

Real Time Update Scenarios
Recently a client has described a need for real time (or near-real time) movement of data from their operational logistics application to an analytics/reporting visualization environment where presentation tools such as Microsoft Reporting Services, Business Objects or QlikView consume the data. First we will focus on the "Real Time" update scenarios. We can address presentation in a separate document. Based on the discussion we noted three possible approaches to solving this problem.
1. Replicate Tables using SQL Server Replication and use Business Objects directly against the OLTP.
2. Utilize a real time update process (Informatica/SQL Server) to incrementally update tables and use Business Objects directly against the OLTP.
3. Use a OLAP or Memory based approach, using various compression techniques, eliminating the need for additional relational tables and SQL based query tools.
In our discussion several vendors were mentioned:
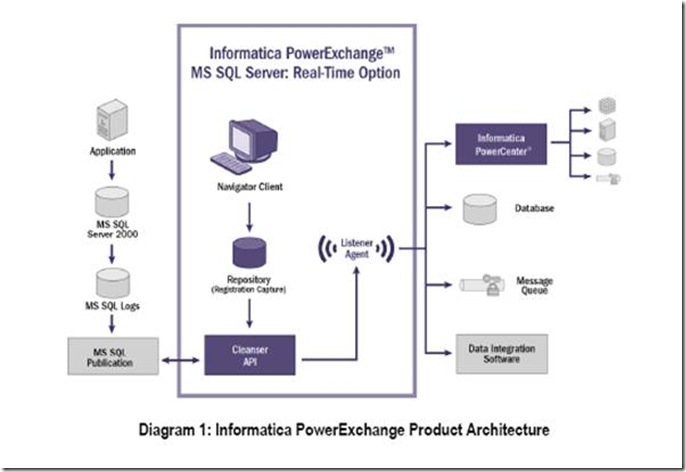
1. Informatica via Informatica PowerExchange™:MS SQL Server Real-Time Option for updated relational tables. This is a change data capture tool.
2. QlikView – A Memory based reporting and querying tool.
3. SQL Server 2005 – Microsoft DBMS , OLAP and associated applications (SSIS – SQL Server Integration Services, SSAS – SQL Server Analysis Services)
There are other solutions that are not relational based such as Netezza or Sand Technology. I would suggest a brief review of Gartner current analysis as it relates to real time updates.
I would like to add the observation that the transfer problem is a separate logical problem from the analysis visualization problem. The three tools discussed all approach the problem completely differently. Only QlikView attempts to present a solution that combines the two.
There are two approaches to near-real time analytics. They are as follows:
Operational Analysis based on loading the source data into compressed proprietary data stores without transformations (Cleansing, Normalization, Hierarchies). This will provide analytical capabilities including metrics relationships and hierarchies that exist in the data model being sourced.
The limitations here are no trending, history or complex business rules, metrics that require corporate reference data such as product or organization hierarchies.
A benefit in relation to the extraction process is this approach does not require any staging area.
Traditional Business Intelligence is based on a metadata driven approach were the source data is transformed to properly analyze a specific set of business metrics and their associated business process hierarchies, including trending and history.
A limitation of approach will require a more complex extraction and loading process and a staging area.
A major benefits is this approach will "insulate" the reporting or analytical layer from any changes or additions to the source. This is accomplished through using a data driven approach and creating a business dimensional oriented semantic layer. In most cases the metric and dimensions math the business processes and do not change over time, where as the source data and nomenclature is volatile.
I conducted a brief analysis of the vendors mentioned and have the following observations:
Informatica– There "Real Time" offering for Microsoft relies on SQL Server 2005 Replication and Publishing and concentrates on providing CDC (Change Data Capture" technology for applications without time date stamps of update switches.
a. This would require replicating the existing database model and reporting directly against it or developing a dimensional model.
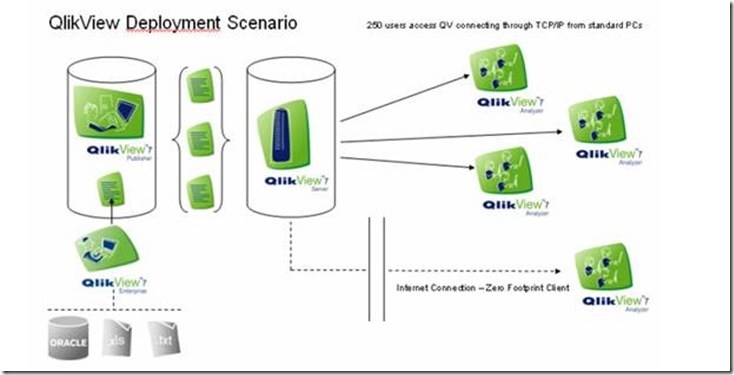
QlikView– This is a Memory based tool requiring various QlikView servers for processing and publishing the QlikView’s based on the QlikView Publisher. QlikView has a wizard to create load and transformation scripts. It assumes relationships based on same named fields. In most cases per the recommendation this needs to be manually modified.
SQL Server 2005 Analysis Services is similar to QlikView in architecture. The specific "real time "features are Snapshot Isolation and Proactive Caching. Snapshot Isolation insures the data extracted is kept in sync by only pulling data available when the first table is queried. Defining Caching Policies Analysis Services provides high query performance by maintaining a cache of the underlying data in a form optimized for analytical queries. The new Analysis Services 2005 proactive caching feature provides a way for the cube designer to define policies that balance the business needs for performance against those for real-time data. The system runs on "auto pilot," without the need for explicit processing.
Different policies allow for quite different behaviors. For example:
- Automatic MOLAP. Real-time data.
- Scheduled MOLAP. The cube is simply refreshed periodically, irrespective of updates to the source data.
- Incremental MOLAP. The cube is refreshed incrementally with new data in the source database.
- Real-time ROLAP. The cube is always in ROLAP mode, and all updates to the source data are immediately reflected in the query results.
The proactive caching settings can be set on each different Analysis Services object (dimension and partition). This provides great flexibility in cases where the policies and the tradeoffs between performance and latency vary for different parts of the cubes .
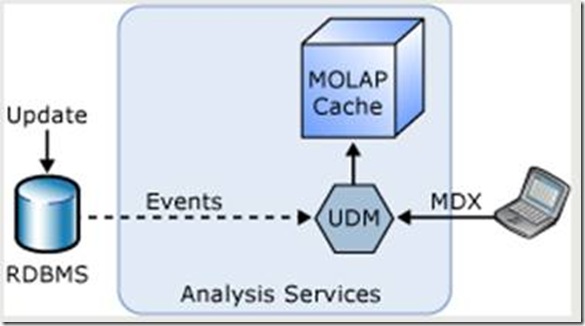
Microsoft Cubes in conjunction with the SSIS (Pipeline Architecture) and UDM (Universal Data Model) do not require any staging.
Recommendations: I would recommend a POC(Proof of Concept) and the creation of two scenarios, focusing on the two OLAP type options using QlikView and SQL Server 2005 Analysis Services. As part of the scenarios I suggest:
Validating existing business requirements including metric formulas and required hierarchies
Defining the metadata driven Extraction Architecture (independently of tool).
In reviewing the two tools it is apparent the extraction processes would be similar and SQL based, but relying on different scheduling and/or scheduling processes. Also it would seem using views for database would be rejected out of hands due to performance. A best practices Extraction Architecture would require a metadata driven application architecture that would be data aware of structure or content (domain) changes and automatically adjust load processes accordingly. Each solution would probably require replication. The focus of completing the scenarios would be to evaluate the gaps each of the recommended scenarios/tools have against Extraction Architecture requirements, effort and skill set required to complete the POC.
Scalability
For QlikView you would need to manually design our queries. In their documentation they mention loading 4 Million rows per minute, without knowing the number of columns or hardware configuration this not very informative.
MSAS Using the UDM and Distributed Query capability of MSAS is capable of 120,000 rows per second or 7 million rows per hour on a Dual-core Xeon (EM64T). [1]
Testing Approach – I would require full volume testing based on several documented update scenarios and the full spectrum of user queries and the testing of dynamic queries or queries determine if you will need joins in QlikView or Hierarchies in MSAS
Source DB impact – We would need to inform and involve the Source DB team in our Extract Architecture and work toward direct access to their tables, most likely in a replicated environment. Each tool (MSAS, QlikView) recommends extracting only the necessary attributes and rows and requires manually adjusting same named fields and joins..[2]
Team Structure – I would structure the team around the Extraction Architecture with individuals focusing on Source Profiling, Source Extraction, Load Scripts/Design and finally presentation.
[1] Microsoft SQL Server 2005 analysis Services Performance Guide
[2]Actually QlikView requires significant manual coding for loading. Specifically QlikView assumes all like field names are keys and attempts to create joins, these must be hand coded for only the required fields FAQ 7 in their doc.
Ira Warren Whiteside
Actuality Business Intelligence
"karo yaa na karo, koshish jaisa kuch nahi hai"
"Do, or do not. There is no try."

