

A couple weeks back I wrote Managing
Jobs - Part 1 as a both a brief introduction to some of the features of jobs
plus a reminder that as your business grows and changes, so must the way you
manage your jobs. This week I'd like to continue that by talking about some
other ideas that you might consider to help you manage them more effectively.
Let's start by revisiting a subject I covered in Worst
Practice - Not Having An Archive Plan For Each Table. I've found that unless
I design a plan to purge data at some point, it will grow unchecked forever,
which is usually about 3 years too long. Trying to solve that problem for
myself, I started by creating a category called "Cleanup", then
creating one job per database labeled 'DBName - Daily Cleanup'. Then I create
one or more steps that usually just have simple things like "delete from
orderdetails where orderdate < getdate() -365". If they are all plain
deletes, I just put them in one step. If I've got portions that have
dependencies (like orders vs orderdetails) I might put that in a separate step
to make it easier to see. I like to run these jobs daily so that the amount of
data being moved or removed is manageable - why delete 300,000 rows at the end
of the month when you can delete 10,000 per day? One job isn't always going to
be enough, you may well need a monthly or end of year type job. In any case,
using 'Cleanup' they're easy to spot when I need to see what is being deleted
when or need to add a new step to the job.
A big big item you need to think about is who gets notified when. Take a look
at your options:
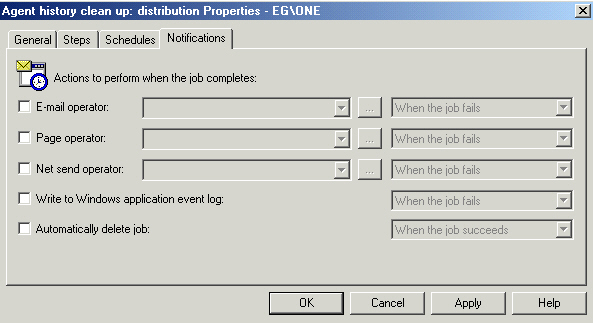
I've gone back and forth on email notification, but the plan I'm using now is
to send the email to the person who is responsible for fixing the problem.
Sometimes it may be that they'll just ask me to run the job again, other times
the data is bad and must be fixed first. The alternative is you could have all
notifications come to you. I've tried this and it's not bad, but sometimes I'm
busy and no one can start working until I tell them it failed. Don't be afraid
to add operators and send them the notifications, it's easy enough to change if
they move on.
Paging can be useful, but should be used lightly. On my Nextel phone there
doesn't seem to be a way to say 'delete all queued messages', I have to read
every one! Reserve pages for really urgent problems. Same goes for net send - I
typically only enable this when I'm troubleshooting a problem and might not
realize I've gotten email if I'm working on something else. Net send is a lot
faster than a page usually.
Writing to the event log? I run 400 or more backups a day, when you look in
the log you scroll...and scroll. Leave the event log for real problems, rely on
the agent and the job history for managing your jobs. It's easier, you always
have access to it, your admin will thank you.
The automatic delete option is not used often, but it's a great tool when you
need it. I use maintenance plans for index rebuilds, sometimes I'll want to do a
quick run on a single db over lunch if it seems unusually slow. I set up a new
plan rather than altering my existing one, then modify the job to delete itself
when done - so I don't forget and let it run at lunch for a week or two.
Managing jobs is tough. If you get email every time a job runs, you'll soon
get used to them and stop paying attention - until they stop showing up...maybe.
Failure notification is better to me, but you are at the mercy of SQL Agent. Not
uncommon for a job to hang, so it hasn't run, but hasn't failed either! For time
sensitive jobs I typically run a second job that checks the history of the first
job looking to see if it completed in time. This works fine until the agent
itself fails. Then what?
Let me digress here a moment to say that not all jobs run in SQL. You may
have jobs that run the tape backup via the NT scheduler or some other scheduler.
Ideally you want to monitor ALL those jobs. Something to think about.
I like Greg Larsen's idea of a failed job report. That works well with the
idea of sending the failure notice to the person responsible for fixing it, yet
you can still monitor to make sure problems are resolved. Beyond that, I've been
thinking that what I really want (and have not yet built) is a process separate
from SQL that checks on all my jobs across servers. In particular I'd like to be
notified if a job varies in run time from the last x times it ran. If a job
usually takes 5 minutes and all of a sudden takes 20 minutes, I need to know and
figure out why. I think I could also use this to catch jobs that hang up and
never finish.
In a week or two I'll wrap this up with a discussion about how to code
complicated jobs (exe, dll, vs., or TSQL) and where to run them. Until then, I
hope you've enjoyed reading this and will take a minute to comment on the
article - positive or negative!
