

This article will demonstrate the heterogeneous systems integration and building of the BI system and mainly talk about the DELTA load issues and how to overcome them. The main issue is: how can we compare the source table and target table when we cannot find a proper way to identify the changes in the source table using the SSIS ETL Tool?
Systems used
- SAP S/4HANA is an Enterprise Resource Planning (ERP) software package meant to cover all day-to-day processes of an enterprise, e.g., order-to-cash, procure-to-pay, finance & controlling request-to-service, and core capabilities. SAP HANA is a column-oriented, in-memory relational database that combines OLAP and OLTP operations into a single system.
- SAP Landscape Transformation (SLT) Replication is a trigger-based data replication method in the HANA system. It is a perfect solution for replicating real-time data or schedule-based replication from SAP and non-SAP sources.
- Azure SQL Database is a fully managed platform as a service (PaaS) database engine that handles most of the management functions offered by the database, including backups, patching, upgrading, and monitoring, with minimal user involvement.
- SQL Server Integration Services (SSIS) is a platform for building enterprise-level data integration and transformation solutions. SSIS is used to integrate and establish the pipeline for ETL and solve complex business problems by copying or downloading files, loading data warehouses, cleansing, and mining data.
- Power BI is an interactive data visualization software developed by Microsoft with a primary focus on business intelligence.
Business Requirement
Let us first talk about the business requirements. We have more than 20 different Point-of-Sale (POS) data from other online retailers like Target, Walmart, Amazon, Macy's, Kohl's, JC Penney, etc. Apart from this, the primary business transactions will happen in SAP S/4HANA, and business users will require the BI reports for analysis purposes.
Architecture Diagram:
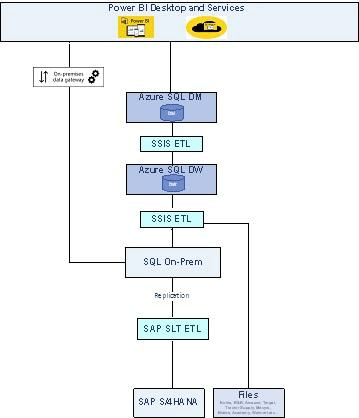
The source systems are multiple, like SAP S/4HANA (OLTP), Files, and Azure SQL (OLAP). The integration/ETL tools are SAP SLT and MS SSIS, and finally, the reporting tool is Power BI.
During this end-to-end process (from source data to reporting), there were several problems because of the heterogeneous systems. The main hurdles are duplicate records in the target system, Power BI reports, and users' inability to make the right decision at the right time.
The main reason is that we do not have a direct delta capture mechanism for the data coming from SAP S/4HANA. So all tables do not have timestamps, though they are there. Until SQL On-Prem (in the above diagram), the data will be maintained by SAP SLT correctly because SAP SLT will take care of the complex deletions in the source and adjust the data in SQL On-Prem. However, in outbound flow to Azure SQL, it is an SSIS tool and will not modify the data automatically.
According to the research, there are four methods for capturing the source data change:
- Timestamp-based modifications
- Database Triggering
- Compare the source and target tables to find the changes.
- Log-based database
In this article, I'm going to talk about the third scenario.
What are the reasons for selecting this approach? I have two:
- There is no way to find the changes in the source table if the timestamp field is not in the source table.
- Due to limitations on the source side, we cannot configure the DB triggers to capture the source changes.
The advantages of this approach are:
- Minimal reliance on the database management system
- To reduce loading time, choose Delta rather than full loads.
- Improve users' confidence while analyzing data using the reports.
- Simple upkeep
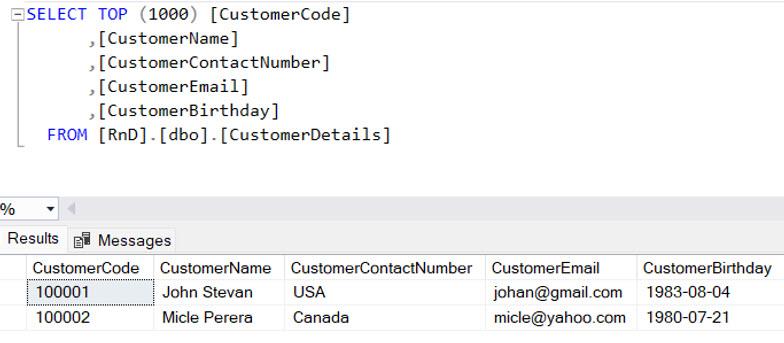
The main challenge of this approach is that it is difficult to use for a large-scale table. For example, below is the source table, and there is no proper method to identify the changes. So, follow the steps.
As a first step, we need to create an SSIS project and a package. Then I will explain how to configure the source connection.
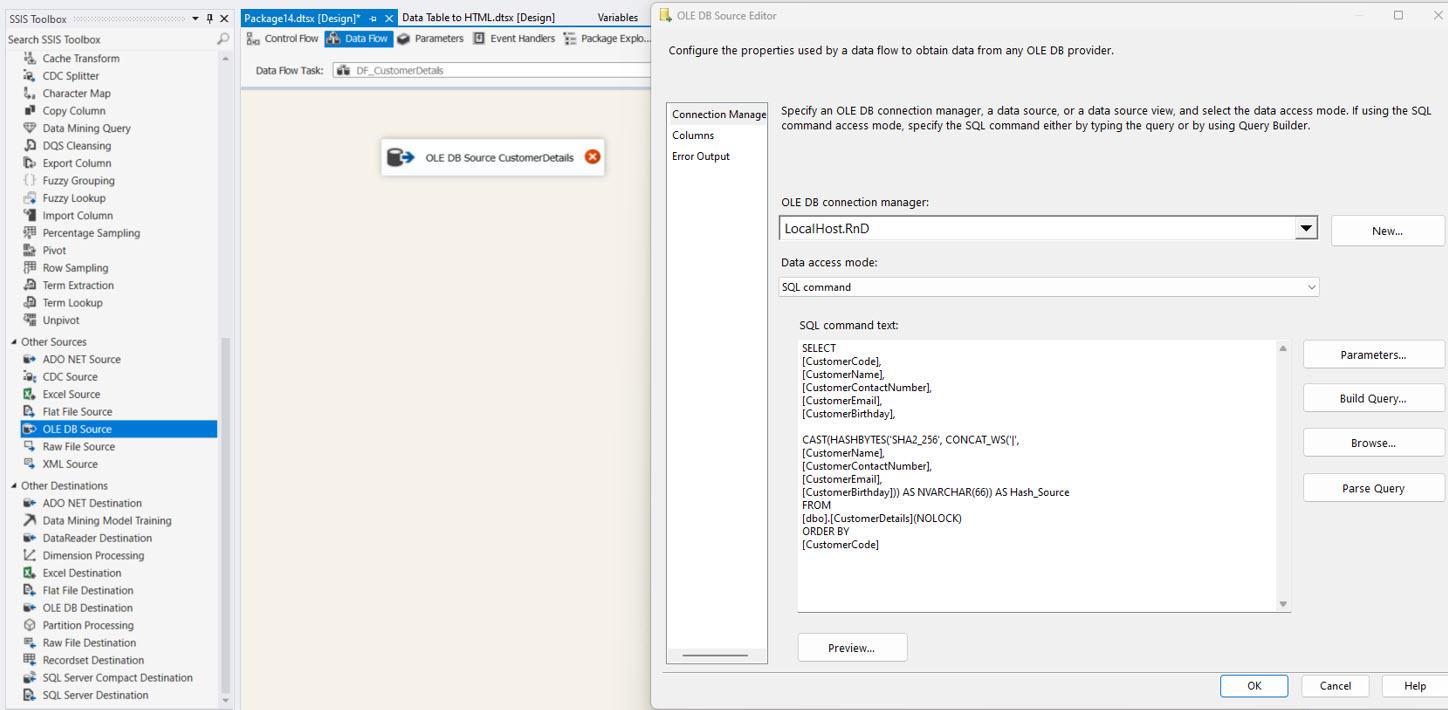
OLE DB Source for the source table: This is to bring the Source table data into the SSIS platform and the required configurations provided below. In the SQL command, we need to select all the columns necessary, and you can see how to use the HASHBYTES function to get the HASH VALUE for each record. And the dataset must be ordered using the unique or primary key. In this example, I used the primary key for ordering the dataset. And by using the NOLOCK keyword in the SQL command, we can prevent the table from locking.
Then OLE DB Source columns need to be sorted and configured in column order in the ADVANCE EDITOR window of the control. The following images explain the required changes.

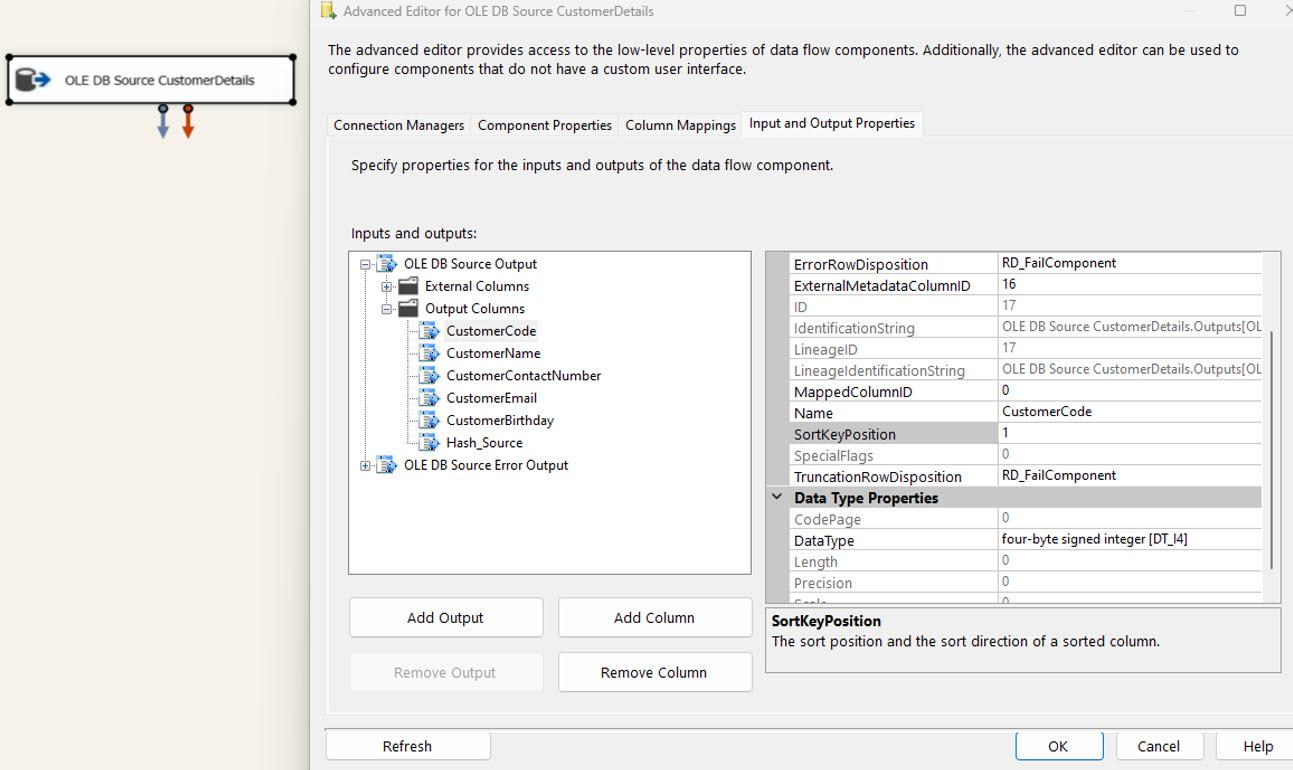
OLE DB source for the target table: We must follow the same steps observed in the SOURCE table. The only difference is that there is no need to select all columns; the UNIQUE KEY and HASH VALUE are both needed in the SQL COMMAND.

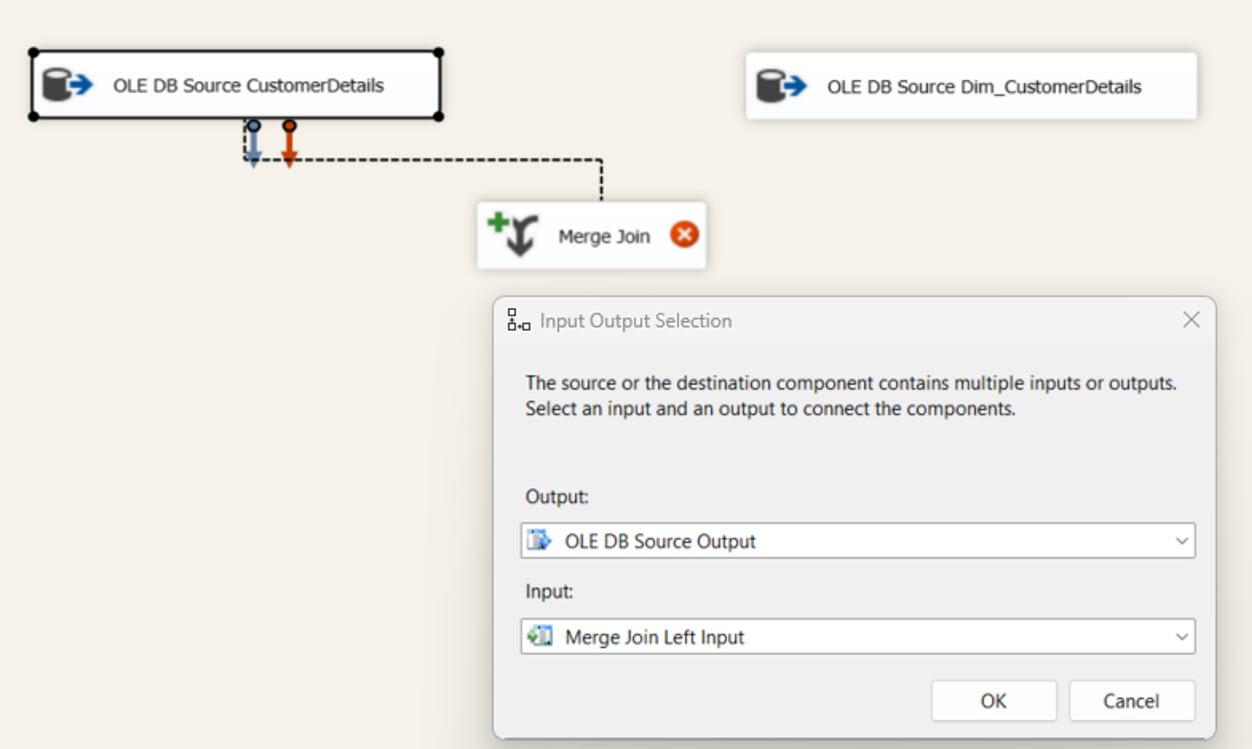
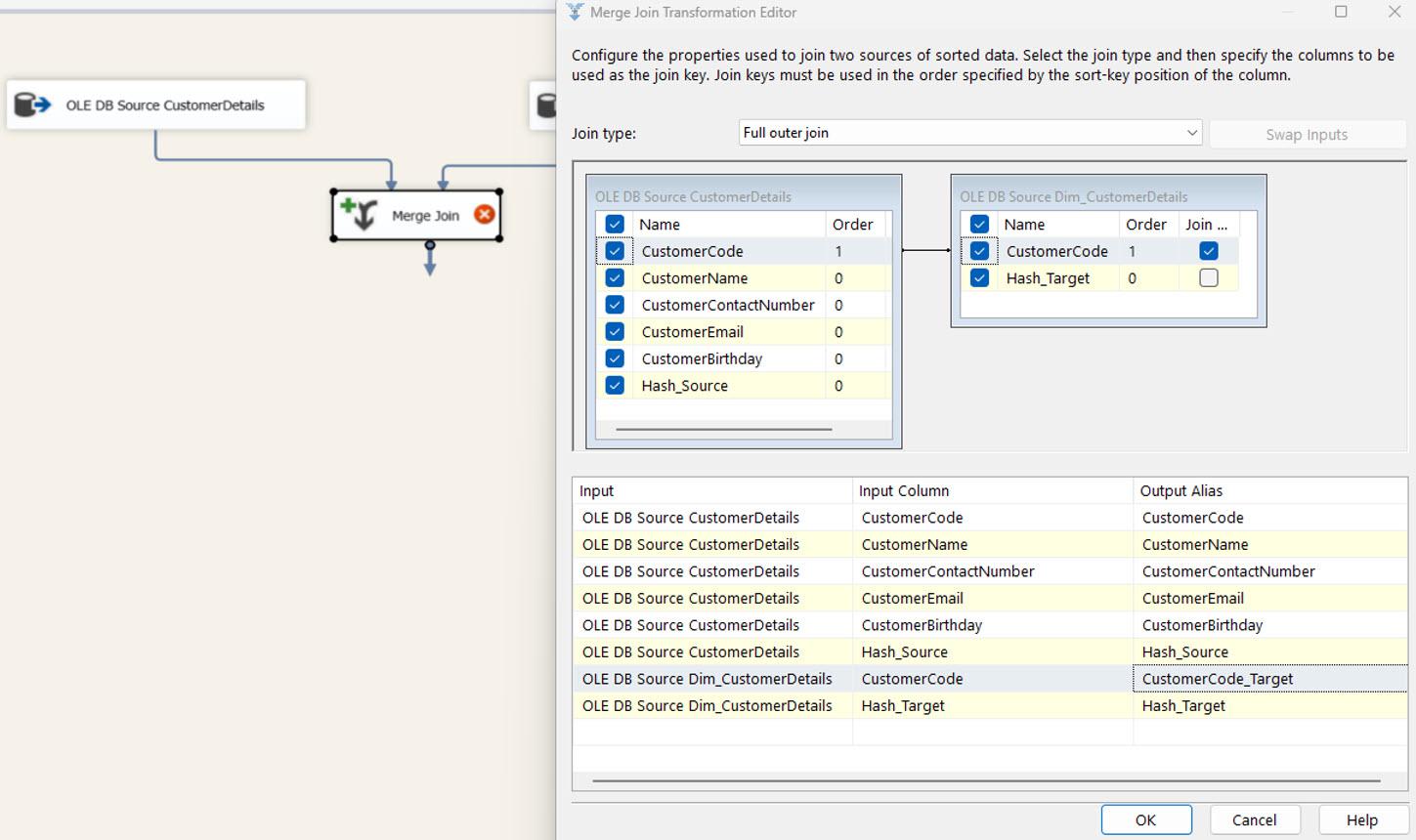
MERGE JOIN: The source and target components join using the MERGE JOIN task. And all the required configurations are explained in the following images. The SSIS automatically matches the join keys based on the column order configured in the OLE DB SOURCE controls. Then you must select the join type as FULL OUTER JOIN and all the source and target columns.
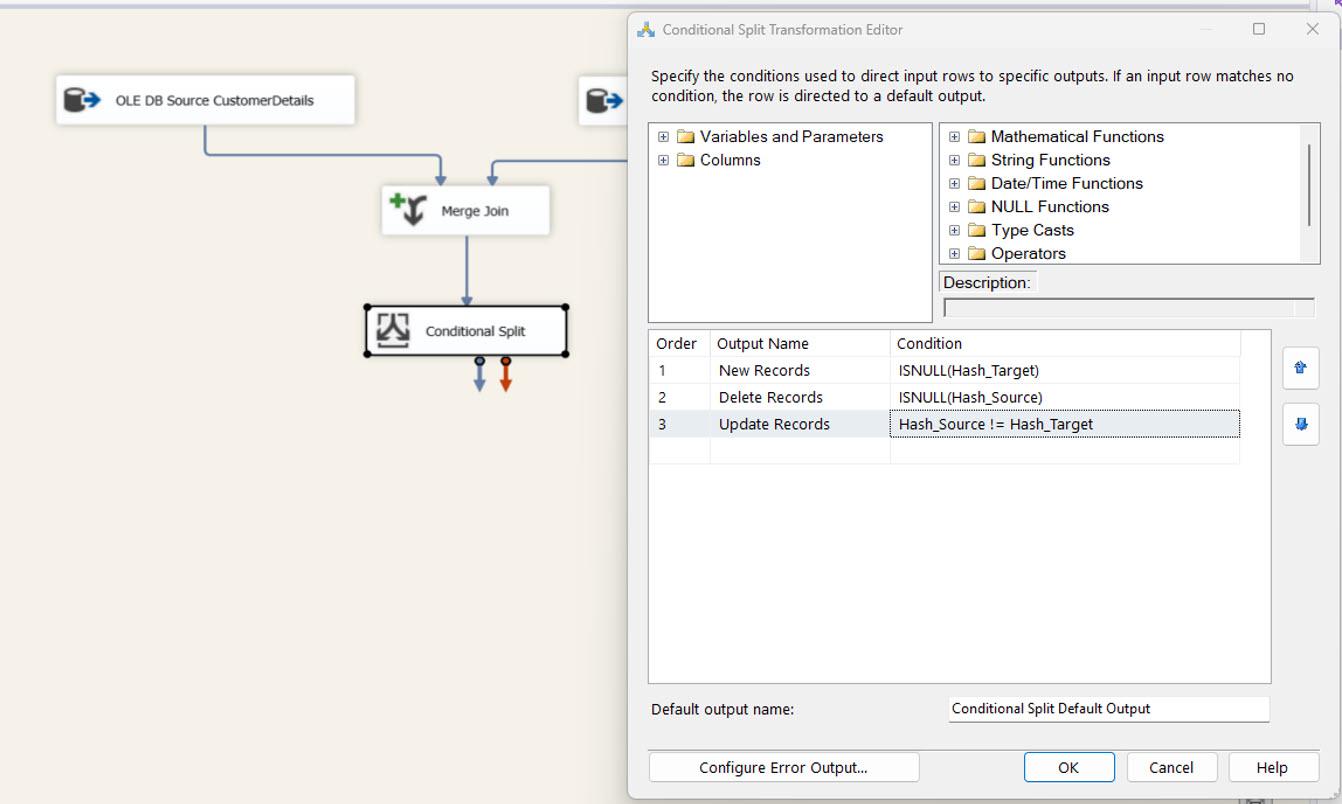
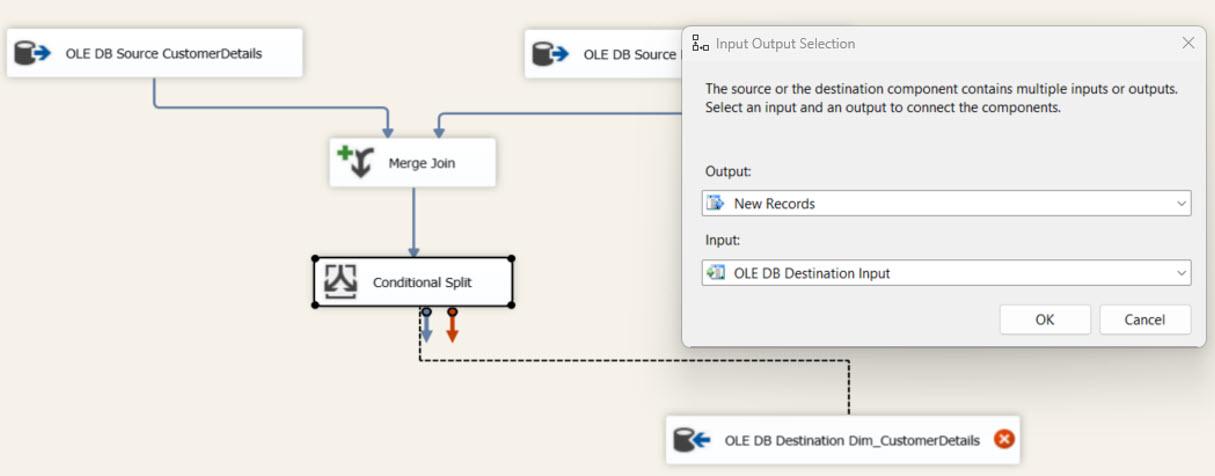
We use a Conditional Split task to separate the input dataset using custom conditions explained in the following image as new, updated, and deleted records.
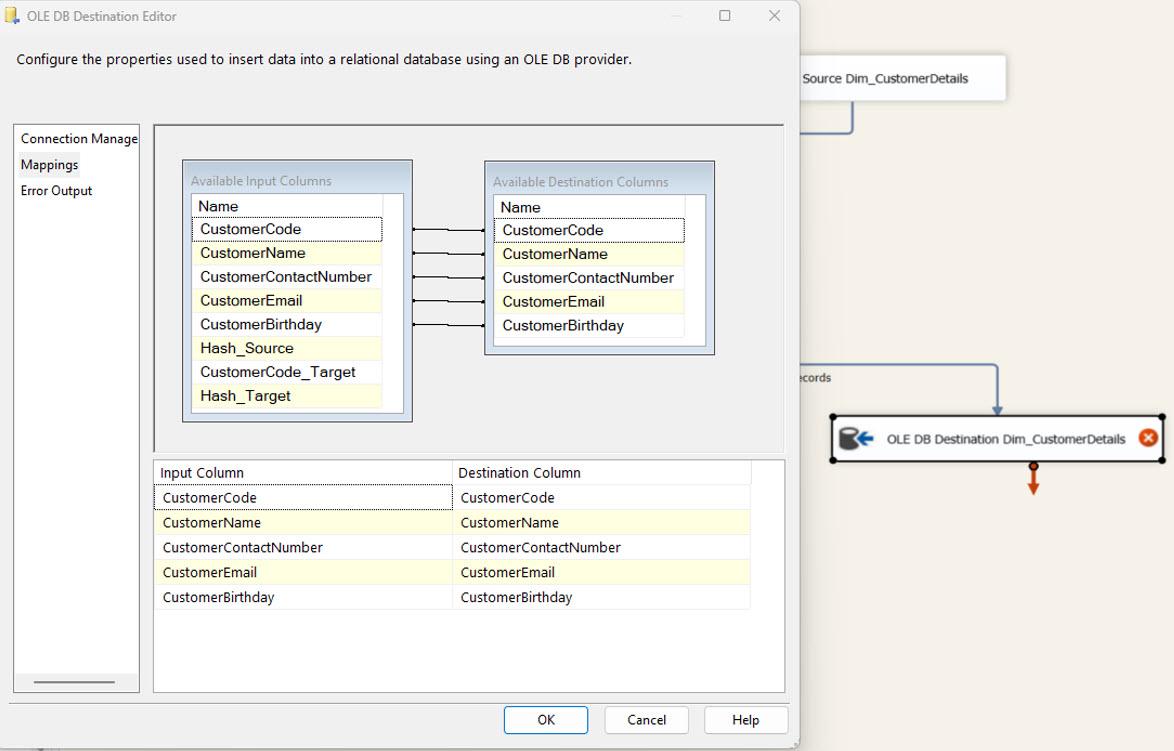
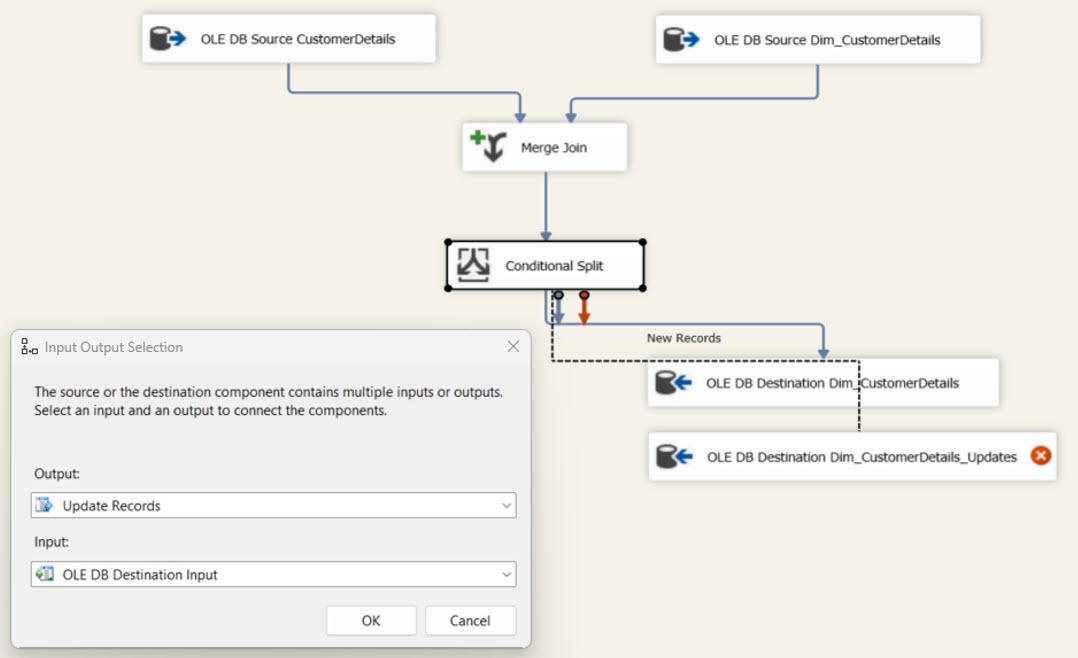
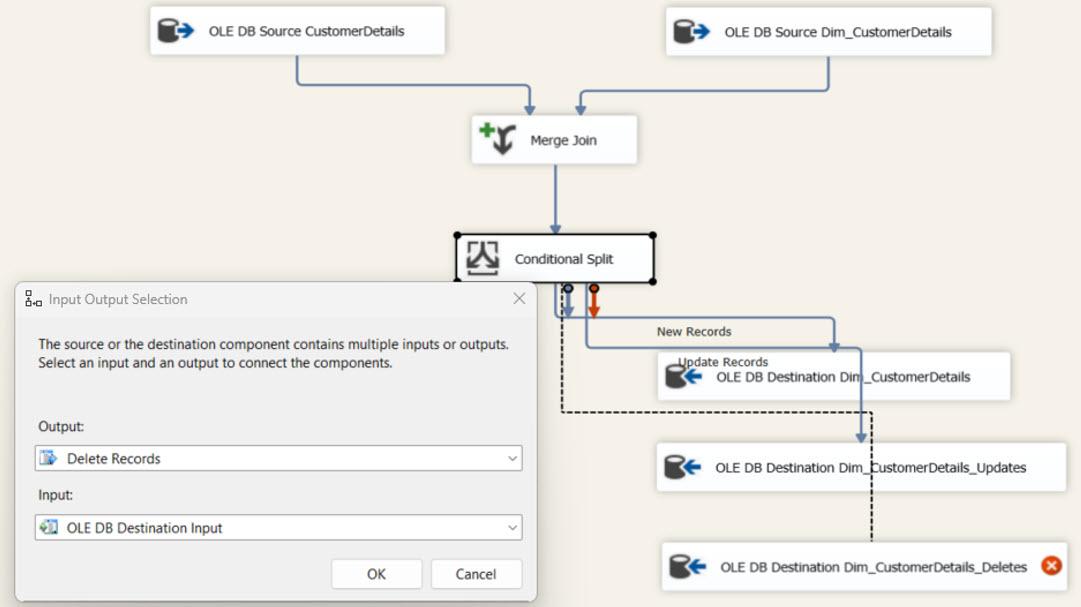
The OLE DB Destination Task for Destination Tables: Now, we need to configure 3 OLE DB Destination tasks for new, updated, and deleted records. The following three tables mainly store the above datasets.
- Dim_CustomerDetails (Final Table): used for the new records.
- Dim_CustomerDetails_Updates: used for keeping updated data until merged with the final table.
- Dim_CustomerDetails_Deletes: Used for keeping deleted records until deleted the original records in the final table.
The required steps:

We can execute the DATA FLOW TASK and validate the steps completed so far. Then it can be observed if they are working correctly or not. This step is the initial execution. So, all source data is considered new records and inserted into the destination table because there were no records in the destination table.
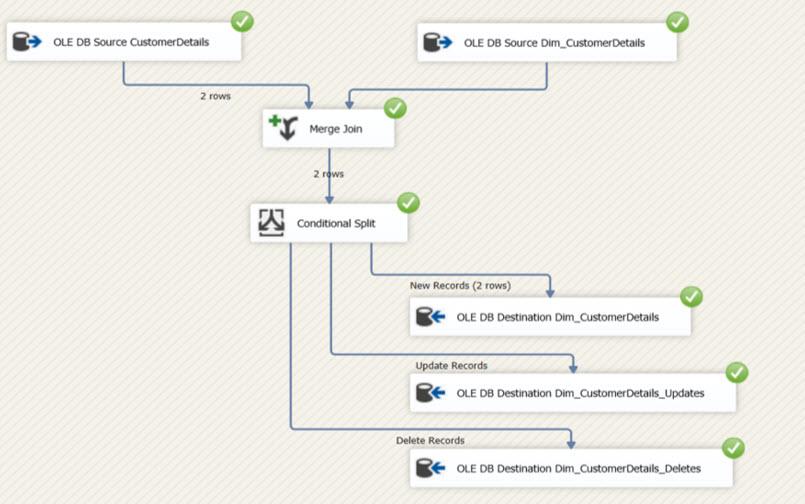
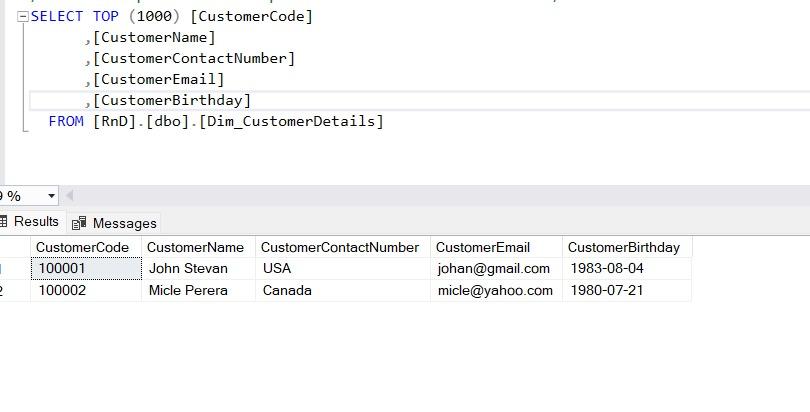
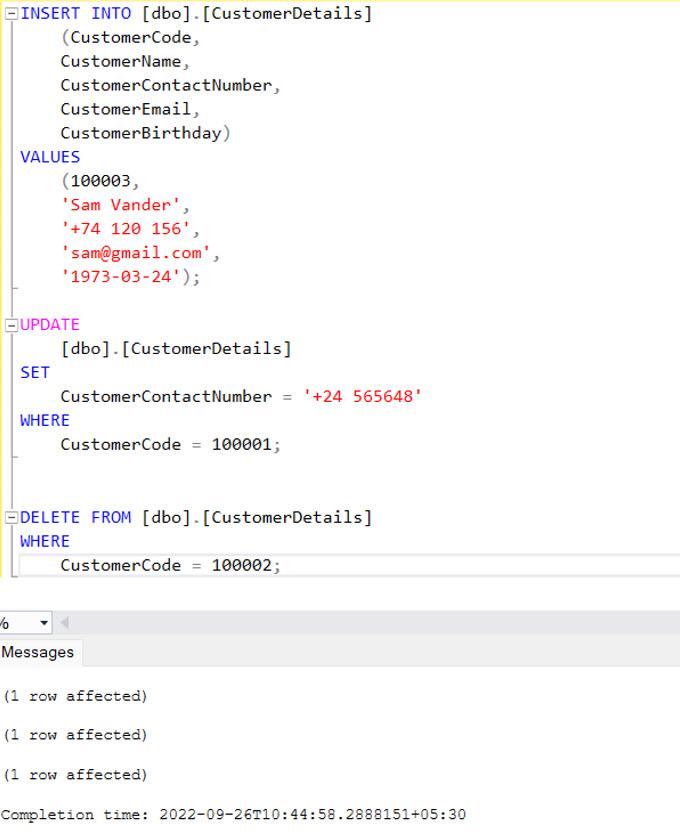
I will make the following changes to the source using the following SQL commands.
- Insert a new record.
- Update the existing record.
- Delete a record from the table.
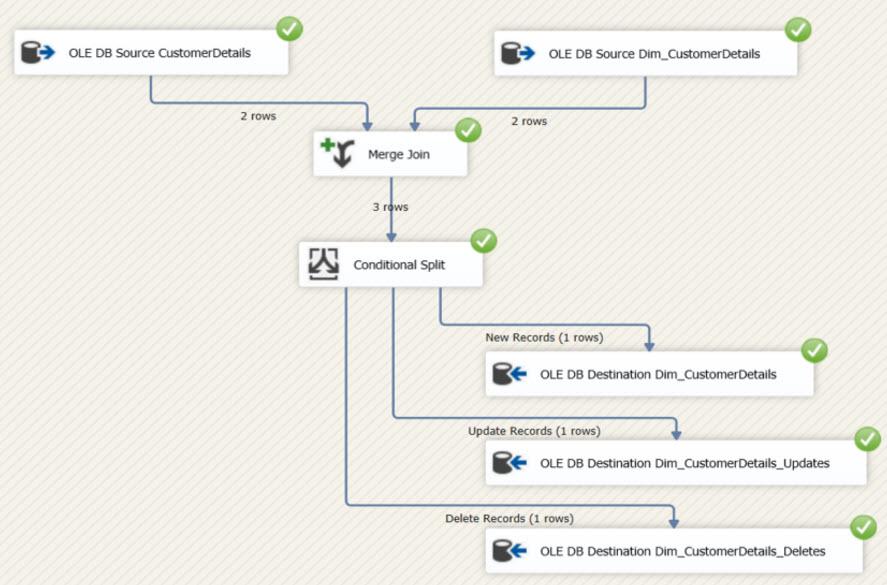
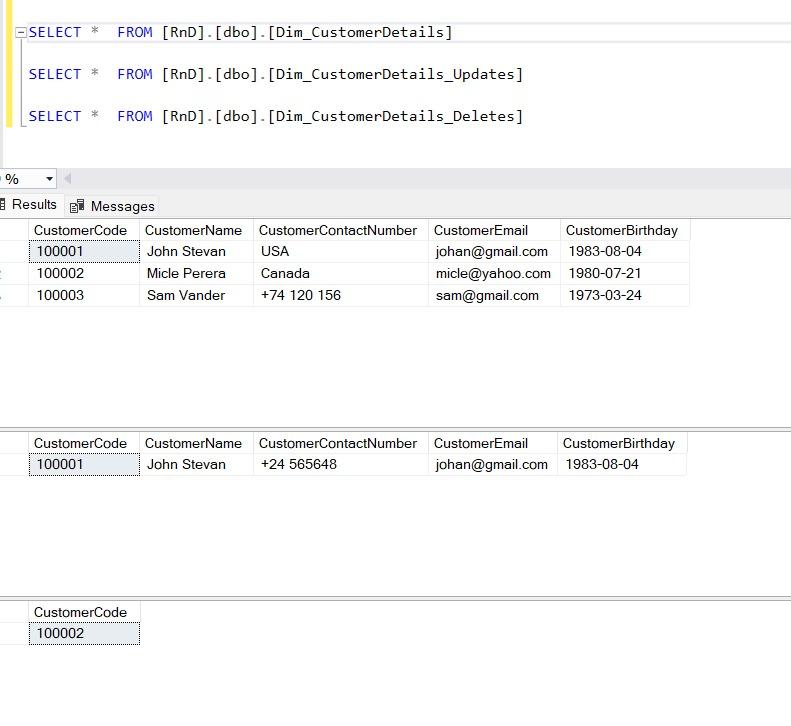
See the difference between the Source and Destination tables.

The Data Flow Task executed again. Then you can observe all the changes inserted into the relevant tables I explained earlier in the document.
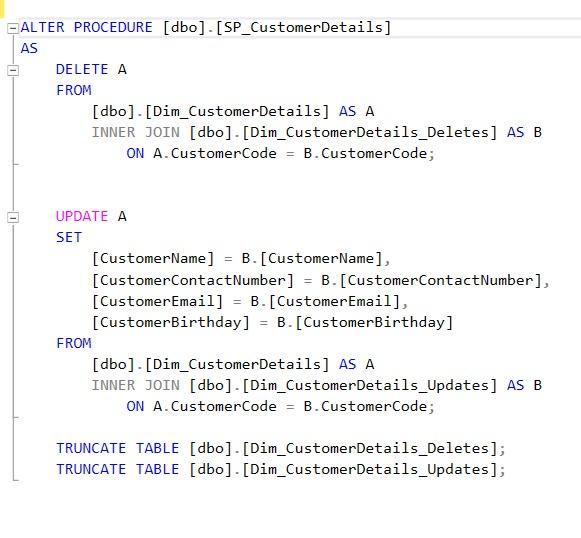
Now, we need to create a stored procedure to merge the changes with the final table, and after the merging, we need to truncate the staging tables. Then we can add an EXECUTE SQL TASK after the DATA FLOW TASK to execute the procedure.
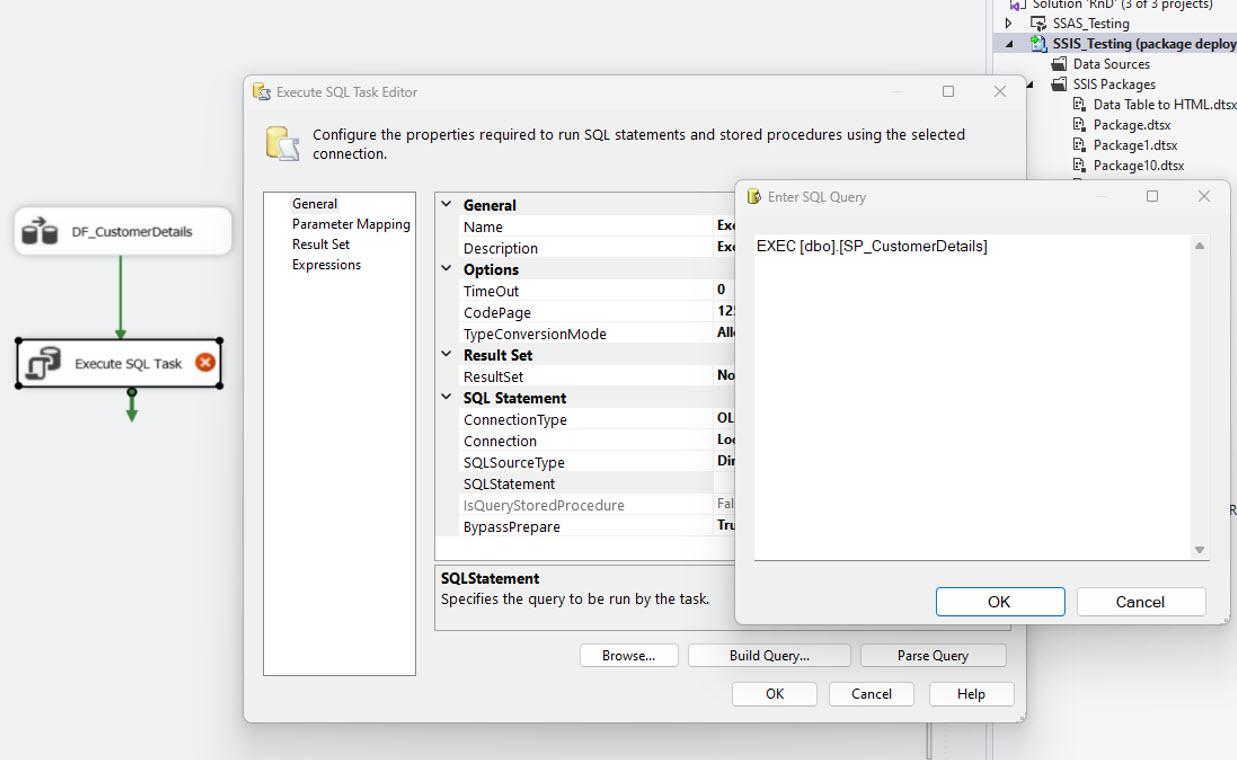
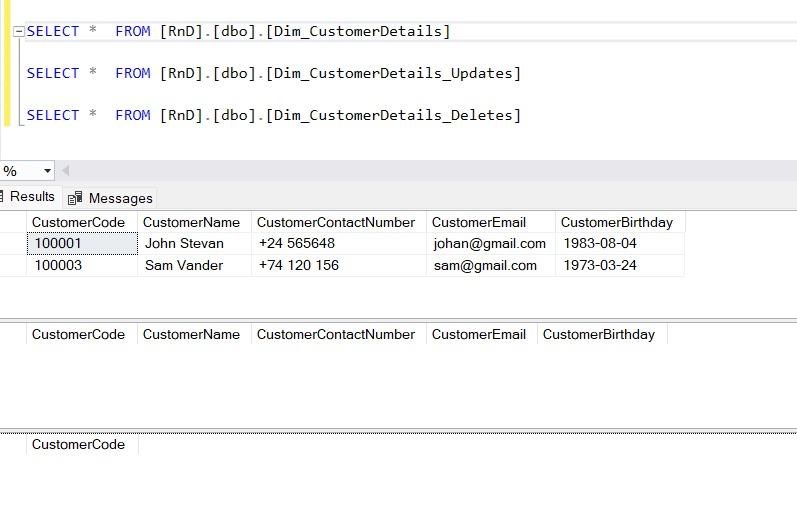
After executing the procedure, you can observe that all the changes merged with the final table in the following image.
Conclusion
When working with heterogeneous systems like SAP S/4HANA, Azure SQL, and ETL tools, it is always good to check these scenarios to avoid duplicate data in DBs and reports. In addition, this approach helped without additional costs on complex configurations like change logs, etc., and is easy to use and maintain.
I hope this article helps design efficient ETL systems/pipelines that will save time, money, and effort.

