

A typical project following any industry standard process for building Azure Data Factory (ADF) pipelines will have different environments as part of development lifecycle. They might be named Development, Staging, Production, and so on. This article describes an approach to save costs from running ADF pipelines using Triggers.
Typical ADF environments will have pipelines ingesting, transforming (Data flows/Notebooks) and loading data to targets. These are scheduled using different triggers and can be Started or Stopped. Apparently, the triggers run at scheduled frequencies if in the started status and do not run if stopped.
I created a test trigger for this article and in the below pictures it can be seen how the status appears when the trigger is stopped and started.
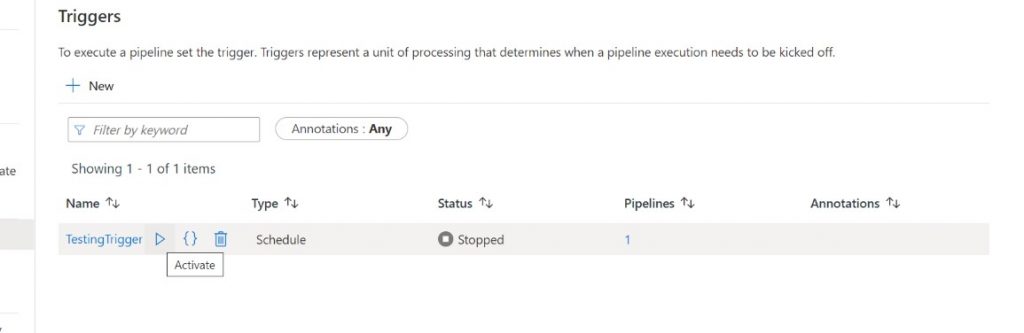
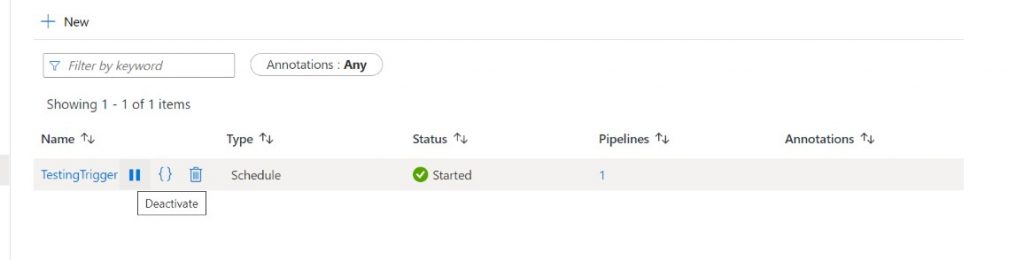
The pricing of Azure Data Factory triggers is based on number of activity runs and more details can be found here. If there are environments in the project setup purely for testing the deployments or doing ad-hoc manual job executions for quality checks (Development/Staging/Integration etc.), then technically all the triggers on them can be stopped. The pipelines can be manually run only when required, saving significant costs.
Below image shows how the triggers appear when they are all stopped in development environment which will be committed to source code repository. I configured Azure DevOps GIT in my ADF development environment as detailed here and is used for deploying to other environments.
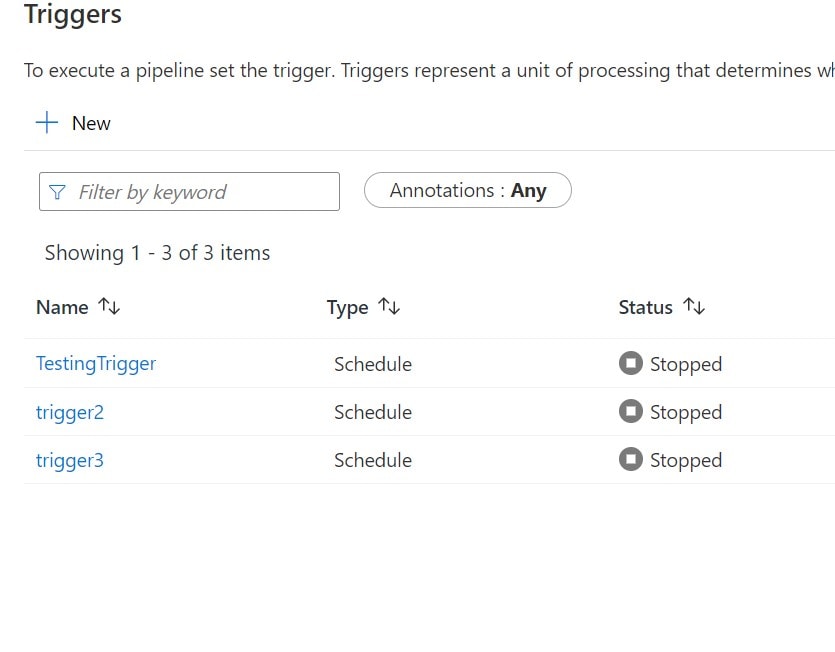
The problem with this idea of having all triggers stopped in development environment/branch arises during the deployment of code changes using ARM templates (Azure DevOps CI/CD), as in the official documentation here . During this deployment if the target environment has all the triggers started, but source has them all stopped, the deployment process considers it as a change in code. All triggers in target environment will be stopped to match the state of source as this is the purpose of deployment. This means triggers in target environment have to be manually started after the deployment.
This can be avoided by adding two PowerShell scripts in the deployment process. A PowerShell script to read all Triggers in the target Azure Data Factory that are Started and store in a temporary location (file/table). Execute this script before the actual Azure Data Factory deployment. Here is sample code to create list of active triggers:
Set-AzContext -Subscription $(Subscription)
$triggersADF = Get-AzDataFactoryV2Trigger -ResourceGroupName $(ResourceGroupName) -DataFactoryName $(DataFactoryName)
$AllActiveTriggers=$triggersADF| where-Object { $_.RuntimeState -eq 'Started'}|ForEach-Object{$_.Name}
$AllActiveTriggers | ForEach-Object{ Out-File -FilePath "$(System.DefaultWorkingDirectory)\Triggers.txt" -Append –InputObject $_}After the Azure Data Factory changes are deployed (which stops all triggers in target) execute another PowerShell script to start the triggers based on the previously created file. This is sample code to enable triggers based on this list:
Set-AzContext -Subscription $(Subscription)
Write-Host "$(System.DefaultWorkingDirectory)\Triggers.txt"
if(Test-Path -Path "$(System.DefaultWorkingDirectory)\Triggers.txt")
{
$TriggerNames= Get-Content -Path "$(System.DefaultWorkingDirectory)\Triggers.txt"
$TriggerNames | ForEach-Object {
Start-AzDataFactoryV2Trigger -Name $_ -ResourceGroupName $(ResourceGroupName) -DataFactoryName $(DataFactoryName) -Force
Write-Host $_
}
Remove-Item "$(System.DefaultWorkingDirectory)\Triggers.txt" -Force
}The deployment pipeline with all these steps will look something like what is shown in the image below.
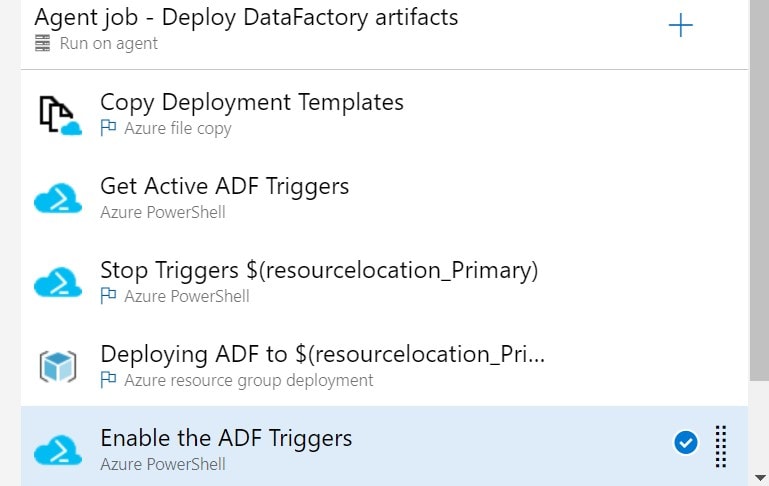
The only potential side effect to this approach would be jobs that have schedules at the time of deployment will not run (runs in progress will be unaffected). So, identifying a slot where no jobs are running is equally important.
Also, if this approach is followed and the Azure Data Factory set up uses self-hosted integration run time, the nodes can be downsized on such environments where triggers are disabled or the nodes can be started on demand to further reduce overall costs

