

Optimizing Your Cube’s Schema
If you have ever built an Analysis Services cube from a fact table with millions of rows and lots of dimensions, you know it can be a time consuming task to process your cube. If you have experienced this problem, you should try optimizing your schema. The mechanics are quite simple. Follow this example using the FoodMart 2000 database that ships with SQL Server 2000.
Open the Analysis Manager, connect to your Analysis Server and expand the FoodMart 2000 database. Expand the cubes folder and then right click on the Sales cube to open the cube editor. You should see the following screen. Click on the Tools menu option and you will see the option to Optimize Schema
Click the Optimize Schema option in the menu and you should get a message like the following (assuming you have not already optimized the Sales cube schema in a previous session).
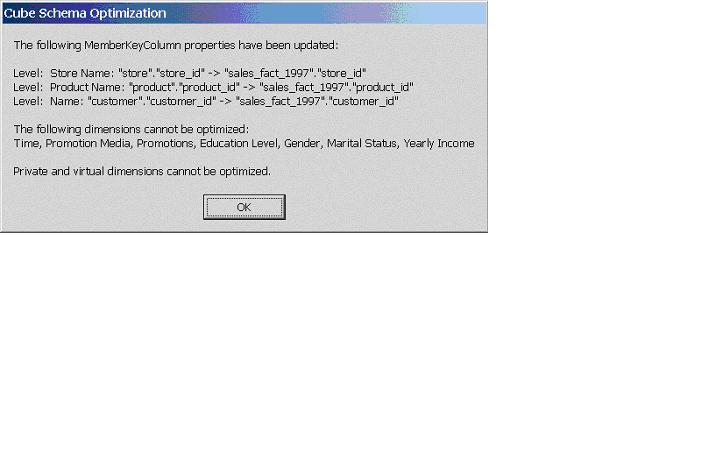
This message indicates that the MemberKeyColumn properties have been updated for three of the cube’s dimensions, 1) Level: Store Name from the Store dimension, 2) Level: Product Name from the Product dimension and 3) Level: Name from the Customers dimension. The message also tells us that the other dimensions in the cube cannot be optimized. We only have one option…..Click OK. It is too late to turn back now. Congratulations. Your schema is now optimized…..sounds too easy to be true? What just happened anyway?
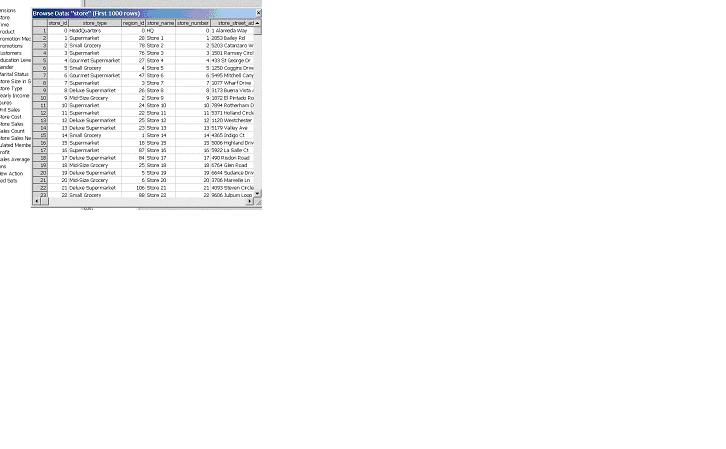
Let’s examine these dimensions in more detail. First, let’s take a look at the Store dimension. You can look at the relational schema in the Cube Editor and see that Store Name is included in the relational dimension table called "Store". You can also see in the graphical display that the Store dimension table is joined to the Sales_Fact_1997 fact table on the column name store_id. If you right click on the Store table and do a quick browse of the data, you can see that store_id is populated with sequential numeric keys, exactly as we would expect from a well designed relational star schema.
Now, let’s take a look at how the Store dimension is built in Analysis Services. Close the Cube Editor and open the Shared Dimensions folder. Right click on the Store dimension and select Edit to open the Dimension Editor. Note that Store Name is the bottom level of the Store dimension.
Now click on Store Name and look at the properties pane to see how the Store dimension is structured. You should see something like the figure below.
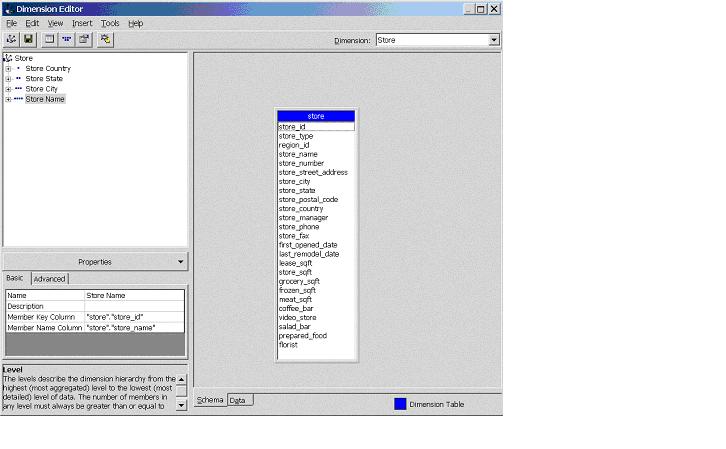
The two properties we want to focus on are the Member Key Column and the Member Name Column. Notice that the Member Key column uses store_id from the store table. The Member Key Column uses store_name from the store table. This brings us to one of the key understandings in how Analysis Services creates dimension levels.
>>The Member Key Column is the column that Analysis Services uses in the SQL code that creates the dimension structure. In this case, there will be a unique dimension member created for each unique instance of store_id. The Member Name Column is the label that Analysis Services will use to display each of the unique values of store_id.
To verify this, process the dimension and then double click on the first yellow SQL box in the process log. You should see the following.
..
Dimension 'Store' Execute : SELECT DISTINCT "store"."store_country", "store"."store_state", "store"."store_city", "store"."store_id", "store"."store_name" FROM "store"
Notice that two columns are extracted for the store name level of the dimension. The first column is the Member Key Column (store_id) and the second column is the Member Name Column (store_name). If you browse dimension data, you will now see that there is a unique member name at the bottom of the dimension for each distinct instance of store_id and the value in the store_name column is displayed for each member.
So what does this mean??
Analysis Services cubes consist of two main components. The first component is the dimensions that make up the cube (sometimes referred to in OLAP terms as metadata). The dimensions in the cube should be processed first to update the cube dimensional structures with new dimension members, changes to hierarchies, etc.
The second major component is the data itself. Data is loaded to the cubes by processing the cubes. If you look carefully at the SQL code in the process window, you will see that the largest (and most time consuming) process is to load the data records from the underlying relational fact table, and that dimensions are processed first before the fact table is loaded.
The underlying relational star schema uses table joins to relate each fact row in the fact table to the appropriate row in each dimension table. In Analysis Services, however, each row in the fact table must be related to a bottom level member of each dimension using the Member Key Column for each dimension. This illustrates a very key point in processing a cube.
>>The Member Name Column has nothing to do with loading the fact table!
With this in mind, there is no reason to execute the join between the fact table and the store dimension table as fact rows are processed into the cube. Why? Because the Member Key Column for the Store dimension already exists in the fact table! The join between the fact table and the store table is not necessary to load the data into the cube!
Now, if we return to the Optimize Schema message, it begins to make a bit more sense. The unnecessary joins between the fact table and the three dimensions listed in the message have been removed by the Optimize Schema step. If we repeat the process of browsing each of these dimensions (Store, Product and Customers), you will see that a common pattern develops. Each of the three dimensions uses an id column as the Member Key Column. The bottom level of the Customers dimension is customer_id and the bottom level of the Product dimension is product_id. No joins needed, therefore faster processing time. This can be a significant time savings on a fact table with millions of rows.
But….what about those other dimensions? Why didn’t they get optimized, too?
Let’s take a look at the Promotions dimension. Right click the Promotions dimension and select Edit to open the Dimension Editor. Note that the Promotion dimension has only one level. Click on the Promotion Name level and look at the Properties pane. You should see the following.
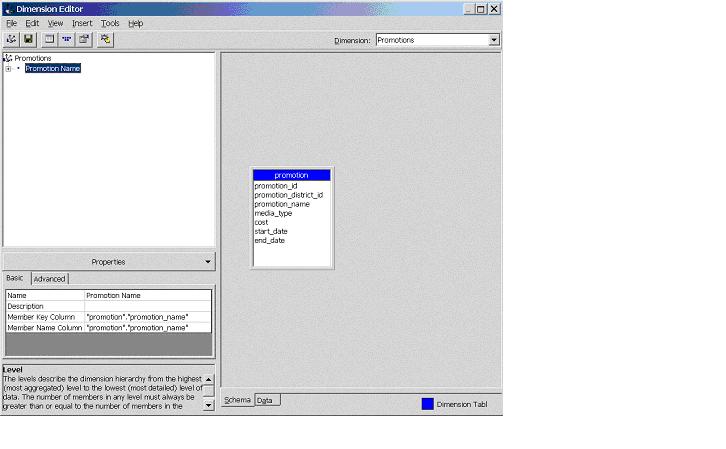
Notice the values for the Member Key Column and Member Name Column. Do you see anything different than we saw for Store, Product and Customers? The Member Name Column is using promotion_name, not promotion_id. This means that when the cube is processed, every fact row added to the cube must execute the join on promotion_id in order to associate that fact with the proper member of the promotion dimension. For this simple reason, the Promotions dimension could not be optimized when the Optimize Schema step was performed in the cube editor. This brings up the most important design tip of all.
>> Always use id’s at the bottom level of each dimension as the Member Key Column wherever possible! This will allow you to get full benefit of the Optimize Schema option in the Cube Editor.
If you already have dimensions out there that do not use id’s as their Member Key Column, do not despair. Try changing the Member Key column in the dimension structure to use id’s at the bottom of each dimension instead of names. You can always use the name as the Member Name Column to display the user friendly names in the dimension display….after all, that is what the property is for.
Remember….you must Optimize Schema in the Cube Editor using the menu option. Also, if you add new dimensions to your cube, you will need to repeat the Optimize Schema option again.
Don Church, President
Quest Industries, Inc.
