

Back in 2011 I wrote Oiling the gears for the data dictionary It describes a means of simplifying the addition of comments to SQL Server objects used by a number of database documentation tools. These produce information that is up-to-date, consistently presented and in a consumable format. These comments can provide the basis for a data dictionary or catalog. Ultimately you still have to make the effort to supply meaningful descriptions for these tools to harvest. However, there is a shortcut and I should like to share my approach with you.
Recap and update
Oiling the gears for the data dictionary took the simple approach to hiding the complexity of the extended properties stored procedures, sp_AddExtendedProperty and sp_UpdateExtendedProperty.
- Build two data dictionary tables to hold table and column descriptions respectively
- Create a stored procedure to populate those tables from the INFORMATION_SCHEMA catalog views
- Add two more stored procedures, each to update a specific data dictionary tables
- Finally, build a stored procedure to take the descriptions from our two tables and apply them as extended properties
I also specified two "test" stored procedures that would highlight any tables or columns with blank descriptions. However these result in too many failed tests when plugged into a legacy system. You can only plug these into a build process once the number of fails are low enough for you to have a realistic chance of filling in the missing descriptions.
As of 2019 I would make three changes to the approach I took in 2011.
- Create my artifacts in an explicit Metadata schema, not dbo
- Change the table DataDictionary_Tables name and structure to support a wider set of objects. Views are important too!
- Alter column names in tables, views and stored procedures containing “field” to “column”
What is the problem I am trying to solve?
When you have worked for an organisation for a long time it is easy to forget what it is like to be a new starter. Especially when that new starter is not only new to the organisation but new to the world of work.
- How do they acquire the knowledge that you take for granted?
- Do they understand the various data modelling concepts and how those models can be used to make their lives easier?
- Is that information written down anywhere or is it word of mouth from person to person?
- Is your written information accurate and up-to-date?
In addition, increased regulation makes the provision of a data dictionary or catalog an important weapon in the compliance arsenal.
Good quality documentation is something that everyone wants to be available but rarely is, furthermore few have the time or mindset necessary to produce and maintain such information.
This is where database documentation tools such as Redgate SQLDoc come in. Redgate SQLDoc allows you to publish your database documentation in HTML, PDF, Word or Markdown files. It allows you to chose what artefacts to publish and also what properties should be included.
It also allows you to maintain the MS_DESCRIPTION property on the various SQL Server database objects including the database itself. Although the product makes it easier to supply the descriptions it does not generate default descriptions for you.
In my experience with a data dictionary or catalog is that you know where you want to get to but you wouldn't start from where you are today!
Can we auto-generate column descriptions?
The data warehouse I work on has tens of thousands of columns across the various tables and views. When examining the structure of the database there are a number of common columns across a multitude of tables. For example the majority of tables have some form of DateKey field that can be used with a DimDate dimension.
Even in the AdventureWorksDW2012, the small demo data warehouse database, we can see that DateKey crops up 14 times.
SELECT name AS ColumnName,COUNT(*) AS Occurrences,GROUPING(name) AS IsTotal FROM AdventureWorksDW2012.sys.all_columns WHERE name LIKE '%datekey' GROUP BY name WITH ROLLUP
| ColumnName | Occurrences | IsTotal |
| DateKey | 8 | 0 |
| DueDateKey | 2 | 0 |
| OrderDateKey | 2 | 0 |
| ShipDateKey | 2 | 0 |
| NULL | 14 | 1 |
We can use SQL to apply simple rules to generate descriptions and wrap it up in a view.
CREATE VIEW MetaData.DefaultDescription_DateKey
AS
SELECT
OBJECT_SCHEMA_NAME(AC.object_id) AS SchemaName,
O.name AS ObjectName,
O.type AS ObjectType,
AC.name AS ColumnName,
CASE
WHEN AC.name='OrderDateKey' THEN 'Identifies the date on which the customer placed the order.'
WHEN AC.name='DueDateKey' THEN 'The expected delivery date. This should be within 3 days of the order date. '
WHEN AC.name='ShipDateKey' THEN 'The delivery date. By subtracting the order date by the delivery date we can identify instances where we are not satisfying the customer.'
WHEN AC.name='DateKey' THEN 'The date on which the ' + OBJECT_SCHEMA_NAME(AC.object_id)+'.'+O.name + ' record was created. '
ELSE '' END AS ColumnDescription
FROM AdventureWorksDW2012.sys.all_columns AS AC
INNER JOIN sys.objects AS O
ON O.object_id = AC.object_id
WHERE AC.name LIKE '%DateKey'
AND O.type IN('U','V')
GO
The rules can be as simple or as complex as needed. You could have made the rule take account of whether the OrderDateKey was for an internet sale or an order passed on to a reseller.
The important piece is telling the reader that the column links back to the relevant dimension.
There are two problems with this approach:
- You can end up with a lot of views
- Your descriptions are still manually created
Addressing the “too many views” problem
There are two parts to our view to provide DateKey descriptions:
- The broad WHERE clause to bring back any column ending in DateKey
- The specific column descriptions in the CASE statement
We can represent this by adding a couple of tables to our MetaData schema as shown below.
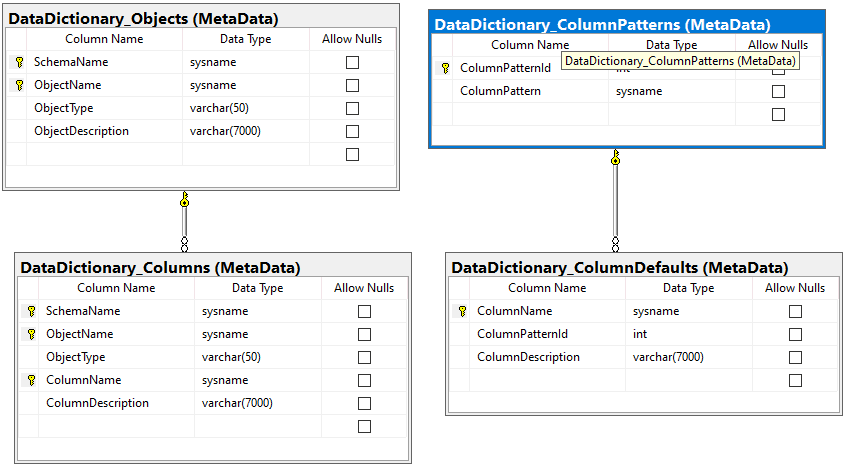
DataDictionary_ColumnPatterns will contain records similar to those below:
| ColumnPatternID | ColumnPattern |
| 1 | %DateKey |
| 2 | %CustomerKey |
DataDictionary_ColumnDefaults will replicate the function of the CASE statement from our earlier query.
- WHEN values stored in ColumnName
- THEN value stored in ColumnDescription
| ColumnName | ColumnPatternId | ColumnDescription |
| DateKey | 1 | The date on which the {schema.table} record was created. |
| DueDateKey | 1 | The expected delivery date. This should be within 3 days of the order date. |
| OrderDateKey | 1 | Identifies the date on which the customer placed the order. |
| ShipDateKey | 1 | The delivery date. By subtracting the order date by the delivery date we can identify instances where we are not satisfying the customer. |
| CustomerKey | 2 | The DimCustomer dimension presents properties of the customer but also those properties that allow us to dice/slice and aggregate such as gender, marital status, commute distance banding. |
We can create a view to apply these column descriptions.
CREATE VIEW MetaData.DataDictionary_ColumnDefaultDescriptions
AS
SELECT
OBJECT_SCHEMA_NAME(O.object_id) AS SchemaName,
O.name AS ObjectName,
REPLACE(O.type_desc, 'USER_', '') AS ObjectType,
C.name AS ColumnName,
REPLACE(CD.ColumnDescription, '{schema.table}', OBJECT_SCHEMA_NAME(O.object_id) + '.' + O.name) AS ColumnDescription
FROM sys.columns AS C
INNER JOIN sys.objects AS O
ON C.object_id = O.object_id
INNER JOIN MetaData.DataDictionary_ColumnPatterns AS CP
ON C.name LIKE CP.ColumnPattern
INNER JOIN MetaData.DataDictionary_ColumnDefaults AS CD
ON C.name = CD.ColumnName
WHERE O.type IN ( 'U', 'V' );
GO
Now we have that view we can use it to update our MetaData.DataDictionary_Columns table.
UPDATE DEST
SET DEST.ColumnDescription = SRC.ColumnDescription
FROM MetaData.DataDictionary_Columns AS DEST
INNER JOIN MetaData.DataDictionary_ColumnDefaultDescriptions AS SRC
ON SRC.SchemaName = DEST.SchemaName
AND SRC.ObjectName = DEST.ObjectName
AND SRC.ColumnName = DEST.ColumnName
WHERE DEST.ColumnDescription = ''What this has achieved is to turn our column description generator into a data driven mechanism. This makes the addition of rule based descriptions to our data dictionary or catalog a data change rather than a code change.
Harvesting key information for the data dictionary
We can take this a stage further. Our system tables tell us where we have primary and foreign keys therefore we can use these to generate default column descriptions as well.
Remember databases may be sparse on keys whether by design or by omission. This fact was the inspiration for Auto-suggesting foreign keys and data model archaeology.
Primary Key Descriptions
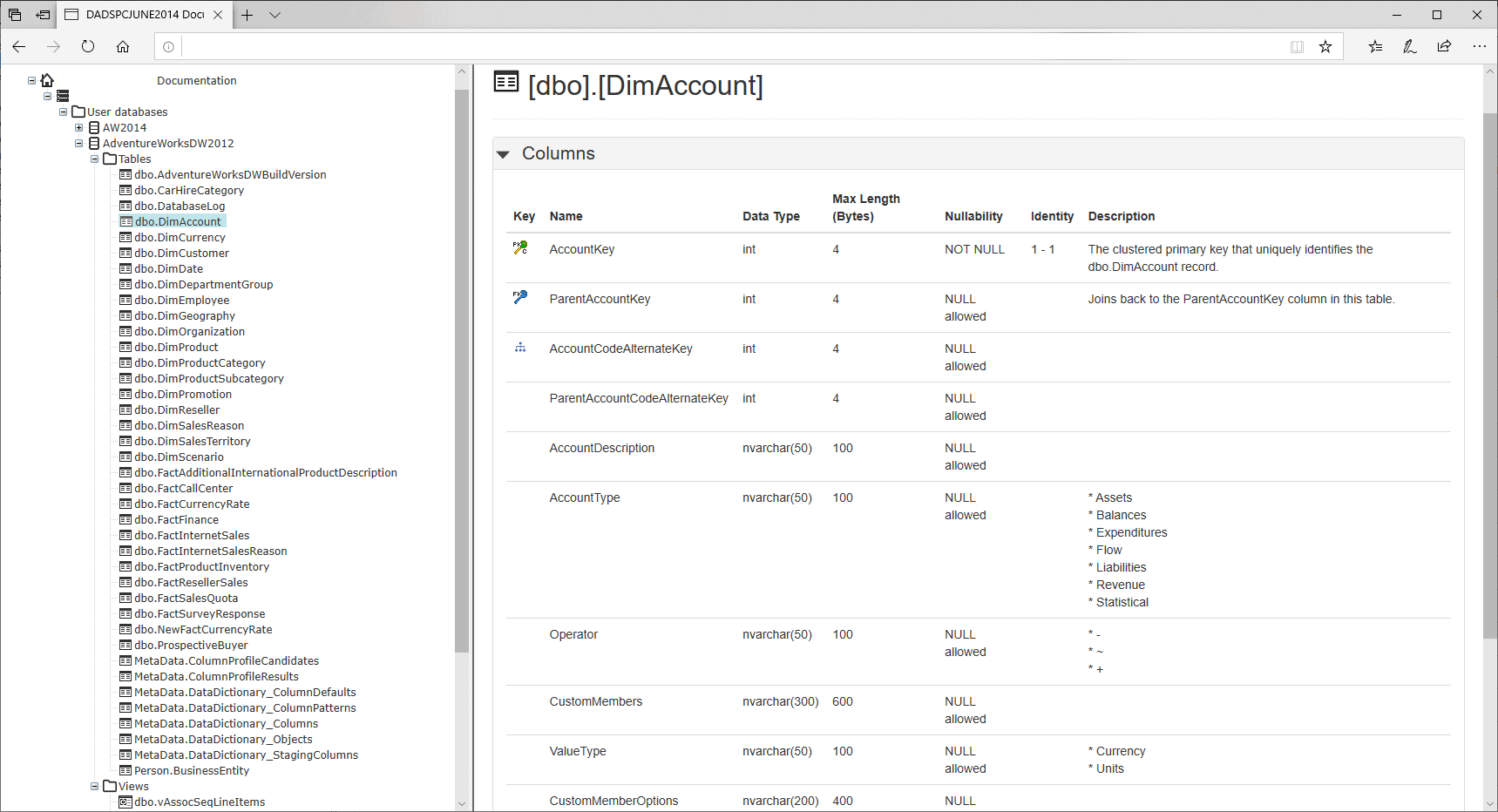
Redgate SQLDoc emphasizes columns participating in a Primary/Foreign Key with an icon. These include descriptions in the image alt text that can be picked up by screen readers. For those of us whose eyesight isn’t what it was but don’t use a screen reader a simple description will suffice.
CREATE VIEW MetaData.DefaultDescription_PrimaryKey
AS
WITH SingleColumnPK AS (
SELECT
I.object_id,
I.index_id,
MAX(LOWER(i.type_desc)) AS IndexType,
MAX(IC.column_id) AS column_id
FROM sys.indexes AS I
INNER JOIN sys.index_columns AS IC
ON IC.object_id = I.object_id
AND IC.index_id = I.index_id
WHERE I.is_primary_key = 1
GROUP BY I.object_id,I.index_id
HAVING COUNT(*) = 1
)
SELECT
OBJECT_SCHEMA_NAME(C.object_id) AS SchemaName,
OBJECT_NAME(C.object_id) AS ObjectName,
'TABLE' AS ObjectType,
C.name AS ColumnName,
'The '+ SCPK.IndexType +' primary key that uniquely identifies the ' + OBJECT_SCHEMA_NAME(C.object_id)+'.'+OBJECT_NAME(C.object_id)+' record.' AS ColumnDesccription
FROM sys.columns AS C
INNER JOIN SingleColumnPK SCPK
ON SCPK.object_id = C.object_id
AND SCPK.column_id = C.column_id
GO
Foreign Key Descriptions
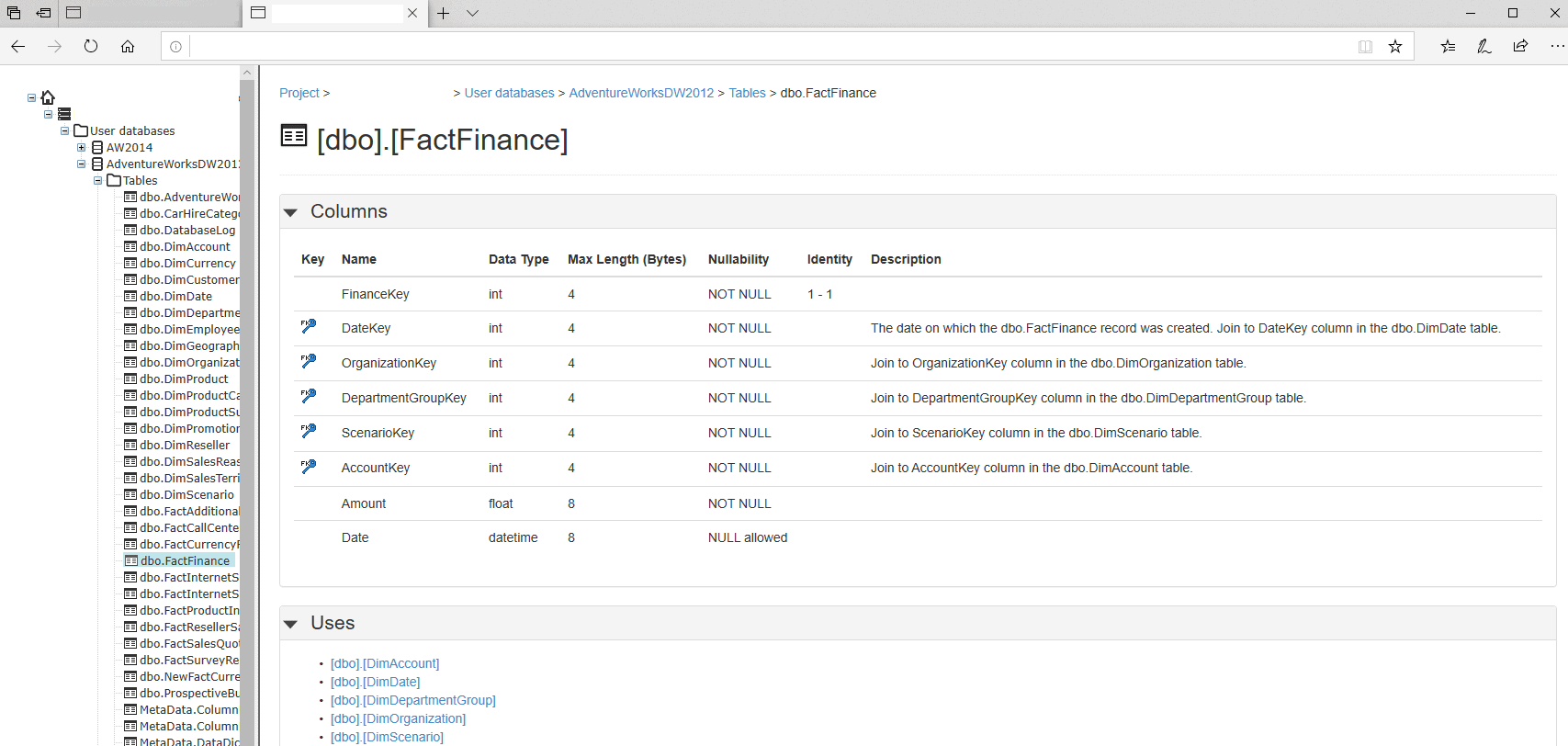
Assuming that there are foreign keys in the database then a simple description can be generated for single column foreign keys too.
CREATE VIEW MetaData.DefaultDescription_ForeignKey
AS
WITH SingleColumnFK AS (
SELECT constraint_object_id,parent_object_id
FROM sys.foreign_key_columns
GROUP BY constraint_object_id,parent_object_id
HAVING COUNT(*) = 1
)
SELECT
OBJECT_SCHEMA_NAME(FKC.parent_object_id) AS SchemaName,
OBJECT_NAME(FKC.parent_object_id) AS ObjectName,
'TABLE' AS ObjectType,
PC.name AS ColumnName,
CASE
WHEN FKC.parent_object_id = FKC.referenced_object_id
THEN 'Joins back to the ' + PC.name + ' column in this table.'
ELSE 'Join to '+FC.name + ' column in the '
+OBJECT_SCHEMA_NAME(FKC.referenced_object_id)+'.'+OBJECT_NAME(FKC.referenced_object_id) + ' table.'
END AS ColumnDescription
FROM sys.foreign_key_columns AS FKC
INNER JOIN SingleColumnFK AS SCFC
ON SCFC.constraint_object_id = FKC.constraint_object_id
AND SCFC.parent_object_id = FKC.parent_object_id
INNER JOIN sys.columns AS FC
ON FKC.referenced_object_id = FC.object_id
AND FKC.referenced_column_id = FC.column_id
INNER JOIN sys.columns AS PC
ON FKC.parent_object_id = PC.object_id
AND FKC.parent_column_id = PC.column_id
GOThe join criteria is particularly useful because it adds data lineage to a data dictionary or catalog.
Combining Default Descriptions with Foreign Key Information
We can concatenate the column descriptions from our two views to form an overall ColumnDescription:
- MetaData.DataDictionary_ColumnDefaultDescriptions
- MetaData.DefaultDescription_ForeignKey
CREATE VIEW MetaData.DefaultColumnAndFKDescriptions
AS
SELECT
COALESCE(CDD.SchemaName,DFK.SchemaName) AS SchemaName,
COALESCE(CDD.ObjectName,DFK.ObjectName) AS ObjectName,
COALESCE(CDD.ColumnName,DFK.ColumnName) AS ColumnName,
COALESCE(CDD.ColumnDescription,'') +COALESCE(' '+DFK.ColumnDescription,'') AS ColumnDescription
FROM MetaData.DataDictionary_ColumnDefaultDescriptions AS CDD
FULL OUTER JOIN MetaData.DefaultDescription_ForeignKey AS DFK
ON DFK.SchemaName = CDD.SchemaName
AND DFK.ObjectName = CDD.ObjectName
AND DFK.ColumnName = CDD.ColumnName
GOCharacter fields with a small number of values
Where there is a small reference table or a dimension where a column contains a small number of values, I prefer to list those values in the column documentation. This it to help the reader by reducing the need to jump to other pages to get the desired information.
For us to know when we have a small number of values, we have to profile our data or have some foreknowledge of the columns for which this is true. Data profiling can be an intensive operation so we should consider the nature of the dimensions.
- Short and wide such as a date or time dimension.
- Deep and wide such as a customer dimension
- Deep and narrow such as an email address dimensions
Identifying Profile Candidates
Due to the intensity of profiling I might build a table to enable me to flag those columns I wish to profile.
CREATE TABLE MetaData.ColumnProfileCandidates(
SchemaName sysname NOT NULL,
ObjectName sysname NOT NULL,
ColumnName sysname NOT NULL,
ApproximateRows BIGINT NOT NULL,
IncludeForProfiling BIT NOT NULL
CONSTRAINT DEF_ColumnProfileCandidates_IncludeForProfiling DEFAULT (1),
CONSTRAINT PK_MetaData_ColumnProfileCandidates PRIMARY KEY (
SchemaName,
ObjectName,
ColumnName
)
);
GOIn a dimensional data mart, such as Adventureworks2012DW, you could run a query similar to the one below to begin to identify columns that might meet the criteria for having a small list of values.
- Choose only NCHAR, NVARCHAR, CHAR, VARCHAR columns whose length is less than 100 and excludes xxxxCHAR(MAX)
- Only look at dimension tables
- Exclude columns that end in “Key”
- Provide the estimated table row count for the table
INSERT INTO MetaData.ColumnProfileCandidates(
SchemaName,
ObjectName,
ColumnName,
ApproximateRows
)
SELECT
SRC.SchemaName,
SRC.ObjectName,
SRC.ColumnName,
SRC.ApproximateRows
FROM (
SELECT
OBJECT_SCHEMA_NAME(O.object_id) AS SchemaName,
O.name AS ObjectName,
C.name AS ColumnName,
COALESCE(I.rows, 0) AS ApproximateRows
FROM sys.columns AS C
INNER JOIN sys.types AS T
ON T.user_type_id = C.user_type_id
INNER JOIN sys.objects AS O
ON O.object_id = C.object_id
LEFT JOIN sysindexes AS I
ON O.object_id = I.id
AND I.indid IN ( 0, 1 )
WHERE T.name LIKE '%char%'
AND O.type = 'U'
AND O.name LIKE 'Dim%'
AND C.max_length BETWEEN 1 AND 100
AND C.name NOT LIKE '%Key'
) AS SRC
LEFT JOIN MetaData.ColumnProfileCandidates AS DEST
ON DEST.SchemaName = SRC.SchemaName
AND DEST.ObjectName = SRC.ObjectName
AND DEST.ColumnName = SRC.ColumnName
WHERE DEST.SchemaName IS NULL;You can set the IncludeForProfiling flag to zero for any column you know will contain more values than is useful for generating descriptions.
Recording Profile Information
I want to record the profiling of the columns flagged in MetaData.ColumnProfileCandidates, so I create a table to do so.
CREATE TABLE MetaData.ColumnProfileResults(
SchemaName sysname NOT NULL,
ObjectName sysname NOT NULL,
ColumnName sysname NOT NULL,
NumberOfValues BIGINT NOT NULL,
CONSTRAINT PK_MetaData_ColumnProfileResults PRIMARY KEY CLUSTERED (
SchemaName ASC,
ObjectName ASC,
ColumnName ASC
)
)
GO
Against every qualifying column I want to run a COUNT(DISTINCT {column name}) AS NumberOfValues. To do this I have to generate the SQL command and execute it. I can do this using the stored procedure shown below.
CREATE PROC MetaData.RecordColumnProfiles
AS
SET NOCOUNT ON;
TRUNCATE TABLE MetaData.ColumnProfileResults;
DECLARE @SQLCommandList TABLE(SQLCommand VARCHAR(2000) NOT NULL);
DECLARE @SQLCommand VARCHAR(2000) = '';
INSERT INTO @SQLCommandList(SQLCommand)
SELECT 'INSERT INTO MetaData.ColumnProfileResults SELECT ''' + SchemaName + ''' AS SchemaName,''' + ObjectName
+ ''' AS ObjectName,''' + ColumnName + ''' AS ColumnName,COUNT(DISTINCT ' + QUOTENAME(ColumnName)
+ ') AS Occurrences FROM ' + QUOTENAME(SchemaName) + '.' + QUOTENAME(ObjectName) AS SQLCommand
FROM MetaData.ColumnProfileCandidates
WHERE IncludeForProfiling = 1;
WHILE @SQLCommand IS NOT NULL
BEGIN
SELECT @SQLCommand = MIN(SQLCommand)
FROM @SQLCommandList
WHERE SQLCommand > @SQLCommand;
IF @SQLCommand IS NOT NULL
BEGIN
EXEC (@SQLCommand);
PRINT @SQLCommand;
END;
END;
GO
Generating the Column Descriptions for the data dictionary or catalog
As there are twelve months in the year I will generate descriptions for any character column that holds up to twelve values.
SELECT * FROM MetaData.ColumnProfileResults WHERE NumberOfValues<=12;
I want to apply descriptions to my MetaData.DataDictionary_Columns table where any existing ColumnDescription is a zero length string. I will need a staging table the same structure as my target table.
CREATE TABLE MetaData.DataDictionary_StagingColumns(
SchemaName sysname NOT NULL,
ObjectName sysname NOT NULL,
ColumnName sysname NOT NULL,
ColumnDescription VARCHAR(7000) NOT NULL,
CONSTRAINT PK_DataDictionary_StagingColumns PRIMARY KEY CLUSTERED(
SchemaName ASC,
ObjectName ASC,
ColumnName ASC
)
)
GOInto this table I want to substitute the schema, table and column names into the query below, execute that query and put the results in my staging table.
SELECT STUFF
(
(
SELECT DISTINCT CHAR(13) + CHAR(10) + '* ' + {ColumnName}
FROM {SchemaName.TableName}
WHERE {ColumnName} IS NOT NULL
FOR XML PATH(''), TYPE
).value('.', 'NVARCHAR(MAX)'),1,2,''
);
GOTo do this we can use the same technique that we used to record the profiling information.
CREATE PROC MetaData.RecordColumnStagingDescriptions
AS
SET NOCOUNT ON;
TRUNCATE TABLE MetaData.DataDictionary_StagingColumns
DECLARE @SQLCommandList TABLE(SQLCommand VARCHAR(2000) NOT NULL);
DECLARE @SQLCommand VARCHAR(2000) = '';
INSERT INTO @SQLCommandList(SQLCommand)
SELECT 'INSERT INTO MetaData.DataDictionary_StagingColumns SELECT ''' + SchemaName + ''' AS SchemaName,''' + ObjectName
+ ''' AS ObjectName,''' + ColumnName + ''' AS ColumnName,REPLACE(STUFF((SELECT DISTINCT CHAR(13) + CHAR(10) + CHAR(42) + CHAR(160) + '
+ QUOTENAME(ColumnName)
+ ' FROM '
+ QUOTENAME(SchemaName) + '.' + QUOTENAME(ObjectName)
+ ' WHERE ' + QUOTENAME(ColumnName) + ' IS NOT NULL FOR XML PATH(''''), TYPE).value(''.'',''NVARCHAR(MAX)''),1,2,''''),CHAR(39),CHAR(39)+CHAR(39));' AS SQLCommand
FROM MetaData.ColumnProfileResults
WHERE NumberOfValues<=12;
WHILE @SQLCommand IS NOT NULL
BEGIN
SELECT @SQLCommand = MIN(SQLCommand)
FROM @SQLCommandList
WHERE SQLCommand > @SQLCommand;
IF @SQLCommand IS NOT NULL
BEGIN
EXEC (@SQLCommand);
PRINT @SQLCommand;
END;
END;
GOOnce the stored procedure is created and executed, we can run an UPDATE statement similar to the one we ran earlier.
UPDATE DEST
SET DEST.ColumnDescription = SRC.ColumnDescription
FROM MetaData.DataDictionary_Columns AS DEST
INNER JOIN MetaData.DataDictionary_StagingColumns AS SRC
ON SRC.SchemaName = DEST.SchemaName
AND SRC.ObjectName = DEST.ObjectName
AND SRC.ColumnName = DEST.ColumnName
WHERE DEST.ColumnDescription = ''We can run the MetaData.ApplyDataDictionary stored procedure to attach our descriptions to the object extended properties.
Examining our results in Redgate SQLDoc
We can use Redgate SQLDoc to generate our documentation. The two screen shots below give examples of what the generated column descriptions look like.
Possible enhancements for foreign key descriptions
Our foreign key descriptions apply one of two rules. One for when the foreign key references the same table, the other for when it references a different table. The generated descriptions for a foreign key will be
- Joins back to the {referenced column} column in this table
- Join to {referenced column} column in the {schema.table}
That is good enough for basic information and with the inclusion of the default column description can be a rich source of information. What if we wanted to add the MS_DESCRIPTION property from the referenced table? This would be simple enough to do although I would choose to have an additional TABLE_SUMMARY property. This would be explicitly to hold a brief description of what the referenced table allowed the analyst to do. It would not constraint us in what we wanted to put in MS_DESCRIPTION.
Worked example using DimDate as the referenced table
Let us suppose that dbo.DimDate has a TABLE_SUMMARY property. The value of that property is “The date dimension provides a mechanism to dice/slice and aggregate facts by various date parts thereby eliminating the majority of date calculations.”
We could harvest the TABLE_SUMMARY for the referenced table so that the description in the fact becomes a concatenation of three things:
- Default description for a column with a specific name
- Description of the join
- TABLE_SUMMARY description
Our view to retrieve foreign key descriptions would change to the following.
CREATE VIEW MetaData.DefaultDescription_ForeignKey
AS
WITH SingleColumnFK AS (
SELECT constraint_object_id,parent_object_id
FROM sys.foreign_key_columns
GROUP BY constraint_object_id,parent_object_id
HAVING COUNT(*) = 1
)
SELECT
OBJECT_SCHEMA_NAME(FKC.parent_object_id) AS SchemaName,
OBJECT_NAME(FKC.parent_object_id) AS ObjectName,
'TABLE' AS ObjectType,
PC.name AS ColumnName,
CASE
WHEN FKC.parent_object_id = FKC.referenced_object_id
THEN 'Joins back to the ' + PC.name + ' column in this table.'
ELSE 'Join to '+FC.name + ' column in the '
+ OBJECT_SCHEMA_NAME(FKC.referenced_object_id)+'.'+OBJECT_NAME(FKC.referenced_object_id) + ' table.'+ COALESCE(' ' + CAST(EP.value AS VARCHAR(MAX)),'')
END AS ColumnDescription
FROM sys.foreign_key_columns AS FKC
INNER JOIN SingleColumnFK AS SCFC
ON SCFC.constraint_object_id = FKC.constraint_object_id
AND SCFC.parent_object_id = FKC.parent_object_id
INNER JOIN sys.columns AS FC
ON FKC.referenced_object_id = FC.object_id
AND FKC.referenced_column_id = FC.column_id
INNER JOIN sys.columns AS PC
ON FKC.parent_object_id = PC.object_id
AND FKC.parent_column_id = PC.column_id
LEFT JOIN sys.extended_properties AS EP
ON FKC.referenced_object_id = EP.major_id
AND EP.minor_id=0
AND EP.name='TABLE_SUMMARY'
GOThe combination of techniques discussed so far can provide rich information for our data dictionary or catalog with remarkably little effort. Think carefully about how we structure and phrase the table descriptions with reuse in mind. Certainly, in a dimensional model it could reduce the amount of manual effort by more than half.
Potential objections to the auto-generation technique
The beauty of a relational database is that the implementation of Codd's rule 4 means that the object metadata is usefully descriptive of the objects within the database. It is easy to generate a useful, human readable description of columns participating in a primary or foreign key relationship.
Arguments against are likely to be that for the operational database:
- It does not utilise foreign keys
- It must not be used for non-core business use
Fortunately, users of Redgate tools have mechanisms for addressing these.
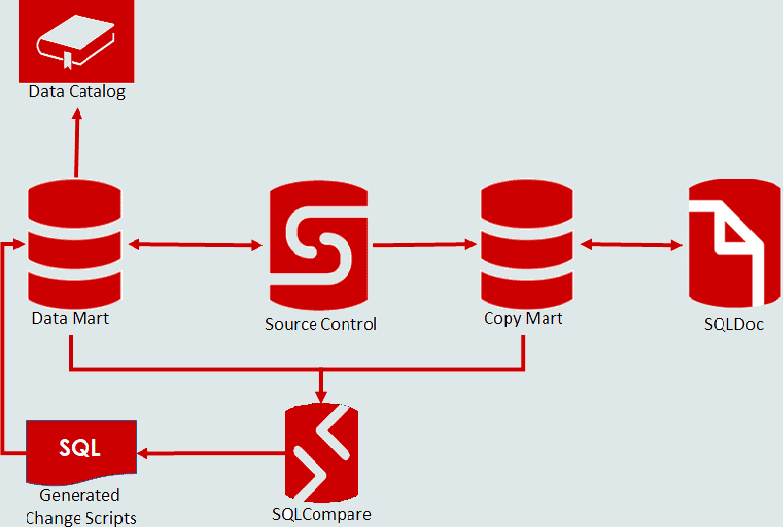
The approach you could take is illustrated in the diagram above.
- Take a copy of the data mart from source control
- Apply any absent keys
- Generate descriptions
- Use SQLDoc to amend or add any other descriptions
- Use SQL Compare to generate change scripts to apply the extended properties
- Apply to the data mart and commit to source control
Concluding thoughts
My experience when it comes to documenting a database is that the size of the effort is always a barrier to doing it. Consequently opposition to providing documentation is always quite vocal. From a documentation perspective you can gain substantial coverage of the database using the techniques described above. Hopefully this will reduce the decibels emitted by the naysayers.
Devising rules for retrieving column information and generating descriptions is an art. Certainly writing reusable table descriptions that can be concatenated with generated foreign keys descriptions is too. The goal is to gain a critical mass of documentation where adding further documentation becomes a matter of adopting development practises.
- Append descriptions when you create objects
- Fill in descriptions that are blank when you amend objects
- Make tests for empty descriptions part of your build mechanism
- Ensure that any failing tests break your build
The payback is a source of information about our databases that is educational and information. An ideal start for a data dictionary or catalog.

