

Partitioning is a powerful technique used to enhance performance, scalability and ease administration of cubes (especially large cubes) in SQL Server Analysis Services. However, this technique is not as well known among developers as it is supposed to be. In this article, we will talk about partitions in Analysis Services, by answering some of the questions that will cover most aspects of partitions.
1. What are partitions?
A partition is a physical unit of storage that contains a subset of the Analysis Services database data. By default, every measure group has a single partition containing the entire data. When you create multiple partitions, the measure group represents the combined data stored in all its partitions.
2. Why should I create partitions?
Here are some of the advantages of creating partitions:
- Partitions can be spread across multiple physical drives allowing parallel data access which Analysis Services can access data in multiple drives at the same time.
- For each partition, you can use a different aggregation design and storage mode, though they belong to the same measure group. This is an excellent option that will improve query response time. For example, let’s say you have a cube with yearly partitions, since the partition for the current year is most likely to be queried often, you will want to create a higher aggregation design for that partition. With higher aggregation design, Analysis Services will create higher number of aggregations (pre-calculated summaries of data) instead of computing them at run time, thus improving the query response time.
- Partitions can be processed independently. For example, if you have yearly partitions (which is quite common) you can save a lot of processing time by processing only the current year partition when data is added to the cube. Since data in previous year partitions generally will not change, you can leave them as they are.
- Partitions can be processed in parallel thereby utilizing the system resources (CPU, memory etc) efficiently. This means that multiple partitions can be processed at once. As said before, the degree of parallelism will be constrained only by the hardware and server workload.
- Analysis Services can extract data from multiple partitions in parallel when a query is executed against the server which will result in efficient utilization of system resources (CPU, memory etc). This will significantly enhance query performance as long as you have enough processor resources, sufficient memory and enough disk resources.
- If you have multiple partitions, Analysis Services will only scan the partition that has the required data to satisfy the query which will in turn improve performance because of reduced IO operations. In short, Analysis Services will query less data.
- Each partition in a measure group can use a different fact table, and these fact tables can be from different data sources. This option will be very helpful especially when you have a large fact table that is physically split into multiple tables.
3. What is stored in partitions?
Analysis Services stores both Fact (detail) and summarized (aggregated) data in each partition. It also stores aggregation design, Proactive caching settings, etc. in each partition.
4. Are there any restrictions while creating partitions that I need to be aware of?
You have to have Enterprise Edition to be able to create partitions. Standard edition is limited to one partition per measure group, which is the default behavior.
When creating multiple partitions, you need to make sure that for a measure group, the data in one partition is exclusive of the data in any other partition to avoid duplicate rows in the measure group which will produce wrong results. In short, data in each partition should be unique.
To add partitions, you need to have administrative privileges on the Analysis Services server. If you are a local administrator on your machine, then you will be a member of the Analysis Services Administrators role by default. This role has absolute rights to the entire system.
A partition must have the same structure as the measure group; all partitions in a measure group must contain the same fields with the same data types as that of the measure group.
If you intend to merge partitions later (which is very common), be sure to have same storage mode and aggregations for the partitions that you intend to merge. For instance, let’s say you have a measure group to store sales data and in this measure group, you have created two partitions - One partition to store data for the current year and the other partition to store data for all the previous years. At the end of each year, you merge the current partition into previous year partitions and create a new partition for the coming new year. In this scenario you will need to have the same storage mode and aggregation for the two partitions. In short, partitions can be merged if and only if they have the same storage mode and aggregation design.
5. How do partitions affect end users?
Partitions are transparent to the end users. So no matter how many partitions you have for each measure group in your cube, for the business user, it’s the same as having a single partition for each measure group.
6. When should I create partitions?
As a general rule of thumb, if your measure group has a record count of less than 20 million and you are not experiencing any performance issues, then you generally don't need to worry about creating partitions. But when the record count is way over 20 million and the end users experience slow query response time, you might want to think about creating partitions.
7. How should I split the data in my partitions?
The most commonly used strategy is to partition by time; however it depends on the requirements and needs of the business users. Let me give a couple of real time scenarios:
In our company we have a single cube used by over 400 users. There are over 10 Lines of Service and each line of service has multiple Practice Areas. Users seldom request queries that span across multiple line of services, so it makes sense to create a partition for each line of service if data in the cube continues to grow and users experience slowness.
We have a client, a travel services company. The company offers travel programs (trips) to different parts of the world and there were over 50 programs in total. Out of these 50 programs, two programs contribute to more than 70% of the total revenue generated by the company, almost every year. From the query patterns, we found users often requesting data related to these two programs. Also, it is obvious that user analysis will be based on programs (trips). The company had an Analysis Services cube with two partitions - one for the current year and the other one for all the previous years. But users were not at all happy with the performance, so we decided to change the partition design. The new design has 4 partitions in total:
i. The first partition is for the current year and the two programs that contribute to more than 70% of revenue.
ii. The second partition is for the current year and the rest of the programs that are not included in the first partition.
iii. The third partition is for all the previous years (except the current year) and the two programs that contribute to more than 70% of revenue.
iv. The fourth partition is for all the previous years (except the current year) and the rest of the programs that are not included in the third partition.
This increased the performance drastically and users were pretty happy.
8. Is there a wizard in BIDS (Business Intelligence Development Studio) for creating partitions?
Yes, you can use Partition Wizard to create partitions. Let’s create yearly partitions for the Internet Sales measure group in the sample Adventure Works Analysis Services Database. Open the Adventure Works analysis services project in BIDS, in the solution explorer, double click the Adventure Works cube and click on the partitions tab as shown in the figure below.
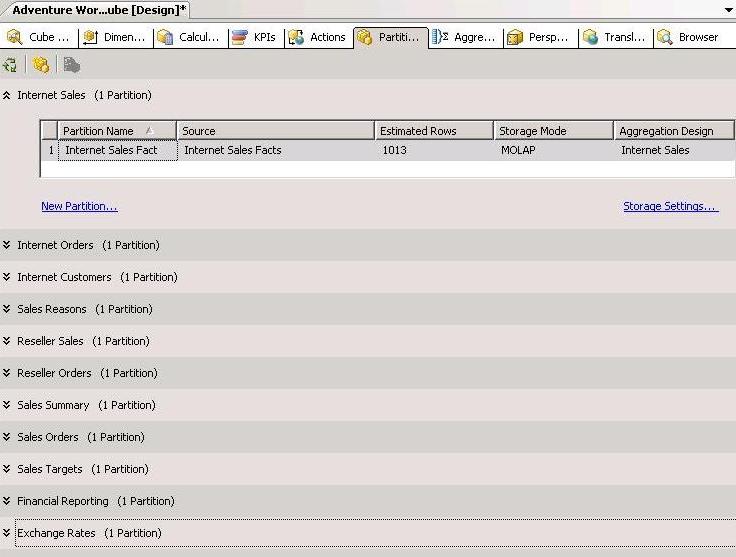
The partitions tab will be opened as shown in the figure below. By default, first partition of the cube will always be expanded when the partitions tab is first opened, while all other partitions are collapsed.
As mentioned before, by default, every measure group has a single partition containing the entire data and this partition is set to use Table Binding. If you intend to use a single fact table for all the partitions, and use a where clause to separate data for each partition, change the Binding Type to Query Binding, if you however, intend to use a separate fact table for each partition, use Table Binding. Since we will be using Query Binding, let’s change the Binding Type to Query Binding before creating any new partitions. To do that, right-click the ellipsis button on the Source column in the Internet Sales partition section as shown in the figure below.
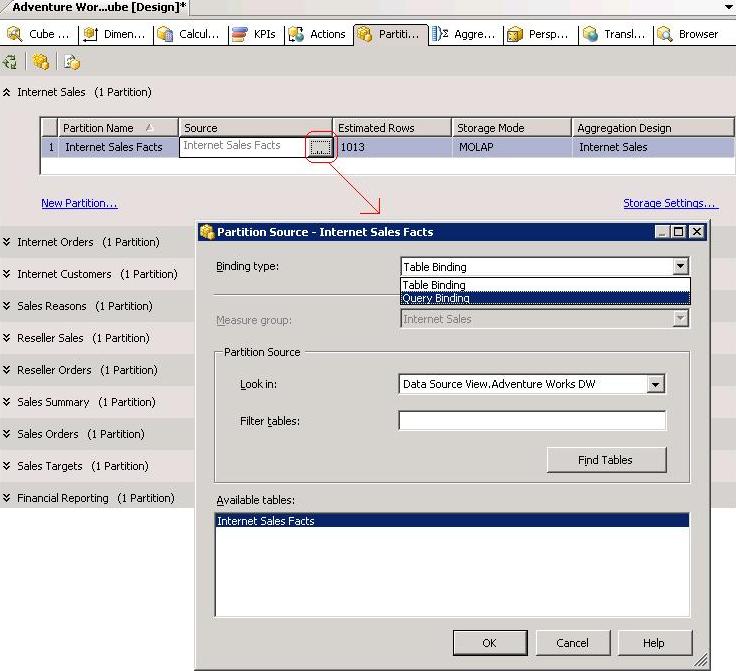
In the Partition Source dialog box, change the binding type to Query Binding using the drop-down list as shown in the figure above. As soon as the binding type is changed to query binding, the dialog box will be populated with a select statement that includes all the columns from the fact table as shown in the figure below. However, the WHERE clause of the query will be empty, so you will need to add a condition to filter out data that you don’t want to be in the partition.
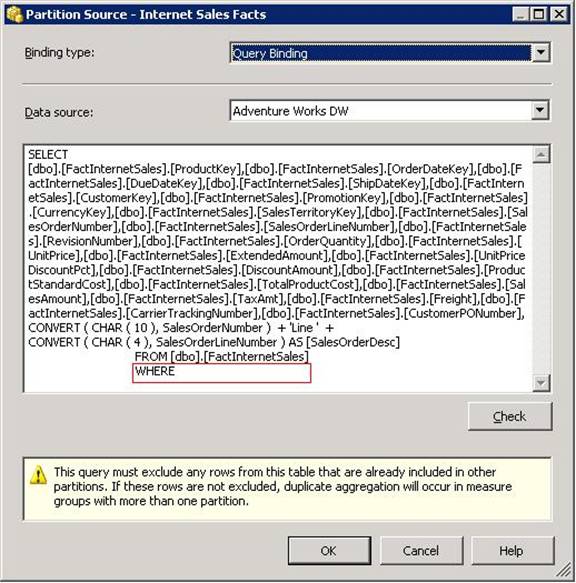
The Adventure Works database has data starting from the year 2005, so the where clause for the first partition should be WHERE OrderDateKey <= '20051231' as shown in the figure below. Also, note that the data in each partition has to be unique to avoid duplicate rows. This is also indicated by the following warning in the dialog box: This query must exclude any rows from this table that are already included in other partitions. If these rows are not excluded, duplicate aggregation will occur in measure groups with more than one partition.
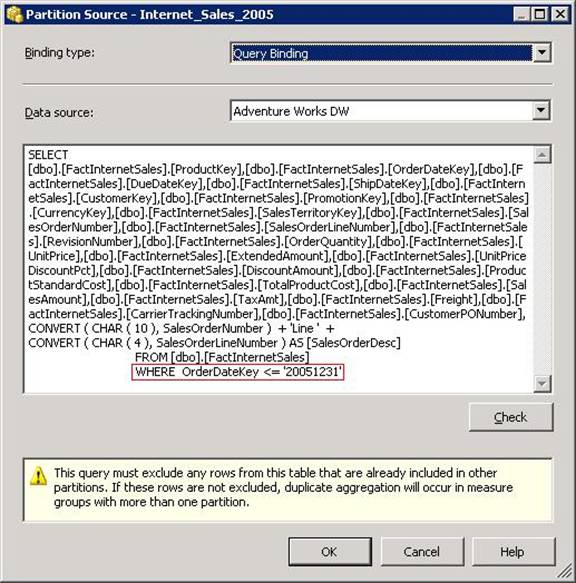
After making the required changes, click OK to dismiss the Partition Source dialog box and return to the partitions tab. Rename the default partition to Internet Sales Facts 2005, under the partition name column. Your screen will look similar to the one below.
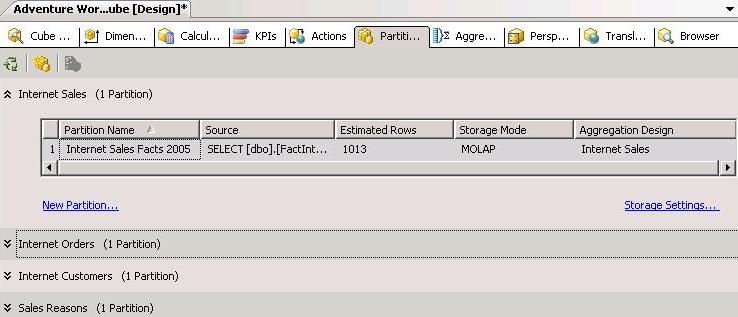
Now, to add a new partition, click the New Partition hyperlink to launch the Partition Wizard. On the welcome page, click next. The Specify Source Information dialog box appears as shown in the figure below.
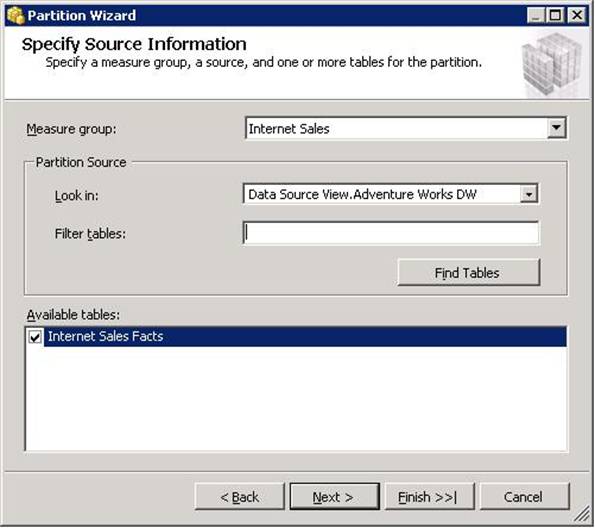
Under Measure group, select the appropriate measure group (Internet Sales in our case) using the drop-down list.
Under Partition Source, select Adventure Works DW data source view (by default the data source view used by the measure group is selected but you can also select a data source that contains the table(s) for this partition).
Select Internet Sales Facts under Available tables and click next. If you don’t see any tables, click the Find Tables button to see a list of tables in the measure group you have selected.
The Restrict Rows dialog box appears next as shown in the figure below. Select the Specify a query to restrict rows checkbox to populate the dialog with a select statement that includes all the columns in the selected fact table.
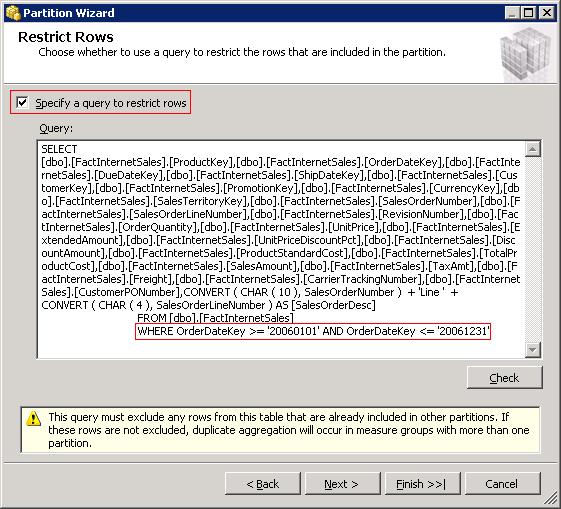
Since this partition will contain data for the year 2006, the where clause will need to be WHERE OrderDateKey >= '20060101' AND OrderDateKey <= '20061231'. Click next.
The Processing and Storage Locations dialog box will appear as shown in the figure below.
Under Processing location, select Current Server instance if you want the current instance of analysis services to process the partition. However, if you want a remote analysis services instance to process the partition, select Remote Analysis Services data source and specify the data source representing the remote instance.
The Storage location specifies the location where Analysis Services will store data for the partition. You can either choose to use the default location or specify a different location. After selecting the appropriate options, click next.
Completing the Wizard dialog box will appear next as shown in the figure below. Type an appropriate name for the partition in the name box.
You have three options regarding aggregation:
- Design aggregations for the partition now: Select this option if you intend to create aggregations for the partition immediately. Selecting this option will launch the aggregation wizard which will walk you through the process of creating aggregations for the partition.
- Design Aggregations later: Select this option if you intend to design aggregations for the partition later.
- Copy the aggregation design from an existing partition: This is a very good option that will let you copy aggregation design from an existing partition. If you plan to merge this partition later with other partitions, you can copy the aggregation design of those partitions with which you plan to merge the current partition.
Finally you can check the Deploy and process now check box to deploy and process the partition immediately or leave it unchecked to process later.
Note: You can also create partitions using SQL Server Management Studio (SSMS). The method is pretty much the same as it uses the same wizard.
Conclusion
In this article, we discussed what partitions are, how to split data in partitions and how to create partitions using the Partition Wizard. We also discussed some of the advantages of creating partitions and how they can be used to enhance performance and ease administration (including some real time scenarios).

