

In SQL Server, the classic stored procedures that we know and love are interpretive. This means that when a stored procedure is executed for the first time, the SQL Server relational engine first compiles it, and then executes it. By contrast, when we create a natively compiled stored procedure, SQL Server compiles it into machine code immediately, and stores it in a DLL.
Since the stored procedure is now expressed in machine code, the CPU can run it directly, without any interpretation. The lack of interpretation means that the resulting code will be much simpler and more efficient than our standard stored procedures.
Natively compiled stored procedures can reference only in-memory tables. This, for most people, will be the biggest "barrier to entry". The time and effort needed to convert old tables into In-Memory OLTP tables can be significant. For example, foreign keys are not allowed in In-Memory tables, which may be problematic for a highly relational environment. In addition, there are many other restrictions on the T-SQL that is allowed inside a natively compiled stored procedure, compared to classic stored procedures.
As such, it's typically a good idea to save in-memory OLTP, as well as in-memory stored procedures for applications where speed and efficiency are of the utmost importance. However, for those tables and procedures that you can move to in-memory, you will often see a huge improvement in performance over standard disk-based stored procedures.
Creating and Using Natively Compiled Stored Procedures
For this example, we are going to perform a series of tests, comparing performance before and after, using the Person.EmailAddress table in the AdventureWorks2012 database:
- Old school – normal tables and stored procedures
- Old meets new – old school table meet natively-compiled stored procedure
- All new –memory-optimized table and natively-compiled stored procedure
Old School – interpreted T-SQL
First, let's create a simple stored procedure
CREATE PROCEDURE get_email_address_data
(
@BusinessEntityID INT = NULL
)
AS
BEGIN
IF @BusinessEntityID IS NULL
BEGIN
SELECT BusinessEntityID ,
EmailAddressID ,
EmailAddress
FROM Person.EmailAddress
END
ELSE
BEGIN
SELECT BusinessEntityID ,
EmailAddressID ,
EmailAddress
FROM person.EmailAddress
WHERE BusinessEntityID = @BusinessEntityID
END
END
GONow that we've defined this stored procedure, we'll turn on IO & time statistics and our actual execution plan to see how it performs for a non-null input
DBCC FREEPROCCACHE SET STATISTICS IO ON SET STATISTICS TIME ON EXEC get_email_address_data @BusinessEntityID = 12894
The execution plan look like this:
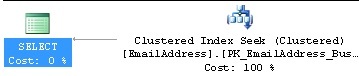
The execution statistics were as follows:
Table 'EmailAddress'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 15 ms, elapsed time = 58 ms.
Some additional info that is handy to note (pulled from our execution plan details):
- Cached plan size: 16kb
- Compile CPU: 33
- Compile Memory: 112
- Compile Time: 33
Old meets new: interpreted SQL and memory-optimized table
With our baseline out of the way, let's convert Person.EmailAddress into an in-memory OLTP table and reassess its performance:
-- Save the email address data so we can put it back later
SELECT *
INTO dbo.EmailAddress_DATA
FROM Person.EmailAddress
-- Drop our old email address table
DROP TABLE person.EmailAddress
-- Create a filegroup and file for our memory-optimized table:
ALTER DATABASE AdventureWorks2012
ADD FILEGROUP ADVENTUREWORKSINMEMORYOLTP CONTAINS MEMORY_OPTIMIZED_DATA
GO
ALTER DATABASE AdventureWorks2012 ADD FILE (name='PersonEmailAddress_1', filename='c:\Data\PersonEmailAddress_1')TO FILEGROUP AdventureWorksInMemoryOLTP
GO
-- Create a new email address table using in-memory OLTP
CREATE TABLE Person.EmailAddress
(
BusinessEntityID INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 30000),
EmailAddressID INT IDENTITY(1,1) NOT NULL,
EmailAddress NVARCHAR(50) COLLATE Latin1_General_BIN2 NOT NULL INDEX ix_EmailAddress NONCLUSTERED HASH(EmailAddress)WITH (BUCKET_COUNT = 30000),
rowguid UNIQUEIDENTIFIER NOT NULL CONSTRAINT DF_EmailAddress_rowguid DEFAULT (NEWID()),
ModifiedDate DATETIME NOT NULL CONSTRAINT DF_EmailAddress_ModifiedDate DEFAULT (GETDATE()),
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
-- Add statistics to the BusinessEntityID column and update them immediately
CREATE STATISTICS stats_EmailAddress_BusinessEntityID
ON Person.EmailAddress (BusinessEntityID) WITH FULLSCAN, NORECOMPUTE
UPDATE STATISTICS Person.EmailAddress WITH FULLSCAN, NORECOMPUTE
-- Populate our email address table with its original contents
INSERT INTO person.EmailAddress
( BusinessEntityID ,
EmailAddress ,
rowguid ,
ModifiedDate
)
SELECT BusinessEntityID ,
EmailAddress ,
rowguid ,
ModifiedDate
FROM EmailAddress_DATA
ORDER BY EmailAddressID
GO Now that we have replaced our table with an in-memory table, we can execute our existing get_email_address_data stored procedure and compare the performance.
DBCC FREEPROCCACHE SET STATISTICS IO ON SET STATISTICS TIME ON EXEC get_email_address_data @BusinessEntityID = 12894
The results were as follows:
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 1 ms.
Cached plan size: 16kb
Compile CPU: 33
Compile Memory: 112
Compile Time: 0
Our performance improved drastically over the original table. There are no IO statistics as there was never a need to read the disk for data. As a result, the runtime for the stored procedure decreased dramatically!
All new: natively complied stored procedure and memory-optimized table
The next step is to convert our stored procedure to be natively compiled.
-- Create a stored procedure that collects data from Person.EmailAddress
-- EdPollack is the login I am using to execute our TSQL
CREATE PROCEDURE get_email_address_data (@BusinessEntityID INT = NULL)
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS 'EdPollack'
AS
BEGIN ATOMIC
WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
IF @BusinessEntityID IS NULL
BEGIN
SELECT
BusinessEntityID,
EmailAddressID,
EmailAddress
FROM Person.EmailAddress
END
ELSE
BEGIN
SELECT
BusinessEntityID,
EmailAddressID,
EmailAddress
FROM person.EmailAddress
WHERE BusinessEntityID = @BusinessEntityID
END
END
GOThe following summarizes the some of the new requirements and syntactical changes when creating natively compiled stored procedures:
-
NATIVE_COMPILATION– tells SQL Server that this stored proc will be natively compiled. -
SCHEMABINDING– mandatory for native compilation to ensure that we cannot alter any of the objects referenced by the pre-compiled stored procedure without first dropping the stored procedure. -
EXECUTE AS– we must specify the execution context, as natively compiled stored procs do not supportEXECUTE AS CALLER(the default context). In this case I am using a local user with the appropriate permissions, but you can also useEXECUTE AS OWNERorEXECUTE AS SELF, if required. -
BEGIN ATOMIC– A natively compiled stored procedure must consist of a single atomic block of TSQL. This ensures that the entire stored procedure will execute within its own discrete transaction. -
TRANSACTION ISOLATION LEVEL = SNAPSHOT– in-memory OLTP engine only supports certain isolation levels.SERIALIZABLEandSNAPSHOTare the two most likely candidates, thoughSNAPSHOTis recommended as it uses fewer resources on average. -
LANGUAGE– we must specify the language as part of the stored proc creation, which in this case will be US English.
We're now ready to run our test with entirely in-memory objects. It is important to note that the Actual Execution Plan option in Management Studio will not return an execution plan. In order to get your actual execution plan, you need to use SET SHOWPLAN_XML ON. You can still view estimated execution plans, though, if desired.
DBCC FREEPROCCACHE SET STATISTICS IO ON SET STATISTICS TIME ON GO SET SHOWPLAN_XML ON GO EXEC get_email_address_data @BusinessEntityID = 12894 GO SET SHOWPLAN_XML OFF GO
As before, STATISTICS IO returns no data as there was no need to access disk for any of our data. STATISTICS TIME returns some glowing results:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
Since our stored procedure is natively compiled, there is no compile time as this work has already been done for us.

Our execution plan is a bit different from what we would normally expect to see – in fact, it looks more complex than before! Despite the added steps and the inclusion of the conditional in the execution plan, further checking confirms that the resources consumed are negligible for both the seek and the scan:
- Estimated CPU Cost: 0
- Estimated I/O Cost: 0
- Estimated Number of Executions: 1
Of course, my computer didn't execute this for free; some resources were expended! It turns out that for operations where the CPU cost is low enough (the order of microseconds), the execution plan will not give us the fine level of detail that we are looking for here. Microsoft provides some additional resources to accomplish this here:
http://msdn.microsoft.com/en-us/library/dn452282.aspx
In order to better measure those resources over time, we should turn on the in-memory stats collection. Executing the following statement enables the collection of in-memory OLTP execution stats, which can be found in sys.dm_exec_procedure_stats:
EXEC sys.sp_xtp_control_proc_exec_stats @new_collection_value = 1
With this collection is enabled, we can take a closer look at this collected data (after running our stored proc a bunch of times first, to establish some test data):
SELECT object_id,
object_name(object_id) AS 'object name',
cached_time,
last_execution_time,
execution_count,
total_worker_time,
last_worker_time,
min_worker_time,
max_worker_time,
total_elapsed_time,
last_elapsed_time,
min_elapsed_time,
max_elapsed_time
FROM sys.dm_exec_procedure_statsThe results of this query show 3 executions: two are from system procs, and the third is our natively compiled stored procedure:

This shows aggregate statistics for our proc since it was cached. While it is clear that resources were in fact consumed by our proc, but those resources are tiny. The unit of measurement for time in this DMV is microseconds. The time it took to execute our query most recently was 25 microseconds, which represents almost a 1000x improvement!
Microsoft even warns us that natively compiled stored procedures with an execution time under 1 millisecond may result in timing data that is not 100% accurate. In other words, it's so blazingly fast and the units of time are so small, that some margin of error is almost unavoidable. Needless to say, when we are talking about stored proc executions of a fraction of a millisecond or less, it quickly becomes clear how powerful in-memory OLTP can be!
The Long List of Gotchas
Creating natively compiled stored procedures requires some careful planning as many features of traditional stored procedures are not valid. Following is a list of the most significant restrictions with regards to natively compiled stored procs.
Microsoft provides a complete list of all In-Memory OLTP here:
http://msdn.microsoft.com/en-us/library/dn246937(v=sql.120).aspx
Since these stored procedures are natively compiled, SQL Server will warn you immediately upon creation if you are using syntax that is not allowed. This will at least allow for immediate feedback so that you can build your stored procedure correctly up-front.
As a lifeline, Microsoft provides a Native Compilation Advisor in SQL Server Management Studio 2014, which will assist in converting an old stored procedure. This feature is accessible in the Object Explorer for an existing stored procedure and will walk you through disallowed features so that you can more easily implement your changes and convert the proc into one that is natively compiled:
EXISTS is not supported
In order to work around this, you'll need to execute TSQL for the existence check and assign a bit to a scalar variable to confirm the result:
DECLARE @exists BIT = 0
SELECT TOP 1
@exists = 1
FROM Person.EmailAddress
WHERE BusinessEntityID = 12894
IF @exists = 1
BEGIN
SELECT 'TSQL goes here'
ENDMERGE is not supported
In order to handle a MERGE, you'll need to perform each part of your statement separately, rather than all-in-one.
CASE statements are not supported
There are workarounds available that utilize stored procs or some sort of looping logic. I'd recommend avoiding these if possible, to keep your TSQL simple and legible.
OUTER JOIN is not supported, which includes LEFT JOINs
Microsoft's workaround for this involves using a WHILE loop to move through data row-by-row. This may still be more efficient given the immense benefits of in-memory OLTP, but performance testing would be required to confirm this in any given case.
OR, and NOT are not supported
The simplest workarounds would use table variables to manipulate rows of data into the form desired. This can be messy, but can be done relatively efficiently.
TempDB cannot be used.
All access in a natively compiled stored procedure must be in-memory. You may use table variables or any other in-memory variables to achieve the same effect of a temp table. Incidentally, this TempDB restriction is the primary reason why so many other pieces of functionality are not allowed in natively-compiled stored procs. Hash joins, for example, will result in TempDB usage, as can other operators in execution plans, which would be problematic when a stored procedure needs to be natively compiled and not use TempDB. If you create your in-memory OLTP table with DURABILITY = SCHEMA_ONLY, you can also skirt this rule, but at the cost of potentially losing data in a disaster.
ALTER PROCEDURE is not allowed
Natively compiled stored procs must be dropped and then created again. If time is of the essence, you can create the new stored procedure first (with a new name), modify application code to point to the new version, and then drop the old proc at your leisure. This allows a seamless transition with no outage period where the proc would not be available.
CURSORs are not supported
It's likely that very few people reading this will have a problem with that.
CTEs are not allowed
You'll have to convert them into simpler structures in order to be usable here.
Other restrictions
There are many more restrictions, including no supports for OUTPUT, INTO, INTERSECT, EXCEPT, APPLY, PIVOT, UNPIVOT, IN, LIKE, UNION, DISTINCT, PERCENT, WITH TIES, UDFs, WITH RECOMPILE, and views. You'll have to rewrite any SQL that uses these to achieve similar results without them.
Viewing the DLLs
You can view the DLLs that are used by SQL Server using the DMV dm_os_loaded_modules. The following query will return a list of all DLLs currently in use on this instance:
SELECT LOADED_MODULES.name ,
LOADED_MODULES.description
FROM sys.dm_os_loaded_modules LOADED_MODULES
WHERE LOADED_MODULES.description = 'XTP Native DLL'In addition, that query can be modified slightly to return the DLL info for a single in-memory object:
SELECT LOADED_MODULES.name ,
LOADED_MODULES.description
FROM sys.dm_os_loaded_modules LOADED_MODULES
WHERE LOADED_MODULES.name LIKE '%xtp_t_' + CAST(DB_ID() AS VARCHAR(10))
+ '_' + CAST(OBJECT_ID('Person.EmailAddress') AS VARCHAR(10)) + '.dll'Conclusion
In-memory OLTP tables used in conjunction with natively compiled stored procedures can improve query performance by many orders of magnitude. The long list of restrictions on their creation and usage may result in messy or seemingly suboptimal TSQL, but there is still a very good chance that the resulting performance will still be a huge improvement.
Microsoft provides fairly extensive documentation on in-memory OLTP, which is worth spending some time with as there is not enough room in a single article to cover even a fraction of its functionality. The key to successfully implanting In-Memory OLTP and natively compiled stored procedures is to start simple and test often. Management Studio will provide consistent feedback as to what isn't working and why, so as long as you incrementally make changes and add functionality, it'll remain easy to isolate problems and ultimately fix them.
The key to understanding in-memory OLTP is to put aside many of the preconceptions that we have from our previous work in SQL Server. Many of our assumptions about how good SQL should look, and the efforts we have spent to reduce the impact of common problems such as locking and latching are no longer relevant here. With no need to access disk, and with our stored procedures being boiled down to natively compiled atomic transactions, SQL can perform much faster than we are used to. This will be true even if in the process of upgrading a stored proc we are forced to make our SQL longer and more complex in order to get it to work within all of the restrictions outlined above.
I definitely recommend that you take these new features for a spin and judge for yourself how they perform. I've been consistently awed by the level of performance I've seen in every example I've created thus far, regardless of complexity. The prerequisites and effort needed to convert existing schema into in-memory OLTP capable schema may be significant, but if successful, the resulting performance will justify all of that time and effort.
Lastly, here is the MSDN article with a complete introduction to using in-memory OLTP. Included are links that take you all over MSDN to explore performance, restrictions, syntax, examples, and other useful information. This is an excellent place to go if you are unsure of where to begin:
