

I found an article that caught my eye recently. Someone had tried to simulate a large federated load of data by creating a million tables in a MySQL system. This was to show that MySQL 8.0 had vastly improved over MySQL 5.7. Why those versions, I'm not sure, but I thought that this was an interesting test.The article found that randomly inserting data into these tables in 5.7 lowered the transaction rate dramatically. MySQL 8.0 has some issues as well, but fewer, mostly because of file opens. A table is a file in MySQL.
While I'm not worried about benchmarking different versions of SQL Server at scale, I thought it might be fun to try creating a million tables. This isn't a serious comparison, but rather just an experiment to see what happens in a SQL Server lab.
Mapping the Process
MySQL works a bit differently than SQL Server. A database in MySQL is really a schema, and thus corresponds to a schema object in SQL Server. This means that 10,00 databases with 100 tables per in MySQL is really 10,000 schemas with 100 tables. The maximum capacity specifications for SQL Server note that I can have 2 billion (2,147,483,647) tables per database, though no mention on schemas, so let's ignore that for now. We'll create one million tables in a database.
I do want a small benchmark, so I'll do this with a thousand tables, and then with a million.
First, the databases. We don't want defaults here. Let's go with something a little larger
CREATE DATABASE OneThousand
ON PRIMARY
(
NAME = N'OneThousand' ,
FILENAME = N'e:\SQLServer\MSSQL12.SQL2014\MSSQL\DATA\OneThousand.mdf' ,
SIZE = 10240000KB ,
FILEGROWTH = 1024KB
)
LOG ON
(
NAME = N'OneOneThousand_log' ,
FILENAME = N'e:\SQLServer\MSSQL12.SQL2014\MSSQL\DATA\OneThousand_log.ldf' ,
SIZE = 102400KB ,
FILEGROWTH = 10%
);
GO
CREATE DATABASE OneMillion
ON PRIMARY
(
NAME = N'OneMillion' ,
FILENAME = N'e:\SQLServer\MSSQL12.SQL2014\MSSQL\DATA\OneMillion.mdf' ,
SIZE = 10240000KB ,
FILEGROWTH = 1024KB
)
LOG ON
(
NAME = N'CREATE DATABASE OneMillion_log' ,
FILENAME = N'e:\SQLServer\MSSQL12.SQL2014\MSSQL\DATA\OneMillion_log.ldf' ,
SIZE = 102400KB ,
FILEGROWTH = 10%
);
GO
Now we have a database, let's create the tables. I'll keep this simple, and create a set of tables with a name pattern. Since we're not looking to work on performance, let's just create a table with a single column, but obviously separate names. I'll use my standby, MyTable, as the basis for the names. With a tally table, this becomes a simple exercise. I'll use a loop, since I need to execute some dynamic SQL to create the tables. I'll let my loop run until the tables are created.
USE OneThousand GO DECLARE @n INT = 1; DECLARE @cmd VARCHAR(1000); WHILE @n < 1001 BEGIN SET @cmd = &39;create table MyTable&39; + CAST(@n AS VARCHAR(10)) + &39; ( myid int, mychar varchar(2000))&39; EXEC(@cmd) SELECT @n = @n + 1 END GO USE OneMillion GO DECLARE @n INT = 1; DECLARE @cmd VARCHAR(1000); WHILE @n < 1000001 BEGIN SET @cmd = &39;create table MyTable&39; + CAST(@n AS VARCHAR(10)) + &39; ( myid int, mychar varchar(2000))&39; EXEC(@cmd) SELECT @n = @n + 1 END GO
I ran this in two batches on my desktop, with these specs:
- Intel i7-6700k @ 4GHz
- 32GB RAM
- Samsung 850 EVO for data storage
There were definitely other programs running on my system (VMWare, Slack, Outlook, etc.), so this isn't exactly a performance test. To run this script required a couple seconds for the first thousand tables. Once it was done, SSMS looked interesting.
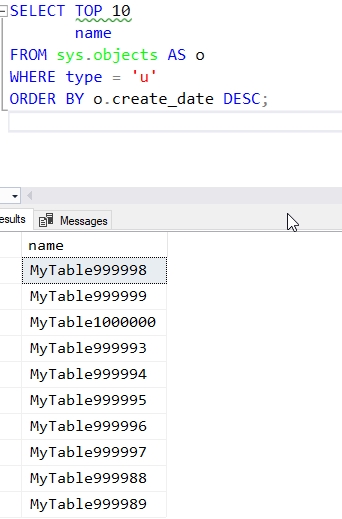
The batch for a million tables took longer. In fact, it took 14:27 about to run. Once it completed, I couldn't get SSMS to load the tables, which makes sense. The controls aren't typically designed for millions of objects, and realistically, it's not a good use of CPU and memory for a visualization. I could run this query, which did look good:
Inserting Data
I've got a PowerShell script that randomly inserts data into a table. This picks one of the tables and drops an integer in the table. The code is shown here.
$loops = 10000
$i = 1
$server = "Plato\SQL2017"
$db = "OneThousand"
$start = Get-Date
while ($i -lt $loops) {
$number = Get-Random -Maximum 1000 -Minimum 1
$query = "insert mytable" + $number + " select " + $number + ", replicate(CHAR(65), 1000)"
Invoke-Sqlcmd -ServerInstance $server -Database $db -Query $query
write-host($number)
$i = $i + 1
}
$end = Get-Date
$Interval = New-TimeSpan -End $end -Start $start
write-host($start)
Write-Host($end)
write-host($Interval)
I used the same code for the OneMillion database, but the max random number is 1,000,000, not 1,000. I ran the script, both for the one thousand and then one million table databases. Here are the results:
| Database | Time to insert with print |
| OneThousand | 00:00:10 |
| OneMillion | 00:00:26 |
I ran this a few times and each time, the time varied by about a second or two at the most. I don't know if I put this down to the additional CPU required for printing the number, and perhaps some calculation. I'm not sure, but I did run this again, removing the print statements in the loop. In that case, I got these results:
| Database | Time to insert with print |
| OneThousand | 00:00:05 |
| OneMillion | 00:00:25 |
This is interesting to me, as there appears to be some slightly different amount of time being taken to do the inserts. Certainly there are variations, but in the four runs of the smaller database, all runs completed within a second of each other, from 5.002s to 5.34s. The OneMillion database varied from 23.4s to 29.79s. It would be interesting to have somone run a larger scale test, but certainly there appears to be some sort of overhead here.
Note: If I'm testing poorly with PoSh, let me know. I'd be curious why there would be a difference if PoSh is slowed with Get-Random somehow.
Conclusion
I'm not quite sure what to think of this. Most of us likely work with databases that have hundreds, maybe thousands, of tables, and we often insert (or update/delete) from a relatively small number of them. That's the nature of what we tend to do with most databases, especially those OLTP ones that may have many concurrent users.
In this case, there appears to be some overhead with either PoSh or SQL Server with this many tables. If I insert just a row or two, I find the time appears to be the same. My guess is that PoSh ends up being a reason for the slowdown here, which is quite slower.
SQL Server does appear to handle 1,000,000 tables fine in a database. As long as I don't try to use Object Explorer, SSMS works fine and my instance appears to function the same as it does for smaller databases.
This isn't really a performance test, or any statement on the scalability of SQL Server databases with lots of objects. For the most part, I didn't notice much different in the two databases. I thought it was a fun experiment, and it was. If someone wants to take this further and conduct more experiments, I'd be curous what your conclusions are.
