First let’s get the apologies out of the way. This article is longer than I first thought it would be. Much longer in fact. Originally I had intended to write a “How to” article, outlining the way I linked SQL Server to a graph database, Neo4j. Then I sat back and thought further. Most dyed-in-the-wool SQL Server aficionados will consider heresy the very idea of using a graph database, or any NOSQL technology for that matter. “SQL Server can do anything” they will say. “Why do I need this non-relational stuff?” “Why should I bother reading this article?”
Yes, SQL Server is incredibly capable at processing data, in huge quantities, and at prodigious speeds (when well-tuned). So I came to the conclusion that as well as “How”, I needed to address the “What” and the “Why”. What problem is so intractable that SQL Server is not the best solution and what alternative technologies might be available? Why did I choose a graph database to solve my problem? Only then I could get to the heart of the issue and describe how I built the solution.
What is the problem?
SQL Server is not necessarily the most efficient way of solving every problem. In particular, I have always found difficulties in handling hierarchical data. Saying there are problems with the handling of relationships between data items seems paradoxical when dealing with a relational database, but just think carefully about the situation. The relations in a relational database are handled by joins between tables. These can be managed in two ways: either in a permanent declarative fashion by the use of foreign keys, or in a temporary fashion by ad-hoc joins in our queries. In either case, these are very efficient in most cases.
Hierarchical data on the other hand, is often modelled with self joins. Consider the typical example of an employee table which has a unique identifier (employee_ID) and a foreign key field holding the employee_ID of the person’s manager, who is themselves an employee. This can be used to create a recursive CTE to return an organisations management structure. But this is a very simple tree structure. An employee is only directly linked to one manager, and the flow of responsibility is in a single direction. From SQL Server 2005, Microsoft has also provided the hierarchy data type to model such structures.
Hierarchical data is often not that simple. For example, an employee might be managerially responsible to one supervisor, but professionally responsible to another. The hierarchy data type cannot handle multiple parents, so is not appropriate for such data. Concepts might have bi-directional links. Consider a social networking example. John might “follow” Paul, but Paul may or may not follow John. Again, the hierarchy data type cannot handle these multi-directional relationships. Such social networking situations are not simple trees as with the employee-manager scenario, but are a more generalised structure – a graph. Graphs can be used to model complex interactions where concepts are linked by various types of relationships, with multiple parents and multiple children.
Graphs can be implemented in a relational database using foreign keys as in the employee-manager example, but often need link tables to model the complexities, and whereas the employee-manager trees tends to be of limited depth, social networking graphs can extend to an almost infinite depth and even be circular in nature. The execution plans for the queries needed to model these structures become increasingly complex, and as the depth of traversal of the graph or tree increases, the queries become ever more inefficient.
My own business domain is that of health care, and for many years I was the head of a software development team developing an electronic health record for cancer patients. True to the spirit of using coded data wherever possible, diagnoses were stored using READ Codes V2. This was a UK oriented coding system containing a thesaurus of over 85,000 concepts plus a further 40,000 for drugs and medical devices.
The codes themselves were 5-byte alphanumeric sequences, and the classification of the terminology was inherent in the structure of the codes. Thus code B1… was the code for the concept “Malignant neoplasm of digestive organs and peritoneum”, and child concepts representing more specific areas of the digestive tract were coded by adding additional characters. So B10.. represented “Malignant neoplasm of oesophagus”, B11.. represented “Malignant neoplasm of stomach” and so on. Similarly, B100. was “Malignant neoplasm of cervical oesophagus” and B101. Was “Malignant neoplasm of thoracic oesophagus”. This meant that to find out how many patients were suffering from malignant disease of some part of the oesophagus, it was sufficient to include the following in the query…
SELECT COUNT(*) FROM DISEASES WHERE READCODE LIKE ‘B10%’
This was simple, straightforward, and more to the point, very fast.
Unfortunately there is a new coding scheme which is being adopted as a National Standard by the NHS, and as Murphy’s Law dictates, it is not that simple any more. The new coding scheme, SnomedCT, has many advantages, not the least of which is having a much larger thesaurus of concepts (over 700,000). It also has one other feature which has both pluses and minuses; its codes are, to all intents and purposes, random or surrogate keys. ConceptIDs are large integers, normally represented as varchar(18) in SQL Server, and relationships between them are defined using a Relationship table which, among others, has fields for ConceptID1, ConceptID2, and RelationshipType. This is very flexible, allowing concepts to be represented in multiple hierarchical position, to have multiple parents, and to have many types of relationships apart from the concept_1 IS_A concept_2 type seen above.
In fact there are over 3,000,000 relationships defined of 81 different relationship types, including IS_A, WAS_A, SAME_AS, Severity, Laterality, Finding_context etc., at a depth of up to 14 levels from the root concept. Although this allows a much greater accuracy in coding medical situations, you can no longer do a simple count “WHERE CONCEPTID LIKE ‘371984007’ (the concept id for Malignant neoplasm of oesophagus), as the query produces meaningless results.
It is possible to get the information using recursive CTEs. For example, a query to return all the child concepts of ‘371984007’ (the concept id for Malignant neoplasm of oesophagus) is as follows:
WITH children (ConceptID, FullySpecifiedName, Level) AS
(
SELECT c1.ConceptID, c1.FullySpecifiedName, 1
FROM dbo.Concepts c
INNER JOIN Relationships r ON r.ConceptID2=c.ConceptID
AND r.RelationshipType='116680003' -- conceptID for 'IS_A' relationship
INNER JOIN dbo.Concepts c1 ON c1.ConceptID=r.ConceptID1
WHERE c.ConceptID='371984007' -- conceptID for malignant neoplasm of oesophagus
UNION ALL
SELECT c1.ConceptID, c1.FullySpecifiedName, c.Level+1
FROM children c
INNER JOIN Relationships r ON r.ConceptID2=c.ConceptID
AND r.RelationshipType='116680003' -- conceptID for 'IS_A' relationship
INNER JOIN dbo.Concepts c1 ON c1.ConceptID=r.ConceptID1
)
SELECT DISTINCT * FROM childrenThis query yields thirteen concepts over three levels. However, once one starts probing relationships of many more levels, or when one needs ancestor codes as well as descendent codes, the SQL becomes increasingly inefficient, and we need to consider other solutions.
Why choose a graph database?
It is at this point that we can look at NOSQL solutions. (As an aside, I like to think of NOSQL as meaning Not Only SQL rather than No SQL). NOSQL technologies come in many flavours, document databases, key-value stores, and graph databases to name but a few. It is the latter that I shall consider here. Graph databases have been designed from the ground up to handle the type of data I refer to above – graph data! Rather than reproduce already published material, I recommend reading “Graph Databases”, by Robinson, Weber and Eifrem (O’Reilly, 2013, available as a free download from http://graphdatabases.com/ ) which discusses in detail what graph databases are, what applications they are best suited for, and how they work. I will extract a few salient point though. Graph databases represent entities or concepts as nodes and the ways in which those entities relate to the world ad to each other as relationships. Their storage engines draw on algorithms developed in the mathematics of graph theory to solve graph problems more efficiently than a relational storage engine can. Unlike relational databases, relationships in graph databases are real entities and do not have to be inferred from foreign keys.
The graph database I have used is Neo4j from Neo Technologies (http://www.neotechnology.com). Unlike many NOSQL solutions, Neo4j is suitable for enterprise deployment as it features full ACID transactions, and scales to many billions of nodes and relationships through its high availability options. Neo4j is a property graph, and has the following characteristics:
- It contains nodes and relationships
- Nodes contain properties (key-value pairs)
- Relationships are named and directed, and always have a start and end node
- Relationships can also contain properties
For an excellent introduction to Neo4j (and graph databases in general), see the Neo4j Manual (http://docs.neo4j.org/chunked/2.0.0-M06/index.html).
There is a body of published material discussing the relative merits of SQL and NOSQL database engines. One comparison which is relevant here is contained in the book “Neo4j in Action”, by Partner, Vukotic and Watt (ISBN: 9781617290763, Manning Early Access Program, 2013, http://www.manning.com/partner/ ). This book considers a simple social networking database with two tables, t_user, and t_user_friend. The latter has two fields for user_1 and user_2 which are both foreign keyed into the t_user table. The t_user table is populated with 1000 users, and each has an average of 50 friends, so the t_user_friend table has 50000 records. They then query this table for friends of friends for up to 5 depths and found query times of about 10 seconds for depth 4, and over 90000 seconds for depth 5.
In my own experiments on SQL Server 2012, the query times were not as bad as this, although there was still a significant deterioration in performance at depth 5. However, I did modify the query slightly. The book used a SELECT DISTINCT … whereas I just used a SELECT INTO a temp table and then a SELECT DISTINCT out of the temp table. This showed such a marked improvement over the original that I am still surprised that the query optimiser can’t do something similar! The book goes on to demonstrate sub-second query times for similar data in Neo4j, and I also found this to be the case.
This data clearly demonstrates an advantage in using a graph database such as Neo4j to handle complex relationships between data items. Neo4j has its own query language Cypher, which broadly follows a SQL-like syntax. The following Cypher query will return the child concepts of Snomed CT concept ID='371984007', the conceptID for malignant neoplasm of oesophagus used in the examples above:
match p=(child:Concept)-[IS_A*]->(parent:Concept) where parent.conceptID='371984007' return distinct child.conceptID as conceptId, child.fullySpecifiedName as fullySpecifiedName, length(p) as level
Cypher uses ASCII art in its pattern matching, where () represents a node and [] represents a relationship. So (child:Concept) is a node of type Concept given the local identifier of child, and -[IS_A*]-> represents a directed relationship of any depth of type IS_A between the node with the identifier child and the node with the identifier parent. The identifier p holds a reference to the entire matched path. The where clause is similar to SQL and tells the Neo4j engine to start matching paths from a parent node with the indicated value for the conceptID property. The return clause is similar to the SQL select, and instructs the engine to return the listed properties of each child node; the length(p) is the number of relationship steps in the overall path.
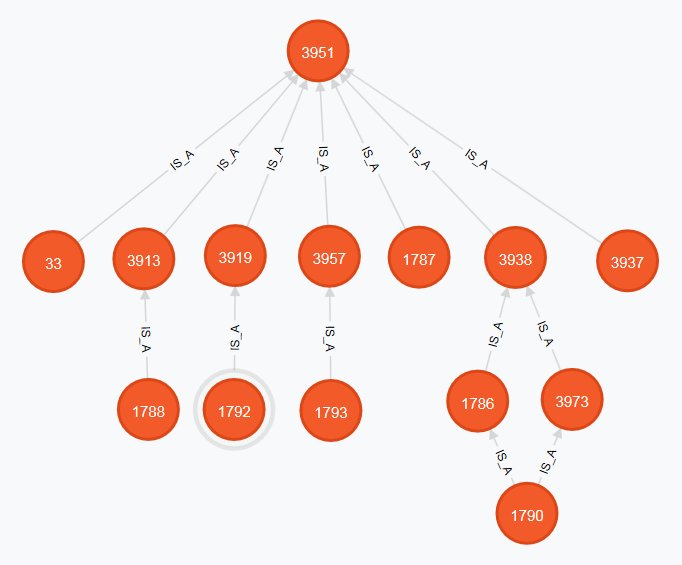
The nodes and relationships returned from the Cypher query are illustrated graphically in figure 1, which is a screen clippping from the Neo4j browser. Note that in this figure, the numbers on the nodes are integer node IDs assigned by Neo4j when the node is created. These can be retrieved in Cypher queries using the syntax id(node_Identifier).
However, this in itself is not the whole answer to the problem. The Cypher query against Neo4j will give me the list of disease codes I am interested in. But the rest of my data is not stored in Neo4j, nor would I want it to be. In accepting that the graph database is a better solution for handling my medical terminology hierarchies, I am not saying it is better for everything else! And this will often be the case.
For example, in an ecommerce application, a graph database may well be an efficient way of identifying recommended products (you know, “people who bought what you have just added to your shopping cart also purchased this, that and the other”). But you probably don’t want to use the graph database for all the inventory, shopping cart, user base, and credit card details. The relational model has a proven track record there at least.
How do we link to two?
Finally we come to the question I started out with. How can I run a query against a Neo4j database and use the results in a query within SQL Server? SQL Server may not quiet be able to do anything, but in the CLR integration, Microsoft have provided us with the means of extending its capabilities wherever our imagination takes us.
I had previously explored Neo4j using Neo4jClient, a .NET client for Neo4j, which is designed to make it easy to write Cypher queries in C# with full IntelliSense in Visual Studio. For more information go to https://github.com/Readify/Neo4jClient/wiki. Neo4jClient ships exclusively as a NuGet package which is installed in your project by running Install-Package Neo4jClient in the NuGet Package Manager Console.
Using this client, the Cypher query above is written as follows:
var _graphClient = new GraphClient(new Uri("http://localhost:7474/db/data"));
_graphClient.Connect();
var query = _graphClient.Cypher
.Match("p=(parent:Concept)<-[*]-(child:Concept)")
.Where("parent.conceptID='371984007' ")
.Return((child,p) => new descendants
{
conceptID = child.As<Concept>().conceptID,
fullySpecifiedName = child.As<Concept>().fullySpecifiedName,
level = p.Length()
});
return query.Results;
The return clause is more than a little convoluted. I originally used the simple return statement shown in the pure Cypher query above, but this produced a run time error that I was trying to return an anonymous object type end that the Neo4jClient did not support this. I posted my problem on StackOverflow, and I am grateful to Chris Skarden for providing the solution. Apparently, the problem arises because I am returning properties from two distinct objects, a concept node, and a path. It is necessary to use the lambda syntax to project these onto a single class (descendants) which combines the concept class defining the node structure, with an integer length parameter. The URI used in the connection method references the default port set when Neo4j is installed as a local server.
As it is so easy to query Neo4j from C#, I thought that it can’t be that difficult to embed the code above in a table-valued CLR SQL function. And in principle, it isn’t that hard. A bit of exploration around MSDN and StackOverflow soon sorted out my deficiencies in syntax and the like. In order to simplify things, I avoided Visual Studio. After all, I didn’t need a full blown solution, just a simple C# script. So with the help of the Great God BOL and his minions at Technet and armed with my trusty Notepad++ as code editor, and the command line C# compiler (csc.exe) to build the DLL off I went to do battle with the SQLCLR.
I soon found the first pitfall. You may have multiple versions of csc.exe on your computer, and you need to use the one which is appropriate for the version of SQL Server in which you intend hosting the CLR function. SQL Server 2012 uses version 4 of the .NET runtime, so on my machine, the appropriate version of csc.exe is located in C:\Windows\Microsoft.NET\Framework\v4.0.30319.
I added this to my environment path variable, then opened a command window in the location of my C# file. A copy of the Neo4jClient.dll must reside in that folder, as must Newtonsoft.Json.dll, which the Neo4jClient uses. Then I compiled the code to a dll using a command line similar to this…
csc /target:library getdescendants.cs /r:Neo4jClient.dll /r:Newtonsoft.Json.dll
.. where getdescendants.cs is the name of my SQL function code file.
The next step was to get this assembly registered in SQL Server. The first step is make sure that SQL CLR integration is enabled. The ability to execute common language runtime (CLR) code is set to OFF by default in SQL Server. The CLR code can be enabled by using the sp_configure system stored procedure as follows:
sp_configure 'show advanced options', 1; GO RECONFIGURE; GO sp_configure 'clr enabled', 1; GO RECONFIGURE; GO
This must be done at database level, so make sure you are in the appropriate database before running this code. The database must also be set to TRUSTWORTHY = ON. The TRUSTWORTHY database setting indicates whether the instance of Microsoft SQL Server trusts the database and the contents of that database. By default, this setting is set to OFF. However, you can set it to ON by using the ALTER DATABASE statement. This setting is necessary because the assemblies I am creating will be built with UNSAFE permission settings.
The next step should be as simple as this:
CREATE ASSEMBLY getdescendants FROM 'C:\path_to_my_dll\getdescendants.dll' WITH PERMISSION_SET = UNSAFE
But this is where things started to get interesting! The beast that is the SQLCLR starts fighting back. SSMS returned an error message like this…
Assembly 'getdescendants' references assembly 'system.runtime.serialization, version=4.0.0.0, culture=neutral, publickeytoken=b77a5c561934e089.', which is not present in the current database. SQL Server attempted to locate and automatically load the referenced assembly from the same location where referring assembly came from, but that operation has failed (reason: 2(The system cannot find the file specified.)). Please load the referenced assembly into the current database and retry your request.
The problem here is that out-of-the box, the SQLCLR supports only a limited number of framework components, and System.Runtime.Serialization is not one of them. So, l located the source dll and tried registering that one manually.
CREATE ASSEMBLY [System.Runtime.Serialization] FROM 'C:\Program Files\Reference Assemblies\Microsoft\Framework\.NETFramework\v4.0\system.runtime.serialization.dll' WITH PERMISSION_SET = UNSAFE
This time is was a different assembly that was missing…
Assembly 'System.Runtime.Serialization' references assembly 'smdiagnostics, version=4.0.0.0, culture=neutral, publicke0ytoken=b77a5c561934e089.', which is not present in the current database…
I had trouble locating that one, but eventually found it.
CREATE Assembly [SMDiagnostics] FROM 'C:\Windows\Microsoft.NET\Framework\v4.0.30319\SMDiagnostics.dll' WITH PERMISSION_SET = UNSAFE
That assembly was created OK, but only with a health warning!
Warning: The Microsoft .NET Framework assembly 'smdiagnostics, version=4.0.0.0, culture=neutral, publickeytoken=b77a5c561934e089, processorarchitecture=msil.' you are registering is not fully tested in the SQL Server hosted environment and is not supported. In the future, if you upgrade or service this assembly or the .NET Framework, your CLR integration routine may stop working. Please refer SQL Server Books Online for more details.
At this point, I kept my fingers crossed that I could safely ignore the warning and tried creating my own assembly again. It failed. Again. This time the error was for missing assembly System.ServiceModel.Internals. So add that, try again. And again. Eventually this was the full sequence of assemblies I needed to create before my own would install correctly.
CREATE Assembly [SMDiagnostics] FROM 'C:\Windows\Microsoft.NET\Framework\v4.0.30319\SMDiagnostics.dll' WITH PERMISSION_SET = UNSAFE CREATE Assembly [System.ServiceModel.Internals] FROM 'C:\Windows\Microsoft.NET\Framework\v4.0.30319\System.ServiceModel.Internals.dll' WITH PERMISSION_SET = UNSAFE CREATE Assembly [System.Xaml] FROM 'C:\Windows\Microsoft.NET\Framework\v4.0.30319\System.Xaml.dll' WITH PERMISSION_SET = UNSAFE CREATE Assembly [System.Runtime.DurableInstancing] FROM C:\Windows\Microsoft.NET\Framework\v4.0.30319\System.Runtime.DurableInstancing.dll' WITH PERMISSION_SET = UNSAFE CREATE ASSEMBLY [System.Runtime.Serialization] FROM 'C:\Program Files\ReferenceAssemblies\Microsoft\Framework\.NETFramework\v4.0\system.runtime.serialization.dll' WITH PERMISSION_SET = UNSAFE CREATE ASSEMBLY [System.Net.Http] FROM 'C:\Windows\Microsoft.NET\Framework\v4.0.30319\System.Net.Http.dll' WITH PERMISSION_SET = UNSAFE CREATE ASSEMBLY [System.ComponentModel.DataAnnotations] FROM 'C:\Windows\Microsoft.NET\Framework\v4.0.30319\System.ComponentModel.DataAnnotations.dll' WITH PERMISSION_SET = UNSAFE
When I did add my own assembly, it also added the Neo4jClient.dll and the Newtonsoft.Json.dll libraries which were referenced in my assembly, and which were both located in the same folder, allowing SQL Server to locate them itself.
Next step – create the functions from the assembly. This is the code for that:
CREATE FUNCTION tvfGetDescendants(@conceptID NVARCHAR(18)) RETURNS TABLE (conceptID NVARCHAR(18), fullySpecifiedName nvarchar(MAX), level bigint) AS EXTERNAL NAME getdescendants.GetDescendantsProc.GetDescendants GO CREATE FUNCTION tvfGetAncestors(@conceptID NVARCHAR(18)) RETURNS TABLE (conceptID NVARCHAR(18), fullySpecifiedName nvarchar(MAX), level bigint) AS EXTERNAL NAME getdescendants.GetDescendantsProc.GetAncestors GO
That worked with no errors. At that point I was quite surprised, but my new found confidence was short lived. I tested the function with a simple bit of tSQL
DECLARE @parentId NVARCHAR(18) = '371984007';--'255058005'; SELECT conceptID, fullySpecifiedName, level FROM tvfGetDescendants(@parentId) ORDER BY level;
This led to a long error message to the effect that the Newtonsoft.Json serialization was failing. Again StackOverflow came to the rescue. Apparently I needed to annotate my descendants class with Json attributes like so:
[JsonObject(MemberSerialization.OptIn)]
public class descendants
{
[JsonProperty]
public string conceptID { get; set; }
[JsonProperty]
public string fullySpecifiedName { get; set; }
[JsonProperty]
public long level { get; set; }}
?
So drop the functions, drop the assembly, make the changes, recompile, add the assembly and recreate the functions. And it worked. Quite simply, I was able to retrieve descendant lists from Neo4j and combine them anyway I wanted with the relational data in SQL Server. The complete C# code for the assembly is available in the attached resource file, getdescendants.cs.
So what about performance? There is no point in going to this trouble if it offers no advantages over doing things natively within SQL Server. I set up two queries to return all the child concepts of a given start point, one using the new CLR table valued function, and one using a recursive CTE. For repeatability, I cleared the procedure and data caches before each run. This is the test code:
DBCC FREEPROCCACHE
GO
DBCC DROPCLEANBUFFERS
GO
DECLARE @parentId NVARCHAR(18) = '371984007';
SELECT DISTINCT d.*
FROM tvfGetDescendants(@parentId) d;
; WITH children (ConceptID, FullySpecifiedName,Level) AS (
SELECT c1.ConceptID, c1.FullySpecifiedName, 1
FROM dbo.Concepts c
INNER JOIN Relationships r ON r.ConceptID2=c.ConceptID
AND r.RelationshipType='116680003'
INNER JOIN dbo.Concepts c1 ON c1.ConceptID=r.ConceptID1
WHERE c.ConceptID=@parentId
UNION ALL
SELECT c1.ConceptID, c1.FullySpecifiedName, c.Level+1
FROM children c
INNER JOIN Relationships r ON r.ConceptID2=c.ConceptID
AND r.RelationshipType='116680003'
INNER JOIN dbo.Concepts c1 ON c1.ConceptID=r.ConceptID1
)
SELECT DISTINCT *
FROM children;
GOFor a pair of queries returning the same 13 rows to a maximum depth of 2, the performance was very different. Over 10 repeat runs, the recursive CTE took an average of 605 msec, whereas the CLR TVF took an average of only 17 msec, a time saving of over 97%. A look at the IO report shows that while the IO for the TVF was just …
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
For the CTE it was more involved as you would expect …
Table 'Concepts'. Scan count 1, logical reads 45, physical reads 9 Table 'Relationships'. Scan count 15, logical reads 156, physical reads 26 Table 'Worktable'. Scan count 2, logical reads 73, physical reads 0
For queries returning the 1002 child concepts to a maximum depth of 7, the difference in performance was similar. Over 10 repeat runs, the recursive CTE took an average of 8890 msec, whereas the CLR TVF took an average of only 372 msec, a time saving of nearly 96%.
For a query returning 23482 rows over 14 levels, the performance difference was not so marked, 15.5 sec for the TVF and 44.1 sec for the CTE. The increase in IO for the CTE is huge …
Table 'Concepts'. Scan count 1, logical reads 390963, physical reads 434 Table 'Relationships'. Scan count 130321, logical reads 936441, physical reads 1656 Table 'Worktable'. Scan count 2, logical reads 782254, physical reads 0
The TVF is very easy to use in more complicated queries, using CROSS APPLY for instance. This technique successfully demonstrates what I wanted, a means of combining the richness of SQL Server functionality with the very efficient graph traversal functionality offered by Neo4j.
Now my imagination has been fired, I plan expanding this functionality. First will probably be CRUD functions or procedures called from triggers on the SQL terminology tables to keep the SQL and Neo4j versions of the relationships synchronised. Perhaps I feel another article coming on!