
From Rows to Pages: The Hidden Chaos Behind SQL Server’s Sampling Methods
Learn about the TABLESAMPLE option in T-SQL and uncover some of the pitfalls of assuming this works as you think it does.
2025-08-22
2,141 reads
Learn about the TABLESAMPLE option in T-SQL and uncover some of the pitfalls of assuming this works as you think it does.
2025-08-22
2,141 reads

While Recurrent Neural Networks (RNN) are powerful, they often struggle with long-term dependencies due to the vanishing gradient problem. Long Short-Term Memory Networks (LSTMs) address this issue by introducing memory cells and gates. For beginners, understanding LSTM components, such as the input, output, and forget gates, can be challenging. This tip breaks down LSTMs in an intuitive way, highlighting their importance and practical applications.
2025-08-22
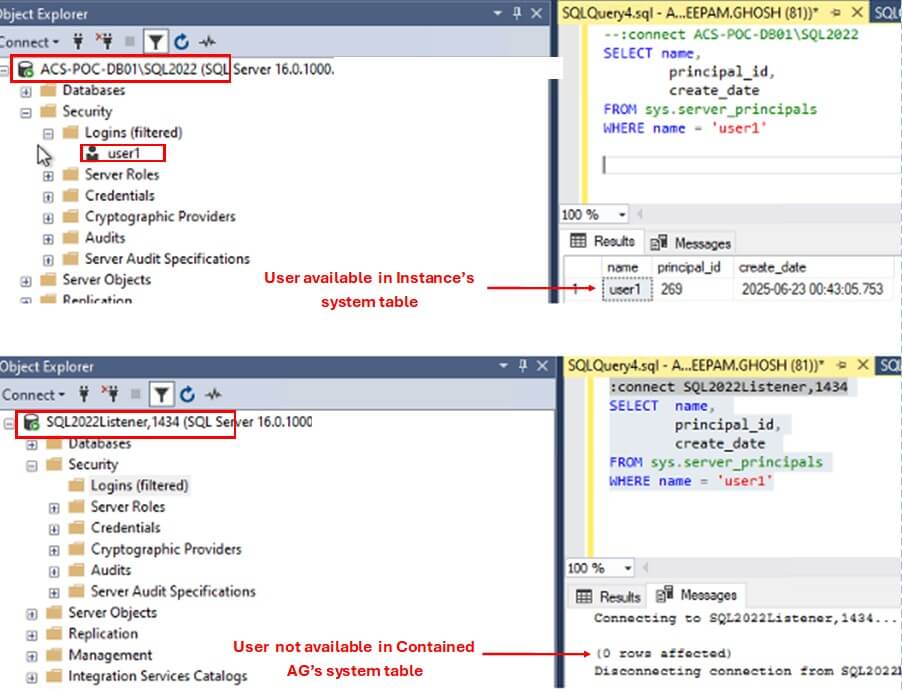
SQL Server 2022 introduced a new feature called Contained Availability Groups. It allows the Database Administrators to effectively manage the Server Level objects, such as Logins, SQL Agent jobs, etc. in an HA environment. In today's article, we will learn about this new feature of SQL Server. The Challenge of Managing Server Objects in Availability […]
2025-08-20
9,310 reads

When I first started with Power Query, it was in Excel, through the Power Pivot feature. I was amazed at how I could transform data with just a few clicks and quickly create PivotTables. Then, when Power Query appeared in Power BI, I began working with larger data sources and more complex projects.
2025-08-20
Learn how to create a dynamic database dashboard that tracks key metrics using SQL Server Reporting Services. From setting up to deploying your report.
2025-08-18 (first published: 2023-07-17)
3,662 reads
SQL Server users have been asking for native regular expression support for over two decades. There are third-party Common Language Runtime (CLR) modules that offer this functionality, but these can be complicated to install and simply aren’t possible in some environments. I want to split a string using a regular expression instead of a static string. Will that be possible in SQL Server 2025, without CLR?
2025-08-18
Meta Description: App-level vulnerabilities can co...
2025-08-15 (first published: 2025-06-12)
85 reads
This is the first in a series of articles meant to provide practical solutions to common issues. In this post, we’ll talk about one of the most pervasive error messages out there:
2025-08-15

A customer has a database that is already set up in a SQL Server Availability Group. Since this database hosts sensitive data, there is a need to encrypt the primary and all secondary replicas of the data. In this article, we will walk through how this can be done.
2025-08-13
Summary: SQL Server administrators frequently enco...
2025-07-30
954 reads
By Vinay Thakur
Continuing from Day 3 where we covered LLM models open/closed and their parameters, Today...
By Steve Jones
One of the nice things about Flyway Desktop is that it helps you manage...
By HeyMo0sh
Microsoft Fabric (not to be confused with the more general term “fabric” in DevOps)...
I'm fairly certain I know the answer to this from digging into it yesterday,...
Hi Team, I am trying to refresh the Azure Synapse Dedicated pool from production...
hi everyone I am not sure how to write the query that will produce...
I have some data in a table:
CREATE TABLE #test_data
(
id INT PRIMARY KEY,
name VARCHAR(100),
birth_date DATE
);
-- Step 2: Insert rows
INSERT INTO #test_data
VALUES
(1, 'Olivia', '2025-01-05'),
(2, 'Emma', '2025-03-02'),
(3, 'Liam', '2025-11-15'),
(4, 'Noah', '2025-12-22');
If I run this query, how many rows are returned?
SELECT *
FROM OPENJSON(
(
SELECT t.* FROM #test_data AS t FOR JSON PATH
)
) t; See possible answers