

Although it has been 3 years since this article was published in August 2015 it is only in recent weeks that I have had time to revisit it. I am indebted to Solomon Rutzky and Marc28082 for providing constructive feedback which I have made tweaks to the original to incorporate their wisdom.
For those of you who look at the Apache commons code for the various algorithmns will notice that I have avoided an attempt to cater for alphabetic characters that are language specific such as umlauts, accents, graves and cedillas. My language knowledge is not sufficient to know the pronounciation rules for these characters and therefore how they should be catered for in the phonetic algorithms.
When I started the first article in this series I had no idea that it would produce enough material for three articles. My original idea (back in 2013) was to write an article demonstrating how the use of phonetic algorithms could help SQL Server provide a more effective search capability. It is a still an article I hope to write.
The article and some updates, as below:
When I first wrote my "Soundex - Experiments with SQLCLR" article I had a need for something slightly more sophisticated than the inbuilt SQL Server SOUNDEX function. I wanted to achieve three things:-
- Generate an all-encompassing phonetic function for SQL Server
- Put into practice Test Driven Development using techniques described in The Art of Agile by James Shore
- Experiment with string handling techniques I learnt from and ancient version of Ivor Horton’s Beginning Visual C++ book.
I wanted to get to the point where I could run a query as follows.
DECLARE@Phrasevarchar(max) ='The quick brown fox jumped over the lazy dog'SELECT'Soundex'AS Algorithm, dbo.LongPhonetic ( 0 ,@Phrase)ASResultUNIONALLSELECT 'Refined Soundex', dbo.LongPhonetic ( 1 ,@Phrase)UNIONALLSELECT 'NYSIIS', dbo.LongPhonetic ( 2 ,@Phrase)UNIONALLSELECT 'Daitch Mokotoff', dbo.LongPhonetic ( 3 ,@Phrase)UNIONALLSELECT 'Metaphone', dbo.LongPhonetic ( 4 ,@Phrase)UNIONALLSELECT 'Caverphone', dbo.LongPhonetic ( 5 ,@Phrase)-- Still TODOUNIONALLSELECT 'Cologne Phonetic', dbo.LongPhonetic ( 6 ,@Phrase)
My Soundex - Experiments with SQLCLR Part 2 article recognised a number of design issues and technical debt items that had to be addressed. It capitalised on the tests from the first article to refactor and address the technical debt.
Having invested a great deal of time and effort in my coding project I faced the painful fact that my approach was chasing down a blind alley. This was not an easy step to take. In the real world failing to recognise and react to such a situation leads to death march projects and a code base that no one wants (or is able to) maintain.
In this 3rd article I would like to share how I addressed my design flaw and my progress to date. Although I will detail some of the code I want to draw attention to the mistakes I made because there is far more to be learnt from mistakes than there is from following a sanitised success story.
At the time of writing (June 2015) I have not implemented all the phonetic algorithms into my function but my source code is available on GitHub should anyone wish to investigate further.
Learning a bit about GIT
My experience with source control stared with Visual Source (Un)Safe. Had a brief dalliance with IBM ClearQuest/Clear Case and then settled with SubVersion for a few years.
At the start of this project I knew nothing about GIT so decided to use this project as a learning opportunity.
I would summarise my experiences with the different source control systems as follows:-
Tool | Experience |
Source Safe | Got me off the ground and running with the concepts of source control. Loved the concept, learnt not to trust the implementation. Checkout and lock of files proves to be a problem in a larger environment where multiple developers needed to maintain the code base. |
IBM ClearQuest/Clear Case | Highly competent enterprise system. Can be made simple to operate but requires expert configuration in order to do so. Obviously has enterprise pricing. |
Subversion | Generally easy and intuitive to use. Still popular in the market place. Biggest pain points were branching and merging. The ability to script actions make it particularly useful in a continuous integration environment and for scripted deployments to specific environments. |
GIT | Although my experience is limited I am finding it quite straight forward to use. All the plus points from Subversion. Suits distributed collaborative working. Works well with peer to peer repositories. As I understand it GIT maintains incremental patches to files so merging is based on application of successive patches rather than comparisons between entire files and this has given it a reputation for handling branch and merging particularly well. |
The resources I found useful for GIT were
- https://msysgit.github.io/ The GIT Bash tool is particularly useful
- http://rogerdudler.github.io/git-guide/
Googling “GIT for dummies” will pull up a number of good resources.
Step One – Recognising Design Flaws
Before embarking on a new design there I wanted to make sure I had a proper understanding of the problems with my existing approach so I could design an appropriate solution.
For simple character substitution algorithms like Soundex the approach taken so far is valid. The only thing that changes from algorithm to algorithm is the values to which the letters get encoded.
Conceptually phonetic algorithms are the same and are illustrated in the diagram below.
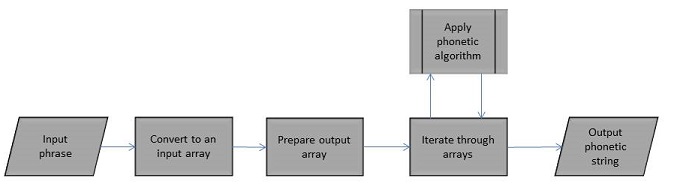
The flowchart symbol used for “Apply phonetic algorithm” is used to denote where a process is more complex than can be represented on the diagram. This certainly applies to algorithms such as NYSIIS, Daitch Mokotoff and Metaphone. They deal with n-gram substitutions and those substitutions vary depending on the position of the n-gram in relation to the position in the word and proximity to a vowel/non-vowel.
Algorithm | Character Substitution | Start Of Word | End Of Word | After Vowel | Combinations | Case Sensitive | Input < Output |
|---|---|---|---|---|---|---|---|
Soundex | Y | Y | |||||
Refined Soundex | Y | Y | |||||
CoognePhonetic | Y | Y | |||||
NYSIIS | Y | Y | Y | Y | Y | ||
Daitch-Mokotoff | Y | Y | Y | Y | Y | ||
Caverphone | Y | Y | Y | Y | Y | ||
Metaphone | Y | Y | Y | Y | Y | Y | |
Double-Metaphone | Y | Y | Y | Y | Y | Y |
An approach that relies on passing all parameters by reference is going to be complicated to write and complicated to maintain.
Step Two – High level design
After reviewing the resources I used for the phonetic algorithms I decided to choose an object orientated approach to the problem. The resources I used were as follows:-
- Nikita's blog was my original inspiration for experimenting with phonetic algorithms.
- The Apache Commons library contains actual Java implementations of the algorithms and adds ColognePhonetic
- Utilitymill.com host the utility I used to build up my test cases.
- Rosettacode.org provides many programming language implementations of common algorithms.
My thought process was as follows:-
- Refined Soundex is a type of Soundex algorithm
- The standard Soundex algorithm is (obviously) a type of Soundex algorithm.
- A Soundex algorithm is a type of Phonetic Algorithm.
The diagram below illustrates the class design I eventually came up with.
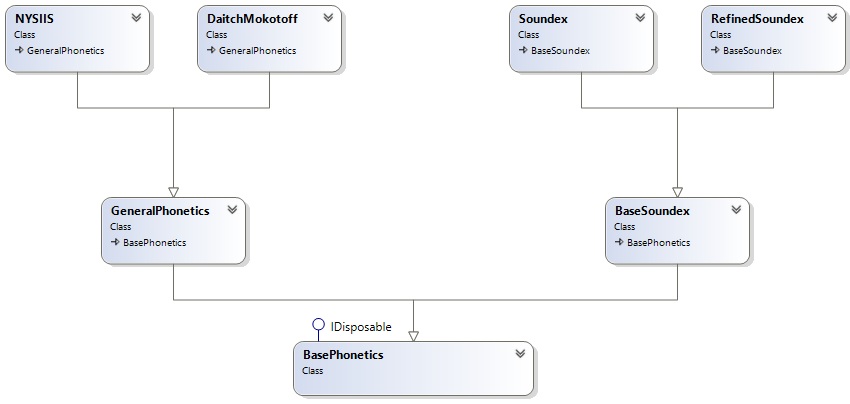
Class | Description |
BasePhonetics | Contains the properties and methods that are common across all phonetic algorithms. |
BaseSoundex | Inherits from BasePhonetics and contains the specialisms that are common to both Soundex algorithms |
Soundex & RefinedSoundex | Inherits from BaseSoundex and contains the specific character substitutions for the specific algorithm |
GeneralPhonetics | Inherits from BasePhonetics and contains functions and methods that are commonly used by the non-Soundex phonetic algorithms. |
NYSIIS & DaithMokotoff | Inherits from GeneralPhonetics and contains the specific implementations of the algorithm using the common functions and methods of the base class. |
Step Three – Adding a new “Project” to the solution
I decided to implement my class design in a separate “Class Library” project. This would mean that my Visual Studio solution would contain three projects.
Project | Purpose |
Phonetics | Holds the SQLCLR function that will be exposed to SQL Server |
PhoneticAlgorithms | The classes that will be instantiated by the SQLCLR function in the Phonetics project. |
PhoneticsTests | Holds all the unit tests that will be run against the code in both the Phonetics and PhoneticAlgorithms projects. |
Step Four – Refactoring code for BasePhonetics
All the unit tests I have written so far remain valid. Switching to a new object orientate design does not render them obsolete.
Similarly not all the code I have written so far needs to be thrown away. The hard work that has gone into defining how the Soundex algorithms can be implemented is still valid it simply needs to be broken out into the class structure shown above.
My intent was to write a test for my base class that would expect an input parameter and output exactly the same result. As the test framework does not allow tests to be written against undefined classes and/or methods I had to leave this until after I had implemented my class.
The first thing I did was to take the variables from my original code and create them as public properties in my new BasePhonetics Class as follows:-
public classBasePhonetics : IDisposable {public char[] _inputArray;public char[] _outputArray;public int_currentCharacterPosition = 0;public int_validCharacterPosition = 0;
As I had implemented the IDisplosable interface I had to implement the two Dispose methods to top & tail my class.
/// <summary> /// Mandataory for an iDisposable interface. /// </summary>public voidDispose() { Dispose(true); GC.SuppressFinalize(this); }/// <summary> /// Releases the arrays. This may be overkill depending on the garbage collector. /// </summary> /// <remarks>In general disposing of managed resources is unnecessary however the size of the arrays could /// be quite large so having an explicit cleardown may be beneficial.</remarks> /// <param name="disposing">Flag to indicate whether or not Dispose should remove resources.</param>protected virtual voidDispose(booldisposing) {if(disposing) { _inputArray = null; _outputArray = null; } } }
I decided that the class constructor was the place to allow the input string and handle the null or empty string occurrences
publicBasePhonetics(stringinputString) { _currentCharacterPosition = 0; _validCharacterPosition = 0;if(String.IsNullOrEmpty(inputString)) { inputString = " "; } _inputArray = inputString.ToUpper().ToCharArray(); }
I would also need a method to output the result
public stringReadOutput() {return new string(_outputArray).Trim(); }
I would need a method to build my _outputArray variable.
public virtual voidbuildOutputArray() { _outputArray =newString(' ', _inputArray.Length).ToCharArray(); }
At this point I should like to draw your attention to the keyword “virtual”. For Soundex and RefinedSoundex the output string can never be bigger than the input string so the code as written is fine. For Daitch Mokotoff and Metaphone the letter X can be transformed to 54 and KS respectively.
By declaring buildOuputArray as “virtual” then we have the option to override it in any inheriting classes.
- Abstract methods/function MUST be overridden and can have no implementation in their base classes
- Virtual methods/functions can have implementation and you have the option as to whether you wish to override them or not.
I needed a phonetic algorithm to apply which in this case simply copied the input array to the output array. Remember, it is going to be overridden in the specific phonetic classes.
public virtual void PhoneticAlgorithm()
{
_outputArray[_validCharacterPosition++] = _inputArray[_currentCharacterPosition];
}All phonetic algorithms share a “IsStartOfWord” function which returns a “True” value if a valid letter is either preceded by a space or that letter is in the first position in the input string.
public boolIsStartOfWord() {boolreturnValue =false;if(_validCharacterPosition == 0 || _outputArray[_validCharacterPosition - 1] == ' ') {if(char.IsLetter(_inputArray[_currentCharacterPosition])) returnValue=true; }returnreturnValue; }
And finally I needed the Iterate function to stitch it all together.
public virtual voidIterate() { buildOutputArray();while(_currentCharacterPosition < _inputArray.Length) { PhoneticAlgorithm(); _currentCharacterPosition++; } }
Now the base class is in place I can retrofit the tests to ensure everything is working as expected. For this I created a new test class called BaseTests. As the handling of zero length and null strings is handled in the base class I can add suitable tests hear and get rid of the previous tests that I used against the LongPhonetic function.
[TestMethod]public voidZeroLengthStringTest() { BasePhonetics bp =newBasePhonetics(""); bp.Iterate(); Assert.AreEqual("", bp.ReadOutput()); bp.Dispose(); }[TestMethod]public voidNullStringTest() { BasePhonetics bp =newBasePhonetics(null); bp.Iterate(); Assert.AreEqual("", bp.ReadOutput()); bp.Dispose(); }
I also added in the test of whether or not the input equalled the output.
[TestMethod]public voidBase_InputEqualOutputTest() { BasePhonetics bp =newBasePhonetics("DAVE POOLE"); bp.Iterate(); Assert.AreEqual("DAVE POOLE", bp.ReadOutput()); bp.Dispose(); }
Step Five – Refactoring code for the Soundex classes
As we have already said Soundex and RefinedSoundex differ only in the character substitutions. This means that the working body of the algorithm can go in the BaseSoundex class.
This means that the BaseSoundex class needs the following:-
- A constructor that simply calls the constructor in our base BasePhonetics class
- An Iterate method that overrides the BasePhonetics.Iterate method
- A PhoneticAlgorithm method that overrides the BasePhonetics.PhoneticAlgorithm method.
- A virtual SoundexChar function that will be overridden in the specific classes.
The constructor within the class appears as follows:-
public classBaseSoundex : BasePhonetics {publicBaseSoundex(stringinputString):base(inputString){ } …etc }
The virtual PhoneticAlgorithm method is copied from the preceding articles
public override voidPhoneticAlgorithm() {if(IsStartOfWord()) { _outputArray[_validCharacterPosition++] = _inputArray[_currentCharacterPosition]; } else {// If not a double occurrence of either characters or phonetic codesif(!(_validCharacterPosition==0 ||(_outputArray[_validCharacterPosition-1] == _inputArray[_currentCharacterPosition]) || _outputArray[_validCharacterPosition-1] == SoundexChar(_inputArray[_currentCharacterPosition]))) { _outputArray[_validCharacterPosition] = SoundexChar(_inputArray[_currentCharacterPosition]);// Only increment the validCharacterPosition if it is not a vowelif(_outputArray[_validCharacterPosition] !='0') { _validCharacterPosition++; } } } }
The Iterate method simply calls the BasePhonetics.Iterate method and then deals with the occasions where the Soundex encoding for words ending in a vowel results in a trailing zero.
public override voidIterate() {base.Iterate();if(_validCharacterPosition < _outputArray.Length&&_outputArray[_validCharacterPosition] =='0') { _outputArray[_validCharacterPosition] =' '; } }
The SoundexChar function is simply a virtual function that returns the character that is supplied to it. We will override this in the Soundex and RefinedSoundex classes.
protected virtual charSoundexChar(chara) {returna; }
The Soundex and RefinedSoundex classes have the following implementation
- A constructor that simply calls the base constructor
- An overridden SoundexChar function.
public classSoundex:BaseSoundex { public Soundex(string inputString) : base(inputString) { }/// <summary> /// For a given character return the raw SOUNDEX value. If the argument is not a letter then return a space. /// </summary> /// <param name="a">The character to be evalutated.</param> /// <returns></returns>protected override CharSoundexChar(Chara) {switch(a) { ...etcdefault: a =' ';break; }returna; } }
Step Six – Plugging it all in to the LongPhonetic function
There are two technical debt items I have to address in my LongPhonetic function before I begin altering the code.
SQLCLR function attributes
I did not include any functional attributes in my original code. I should have included the following:-
Attribute | Impact |
|---|---|
IsDeterministic | When set to true this tells SQL Server that for set values for the function arguments the output value will always be the same. If a SQL table has a computed column then IsDeterministic=true will allow us to place a unique index directly against that computed column. If IsDeterministic=false then the computed column must be persisted first. |
DataAccess | DataAccessKind=None is the default and indicates that no data will be accessed from SQL Server. There can be performance benefits from this setting. DataAccessKind=Read indicates that the local context can be used to read (but not insert, update or delete) data from SQL Server. |
IsPrecise | True indicates that floating point arithmetic is not used. |
SQL Types
Arguments using SqlString will use the collation sequence of the database from which they are called where as string arguments will default to the actual server CultureInfo settings. Typically SQL server defaults to case insensitive collations so SqlString will reflect that whereas strings are always case sensitive.
The SQL Types also present a consistent set of functionality such as an IsNull method and a Value property.
Even though my function forces upper case addressing some string handling issues I should have used the SQL types SqlString and SqlInt16 rather than string and short. Instil good habits first before considering deviating cases.
As SqlString is a struct rather than a primitive type we have to handle it properly to be able to pass it to our classes.
public partial classPhonetics { [Microsoft.SqlServer.Server.SqlFunction (IsDeterministic=true,IsPrecise=true,DataAccess=DataAccessKind.None)]public staticSqlString LongPhonetic(SqlInt16 PhoneticType, SqlString InputString) { BasePhonetics PhoneticObject;string_inputString;if(InputString.IsNull || InputString.Value.Trim() == String.Empty) { _inputString = " "; }else{ _inputString = InputString.Value; }switch(PhoneticType.Value) {case0: PhoneticObject =newSoundex(_inputString);break; case 1: PhoneticObject = new RefinedSoundex(_inputString); break; default: PhoneticObject = new Soundex(_inputString); PhoneticType = 0; break; } PhoneticObject.Iterate();returnPhoneticObject.ReadOutput(); }
The important point to note here is that our “PhoneticObject” is an instance of a BasePhonetic class. As all classes inherit an Iterate and ReadOutput function we can take advantage of polymorphism. That is, even though the object is a of type BasePhonetic it understands that it should implement the functionality expressed in the inheriting class.
NYSIIS
The NYSIIS algorithm introduces us to a number of challenges.
- Identify n-grams (combinations of letters) in different positions within a word (start, middle or end)
- Substitute n-grams for either an standardised n-gram or single letter.
I found a few problems with Nikita's blog
- Not all the example encodings in the article resulted from the rules described in the blog
- I believe that the “After vowel remove H and transform WàA” rule is incorrect.
- If vowels get transformed to ‘A’ and words ending in ‘AY’ get transformed to words ending in ‘Y’ does this mean that words that end in ‘Y’ with a preceding vowel should also lose the vowel and simply end in ‘Y’?
- Similarly if trailing “S” is discarded and trailing “A” is discarded does this mean that words ending in “AS” should have both discarded?
Due to this ambiguity I had to cobble together a hybrid from Utilitymill.com, Rosettacode.org and the blog post.
Phonetic Challenge One – How to represent the transformations
The NYSIIS transformations at the beginning of a word are as follows:-
Start of word | After transformation |
|---|---|
MAC | MC |
KN | N |
K | C |
PH PF | F |
SCH | S |
For the Soundex algorithms with their simple character substitution a switch statement was adequate however a better approach was needed to handle variable length n-grams.
I decided to use a multi-dimensional array and eventually arrived at the code shown below:-
/// <summary> /// When used for SQLCLR functions static arrays have to be declared as readonly if the consuming code /// is to execute in SAFE mode. /// </summary>private readonly static char[][][] _WORDSTART =newchar[][][] {newchar[][]{newchar[] {'M','A','C'},newchar[] {'M','C'} },newchar[][]{newchar[]{'K','N'},newchar[]{'N'} },newchar[][]{newchar[]{'P','H'},newchar[]{'F'} },newchar[][]{newchar[]{'P','F'},newchar[]{'F'} },newchar[][]{newchar[]{'S','C','H'},newchar[]{'S'} },newchar[][]{newchar[]{'K'},newchar[]{'C'} } };
NYSIIS also needs a equivalent construct for the word end and also for transformations that are neither start or end. I called these _WORDSTART and _WORDMIDDLE respectively.
What this gives us is an array containing two elements each of which can contain an array.
- [x][0] contains the letters to find
- [x][1] contains the letters to be substituted
Phonetic challenge Two – How to find an array within an array
I found that the .NET framework had an Array.Find method however this looks for elements in an array whereas I wanted to find an array within an array. In many respects I wanted the array equivalent of IndexOf.
What I needed was a function that would accept two arguments
- A starting position within the _inputArray
- The char array I wished to find which we will call arrayToFind
I decided that rather than a simple Boolean result I wanted my function to return the number of consecutive characters in ArrayToFind that were found in the _inputArray at the position specified as the starting position. This is illustrated in the diagram below.
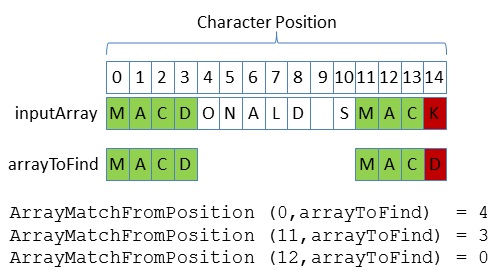
I originally implemented both the test and the code to pass the test directly within the NYSIIS class. After much trial and (mainly) error I eventually reached the conclusion that this function would be useful for all the phonetic algorithms I planned to implement so should belong in my “GeneralPhonetics” class.
I will describe my errors later but for now my tests and code eventually became the following: -
[TestMethod]public voidBase_FindArrayWithinArrayBadPosition() {char[] arrayToFind = {'M','A','C','D'}; GeneralPhonetics gp =newGeneralPhonetics("Macdonald Smack"); Assert.AreEqual(0, gp.ArrayMatchFromPosition(-1, arrayToFind)); gp.Dispose(); }[TestMethod]public voidBase_FindArrayWithinArrayNullArguments() {char[] arrayToFind = {'M','A','C','D'}; GeneralPhonetics gp =newGeneralPhonetics("Macdonald Smack"); Assert.AreEqual(0, gp.ArrayMatchFromPosition(0, null)); gp.Dispose(); gp =newGeneralPhonetics(null); Assert.AreEqual(0, gp.ArrayMatchFromPosition(0, arrayToFind)); gp.Dispose(); }[TestMethod]public voidBase_FindArrayWithinArray() {char[] arrayToFind = {'M','A','C','D'}; GeneralPhonetics gp =newGeneralPhonetics("Macdonald Smack"); Assert.AreEqual(4, gp.ArrayMatchFromPosition(0, arrayToFind)); Assert.AreEqual(3, gp.ArrayMatchFromPosition(11, arrayToFind)); Assert.AreEqual(0, gp.ArrayMatchFromPosition(12, arrayToFind)); gp.Dispose(); }
MISTAKE ONE: Trying to do too much at once
The mistake made was doubly stupid for having warned against it in the earlier articles in this series. James Shore recommended that we progress in small increments and these tests all generated unexpected errors when I implemented the code below to pass the tests
public intArrayMatchFromPosition(intcurrentCharacterPosition,char[] arrayToFind) {intx = 0;if(!(_inputArray == null || arrayToFind == null)) {for(x = 0; x < arrayToFind.Length; x++) {if(currentCharacterPosition < 0 || (x + currentCharacterPosition >= _inputArray.Length) || (_inputArray[currentCharacterPosition + x] != arrayToFind[x])) {break; } } }returnx; }
In implementing all the tests and tried to code to pass all of them at once I faced the task of having to identify the number of errors and their root cause. Had I proceeded in small increments I would have identified the problem much earlier on.
The error has nothing to do with the code or the tests but with the iDispose method in my BasePhonetics class.
The “Iterate” method causes the _outputArray to be built but in these tests we do not call the Iterate method. _outputArray will be null causing an exception when the Dispose method tries to call
Array.Clear(_outputArray, 0, _outputArray.Length);
We have to wrap our Array.Clear call up in a call to detect whether or not _outputArray is null
protected virtual voidDispose(booldisposing) {if(disposing) { Array.Clear(_inputArray, 0, _inputArray.Length);if(_outputArray != null) { Array.Clear(_outputArray, 0, _outputArray.Length); } } }
Returning to the ArrayMatchFromPosition function it caters for the following situations:-
- Where it is asked to find a null array
- Where it is asked to search within a null array
- When the starting position is invalid
- When the starting position or subsequent positions goes beyond the end of the _inputArray.
If any of the above occur or the characters in the _inputAray and ArrayToFind cease to match up the function exits returning a count of the matches made so far.
Phonetic Challenge Three – Replacing an array within an array
As stated earlier I originally implemented both ArrayMatchFromPosition and ArrayReplaceFromPosition in my NYSIIS class and latterly refactored them into the GeneralPhonetics class.
MISTAKE TWO: Testing End to end rather than isolated code.
I feel that the way in which I implemented TDD for NYSIIS was flawed. My approach was born out of the refatoring of my Soundex code and was as follows:-
- Create the NYSIIS class
- Implement the constructor, Iterate and PhoneticAlgorithm methods simply calling the base implementation
- Write tests against the LongPhonetic function.
In effect I was testing the end-to-end implementation rather than the isolated pockets of code. I feel that a better approach would be to create mock objects containing my functions and methods and allowing differing values to be passed in to test my algorithm. Once I had working code then I would have migrated it to the appropriate class.
The end result would have been the same but the journey would have been much easier.
The tests I devised for the start of a word eventually became the following:-
[TestMethod]public voidNYSiiS_Start(){ Assert.AreEqual("MC", Phonetics.LongPhonetic(2,"MAC")); Assert.AreEqual("MC", Phonetics.LongPhonetic(2," MAC")); Assert.AreEqual("N", Phonetics.LongPhonetic(2,"KN")); Assert.AreEqual("F", Phonetics.LongPhonetic(2,"PH")); Assert.AreEqual("S", Phonetics.LongPhonetic(2,"SCH")); Assert.AreEqual("F", Phonetics.LongPhonetic(2,"PF")); Assert.AreEqual("C", Phonetics.LongPhonetic(2,"K")); Assert.AreEqual("C", Phonetics.LongPhonetic(2," K")); }
During actual development I built the test conditions up one at a time to ensure that any unpredicted problems could be identified early. The code I eventually devised is shown below:-
public boolArrayReplaceFromPosition(char[] arrayToFind,char[] arraytoReplace) {boolreturnValue =false;if(!(arrayToFind == null || arraytoReplace == null || _inputArray == null || _outputArray == null)) {if(ArrayMatchFromPosition(_currentCharacterPosition, arrayToFind) == arrayToFind.Length && arrayToFind.Length > 0) {intx = 0;//The default Iterate method always adds one so we always add one less than the length of the // array we are trying to find._currentCharacterPosition += arrayToFind.Length-1;for(x = 0; x < arraytoReplace.Length; x++) { _outputArray[_validCharacterPosition + x] = arraytoReplace[x]; } _validCharacterPosition += arraytoReplace.Length; returnValue =true; } }returnreturnValue; }
The functionality is actually quite simple:-
- Make sure that all the required parameters and properties are available
- If the desired ArrayToFind is identified then increment the position in our _inputArray to get past the ArrayToFind
- Write out the replacement array into the _outputArray
- Increment the position in our_outputArray ready for the next replacement
Phonetic Challenge Four – Overriding the NYSIIS PhoneticAlgorithm method
I had to think through the order of precedence for dealing with the different n-gram positions within a word.
Clearly the first step was to implement the start of word substitution in order to satisfy my NYSIIS_Start test.
The word start processing should do the following:-
- Detect that there was actually a start of word
- Scan through the list of substitutions in my _WORDSTART array until a match is found then apply that substitution
- If no substitution could be found then simply accept the first letter of the word.
Once the start of a word has been handled the next thing to address would be whether the remaining characters in a word had an exact match in the _WORDEND substitutions. Word end processing should do the following:-
- Loop through the list of substitutions in _WORDEND until a match is found.
- If the character position after the match is beyond the end of the inputArray or the next character beyond the match is a non-letter then we should carry out the word end substitution and break out of the loop.
- If there is a match but it is not at the end of the word then repeat the process using the next _WORDEND item until there are no more items remaining.
If neither the Word start or end processing identified a substitution then we would simply use the _WORDMIDDLE substitutions and if that in turn produced no matches then I would simply copy the untransformed character to my output array.
Within my LongPhonetic function I added the following case statement to the body of the switch function.
case2: PhoneticObject =newNYSIIS(_inputString);break;
This would allow my NYSIIS_Start test to run against my actual NYSIIS class.
After creating the code to pass the NYSIIS_Start() tests I began a cycle of creating tests, code to pass those tests and then refactoring that code when I spotted code duplication.
Phonetic Challenge Five - Short circuiting array comparison
I started to look ahead to the substitutions that would need to be made in the other phonetic algorithms. It struck me that there were a large number of n-grams to be compared and for efficiency sake I should look for a means of short-circuiting the comparison. As a requirement this could be expressed as follows:-
- For word end comparison only consider those substitutions that are exactly the length of the number of remaining letters
- For other comparisons only consider those substitutions that are shorter in length than the number of the remaining letters
To do this I needed a property to store and a function or method to work out what position within the input array the end of the current word.
This optimisation only makes sense for the non-Soundex algorithms therefore I decided to put it within the GeneralPhonetics class.
At the class declaration I added a new private property and a readonly public property
private int_WordEndPosition = 0;/// <summary>/// Returns the character position of the current word. /// </summary> /// <remarks>Where the supplied position is negative then the start of the array will be assumed.<br /> /// Where the supplied position is at the end of the array then the last position in the array will be assumed.</remarks>public intWordEndPosition {get{return_WordEndPosition; } }
/// <summary> /// Iterates forward from the current string position until a letter is found. /// From that point the algorithm iterates forward until the next non-letter is detected and records the position of the last /// character of the word. The algorithm will work where the end of the string is the last letter /// </summary> /// <param name="currentCharacterPosition">The starting position within the inputArray parameter from which the end of word will be calculated.</param> /// <returns>The character position of the last letter of the word from the starting position.</returns>public voidGetWordEnd(intcurrentCharacterPosition) {intx = currentCharacterPosition < 0 ? 0 : currentCharacterPosition;if(x >= _inputArray.Length) { x = _inputArray.Length; }// Scan forward until you run until you hit a non-letter indicating end-of-word // or hit the end of the arrayfor(; x < _inputArray.Length; x++) {if(!char.IsLetter(_inputArray[x])) {break; } }if(x == _inputArray.Length){x--;}//Scan backwards until you hit a letter as this will be the end of the word.for(; x > 0; x--) {if(char.IsLetter(_inputArray[x])) { _WordEndPosition = x;break; } } }
- Should I make a call to GetWordEnd in each of the phonetic algorithms and duplicate code?
- Should I bite the bullet and make GetWordEnd part of the BasePhonetics class and couple it to the IsStartOfWord function
- Should I come up with a new function that would call both IsStartOfWord and if true then call GetWordEnd?
There are two principles to bear in mind
- Each function/method should have only one responsibility
- Designs should be loosely coupled and strongly cohesive
The solution I eventually chose was to change my BasePhonetics class slightly so my IsStartOfWord became a virtual function.
public virtual bool IsStartOfWord()/// <summary> /// For the non-soundex algorithms knowing the end of the word allows an small optimisation to short-circuit the evaluation of /// substitution n-grams. /// 1. At the end of the word only evalute those substitutions that are exactly the length of the number of remaining letters /// 2. For other substitutions only evaluate those substitutions whose length is not greater in length than the number of remaining letters. /// </summary> /// <returns>True if this is the start of a word.</returns>public override boolIsStartOfWord() {boolreturnValue =base.IsStartOfWord();if(returnValue) { GetWordEnd(_currentCharacterPosition); }returnreturnValue; }
The NYSIIS PhoneticAlgorithm code eventually evolved to the following:-
public override voidPhoneticAlgorithm(){ if (IsStartOfWord()) {if(!(ProcessWordStart())) { _outputArray[_validCharacterPosition++] = _inputArray[_currentCharacterPosition]; } }else{if(!ProcessWordEnd()) {if(!ProcessWordMiddle()) { _outputArray[_validCharacterPosition++] = _inputArray[_currentCharacterPosition]; } } } }
In my GeneralPhonetics class I realised that the principal mechanics for handling _WORDSTART and _WORDMIDDLE differed only in the substitution arrays used so I refactored the code to the following:-
public boolProcessWordStart() {returnProcessWordPart(WORDSTART); }public boolProcessWordPart(char[][][] pairSubsitution) {boolreturnValue =false; for (int i = 0; i < pairSubsitution.Length; i++) {if(pairSubsitution[0].Length <= 1 + WordEndPosition - _currentCharacterPosition) {if(ArrayMatchFromPosition(_currentCharacterPosition, pairSubsitution[0]) == pairSubsitution[0].Length) { returnValue = ArrayReplaceFromPosition(pairSubsitution[0], pairSubsitution[1]);if(returnValue) { break; } } } }returnreturnValue; }public boolProcessWordMiddle() {boolreturnValue =false; returnValue = ProcessWordPart(WORDMIDDLE);// We haven't found a match so either this is a non-transforming letter or a non-letterif(!returnValue) { _outputArray[_validCharacterPosition++] = char.IsLetter(_inputArray[_currentCharacterPosition]) ? _inputArray[_currentCharacterPosition] :' '; returnValue =true; }returnreturnValue; }
This made my optimisation completely transparent to the NYSIIS class.
Mistakes made along the way
I have glossed over quite a large part of my journey to implement NYSIIS and Daitch Mokotoff algorithms but at this stage I should like to draw attention to some of the mistakes I made.
I have already identified two mistakes:-
- MISTAKE ONE: Trying to do too much at once
- MISTAKE TWO: Testing End to end rather than isolated code
To add to these we have the following:-
MISTAKE THREE – Flawed definition of end-to-end
As my code compiled and passed all the tests that I had devised I believed that deploying to my SQL Server was going to be simple. Such hubris is all the more embarrassing because having peer reviewed Solomon Rutzky’s “Stairway to SQLCLR – Level 3: Security (General and SAFE Assemblies” I should have spotted that my static _WORDSTART, _WORDMIDDLE and _WORDEND arrays would cause problems.
SQLCLR checks against the use of static variables and forbids them in SAFE assemblies unless they are marked as readonly. Apparently there ways to fool the CREATE ASSEMBLY checks but those checks are there for a reason.
Read only static variables are the legitimate way to use static variables in SAFE assemblies as shown below.
private readonly static char[][][] _WORDSTART =newchar[][][] { …etc}
MISTAKE FOUR – Order of substitutions in _WORDSTART, _WORDEND and _WORDMIDDLE
This was another embarrassing one that didn’t become apparent until I started to implement the Daitch Mokotoff substitutions. It was pure luck that I didn’t run into the problem with NYSIIS.
To describe the problem in terms of the NYSIIS algorithm consider the handling of the _WORDSTART substitutions.
1. You write a test with the acceptance criteria for transforming words starting with K to starting with C
2. You run the test and it fails (you haven’t written the code yet or supplied the data to drive the code)
3. You add the ‘K’ and ‘C’ elements to the appropriate array
4. You implement the code and the test passes.
5. You write a test to handle words starting with ‘KN’ transforming to words starting with ‘N’
6. You run the test and it passes! At this point it should have failed.
What has happened is that the both the words that start with ‘K’ and ‘KN’ actually start with ‘K’ and so pass that test. Until you implement the data and the code to handle _WORDEND and _WORDMIDDLE the ‘KN’ test won’t fail
The solution is to handle the substitutions in order to the longest array first.
MISTAKE FIVE – Poor class design and use of utility classes
I created a class called NYSIISUtility to hold my _WORDSTART, _WORDEND and _WORDMIDDLE substitution arrays.
Having got NYSIIS working I used the same pattern with Daitch Mokotoff. However, having created a DaitchMokotoffUtility class I was faced with there being considerable duplicate code between NYSIIS and DaitchMokotoff.
The refactoring required to address this was quite involved. If there was duplicate code between NYSIIS and Daitch Mokotoff this suggested that the functionality belonged in the “GeneralPhonetics” class that they both inherit.
In order to have shared functionality that uses _WORDSTART, _WORDEND, _WORDMIDDLE then those arrays would also have to be in the GeneralPhonetics class but how could I have two completely separate implementations of _WORDSTART?
The answer was to implement blank arrays in the GeneralPhonetics class and implement virtual Property methods to expose them.
In NYSIIS and Daitch Mokotoff classes I would implement the actual _WORDSTART, _WORDEND and _WORDMIDDLE arrays. The inherited property methods would ensure that the appropriate underlying array was used.
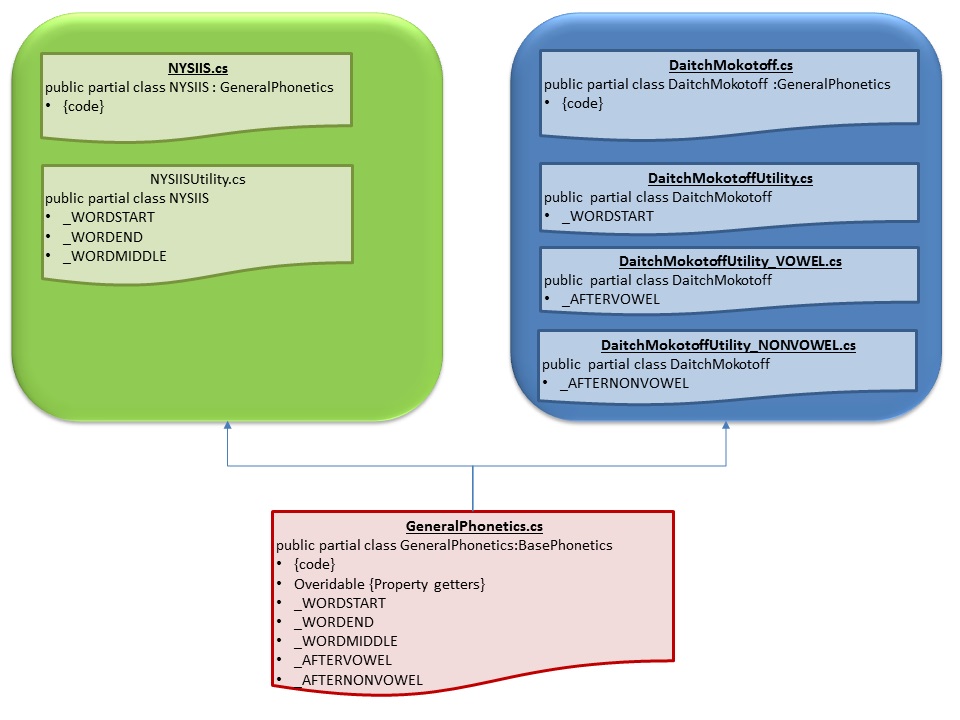
MISTAKE SIX:- Overlong class code
Datich Mokotoff in particular has a large number of substitutions to enact. If the _WORDSTART and associated arrays are added to the class then the class file becomes awkward to navigate.
The approach I took was to spread the implementation across multiple files and use partial classes as shown in the diagram below:-
Daitch Mokotoff
Once the NYSIIS algorithm has been implemented the Daitch Mokotoff algorithm introduces only minor changes to the base classes. The main change being the need to size the _outputArray to allow for substitutions that are longer than the n-gram they are replacing.
Changes made to the GeneralPhonetics class
- Add an IsVowel function that returns true when the supplier character argument was A, E, I, O or U.
- Add a property setter to allow the specification of a char array of characters requiring two characters to replace a single character. This is for cases such as the letter X which is replaced by 54 in Daitch Mokotoff and KS in Metaphone
- Add an ExtraLength function to double count characters specified as having two character replacements.
- Override the BuildOutputArray method to use the size of the input array plus the output from ExtraLength as the initial size of the _outputArray.
- Add a GetOutputLength method to retrieve the length of _outputArray. This would be used for testing purposes
The implementation of the algorithm itself was remarkably straight forward. The key thing (as with NYSIIS) was to identify the order of precedence for the different n-gram positions within the words.
Summary and next steps
When I look at the code and the approach that has evolved I see that what I have is a data driven phonetic framework. I expect the implementation of Metaphone and Caverphone to highlight some more gaps. However the architecture and techniques I have stumbled upon should cater for much of the implementation of those algorithms.
I did have some head scratching moments when it came to deploying my code to SQL Server. Publish and deploy seemed to run fine but not actually deploy my code or throw any errors. Once I had tracked down the problem to the autogenerated script containing “on error exit” I was able to find some meaningful error messages that allowed me to fix the problem.
I fully intend to implement further algorithms though I think I have covered the process of development thoroughly enough in these 3 articles.
My source code is available on GitHub - DaveJPoole/Phonetics.git
Any constructive criticism would be gratefully received but please bear in mind that even though my original intent was to produce an efficient code base for applying phonetic algorithms these are not functions I would use in a heavily stressed OLTP environment.

