

One of the really powerful things with SQL Clone is that it allows for multiple copies of a database without using much space. There are some advantages of this over other methods of copying databases, such as SAN snapshots, backup/restore, etc. In addition, unlike database snapshots, a SQL Clone database is writeable. You can read more about the details of the technology in Tony Davis’ piece, Database Provisioning: getting started with SQL Clone.
Let’s see this in practice.
Getting a Blank Table
I’ve got a copy of the StackOverflow database on my machine. This is a large database, and makes for a good place to test some large queries. As you see below, this is a 90+GB database.
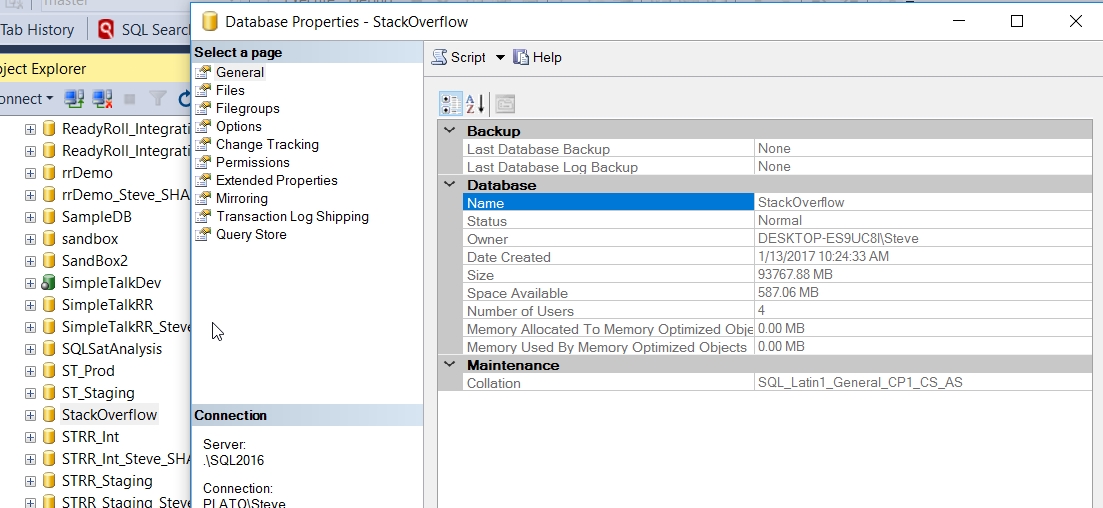
This currently exists on my F: drive. While I have space, I don’t want to make too many copies of the database or I’ll have space issues.
However, SQL Clone makes this process safe and easy. I create a data image, from a database or a database backup, and from that image I can easily make as many clones, of this database as I might need. Let’s start by creating a new data image, and see how this works.
Creating the data image
When I first connect to my SQL Clone Server, I get a nice dashboard. This is the first place to start. In my case, I’ve already installed the agent and created a service account for my SQL Clone Agent service.
I’ve also set a local location for storing data images. In my case, this is e:\SQLCloneImages. Right now there’s nothing in there as I cleared my images for a test. Let’s create a new image.
I’ll click the blue button and see this.
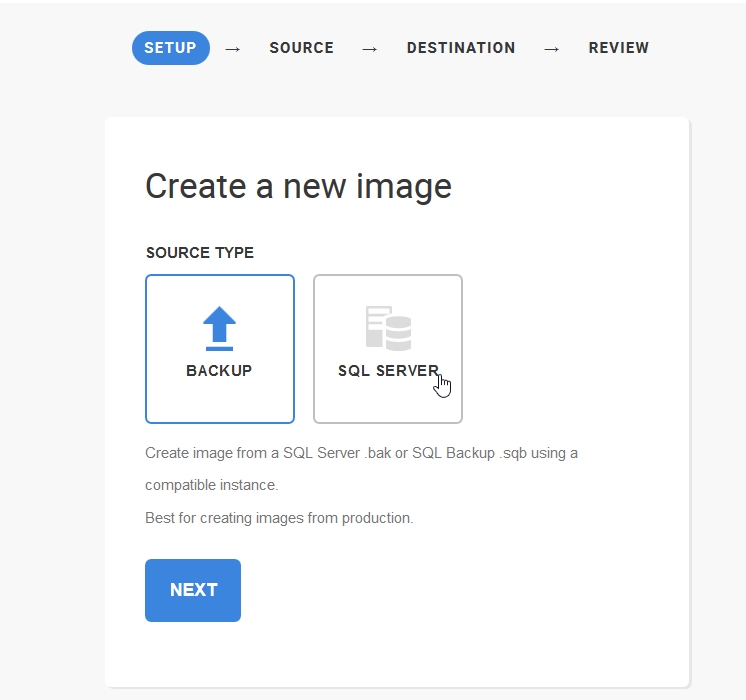
This is where I start. I don’t have a backup of this database, so I’ll click SQL Server. Once I click “Next”, I get this screen. I’ve previously used my SQL2016 named instance, so it’s in the drop down. I could easily add a new instance if needed.
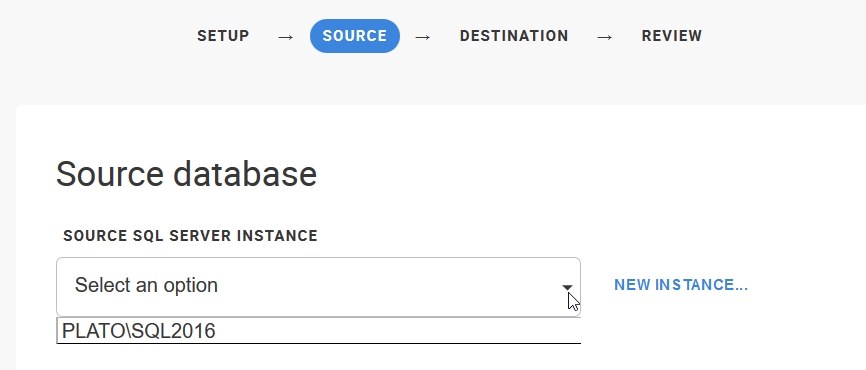
Once I do that, I get the next screen, asking for my source database. In this case, I’ll select the StackOverflow database.
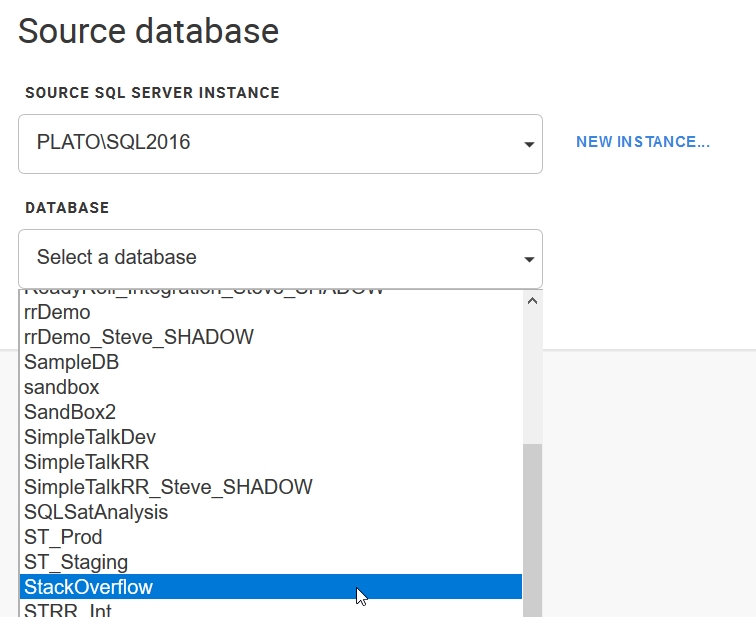
After I pick the database, I need to select a location for the image. This is the full data set, which in my case will be 90+GB. I’ve previously set a location, so it’s in my drop down.
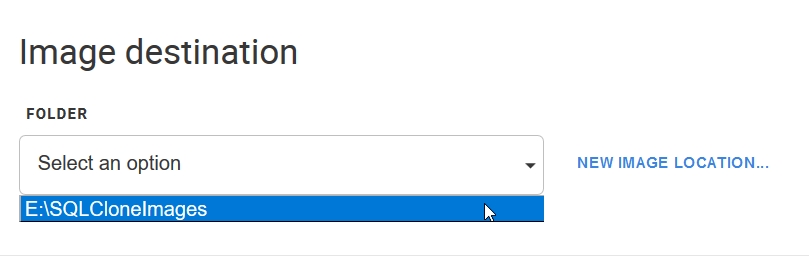
I pick the location and then I get a confirmation screen. Here I can see my selections, and I also can enter a name for the image. In this case, I’ll pick the db, the date, and a base note. This will be the base image from which I’ll create clones.
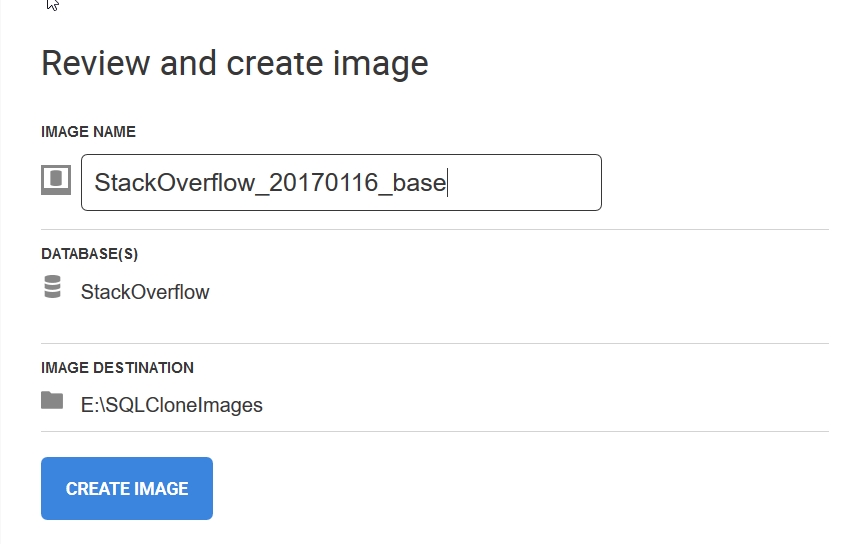
As soon as I click “Create Image” the process begins. The agent is handling this, with updates being sent to the web browser.
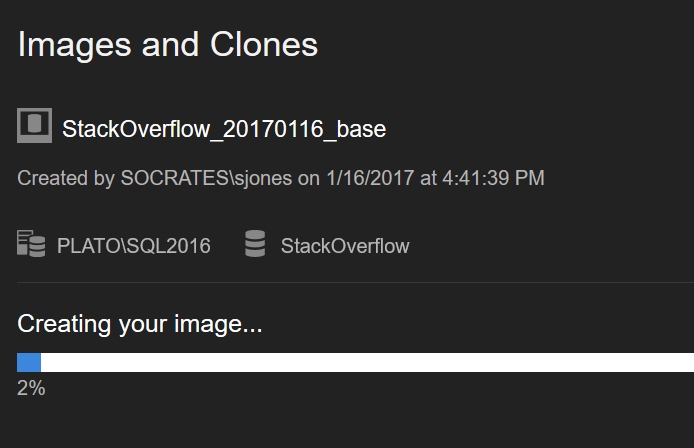
This process takes a bit of time. After all, it’s essentially the same as taking a full backup. Once this is complete, I can start getting work done. As an FYI, this took about 50 minutes on my machine.
The Problem – running frequent tests against large databases
Let's say I'm developing a new feature for StackOverflow, which accesses data in one of the base tables, say the Posts table. One of the things I’d like to do is test some data inserts on the Posts table. However, I don’t want to mess with the full size table, which is 73GB. I want to truncate it. I can easily do that, but then what if I need the full table for some other tests? Do another restore? Not practical and not fun. Unless I get to start the restore in the morning, go skiing all day, and come back to work later.
SQL Clone makes this easy. Having created the initial data images, I can use it to build a new database (a clone) very quickly.
In the SQL Clone dashboard, I can see a summary of existing images and their associated clones. In this case, I have just the SO image I just created, and a few links to help me create a clone.
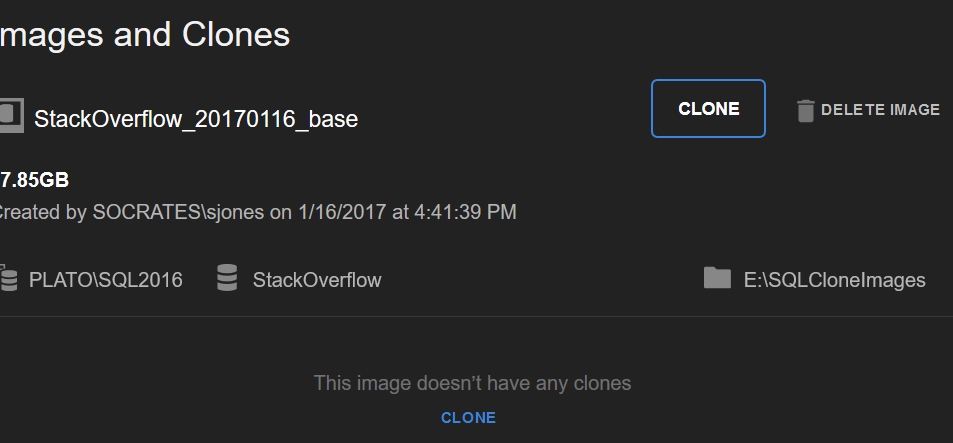
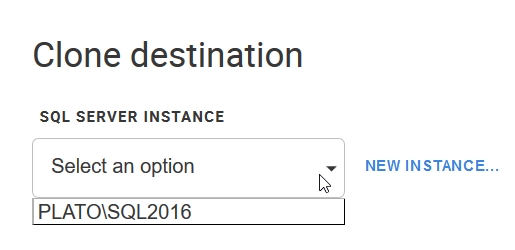
Once, I pick the required image and hit "Clone", I enter a familiar workflow. First, pick an instance.
Then give a database name for the clone.
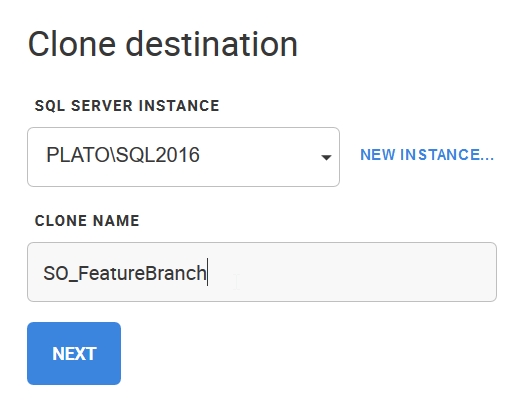
Confirm my choices and click clone.
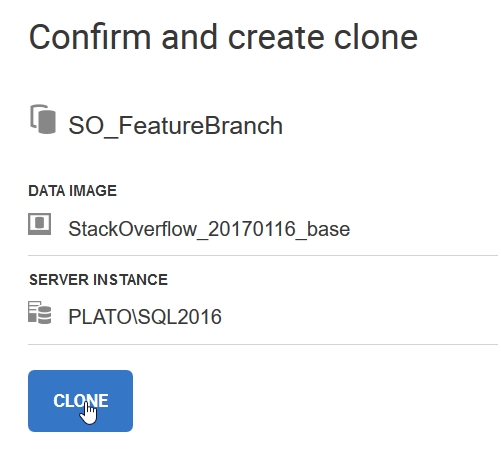
The clone took about 6 seconds to create. I see it in the dashboard:
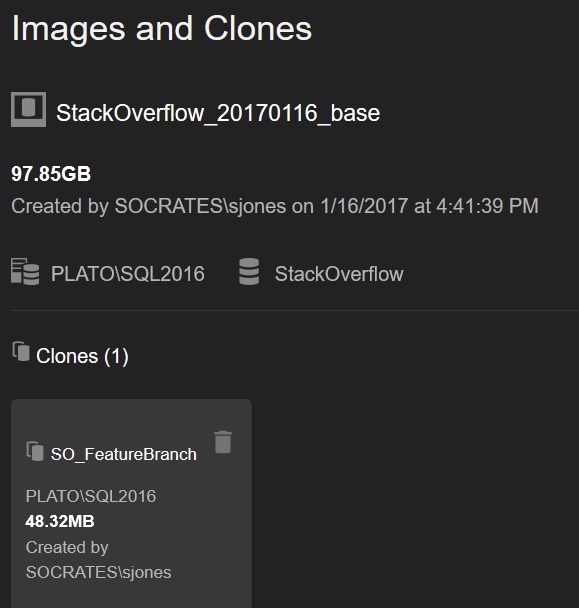
If I go to SSMS, I’ll see the database there as well. I do need to refresh the database list. Once I do that, I can select the database and get its properties. Note that this looks just like the original database at 90+GB.
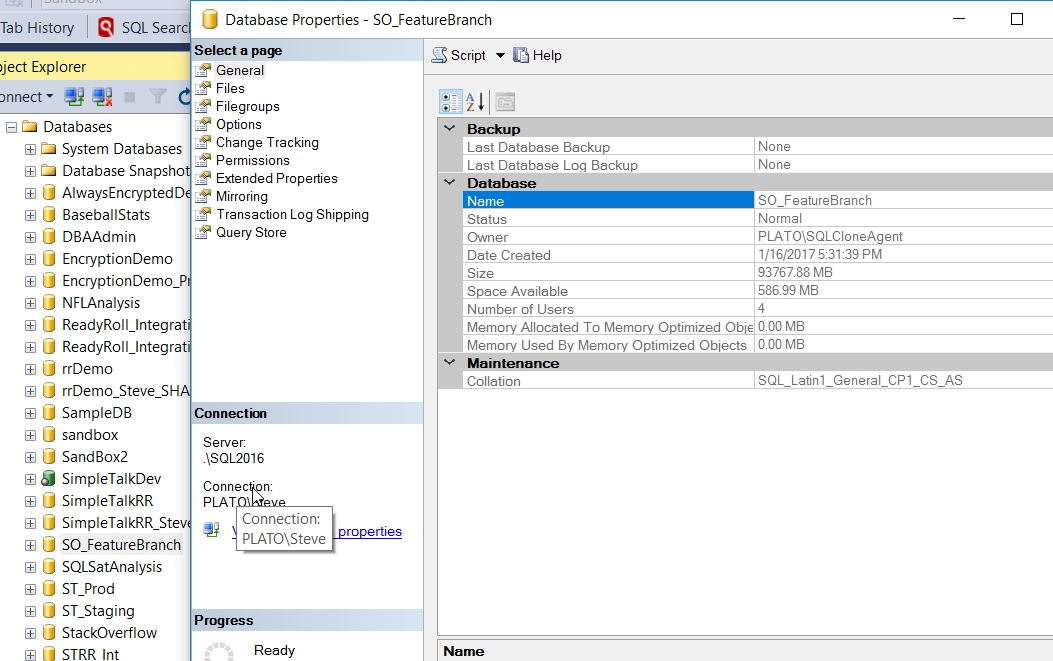
If I open a query window to this database clone, I can query the Posts table. I see the full posts table, which has a lot of posts (almost 30 million).
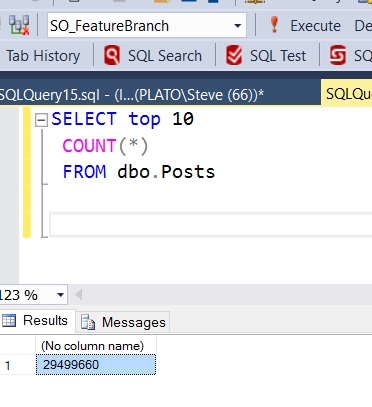
Now, let’s truncate the table and then add a row back.
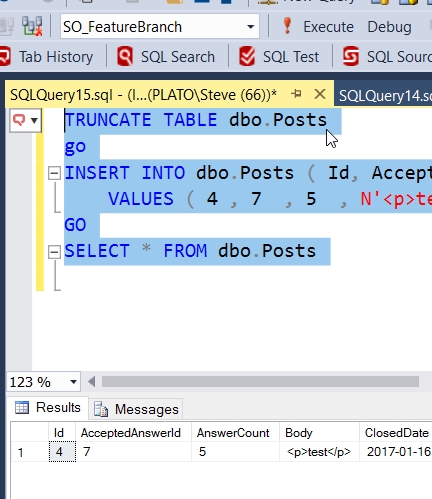
Now, there is only one row here, but if I check my original database, I’ll see that it still holds close to 30 million rows. The data image, from which we created the clone, is completely unlinked from the original database and changes to a clone do not affect the image, the original database, or any other clone.
I can do whatever I want to this test database, which took 6 seconds to create, and use it as needed in development. If I need another copy, or a few more, I can easily create those. In fact, I’ve created 3 other clones, each taking 6-10 seconds to create. Each of them looks like a full sized StackOverflow database.
 All of the clone databases have the same properties and size as the original database, as far as SQL Server is concerned.
All of the clone databases have the same properties and size as the original database, as far as SQL Server is concerned.
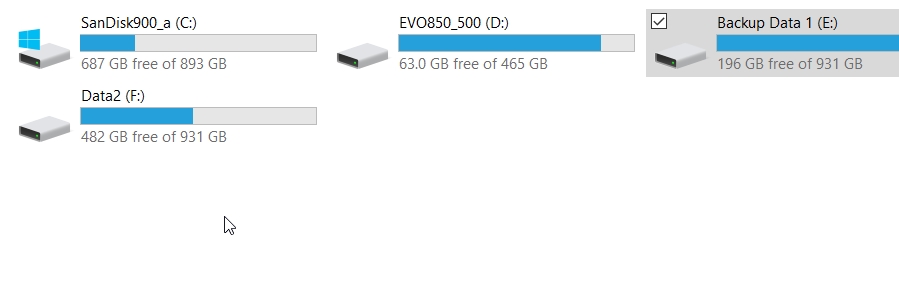
I now have 4 copies of a 90+GB database, but my disk space on the F: drive is only the 95GB less than it was when I started. This is because my clones are using tens of MB in actual space.
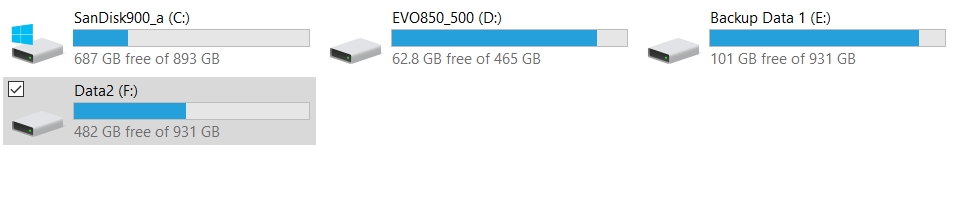
In my dashboard, I can see the actual size of each clone. My first clone is bigger because I made some changes, and those changes to data are written to the differencing disk, which is the space I actually need for the clone.
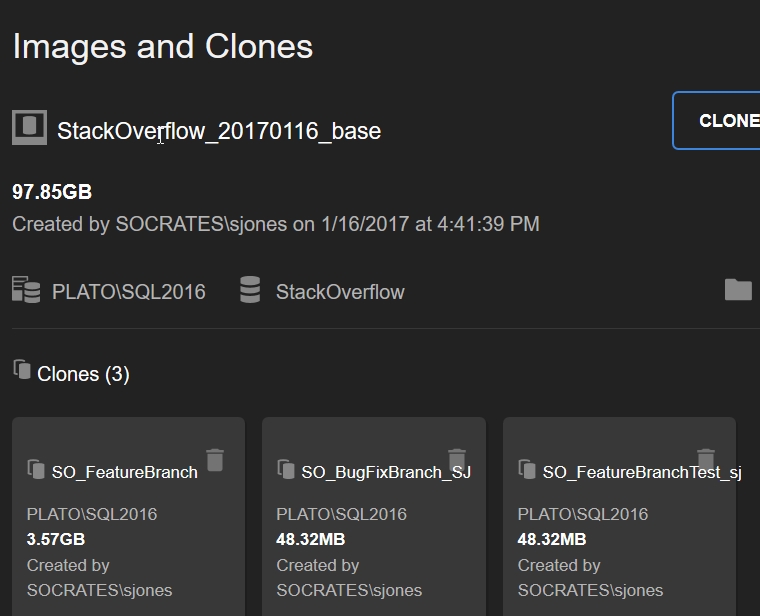
If I decide that I’m done testing, I can easily remove one of these clones without affecting the other clones, the image, or the original database. In fact, I can experiment on a clone, drop it, and recreate another one in seconds.
SQL Clone and the Experimental Developer
In order to use SQL Clone, I do need an image file, which is a full size copy of the database. While this can easily be on a share that everyone can access, I can certainly keep an image file on my local machine. Then with the SQL Clone Agent, I can create new clones as needed, from this image file, adding and dropping clones on my local SQL Server instance.
Even though I’m disconnected from the SQL Clone Server, I can still work with my existing clones. This allows me to keep working on the road, testing and changing the databases as needed for my database development work.
SQL Clone is a great option for allowing developers to experiment in sandbox environments, with full copies of large databases, without the hassle and delays of restoring backups or copying database files.
