

Using Track Changes in Microsoft Office and Full Text Search in Microsoft SQL Server 2005 to Share Database Operational Knowledge and Information
It is always wise for a newly hired DBA to identify and review any existing database administration and database related operational documentation straight away. Almost always, this provides some helpful information. If there is no documentation, expect the chaos to be obvious before anyone is able to even confirm that there is in fact no documentation. In fact, if there is no documentation, one recommendation could be to hit the floor fast and crawl to the nearest exit. The alternatives to learning by reading this a priori documentation is more time consuming, less complete, and orders of magnitude more stressful when the need is urgent. Especially if the goal is to keep the business viable by keeping the database application(s) up and running.
Every DBA knows that mucking around in a production database for research or reporting or other ad hoc internal uses compromises the primary purpose of the database server. The right place for ad hoc investigation and testing is on an offloaded database somewhere, a snapshot on the mirror maybe, a warm spare, or even a hot potato restore to a dev box or a desk top. The right place to poke around is never the production database. Usually, some formal structure is created to enable developers and analysts to use as fresh an image of the production dataset as is possible. This is good. It makes for a happy production database server and provides the business with ad hoc access when the need is compelling.
Unfortunately, a lower level of caution is demonstrated with the touches that a database server might see from non-DBA production support staff or even less experienced DBAs. Even routine activities on a production database server can pose some gigantic risks. Sure enough, every now and again in every shop someone validates the enormity of that risk. Every operator, whether operating a Commercial Space Shuttle service, the driver of the family car that won't start, or the data center night operator at a web company, just naturally wants to 'try it once more' when something doesn't go as expected and there is no structured way to determine what to do next. It may simply be human nature.
Flipping it on and off might not make a mess of things, and might appear to 'fix' the problem, but it almost never is the correct solution. The problem is sure to return and the symptoms may now be erased. You might compare the 'try it again' troubleshooting methodology to chasing the boogie man out from under the bed every night before lights out or having to reboot your machine six times a day while you are using Visual Studio to debug SQL Server stored procedures. It works, but you have to keep doing it: again and again. There has to be a better way.
In part due to the inadequacies of the 'try it again' support troubleshooting protocol, a collaborative spirit must develop among those responsible for the production environment. In the final analysis and regardless of who did what when, these people must work together to assure that the system meets some real or implied service level this may be implicitly or explicitly defined by the business. This is somewhat simplified and is intended to convey the principle that availability is always a major part of the common production environment goal and fundamental to the success of the business.
In the effort to reach this shared goal, documentation about the database, the database servers, and the application(s) data layer will emerge. Unfortunately, a document library tends to grows randomly more like weeds than a garden. It is helpful in most organizations to build structure around the database documentation. To create process so that documentation can be added, updated and removed as needed. The structure and process need not be complex, it need only meet the current needs of the pool of database administration and operations staff working to meet the common goal.
Many DBAs in this situation would enjoy the chance to build a new system that would include all the lessons learned from the production support efforts. Not many will get that chance. Instead, we must define and design adaptive mechanisms that will help us move step by step toward that system we would build if we could create something 'from scratch'. Explaining and educating others about such adaptive mechanisms will be instrumental to realizing the desired change intended by the mechanisms.
One valid action a DBA can take when that DBA knows something must change is to convince others in the IT organization and to get their backing not only for the need to change but for the way of change. This is fundamentally a system of peer review.
The basics of peer review are:
- One person among the peers originates a description of the correct way to proceed or a necessary change.
- Peers review the description, perhaps adding requirements the originator has overlooked or detailing alternatives, and in some way rates the original description.
- The originator responds to submitted feedback.
- The process iterates until a way forward that is suitable to all has been identified.
Another valid action is to make any existing database documentation more accessible to all production support staff. Obviously, getting things recorded is required, and then enabling all staff to search and query that body of documentation is essential to render the recorded information accessible to all in a timely manner.
How Microsoft Office could make you a better DBA
More SQL Server database documentation is done with a Microsoft Office (Office) product than with other desktop applications. There are many reasons for this. Most are centered on the fact that almost everyone reading this article is working from a Windows computer in a corporate setting. Because the platform is so wide spread in the business world, it is an attractive proposition from both the integration and support perspectives for the businesses to also use the Office desktop software suite. Most readers have a form of Office on their desktop computer.
In spite of the mind boggling space hoggling Office 2007 ribbons, it is still more annoying to have to try to figure out and then use any other desktop word processor or spread sheet than it is to use Office. Typically, Microsoft Word (.doc) and Microsoft Excel (.xls), the two most commonly deployed applications of the Office suite, are already installed on the each production support desktop machine. The exceptions to this are rare.
Irrefutable Truth: The documentation is far more important that the tools used to produce it.
It is difficult to imagine any shop that would mandate that all documentation be done in only Microsoft Word or Microsoft Excel or any other productivity tool. The quality of the documentation would suffer in many cases. Even worse, staff would use the limitations of the pre-determined tool to avoid needful documentation activities. If data modeling is already done with ERwin or Visio in the organization, continue to use that tool until you have a compelling reason to change. On the other hand, if the only way you'll ever find the time to create a shared picture of your database for others is by using SQL Server Management Studio (SSMS) or Visual Studio (VS) to auto-generate a database diagram and spend a half a day printing sections to produce Charts on Wall (COWs) then use the COWs. If the night shift guy in the NOC draws funny cartoons that explain his routine tasks, use them. If the organizational wiki is already the documentation repository then use it.
Database Documentation Standards & Best Practices
There are many reasons to use tools other than Microsoft Office to generate database administration and database related operational documentation. Each organization will have a different take on what is an appropriate documentation tool just as there is differentiation between organizations as to what is appropriate documentation. If there are no over-arching organizational documentation best practices and no existing database documentation standards or guidelines, then creating such instruments is very helpful if not absolutely necessary. Furthermore, a best practice delivered in a Word document is more enduring than if distributed in the body of an email and more sharable than if hand written on a note pad and taped to the wall. Perhaps a standard that certain methods and applications will be used as the default for documentation is appropriate? Something like:
Use the desktop applications licensed and installed across the organization for all database documentation when more appropriate alternatives are not available.
This is close to most organization's de facto documentation standards already. However, as you will hopefully see as this article develops, the transparency of de facto standards are inadequate and do not scale. All that is necessary to make a de facto standard accessible by all in the organization is to write it down: probably in a Word document.
This article's focus will be on the database related documentation that is appropriately stored as .doc or .xls files. This includes documentation created and used by Database Administrators, System Administrators, Network Operations Center (NOC) staff, perhaps even Database Developers, QA testers and other tiered production support folks in the organization. Everything from spelling out, "When to call the DBA in the middle of night" to the detailed user guide for the change control process to the disaster recovery plan might fall in to this category. Database documentation can also include coding standards, code review guidelines, heuristics for the nightly data warehouse load, etc. A DBA may also keep a variety of spread sheets – such as performance analysis, storage growth and scalability metrics - and procedural documents that may never be used by anyone outside the DBA group, or maybe used by only that DBA, yet provide information invaluable to the ongoing business concern.
Every DBA has at least a few documents to create, manage and maintain. In many cases a .doc or an .xls file is the most convenient tool to use to get the job done. This includes everything you need to know to do your job. Almost always these files will be useful for a long period of time. As a consequence of longevity, such documents often need to be updated to accurately describe the ever-changing data tier(s).
Defining the Use Case for Database Documentation
As documentation is created and maintained, contemplate these two questions:
1. Is there value in keeping the history of changes for this document?
In many cases the answer is found by answering three base questions:
a. Will there be a need to change this document?
b. Will there be a need to know what changes were made?
c. Will there be a need to know who made changes to this document?
The answer may often be "unknown". When possible, I recommend that you error on the side of caution and document even if there is uncertainty as to need. The alternative can be chaos during crisis.
2. Will there be a need to search the contents of this document? Documentation is by nature topical. The number of topics documented is in no way a fair representation of the manifesting problems or issues that may be encountered. On the other hand, topical organization of documentation is valid and useful. Most often, the topic will be the way documentation is identified as interesting. In addition, the ability to search the contents of all documents for a common word or phrase is appropriate, especially when the need is urgent and there is no topic directly matching the manifesting symptoms of an unexpected problem.
Here's where it get's interesting.
Expanding those two questions to include the business reasons for database documentation in general, the questions are more like:
1. Should this document be peer reviewed?
2. Will others use this document?
Narrowing those two questions to include only .doc and .xls files, the questions can be re-phrased as:
1. Should I enable Microsoft Office Track Changes capabilities for this document?
2. Should I enable Full Text Search of this document?
The next section of this article will narrow the focus to the first of these latter Microsoft Office specific forms of the need questions. Then the discussion will switch to the Full Text Search question. The Full Text Search information is appropriate for almost all other file based methods of recorded documentation.
Microsoft Office Track Changes
I was first indoctrinated to working with the Track Changes feature of Office while working on some material for publication. The publisher required that all content be submitted in their .doc template with "Track Changes" enabled. As the document made the rounds through the technical editors and back to me, each person's comments, recommendations, and changes could be seen. The sequence of who said what when was easy to see. It really helped the process. Filtering for only interesting changes was possible and viewing the most recent "final" version of the document without any of the change markup visible was a snap. Track Changes was definitely a bright spot in an otherwise grueling review experience.
Track Changes is a way to keep track of who made what changes when. Track Changes does not provide or enforce security. It does not prevent, validate or suggest changes to the document. It does helps you work together as a team to make a better document. It creates accountability. It stores the complete history of the document in a single file.
There is a nice three part resource on using Track Changes on the Blog of Microsoft's Office Word Team written by Jonathan Baker I believe:
http://blogs.msdn.com/microsoft_office_word/archive/2007/11/09/see-below-for-real-title.aspx
Most can expect to become fluent in Track Changes in about 10 minutes after reading this blog entry. Then if you want to become the consummate Track Changes expert, spend another 10 minutes with:
http://blogs.msdn.com/microsoft_office_word/archive/2007/11/20/change-tracking-views-filters.aspx
And if you want to get really serious with Microsoft Word Document Protection and its cousin Microsoft Excel Work Workbook Protection to create more sophisticated Track Changes security scenarios check out the final installment in the Track Changes trilogy:
http://blogs.msdn.com/microsoft_office_word/archive/2007/12/07/who-can-change-what-when.aspx
If the shop is new to Track Changes, the recommendation is to hold off on looking at Document Protection and Workbook Protection for your database documentation. Go for smaller achievable changes. First introduce Track Changes; if there is need for protection then use it. Once Document Protection and Workbook Protection are in use, it may even be useful to get into the Information Rights Management (IRM) layer provided it has first been discussed and approved by the organization's IT security administrators.
Track Changes is quite helpful in understanding how a document changes. With Track Changes it's easy to see what changed in the documentation as a result of a recent hardware upgrade assuming the changes were added to the documentation – and what still needs to be changed or added. Furthermore, when everyone that uses a document knows that Track Changes is enabled and also understands how Track Changes works, the quality of the document almost magically goes up. There are at least two reasons for this.
1. Track Changes enables a simple peer review. Peer review is the act of subjecting work, research, procedures, and ideas to the scrutiny of others with the intention to uncover errors, omissions and mistakes. Peer review is a necessary precursor to back end and server side development, administration and operations activities. It happens whether it is at all formalized. It is many times more helpful to the success of the business when more formal and enduring.
2. When everyone is clear that the document can be changed at any time and that anything can be fleshed out later if needed, necessary revisions to documentation are more likely to happen. There is no reason to put off for the right person or set aside for approval, or any of the other Dilbert style list-o-reasons that documentation update have been avoided or ignored. Just as it happen in the political arena, a protocol laden change process will squelch necessary updates in short order. Instead, make it easier and low risk to update documentation when needed – and with higher personal risk (consequences) when not done - and documents will be updated more often.
Most of the documents we are talking about here are most valuable in their current – or last revised - form. Having the historical context of change can be helpful in troubleshooting and it can be an interesting metric when review time rolls around to measure who has been actively participating in documentation maintenance. However, track changes history is a secondary benefit to having the document at all. The most effective implementations of Track Changes enabled documentation will be very nearly transparent in a shop that currently has good documentation practices. If Track Changes is enabled and the "Final" tracking view is selected in Word, anyone making changes to the document will barely notice Track Changes – the ribbon parts change colors in the Tracking cell of the Word ribbon or the Changes cell of the Excel ribbon. That's about it.
Shops trying to implement documentation practices and Track Changes at the same time have it a little more difficult, yet should be expected to realize the double benefit with a bit of training and the support of management. In extension of that concept, a half hour training session on using Track Changes for all that will be expected to properly use the database documentation is wise. Periodic refreshers and lessons learned sessions are also beneficial.
With Track Changes there is little need for any other rules other than to limit access to a document to those that you want to be able to change the file. This file access security is not an additional requirement of Track Changes but should already be in place in any event. Database documentation should be considered confidential and should always be appropriately secured.
Do not put system documentation in locations accessible for general use. Using public shares to make the details of how you keep the database server up and running is not a good security practice. Even the worst, most inadequate documentation contains enough information to help someone with malicious intent. Always explicitly place access controls on the system documentation files - and on the database where the Full Text indexing is taking place as will be discussed below.
Why would we care about the historical context of documentation content anyway? There are actually a few good reasons. Track Changes, in the usage proposed, becomes a database operational metadata change monitoring tool. The document becomes a master copy. The notion of a central library of system documentation as a best practice is reinforced. The centralized peer reviewed copy of a document becomes authoritative much like the central source repository of the application.
Track Changes in Excel is but a shadow of the Word implementation. Easy enough to enable and helpful to show when formulae and data may have been changed to be sure. This is reasonable, because most of the database documentation kept in spreadsheets changes en masse. In many cases the durability – value over time – of spreadsheet data is low. Such volatile workbooks are poor candidates for Track Changes. When the data is durable Track Changes is almost always appropriate.
In figure 1 a spreadsheet with modified cell formulas is shown. The option to "highlight changes" has been enabled from the Track Changes drop down of the Changes ribbon cell. Changed cells show a small marker in the upper right corner of the cell, much like the comment marker that appears in the upper left hand corner of a cell when comments are added.
Hovering over one of the spreadsheet cells marked as changed shows the person that made a change, time of change, and the before and after values of the change (who did what when). Since the Office Blog doesn't go into Excel side of Track Changes much, it is worthwhile to take a few minutes to look at Excel's Track Changes a bit closer. Figure 1 show the Track Changes ribbon option selected with the "Highlight Changes…" option and the Accept/Reject Changes option both visible to the right at the bottom of the ribbon.
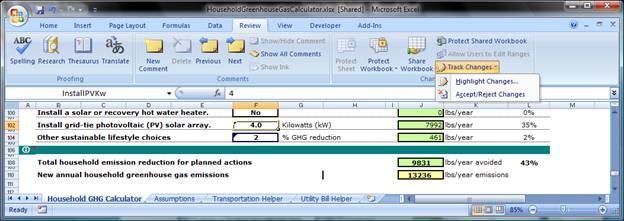
Figure 1 - Selecting Track Changes from the Excel Review ribbon.
As shown in Figure 2, A check box in the "Highlight Changes…" dialog must be enabled before changes are tracked.
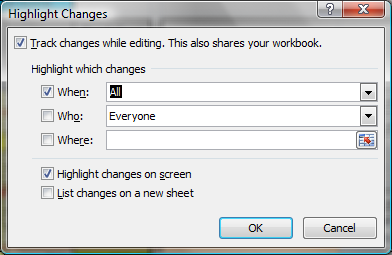
Figure 2 - The Highlight Changes Dialog from the Track Changes ribbon item
When the changes are accepted, the highlight and sheet are viewable within the spreadsheet. Cells with changes are marked in the upper right hand corner if "Highlight changes on screen" is checked. The Mark is similar to the comment mark that appears in the upper right hand corner of a cell. The full listing of all change history captured will be dumped to a new worksheet if "List changes on a new sheet" is checked.
When the changes are accepted, the highlight and sheet are viewable within the spreadsheet. Cells with changes are marked in the upper right hand corner if "Highlight changes on screen" is checked. The Mark is similar to the comment mark that appears in the upper right hand corner of a cell. The full listing of all change history captured will be dumped to a new worksheet if "List changes on a new sheet" is checked.
Selecting the "Accept/Reject Changes" option will allow pending changes to be reviewed and either accepted or rejected. Once accepted, the change becomes a part of the worksheet's embedded change history. This is different from the way Word treats accepted and rejected changes.
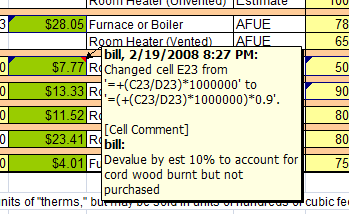
Figure 3 – Excel spreadsheet region. Note cell change markers in upper left hand cell corners. They appear after the "Highlight changes on screen" option is selected from the Track Changes ribbon option. Moving the mouse over a highlighted cell shows the changes tracked. If the cell also has viewable comments, the comments are shown in the same tooltip.
"List changes on a new sheet" shows a complete history of a cell while "Highlight changes on screen" will show only the most recent change to a cell.
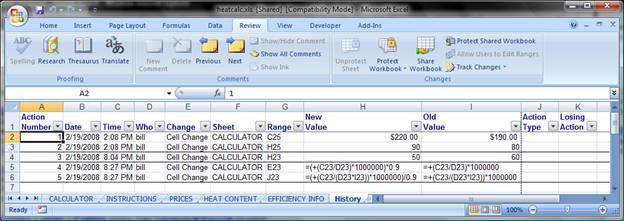
Figure 4 - A "History" worksheet (shown) is automagically added to – and automagically disappears from- an Excel Workbook when the "List Changes on a New Sheet" Check box is toggled in the "Highlight Changes…" dialog of the Track Changes ribbon item.
Track Changes provides an effective addition to database documentation. It can stimulate or initiate the peer review process for database documentation without adding additional work. Now to really make this body of documentation with track changes enabled work hard for you, all that is missing is a way for adequately trained people to look inside all of those documents quickly to find out which ones are relevant to the exigencies of the day. Enter SQL Server 2005 Full Text Search.
Searching Document Content
The more documentation generated, the more difficult it is for everyone to keep track of it all. Many people will use only a subset of the documentation. Not only will they have little interest in where other documents are, but there will also be an inadvertent added pressure from such folks to move the interesting documentation perceptively closer to them. Caution is advised. A splintered documentation set is much more difficult to maintain and manage than is a central library. One key to avoiding splintered documentation stores is an easily accessible central store.
Even with all the documents in a central library, finding all the documentation on a particular subject can remain elusive. Short of knowing the documentation forward and backward, it would be useful to search and query within the full documentation library for those documents with related references. Such search-ability will surely prove crucial more than once. A search that can change and learn over time will lead to consistently faster and more effective problem resolution as the database environment changes.
SQL Server 2005 Full Text Search
With the SQL Server 2005 Full Text Service (MSFTESQL), a mechanism is provided to build a full text index on many binary formatted files. Of particular note, Word 97-2003 documents .doc and Excel 97-2003 spreadsheets .xls are included in the number of document types that have built in full text filters. The 50 document types that can use this capability out of the box are listed in the system view [sys].[fulltext_document_types]. These filters extract the textual data from binary files when stored in VARBINARY columns and then submits only the textual portion of the document or spreadsheet or other qualified document type for full text indexing. Makes for a pretty slick search capability – especially when the scenario includes a need to search a large body of less frequently changing documents in the same context as the structured data. Full Text Indexes can be used to join, qualify and filter data alongside the other
Configuring Full Text Search in SQL Server 2005 is not difficult but is spread across too many configuration layers. Read the documentation, do the size planning, secure the service. The SQL Server 2005 Books Online topic "Performing Investigation and Clean-up Tasks for Full-Text Catalogs" contains unusual content for Books Online; providing an opportunity to hack around with Full Text Search in the Adventure works database. It is a good place to start if you are one of those DBAs with a hand-on or kinesthetic cognitive style and just getting started with Full Text Search or would like a broad spectrum refresher on the administrative fundamentals.
Many DBAs are reluctant to even consider Full Text Seach due to the poor usability of the Full Text Service and poor success with binary data types in previous SQL Server Releases. Such caution is sagacious. This author's experiences with the Full Text Engine and with binary data in SQL Server 2005 have been pleasant and successful. I encourage all to reconsider the viability of both Full Text Search and the VARBINARY(MAX) data type.
Full Text Search is available for all Editions of SQL Server 2005. SQL Server 2005 Express requires the Advanced Services download to get Full Text Search capabilities. Everything discussed here works the same on all Editions.
Full Text Service
The SQL Server BOL (September 2007) guidance is to use a non-privileged user account for the Full Text Service.
The logs generated by the Full Text Service are written to the MSSQL\Log folder for the instance. Be sure to look there if things don't seem right. There is an entire topic in SQL Server 2005 Books Online dedicated to the log file naming convention. I just order by data modified attribute and ignore the names. The truth is Full Text Search makes a bit of clutter in this folder. Do your best to ignore it.
SQL Server
Configure the SQL Server Service with a Windows user account. Grant that account read access to the document files to be indexed. If the documents are located on a network resource, use a domain account.
Enable CLR Integration and restart the SQL Server service to try the example discussed below.
There are several server configuration options specific to Full Text Search. Most include the literal "fulltext" in the option name. Refer to SQL Server 2005 Books Online for full details on each of these server configuration options. Two are worth mentioning now because they are somewhat arcane. The use of both is limited to Full Text Search.
-- change noise words to * to avoid runtime errors in CONTAINS EXEC [dbo].[sp_configure] 'transform noise words', 1 ; -- performance optimization for sorts in FREETEXTTABLE queries EXEC [dbo].[sp_configure] 'precompute rank', 1 ; GO RECONFIGURE ;
As is true it any time, change production server configuration options only after the impact of the change has been adequately evaluated for all the databases on the SQL Instance by testing.
The Database Master Key for the master database must be created in order to grant the CLR assembly the necessary CAS EXTERNAL_ACCESS permission. Specifically, before the assembly is deployed to the SQL Instance, An Asymmetric key must be created in the master database. Then a login is created that uses the key. The Login is granted EXTERNAL ACCESS ASSEMBLY. (Avoid the temptation to set the database to TRUSTWORTHY.)
The Asymmetric key is built from the strong name key used to build the assembly containing the two CLR stored procedures:
Use [master] GO CREATE ASYMMETRIC KEY SQLRunbookAsymmetricKey FROM FILE = '<path & name of strong name keypair.snk>'
Alternately, it can be build from the .dll created by building the assembly's project. In order to use the .dll the syntax changes slightly. The key is created FROM EXECUTABLE FILE rather than simply FROM FILE as must be stated when the strong name key pair is used. The key must use the assembly's .dll or the strong name file used to build the assembly. Another .dll or .snk
CREATE ASYMMETRIC KEY SQLRunbookAsymmetricKey FROM EXECUTABLE FILE ='<path & name of the assembly.dll>'
Regardless if the .snk or the .dll is used, the next step is to create a login from the key and give that login the necessary permission to load documents from the file system.
CREATE LOGIN SQLRunbookKeyLogin FROM ASYMMETRIC KEY SQLRunbookAsymmetricKey GRANT EXTERNAL ACCESS ASSEMBLY TO SQLRunbookKeyLogin
The Server Master Key and Database master key for the master database should both be backed up straight away. The risk is pretty low if only this login is relying on the database master key for it's encryption hierarchy. It is a fairly trivial matter to drop the procedures, assembly, login and asymmetric key and regenerate them if necessary. As a best practice however, having a backup of the encryption is something every smart DBA will always do.
Database
Full text is enabled by default in every user database when SQL Server 2005 is installed. Is it just me or does that seem a little backwards from the general trend toward off by default? It can be enabled and disabled using the Database Properties page in SQL Server Management Studio (SSMS) or the SQL Management Objects (SMO) IsFullTextEnabled database object property. I'm not seeing a way to toggle the flag using T-SQL. IT'S OK though, because I've never had to toggle the flag.
The state of the Full Text Enabled flag in the current database can be determined with the T-SQL:
SELECT DATABASEPROPERTYEX(DB_NAME(),'IsFullTextEnabled')
Full Text Catalogs are Database scoped, Full Text Catalogs can be placed on designated File Groups. The location of Full Text Catalog files can affect performance.
Full Text Indexes are schema scoped. A Full Text Index is placed in a Full Text Catalog. Each Table may have one (1) Full Text Index.
The DDL for Full Text Search objects is limited to objects: The Full Text Catalog and the Full Text Index
· CREATE/ALTER/DROP FULLTEXT CATALOG
· CREATE/ALTER/DROP FULLTEXT INDEX
The flesh of Full Text Search administration is visible in the ALTER FULLTEXT INDEX information. For example you can, rebuild or reorganize a Full Text Catalog much as you would a table or view index.
ALTER FULLTEXT INDEX ON table_name
{ ENABLE
| DISABLE
| SET CHANGE_TRACKING { MANUAL| AUTO |OFF }
| ADD ( column_name
[ TYPE COLUMN type_column_name ]
[ LANGUAGE language_term ] [,...n] )
[ WITH NO POPULATION ]
| DROP ( column_name [,...n] )
[WITH NO POPULATION ]
| START { FULL| INCREMENTAL | UPDATE} POPULATION
| { STOP| PAUSE |RESUME } POPULATION
}
The value in being able to turn an Index on or off to change the columns in an index ought to be indisputable. CHANGE_TRACKING is arcane. To be clear, it has no relationship to Microsoft Office Track Changes. It is a knob that allows control of when Full Text Indexes are update with known changes in the VARBINARY column. The default is to automatically update the index when the column changes. Keep in mind that even in Auto mode there can be some propagation delay between when the data is changed and the change is reflected in query results using the index. Full Text Search indexing is asynchronous. Best practice would be to "give it a minute". POPULATION is also a bit obscure. In essence, POPULATION is a way to throttle the overhead of Full Text Search. When Full Text background processing becomes a performance bottleneck, use POPULATION to optimize system performance by using INCREMENTAL or UPDATE populations. When system resources are needed more for another purpose, use POPULATION to control when POPULATIONactivities can and cannot be run.
The Full Text Search DDL syntax is slightly expanded from most examples when specifying a full text index on a filtered VARBINARY (MAX)column. A column in the same table as the VARBINARY (MAX) column must contain the type of the document. The TYPE COLUMN must be an exact match to a document type in [sys].[fulltext_document_types] and the document must be of the proprietary format identified in the table for that TYPE else the VARBINARY (MAX) column for the row will not included in the index.
CREATE FULLTEXT INDEX ON [dbo].[tSQLRunbookDocument] ( [Document] TYPE COLUMN [DocumentType] LANGUAGE 0X0 ) KEY INDEX [pkc_tSQLRunbookDocument__Id] ON [ftSQLRunbookCatalog] WITH CHANGE_TRACKING AUTO;
The TYPE COLUMN [DocumentType] attribute is a mandatory separate column that must inner join to a document_type in [sys].[fulltext_document_types]. The column must be in the same table as the VARBINARY (MAX) column. This should clarify that all qualifying document types can be stored in same table column. In fact, even non-qualifying document types can be stored in that column. However, only listed types will be indexed by the Full Text service.
IFilters
In testing on a default Full Text Search install on the SQL Express with Expanded Services platform using Microsoft Office 2007 documents (.docx) and workbooks (.xlsx) files it was observed that as non-listed document types are added to the column, they are ignored for all practical purposes by the Indexing engine and by all queries. One could try to impose an IFilter by mapping a file's extension to an existing filter – or more simply, change the files extension to the desired document type. An example might be to try to hook up the .docx Office 2007 format to the Office 2003 filter (offfilt.dll). Be advised that this won't work.
There is a supported Microsoft IFilter .dll for Office 2007 that will work with SQL Server 2005 and SQL Server 2008. Microsoft KB article 945934 (http://support.microsoft.com/default.aspx?scid=kb;en-us;945934) Provides a link for downloading these filters and instructions for installing the filter pack that includes the Office 2007 XML formats. This filter pack also includes .zip and .one support.
On a base SQL Server 2005 install, when the Full Text Search engine comes upon a new document type for indexing that is not listed, the following warning is written to the Full Text log.
2008-02-24 21:16:58.04 spid24s Warning: No appropriate filter was found during full-text index population for table or indexed view '[SQLRunbook].[dbo].[tSQLRunbookDocument]' (table or indexed view ID '8', database ID '129435535'), full-text key value 0x00000001. Some columns of the row were not indexed.
The insert is allowed. No error or warning is returned with the insert. Full Text predicated queries and rowset functions will simply have no data available, so will never find the non-listed row. Apparently, It is left to the application to verify that the documents type is in [sys].[fulltext_document_types] and decide what, if anything to do if it isn't.
Perhaps the new Office 2007 types and some other document types will be Full Text Search-able out-of-the-box with SQL Server 2008? They are included with Search Server 2008. PDF document type support out of the box would be nice too, but less likely to happen. In the SQL Server 2005 Books Online (Sept 2007) the "Full-Text Indexing Performance Slow Due to Filtering Process" topic talks about degradation due to cascading filters within the document. The example describes a plausible .doc with a .pdf embedded scenario. The thing is, there is no .pdf filter in my [sys].[fulltext_document_types]. For what it is worth, when recreated, the scenario the SQL Server 2005 Books Online page describes: Full Text Indexing of a .doc with an embed .pdf the content of the .pdf was indeed ignored.
When a test .doc with an embedded .pdf is inserted, and adequate time is allowed for the indexing, eventually this message will be written to the Full Text Search log file:
2008-02-27 17:43:49.72 spid24s Warning: No appropriate filter for embedded object was found during full-text index population for table or indexed view '[SQLRunbook].[dbo].[tSQLRunbookDocument]' (table or indexed view ID '373576369', database ID '8'), full-text key value 0x00000011. Some embedded objects in the row could not be indexed.
It is useful for this discussion to explain in greater detail the .pdf problem than is presented in the "Full-Text Indexing Performance Slow Due to Filtering Process" help document.
And we need to go even one level farther back, in order to provide an accurate context of how full text indexing of non-Microsoft proprietary document formats like the .pdf is done. Pardon me if this sounds a little too much like the future of the world according to Microsoft.
The technology used to build full text indexes is encapsulated by SQL Server, Exchange Server, Indexing Service, SharePoint Server, and Windows Desktop Search. In fact, these are all possible alternatives to using Full Text Search from SQL Server. SharePoint Server is the only strong alternative to using the Full Text Search capabilities of SQL Server in the database documentation scenario. If the organization already uses a SharePoint Server in the intranet and that SharePoint server can support the database documentation indexing use; then it will be a snap to get the database documentation on the SharePoint Server, Full Text Indexed and more useful than ever. SharePoint Server uses its underlying SQL Server to do the indexing and searches. SharePoint Server has the added power of being able to search the document titles and traverse document hierarchies when searching. Another big advantage for SharePoint Server is that the search interface is already built. SharePoint Server 2007 offers search administration tools and usability features that SQL Server cannot match alone. On the other hand, the results set of a custom query that truly exploits the power of a CONTAINS predicate and the knowledge and information in the database documentation is much more accessible from SQL Server.
To quote Swedish MVP Kenneth Wilhelmsson, "It Depends."
Indexing Server seems to be the guts of Full Text Search and the other servers mentioned. To wit, the IFilter is an Interface from the Indexing Service SDK.
An IFilter .dll can identify the textual data within the proprietary document structure(s) supported by that filter. Only the textual data will be considered for by Full Text Indexer if the filter works correctly. The same IFilter interface is supported by all the above mentioned Microsoft technologies. It is common in researching this topic to find references to building a single IFilter .dll that can is used by all servers listed. It is also common to see explicit instructions for installing third party filters. These .dlls are installed just like any other good old COM object: registered by CLSID. That's the good and the bad of IFilters all at once. It is a COM technology.
IFilters are COM objects. While we often hear that COM is not the database engines friend, perhaps IFilters are not as big a risk? After all the problems of COM based extended stored procedures, I admit I am a bit nervous on this point. The .pdf saga helps explain why.
There is in fact a .pdf filter available and it works with SQL Server. It must be downloaded from the Adobe web site.
http://www.adobe.com/support/downloads/detail.jsp?ftpID=2611
Then when you search the Internet you will find even Microsoft Folks recommending a way to register the Adobe .dll and use it inside SQL Server Full Text Search. Adobe provides no indication on the download page that it is intended for SQL Server. The page does list a number of IFilter based products Microsoft products that have been tested with the Adobe COM .dll. In the instructions you will learn that for any use the .dll must be registered on the machine. Enabling use in SQL Server requires a configuration change that opens the floodgates for all IFilters registered on the local system it would appear.
-- take all IFilter COM dlls the OS has to offer EXEC sp_fulltext_service 'load_os_resources',1 -- dispense with the formality of signatures EXEC sp_fulltext_service 'verify_signature', 0
The idea of full text indexing .pdf documents is useful, but running the two statements above on a production box seems risky without some testing and some runtime experience with the changes. In defense of IFilters, the Full Text Service is nicely isolated from SQL Server. I suspect the damage, if any, would be to performance and possibly index corruption rather than posing any risk to the data. However, the question of system stability cannot be ignored when 3rd party COM objects are introduced onto a server. COM objects in SQL Server memory space have been known to "leak" enough of that memory resulting in many an unhappy database server. Sure would be good to have something more than blind faith that what has been clearly discouraged as extended stored procedures is less perilous as a large file parser. It is difficult to not think of Full Text as an elaborate extended stored procedure.
The IFilter interface is well documented:
http://msdn2.microsoft.com/en-us/library/ms692577%28VS.85%29.aspx
There are a number of other Microsoft and 3rd party created IFilters. One of the more complete listing available is at:
http://channel9.msdn.com/wiki/default.aspx/Channel9.DesktopSearchIFilters
Full Text Query Predicates and Rowset Functions
Full Text Search is well documented. Implementing it is - for better or worse - much easier than understanding how it works. Figuring out how to fully exploit the CONTAINS() and FREETEXT() Transact-SQL predicates, and the CONTAINSTABLE and FREETEXTTABLE rowset functions is another story. The basic usage is a snap. Unfortunately, many of our impressions of Full Text Search are based on the easy to write predicate. The result was an unexciting search. The results from more tuned query configurations are dramatic. In terms of delivery of relevant content and query performance. Getting the most from the Full Text predicates and rowset functions quickly becomes a valuable skill. The person that can create a compelling and robust Full Text Search environment will quickly become an artist in demand. But then, who better to become the expert artisan on SQL Server Full Text Search than the friendly neighborhood DBA?
The questions asked of the database documentation search engine will aid in identifying more advanced CONTAINS predicates, as I imagine will be the tendency if the notion of enabling Full Text Search on the database documentation is perceived as useful. Many of those questions will revolve around how and when the full text index will be refreshed from the original document. Most such questions are exposed and answered by showing an example of how documents are loaded for indexing.
Searching the File System with a Database Query
A user interfaces is necessary for managing which documents will be full text indexed, which documents have changed since the last indexing, and which indexes need to be removed because the document is gone. A user interface is also needed for those that might query the indexed documentation for useful information. Since the navigation hierarchy for these two user interfaces is the same, it may be possible to combine the two functions if the reduced security is acceptable. Rather than force one approach or another, here we will build the file to database binary I/O stream necessary to obtain indexing data at the database. There are nice benefits to the database server side approach to Binary File IO:
- IO is abstracted from the application user interface
- Application front end is simplified. Can focus on usability and presentation
- The file system security for IO can be tightly defined.
- Asynchronous file IO operations for indexing
- Improved Unit Test pattern
Security is more easily managed by keeping the file IO at the database. The application security can determine who might initiate an operation. Windows Full Text service account, SQL Server Service, Database credentials and ACLs security around the file server secure the IO. Security will generally be less complicated. Be careful with this. Make sure the security implications for all changes are fully understood. A security scheme that allows SQL Server access to files by granting read/write access to file folder to Everyone when only the SQL Server service account or proxy account needs to use it is does indeed make things simpler. It also makes the file server less secure.
Rule of thumb: Give everyone exactly the permission(s) they need
Give the SQL Server service a user account. Probably a minimally privileged domain account is most suitable since the SQL Server and the file system location are unlikely to be on the same box. Consult with the network security administrator of the system for exact guidance. Give the service account the ability to read and write to a file system location dedicated to database documentation. Think about who else needs to access this folder and what access they need.
There are a few ways we could get a .doc or an .xls file loaded into a VARBINARY(MAX) column.
- Application
- ASP page
- bcp,
- BULK INSERT,
- CLR Integration
- host script file,
- Integration Services,
- OLE automation
- OPENQUERY,
- Web Service
- Windows Service,
- xp_cmdshell
Over any of these, CLR Integration stored procedures is particularly appealing because the result is simple and clean and the security is high. The code to make the document fully searchable is but a few lines. In fact even the stored procedures are simple in my ideal world so using a CLR assembly and requiring that all CRUD operations are done using T-SQL stored procedures is not a penalty but a benefit in terms of manageability and reusability.
The primary need when going after Full Text Search for documents is to get the documents into SQL Server for indexing. There is no requirement to get the document back out of SQL Server related to Full Text Search. Each time the document is changed the VARBINARY(MAX) column can simply be updated with the document's latest bytes. All that is required is a CLR Integration stored procedure to load the Document into SQL Server and a T-SQL stored procedure to insert the data into a table. Fully KISS compliant.
There is a likelihood that the copy of the document stored in the column might become the only usable copy of the document around. For this reason a tested stored procedure to export the document back to the file system is a good secondary feature. Precautions are in order to assure that this stored procedure is not misused. It should be an administrative tool. As will be seen in the sample code, coding this stored procedure to use a name that clearly identifies it as from the database for the exported document assures that the original document is never clobbered. In the example, the export date is suffixed to the original name.
Code Access Security (CAS)
The CLR assembly will require the EXTERNAL_ACCESS permission set. This provides slightly elevated CAS level. EXTERNAL_ACCESS has the same programming model restrictions and verifiability requirements – and the same restriction against calling native code - as the SAFE permission set. EXTERNAL_ACCESS simply allows SQL Server to interact with a slightly larger subset of the .NET Framework's base assemblies. The CLR stored procedure to bring the file into the SQL Server and the less used stored procedure to move the document from the SQL Server back to the file system are loaded to the same Assembly in the dbo namespace. Books Online provides a reminder that the CAS policies in effect are determined by three policy sets:
The security policy that determines the permissions granted to assemblies is defined in three different places:
- Machine policy: This is the policy in effect for all managed code running in the machine on which SQL Server is installed.
- User policy: This is the policy in effect for managed code hosted by a process. For SQL Server, the user policy is specific to the Windows account on which the SQL Server service is running.
- Host policy: This is the policy set up by the host of the CLR (in this case, SQL Server) that is in effect for managed code running in that host.
EXTERNAL_ACCESS is one of three possible permission sets that can be given a SQL Server CLR assembly: SAFE, EXTERNAL_ACCESS, UNSAFE. These permission sets are assigned in the Host policy.
The two sets of three and the poor transparency of implementation make this potentially confusing. Restated for clarity; the Machine Policy, the User Policy and the Host Policy collectively define the Code Access Security policy. Within the Host Policy are three permission sets, only one of which can and must be set for every SQL Server CLR assembly: SAFE, EXTERNAL_ACCESS, UNSAFE.
With that we have a described a business use case, a methodology, and enough background information to enable Full Text Search on the organizations database documentation.
The .NET Byte() array & SQL Server 2005 VARBINARY (MAX)
The best way to explain the mechanics of the import and export of an Office document to a SQL Server VARBINARY(MAX) column to a DBA is to show you the code. The demonstration code has been written in VB.NET, compiled in Visual Studio 2008 and deployed to a SQL 2005 Express Edition and a SQL Server 2005 Developer Edition instance for testing.
Setting up a working sample:
Enable SQL Server interaction with the file system. The easy but wrong way is to set to the Database as TRUSTWORTHY and make sure the database owner has EXTERNAL ACCESS ASSEMBLY permission for this sample. The proper way is to create a SQL Server Asymmetric Key from the compiled .dll assembly, create a login from that key, and grant the Login EXTERNAL ACCESS ASSEMBLY.
Security best practice is to not use the TRUSTWORTHY setting at any time on any SQL Server instance because it opens the server to malicious attack should someone load a malicious CLR assembly. It's the basic overkill scenario. When TRUSTWORTHY is used to remove the server trust security layer, all processes are given equal opportunity to exploit the weakness. When Permissions are reduced to the principal of least privilege, (e.g specific securables are granted to specific principals) the security risk is greatly reduced. The purpose of TRUSTWORTHY is not to enable CLR CAS per se, it is more like the impersonation version of database chaining. See the SQL Server 2005 Books Online topic, "Extending Database Impersonation by Using EXECUTE AS" for additional information on the role of server/database trust as determined by the database's TRUSTWORTHY setting affects Impersonation.
That's fairly close to the official story anyway. I have seen more than one of the most respected of SQL gurus say in one breath that TRUSTWORTHY should not be used to enable CLR EXTERNAL_ACCESS and in the very next breath pronounce it as the easiest way to enable EXTERNAL_ACCESS for demonstration purposes. The fact that TRUSTWORTHY works at al to allow EXTERNAL_ACCESS and UNSAFE CAS is a black mark for the SQL Server 2005 as a secure operating environment. Enabling 'proper' CLR security is quite easy. The logistics can be a minor challenge due to the need to feed the required Asymmetric Key either a VARBINARY(MAX) with an embedded strong name, a .dll containing a strong name key or a .snk strong name file. The included script includes a working example of using the VARBINARY(MAX). along with commented versions of the other two methods as aids should you decide to work through the sample using Visual Studio.
Create a database. I'm suggesting below you call it SQLRunbook. Hint: It will make trying this example much easier if you call it SQLRunbook.
use master;
CREATE DATABASE [SQLRunbook];
GO
ALTER DATABASE [SQLRunbook]
SET AUTO_CLOSE OFF
ALTER DATABASE [SQLRunbook]
SET READ_COMMITTED_SNAPSHOT ON;
USE[SQLRunbook] ;
Create a table in the database that meets the criteria covered above.
CREATE TABLE [dbo].[tSQLRunbookDocument] (
[Id] [INT] IDENTITY(1, 1) NOT NULL
, [File] [NVARCHAR] (450) NULL
, [Document] [VARBINARY] (MAX)NULL
, [DocumentType] [NVARCHAR] (8) NULL
, CONSTRAINT [qkn_tSQLRunbookDocument__File]
UNIQUE ([File])
, CONSTRAINT [pkc_tSQLRunbookDocument__Id]
PRIMARY KEY ([Id]));
Create a full text catalog and add an index for the table:
CREATE FULLTEXT CATALOG [ftSQLRunbookCatalog] ASDEFAULT;
GO
CREATE FULLTEXT INDEX ON [dbo].[tSQLRunbookDocument]
( [Document] TYPE COLUMN [DocumentType] LANGUAGE 0X0 )
KEY INDEX [pkc_tSQLRunbookDocument__Id] ON [ftSQLRunbookCatalog]
WITH CHANGE_TRACKING AUTO;
GO
Create a T-SQL Stored procedure to update the document insert a row into the table:
CREATE PROCEDURE [dbo].[pSQLRunbookDocumentUpsert]
( @File [NVARCHAR] (450)
, @Document [VARBINARY] (MAX)
, @DocumentType [NVARCHAR] (8))
AS
BEGIN
DECLARE @TextData [NVARCHAR] (2048);
SET XACT_ABORT ON;
BEGIN TRY
UPDATE [dbo].[tSQLRunbookDocument]
SET [Document] = @Document
, [DocumentType] = @DocumentType
WHERE [File] = @File
IF @@ROWCOUNT = 0
INSERT [dbo].[tSQLRunbookDocument] ([File], [Document], [DocumentType])
VALUES (@File, @Document, @DocumentType);
END TRY
BEGIN CATCH
RAISERROR('pSQLRunbookDocumentInsert Insert Failed',16,1)
END CATCH
END;
GO
Create a T-SQL stored procedure to get a row back from the table
CREATE PROCEDURE [dbo].[pSQLRunbookDocumentSelectByFile]
( @File NVARCHAR(450))
AS
BEGIN
SELECT [Id]
, [DocumentType]
, [Document]
FROM [dbo].[tSQLRunbookDocument]
WHERE [File] = @File;
END;
GO
Now from Visual Studio we need to create a CLR stored procedure to feed a file system document into the VARBINARY (MAX)column of the insert T-SQL stored procedure. To be consistent with the code samples provided and make it easier to kick the tires on the concepts here, create a SQL Server database project named clrspFullTextFile, add two new stored procedures named clrspFullTextFileImport and clrspFullTextFileExport in Visual Studio, and paste code from the samples over the top of the stub code generated in the newly create stored procedures.
The import stored procedure creates a buffer for bytes the size of the document, loads the file content into the buffer and then calls the insert stored procedure.
Option Explicit On
Option Strict On
Option Infer On
Imports System
ImportsSystem.Data
ImportsSystem.Data.Sql
ImportsSystem.Data.SqlClient
ImportsSystem.Data.SqlTypes
ImportsMicrosoft.SqlServer.Server
Imports System.IO
Partial Public Class StoredProcedures
<Microsoft.SqlServer.Server.SqlProcedure()> _
Public Shared Sub clrspFullTextFileImport(ByVal sFile As String)
Try
' get the cart before the horse to ReadBytes
Dim fInfo As New FileInfo(sFile)
Dim numBytes As Long = fInfo.Length
Dim fStream As New FileStream(sFile, _
FileMode.Open, _
FileAccess.Read)
Dim br As New BinaryReader(fStream)
Dim Document() As Byte = br.ReadBytes(CInt(numBytes) - 1)
br.Close()
fStream.Close()
Using cn As New SqlConnection("context connection=true")
If cn.State = ConnectionState.Closed Then
cn.Open()
End If
Dim cm As SqlCommand = cn.CreateCommand
cm.CommandText = "dbo.pSQLRunbookDocumentInsert"
cm.CommandType = CommandType.StoredProcedure
Dim FileName AsNew SqlParameter()
With FileName
.Direction = ParameterDirection.Input
.ParameterName = "@File"
.SqlDbType = SqlDbType.NVarChar
.Size = 128
.Value = sFile
cm.Parameters.Add(FileName)
End With
Dim Doc AsNew SqlParameter()
With Doc
.Direction = ParameterDirection.Input
.ParameterName = "@Document"
.SqlDbType = SqlDbType.VarBinary
.Size = -1
.Value = Document
cm.Parameters.Add(Doc)
End With
Dim DocType AsNew SqlParameter()
With DocType
.Direction = ParameterDirection.Input
.ParameterName = "@DocumentType"
.SqlDbType = SqlDbType.NVarChar
.Size = 8
.Value = fInfo.Extension.ToString
cm.Parameters.Add(DocType)
End With
cm.ExecuteNonQuery()
EndUsing
Catch ex As Exception
Throw (New Exception("(clrspFullTextFileImport) Exception.", ex))
EndTry
End Sub
End Class
The second CLR stored procedure fetches the VARBINARY(MAX)from the table using the T-SQL select stored procedure and then creates a file system document from it. It allows recovery of the original document from the database. Notice that the approach taken here is to slightly rename the file to make it clear where it came from, yet always overwrite the target file. That is by no means the only way it can be done. It works well for this example.
Option Explicit On
Option Strict On
Option Infer On
Imports System
ImportsSystem.Data
ImportsSystem.Data.Sql
ImportsSystem.Data.SqlClient
ImportsSystem.Data.SqlTypes
ImportsMicrosoft.SqlServer.Server
Imports System.IO
Partial Public Class StoredProcedures
<Microsoft.SqlServer.Server.SqlProcedure()> _
Public Shared Sub clrspFullTextFileExport(ByVal sFile As String)
Try
'send a little info about what is happening to the caller
Dim pInfo As SqlPipe = SqlContext.Pipe
pInfo.Send("Original file: " & sFile)
Using cn As New SqlConnection("context connection=true")
If cn.State = ConnectionState.Closed Then
cn.Open()
End If
Dim cm As SqlCommand = cn.CreateCommand
cm.CommandText = "dbo.pSQLRunbookDocumentSelectByFile"
cm.CommandType = CommandType.StoredProcedure
Dim DocFile AsNew SqlParameter()
With DocFile
.Direction = ParameterDirection.Input
.ParameterName = "@File"
.SqlDbType = SqlDbType.NVarChar
.Size = 450
.Value = sFile
cm.Parameters.Add(DocFile)
End With
Dim rdr As SqlDataReader = cm.ExecuteReader()
rdr.Read()
Dim DocId AsString = rdr.Item(0).ToString
Dim DocType AsString = rdr.Item(1).ToString
Dim Document(CInt(rdr.GetBytes(2, 0, Nothing, 0, _
Integer.MaxValue) - 1)) As Byte
rdr.GetBytes(2, 0, Document, 0, Document.Length)
rdr.Close()
cn.Close()
'MAKE EXPORT FILE NAME
'<file path/name>__DocumentId__<#>__ExportedFromDBOn__<date>
Dim NewFile As String
NewFile = String.Format( _
"{0}__DocumentId__{1}__ExportedFromDbOn_{2}{3}", _
Mid(sFile, 1, sFile.Length - DocType.Length), _
DocId.ToString, _
Now.ToString("yyyyMMddHHmmss"), _
DocType)
pInfo.Send("Exported to file: " & NewFile)
Dim fStream AsNew FileStream(NewFile, _
FileMode.CreateNew, _
FileAccess.ReadWrite)
fStream.Write(Document, 0, Document.Length)
fStream.Close()
EndUsing
Catch ex As Exception
Throw (New Exception("(clrspFullTextFileExport) Exception.", ex))
EndTry
End Sub
End Class
That creates the parts necessary to enable database documentation Full Text Search.
The next step is to load a couple of pieces of database documentation that you have in an Office format or any other document type. Remember, only if the type is found in [sys].[fulltext_document_types] will the document be indexed. This will allow some hands on experience with the Full Text predicates and rowset functions.
To provide examples of the calls to import and export data, consider that the file SQLClueRunbookTest.doc (in the Resources Section at the bottom) included with the article has been placed in the folder location C:\test and that the SQL Server Service account can read and write files to the C:\test folder. Note that this Word document contains an embedded .pdf for evaluation of the .pdf indexing IFilter if installed.
To load or import this document:
exec clrspFullTextFileImport 'C:\test\SQLClueRunbookTest.doc'
To Export a Document
execclrspFullTextFileExport 'C:\test\SQLClueRunbookTest.doc'
When the above sample document is exported, the SSMS results message window displays:
Original file: C:\test\SQLClueRunbookTest.doc
Exported to file: C:\test\SQLClueRunbookTest__DocumentId__19__ExportedFromDbOn_20080401180327.doc
Working through the sample will quickly provide confidence with the technical aspects of Full Text Search. It will also provide a ready feel for the power of Full Text Search.
The complete TSQL script for the sample is in the resource below. No need for Visual Studio if you use this script. The Assembly is scripted as a VARBINARY(MAX)from SSMS. The SQL Server security and configuration steps detailed above must be completed before the script will work. The script assumes that this document and the SQLClueRunbookTest.doc have been placed in folder C:\test. To clean up, just drop the database and remove the Asymmetric key after removing the login created from it in the master database. The necessary cleanup commands are found in the comments at the top of the sample script.
There are three queries with a CONTAINS predicate at the end of the script. When the script is first executed all may return no rows unless you have a really fast machine. After a few minutes, run them again. The first two should eventually return a result once the indexing operation is complete. The third should only produce a result if the .pdf IFilter is correctly installed.
Bill Wunder is a DBA/.NET Database Developer/Data architect with 15 years of SQL Server experience. He co-authored the SQL Server 2005 Bible (WILEY ISBN 0-7645-4256-7) writing the chapters "Programming CLR Assemblies within SQL Server", "Persisting Custom Data Types", and "Programming with ADO.NET 2.0". He served as the design Subject Matter Expert (SME) for Microsoft Official Curriculum courses 2781 "Designing Microsoft SQL Server 2005 Server-Side Solutions" & 2789 "Administering and Automating Microsoft SQL Server 2005 Databases and Servers". He developed a freeware SQLLiteSpeed log shipping for SQL Server 2000 that the owners of SQLLiteSpeed (DBAssociates, IMCEDA and Quest) have all directly provided to their customers. Bill has been a SQL Server MVP (2004, 2005, 2006), founded the Boulder SQL Server User Group (an Official PASS chapter), is a long time PASS volunteer and a former PASS DBASIG chair. Bill has authored over 100 SQL Server articles published at web sites such as sqlservercentral.com, swwug.org, www.pass.org, swynk.com, and his personal web sites at www.nyx.net/~bwunder and more recently www.bwunder.com. He is a long time speaker at local user groups, PASS conferences in North America and Europe, and swynk.com's Backoffice Administrator's conferences. Bill has provided SQL Server expertise at TechEd Europe and SQL Server Roadshows and SQL Server Release events. He developed the popular Bill Wunder's DDL Archive Utility: a DDL change tracking tool for SQL Server 7 and SQL Server 2000. He is currently finishing up a SQL Server 2005/SQL Server 2008 tool called SQLClue: an adaptive database change monitor that includes a SQL Configuration Repository with capabilities similar to the DDL Archive Utility extended for SQL Server 2005 and SQL Server 2008, a SQLRunbook that builds upon the knowledge and information sharing principles introduced in this article and a Reporting Services based Query Baseline and Analysis tool. SQLClue will run on any Edition of SQL Server 2005 including the freely distributed SQL Express Editon with Advanced Services, and also presents a well considered framework for strategic database monitoring. Bill can be reached by email at bwunder@yahoo.com. He invites all comments, inquiries and questions.

