2000_2005 AS emp
INNER JOIN EmployeeHierarchy AS Parent ON emp.ReportsTo = parent.EmpID
)
SELECT *
FROM EmployeeHierarchy
Even though SQL Server 2005, using CTE, simplified the process of retrieving hierarchical data from the SQL Server but still it has performance penalty. Not only this, the major drawback was still existent, I mean it was a nightmare to move child/sub-child records from one parent to another because of some organizational restructuring/realignment. Luckily with HIERARCHYID in SQL Server 2008 we would not be having those problems anymore. So now let's turn our attention to learn about this new system data type in details.
HIERARCHYID Data Type – taking its place
SQL Server 2008 has introduced a new data type HIERARCHYID to store hierarchical data in database table. HIERARCHYID is a variable length system data type, and used to locate the position in the hierarchy of the element. The HIERARCHYID data type is optimized for representing trees, which are the most common type of hierarchal data. The HIERARCHYID data type should be used to represent the position in a hierarchy, that is, a column of type HIERARCHYID does not represent a tree itself, but rather it simply represents the position of a row/node within a defined tree. HIERARCHYID data type exposes many different methods as discussed below which can be used to retrieve a list of ancestors and descendants as well as a means of traversing a tree etc.
| Method Name | Definition |
| GetRoot | It is static method so you need to call it with HIERARCHYID type itself. It returns root of the hierarchy tree. Syntax HIERARCHYID::GetRoot() |
| GetAncestor | It is used to find nth ancestos (parents and grantparents) of the given node. Syntax child.GetAncestor (<n>) Details: where <n> represents the number of levels to go up in the hierarchy. |
| GetDescendant | It returns a child node of the given parent. It is mainly used to determine new descendant's position before adding it to tree. Syntax Parent.GetDescendant (<child1>, <child2>) Details: • If parent is NULL, returns NULL. • If parent is not NULL, and both child1 and child2 are NULL, returns a child of parent. • If parent and child1 are not NULL, and child2 is NULL, returns a child of parent greater than child1. • If parent and child2 are not NULL and child1 is NULL, returns a child of parent less than child2. • If parent, child1, and child2 are not NULL, returns a child of parent greater than child1 and less than child2. • If child1 is not NULL and not a child of parent, an exception is raised. • If child2 is not NULL and not a child of parent, an exception is raised. • If child1 >= child2, an exception is raised. |
| GetLevel | It returns the depth of the node under the provided node/tree. Syntax node.GetLevel ( ) |
| IsDescendantOf | It returns true if child is a descendant of provided node. In other words, It is used to determine if a record or value is a child of a second record or value. Syntax Parent.IsDescendantOf(<Child>) |
| Parse | It is again a static method so it will be called by HIERARCHYID type itself. It is used to convert the canonical version of the data type to a HIERARCHYID value. Parse is called implicitly when a conversion from a string type to HIERARCHYID occurs. It acts as the opposite of ToString method discussed below. Syntax HIERARCHYID::Parse ( input ) |
| Read | This method is only available within .NET CLR code. It is used to read the binary representation of the HIERARCHYID value and cannot be called by using Transact-SQL. It reads binary representation of SqlHierarchyId from the passed-in BinaryReader and sets the SqlHierarchyId object to that value. Syntax void Read( BinaryReader r ) |
| GetReparentedValue | This method helps to re-parent a node i.e. suppose a manager left a job and all his directs will now come under another manager, it will be much helpful in this kind of scenario. In other words, it can be used to modify the tree by moving nodes from oldRoot to newRoot. Syntax node. GetReparentedValue ( <oldRoot>, <newRoot> ) <oldRoot> - represents the level of the hierarchy that is to be modified. <newRoot> - node that will replace the oldRoot section of the current node in order to move the node |
| ToString | It gives string representation (logical representation) of the HIERARCHYID. The data type for returned value is nvarchar(4000). Syntax node.ToString ( ) |
| Write | Similar to the Read method as discussed above, this method is also available only within .NET CLR code and cannot be called by using Transact-SQL. It writes out a binary representation of SqlHierarchyId to the passed-in BinaryWriter. Syntax void Write( BinaryWriter w ) |
Now let's run through some example of using HIERARCHYID data type. I will take the same tree which I have mentioned above to represent using HIERARCHYID this time.
--First I will create a table which uses new data type
CREATE TABLE Employee_2008
(
EmpID INT PRIMARY KEY NOT NULL IDENTITY,
EmpName VARCHAR(255) NOT NULL,
Title VARCHAR(255) NOT NULL,
HierarchicalLevel HIERARCHYID --Note the new data type here
)
GO
--Insert the Root node first in the table
--HIERARCHYID::GetRoot() is static method which returns the root node of a hierarchy
INSERT INTO Employee_2008 (EmpName, Title, HierarchicalLevel)
VALUES ('Akram', 'Chief Technology Officer', HIERARCHYID::GetRoot())
GO
--Let's see the data in the table
SELECT EmpID, EmpName, Title, HierarchicalLevel, HierarchicalLevel.ToString() AS [Position]
FROM Employee_2008
GO

Now I will add child nodes to the root node. Notice I am using here GetDescendant and GetAncestor methods to find out the position where a new node will be placed in the tree.
--Insert the first child node of the root node
--Get the root node we wish to insert a descendant of
DECLARE @CTONode HIERARCHYID
SELECT @CTONode = HIERARCHYID::GetRoot() FROM Employee_2008
INSERT INTO Employee_2008 (EmpName, Title, HierarchicalLevel)
VALUES ('Ranjit', 'DEV Manager', @CTONode.GetDescendant(NULL, NULL))
GO
--Now let's insert the second child node of the root node
--Get the root node we wish to insert a descendant of
DECLARE @CTONode HIERARCHYID
SELECT @CTONode = HIERARCHYID::GetRoot() FROM Employee_2008
-- Determine the last child position
DECLARE @LastChildPosition HIERARCHYID
SELECT @LastChildPosition = MAX(HierarchicalLevel) FROM Employee_2008
WHERE HierarchicalLevel.GetAncestor(1) = @CTONode
INSERT INTO Employee_2008 (EmpName, Title, HierarchicalLevel)
VALUES ('Adil', 'TEST Manager', @CTONode.GetDescendant(@LastChildPosition, NULL))
GO
--Let's see the data in the table
SELECT EmpID, EmpName, Title, HierarchicalLevel, HierarchicalLevel.ToString() AS [Position] FROM Employee_2008
GO
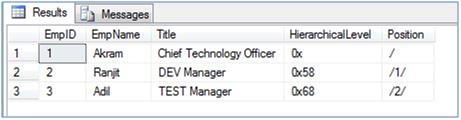
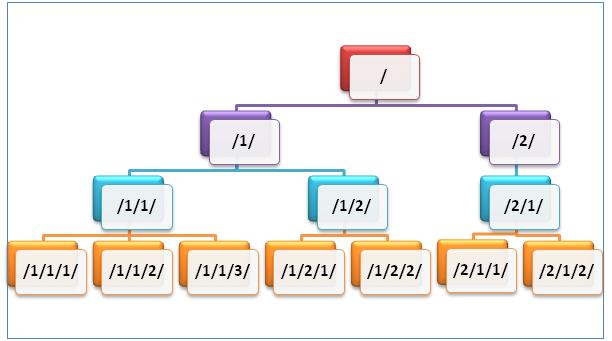
Looking at Position column in the result-set it is evident that the HierarchicalLevel column which is of type HIERARCHYID does not store the tree itself but rather the position of the node in the tree as given below diagram:
If you look at the scripts above, you will notice that you need to write several statements to just insert one record, why not to write a stored procedure for this; so that we need only single statement of calling stored procedure and get our record inserted by this stored procedure only.
CREATE PROCEDURE AddEmployee_2008
(@ReportsToID INT, @EmpName VARCHAR(255), @Title VARCHAR(255))
AS
BEGIN
-- Get the root node we wish to insert a descendant of
DECLARE @ReportsToNode HIERARCHYID
SELECT @ReportsToNode = HierarchicalLevel FROM Employee_2008
WHERE EmpID = @ReportsToID
-- Determine the last child position
DECLARE @LastChildPosition HIERARCHYID
SELECT @LastChildPosition = MAX(HierarchicalLevel) FROM Employee_2008
WHERE HierarchicalLevel.GetAncestor(1) = @ReportsToNode
INSERT INTO Employee_2008 (EmpName, Title, HierarchicalLevel)
VALUES (@EmpName, @Title, @ReportsToNode.GetDescendant(@LastChildPosition, NULL))
END
GO
--Let's add remaining nodes of tree using created stored procedure
EXECUTE AddEmployee_2008 2, 'Chandan', 'DEV Leader'
EXECUTE AddEmployee_2008 2, 'Sudeep', 'DEV Leader'
EXECUTE AddEmployee_2008 3, 'Ashraf', 'DEV Leader'
EXECUTE AddEmployee_2008 4, 'Dheeraj', 'DEV Engineer'
EXECUTE AddEmployee_2008 4, 'Hem', 'DEV Engineer'
EXECUTE AddEmployee_2008 4, 'Gaurav', 'DEV Engineer'
EXECUTE AddEmployee_2008 5, 'Uday', 'DEV Engineer'
EXECUTE AddEmployee_2008 5, 'Shayam', 'DEV Engineer'
EXECUTE AddEmployee_2008 6, 'Mukesh', 'TEST Engineer'
EXECUTE AddEmployee_2008 6, 'Sarfaraz', 'TEST Engineer'
--Here is final resultset
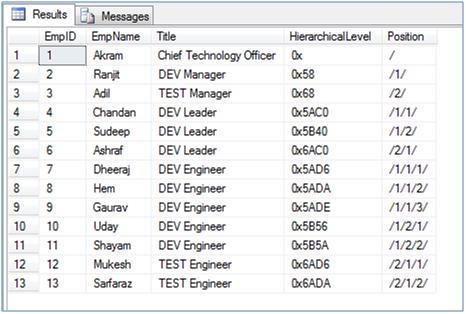
Now let's turn our attention from inserting records to retrieve it. The problem statement is:
- Get all employees who directly/indirectly report to a particular Employee.
- Get all managers of a given employee in all levels in the management chain until the root node.
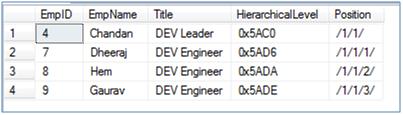
--Get all employees who directly/indirectly report to EmpID = 4 DECLARE @ReportsToID HIERARCHYID SELECT @ReportsToID = HierarchicalLevel FROM Employee_2008 WHERE EmpID = 4 SELECT EmpID, EmpName, Title, HierarchicalLevel, HierarchicalLevel.ToString()AS [Position] FROM Employee_2008 WHERE HierarchicalLevel.IsDescendantOf(@ReportsToID)= 1
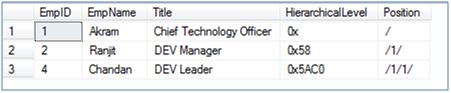
--Get all managers of a given employee(EmpID=4) in all levels in --the management chain until the root node SELECT @ReportsToID = HierarchicalLevel FROM Employee_2008 WHERE EmpID = 4 SELECT EmpID, EmpName, Title, HierarchicalLevel, HierarchicalLevel.ToString()AS [Position] FROM Employee_2008 WHERE @ReportsToID.IsDescendantOf(HierarchicalLevel) = 1
Now let's see the last example of HIERARCHYID here. The requirement is Dev Lead Chandan has left the job so all his direct reports now will report to new Dev Lead Rakesh. To accomplish this task you need to write your script which will look something like this.
--Adding new Dev Lead EXECUTE AddEmployee_2008 2, 'Rakesh','DEV Leader' --Get the HierarchyID of New DEV Lead DECLARE @NewDevLead HierarchyID= (SELECT HierarchicalLevel FROM Employee_2008 WHERE EmpID = @@IDENTITY) --Get the HierarchyID of old DEV Lead DECLARE @OldDevLead HierarchyID= (SELECT HierarchicalLevel FROM Employee_2008 WHERE EmpID = 4) UPDATE Employee_2008 SET HierarchicalLevel = HierarchicalLevel.GetReparentedValue(@OldDevLead, @NewDevLead) WHERE HierarchicalLevel.IsDescendantOf(@OldDevLead)= 1 --Parent is considered its own descendant, so you need to exclude it AND HierarchicalLevel <> @OldDevLead
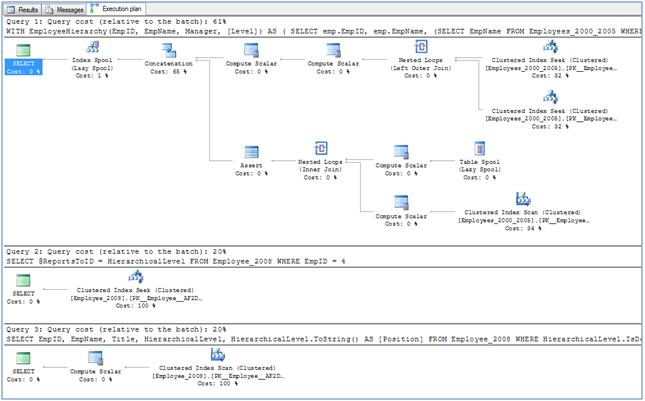
While doing performance testing of three approaches as discussed above for tree structure management in database table, I found that the approach we took in SQL Server 2000 of using recursive stored procedure was several times slower than the approach of using CTE of SQL Server 2005. Further CTE was almost 1.5 times slower than using the HIERARCHYID of SQL Server 2008. You too can see this performance difference by executing both the queries in a single batch and comparing relative cost of each approach's query(s).
Note: HIERARCHYID data type does not ensure uniqueness; I mean there's nothing stopping you from inserting a new row into the Employee table with the same position within the hierarchy as the other nodes unless you define unique constraint on the column.
The HIERARCHYID column can be indexed in two ways
Depth First Strategy: By default when you create an index on HIERARCHYID data type column, it uses Depth First Strategy. In a depth-first index strategy, rows in a sub tree are stored near each other. For example, all employees that report through a manager are stored near their managers' record.
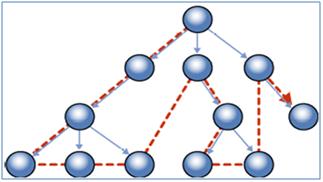
Depth First Search – Image source MSDN
As you can see in the image above, all sub-trees are stored near each other, and hence it is efficient for answering queries about sub-trees, such as "Find all files in this folder and its subfolders".
--Create a depth first index CREATE UNIQUE INDEX IX_Employee_2008_DFS ON Employee_2008(HierarchicalLevel) GO
Breadth First Strategy: A breadth-first strategy stores the rows at each level of the hierarchy together. For example, the records of employees who directly report to the same manager are stored near each other. Also to create a bread first index, the system needs to know the level of each record in table; for that purpose you can use GetLevel function of HIERARCHYID.
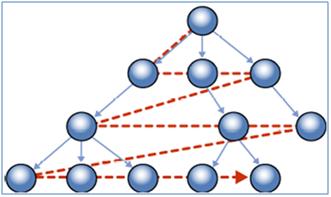
Breadth First Search – Image source MSDN
As you can see in the image above, all direct children of a node are co-located in Breadth-first index strategy, therefore it is efficient for answering queries about immediate children, such as "Find all employees who report directly to this manager".
--Create a computed column for level ALTER TABLE Employee_2008 ADD [Level] As HierarchicalLevel.GetLevel() GO --Create a breadth first index CREATE UNIQUE INDEX IX_Employee_2008_BFS ON Employee_2008([Level], HierarchicalLevel) ; GO
You can change the strategy as and when you want but the index needs to be dropped and then a new index has to be rebuilt. If the data is huge and the index is clustered then the table is converted to heap and then indexed again.
One interesting thing to note here is, the new HIERARCHYID data type has been introduced to SQL Server 2008 via a SQLCLR UDT (Common Language Runtime User Defined Type), or in other words, the data type has been coded as a C# class using the .NET Framework. If you want to explore it more, you can use Red Gate's .Net Reflector to dissemble the code as shown in image below:
References
SQL Server Books Online
- http://msdn.microsoft.com/en-us/library/bb677290(SQL.100).aspx
- http://technet.microsoft.com/en-us/library/bb677193.aspx
Large User Defined Types
With SQL Server 2000, you were allowed to create a TYPE, which is nothing but an alias of existing scalar data type of the SQL Server. There was no way to extend this scalar type and implement a real world entity as a data type of SQL Server. With SQL Server 2005, Microsoft integrated the .NET Common-Language Runtime (CLR) into the database engine itself, with that now you were allowed to create used defined type (UDT) and use it in SQL Server in a similar way as you use any in-built data type once assembly containing UDT is registered into the database. It was good starting point, but the problem with it is, the size of UDT is limited up to 8000 bytes only. SQL Server 2008 overcomes this limitation by introducing Large User Defined Type.
Large user-defined types allow users to expand the size of defined data types by eliminating the 8-KB limit. What I mean here is, SQL Server 2005 allowed for user defined types (UDTs) and user defined aggregates in the CLR up to 8000 bytes only, but SQL Server 2008 increases this all the way to 2GB. Similar to the built-in large object types that SQL Server supports, large UDTs can now reach up to 2 GB in size. If the UDT value does not exceed 8,000 bytes, the database system treats it as an inline value as in SQL Server 2005. If it exceeds 8,000 bytes, the system treats it as a large object and reports its size as “unlimited.”
This works especially well for scenarios involving the new spatial(GEOGRAPHY and GEOMETRY) data types (more about this in another article viz. “SQL Server 2008 - T-SQL Enhancements - Part - IV” of this series), which can be quite large in size.
The below image shows dissembled code of GEOGRAPHY data type which has been implemented as Large User Defined Type. You too can try your hands to dissemble your .Net assemblies using Red Gate's .Net Reflector.
A UDT's size is defined by the attribute SqlUserDefinedTypeAttribute.MaxByteSize as part of the type's definition. If this attribute is set to -1, the serialized UDT can reach the same size as other large object types (currently 2 GB); otherwise, the UDT cannot exceed the size specified in the MaxByteSized property.
[SqlUserDefinedAggregate(Format.UserDefined, MaxByteSize=-1,IsNullIfEmpty=true)]
References
Large CLR User-Defined Types - http://technet.microsoft.com/en-us/library/bb677285.aspx
Working with User-Defined Types in SQL Server - http://technet.microsoft.com/en-us/library/ms131064.aspx
Conclusion
The new HIERARCHYID data type opens up a new avenue to store hierarchical data inside a database table itself and makes developers' lives easier working with it. Not only this, it also improves performance compare to the approaches taken before SQL Server 2008.
The new Large User-Defined Types allow users to expand the size of defined data types by eliminating the 8-KB limit as it was there in SQL Server 2005, now SQL Server 2008 increases this all the way to 2GB.
In the next article I will discuss about the new FILESTREAM data type which enables SQL Server applications to store unstructured data, such as documents and images, on the file system and pointer of the data in the database and then I will talk of SQL Server 2008 spatial data types, which provide a comprehensive, high-performance, and extensible data storage solution for spatial data, and enable organizations of any scale to integrate geospatial features into their applications and services.
This article is the fourth in a series. The other articles in the series are:
- SQL Server 2008 T-SQL Enhancements Part - I (Intellisense)
- SQL Server 2008 T-SQL Enhancements Part - II (UDTs and TVPs)
- SQL Server 2008 T-SQL Enhancements Part - III (HierarchyID and Large UDTs)
- SQL Server 2008 T-SQL Enhancements Part - IV (Filestream)
- SQL Server 2008 T-SQL Enhancements Part - V (Spatial)

