

Lookup Table Design Overview
When I begin to design a new database for a client, one of the dilemmas facing me is how to construct lookup tables.
When we say that a table is a lookup table for another main table, we mean that the lookup table contains values that will be used as the content of a column located in the main table. Usually the lookup table has at least two fields – CD (Code) and Description. The main table stores only the values from the CD field, but since there is a relationship between the lookup and the main table, the value of the associated Description field is also associated with the record in the main table. On the GUI’s level , lookup tables are often implemented as list boxes or combo boxes. For example: state code and state description.
There are 3 main design concepts for the lookup tables. Lets review each concept and discuss some real life scenarios.
Design 1 - Traditional
Each code has its own table with at least two fields – Code and Description (see diagram 1)
This design is simple, understandable for every developer and business person, and self explanatory. And this is why this type of the lookup table design is implemented in most databases. About 25 – 40 % of all lookup tables in a typical database are implemented using this design.

Design 2 – Combine Codes into a few tables
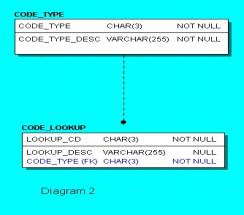
Usually one or two tables are created to combine all codes altogether. (See diagram 2)
Based on 2 tables the codes can be stored in database. A separation between various types of codes is done by a column “code_type”, so that all codes of the same type can be grouped together. For example:
Select lookup_cd, lookup_desc, code_type From code_lookup Where code_type = ‘ADR’
will return all address codes.
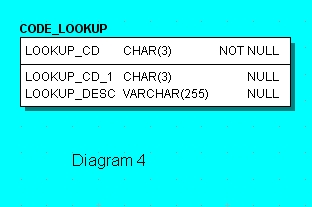
The design looks simple, but less self explanatory than the one table per code. It practically always requires the use of ‘where’ clause while join or viewing the specified type of code. The size of the code_lookup table can reach thousands of rows. Still, there are only 2 tables. This is simplistic approach for design 2. It is possible to make the design using one recursive table (see diagram 4). LOOKUP_CD_1 refer to LOOKUP_CD. And the top level of a code keeps LOOKUP_CD_1 with NULL value (or the same value as LOOKUP_CD). It is not a really practical solution because of the difficulties for the data selection with unlimited recursion depth. Even if the required depth of recursion is limited, design will be impractical. Further in this article I will show a more sophisticated and practical sample of this type of design.
Design 3 – Mixed Code Design
This one is a combination of the first and the second designs together. In a lot of cases, there are some industry standard lookup tables and some company specific ones. It may be more practical to separate some codes and combine the others.
For example: if you are using postal zip codes ( or phone area codes) and update them quarterly from USPS - ZIP Code® Directories , it is a good idea to separate them from the other codes. In some other cases, codes may be formatted differently.. For example: country (ISO 3166) or language (ISO 639) codes. A company may use the standard ISO char(2) and/or custom char(3) format. In those situations the mixed solution become more practical.
Real world example of design 2
Let me try outlining a practical implementation for design 2. To be able to satisfy a real business, different conditions should be met:
a)Ability to store various standard codes (For example: ISO, SIC, etc), as well as company or vendor specific codes
b)Ability to separate codes more granularly by type and sub-type
c)Be able to setup a sub-code of a code. For example: there are certain languages spoken in a country. Country and language codes should be entered and then linked to each other.
d)Ability to setup a corporation specific description and/or name versus the standard one.
Keep active and retired codes for audit purposes
Diagram 3 shows a sample design with all the business conditions from above. There are 4 tables which can keep all codes for the database.
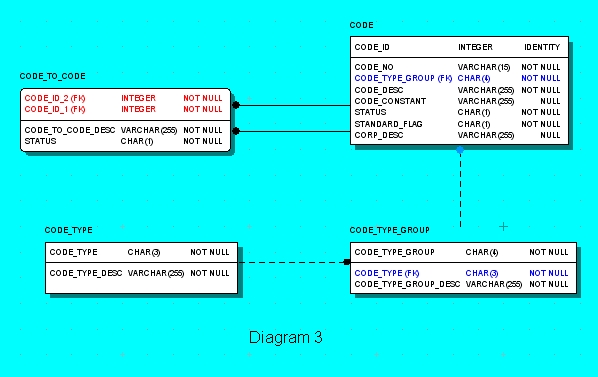
Table CODE_TYPE captures the various code types. A code type can refer to an object or a vendor or a transmission type or a
language or an error code etc… For example:
CODE_TYPE_CD | CODE_TYPE_DESC |
GEO | GEOGRAPHIC CODES |
ERR | ERROR CODES |
Table CODE_TYPE_GROUP captures the various groups within code types. A group within a error code type can refer to a various means of errors: application, FTP, email, SQL Server, custom errors.
CODE_TYPE_GROUP_CD | CODE_TYPE_CD | CODE_TYPE_GROUP_DESC |
EFTP | ERR | FTP errors |
EAPP | ERR | Application errors |
COUN | GEO | Country codes |
STAT | GEO | State codes |
Table CODE captures the various codes.
Columns:
CODE_ID - A unique identifier
CODE_NO – Keep specific numbers for the standard codes. For example: FTP has its own error numbers for any specific error.
CODE_TYPE_GROUP – define the group type for the code
CODE_DESC - Provides a description associated with code
CODE_CONSTANT: Used primarily for the standard codes to keep the code value. For example: 3 characters for ISO standard country code.
STATUS – shows the status of the code. For example: ‘A’ – active, ‘D’ – deleted (non active), ‘N’ – no standards
STANDARD_FLAG – shows which standards code belongs to. For example: ‘I’ - ISO, ‘S’ - SIC
CORP_DESC – special (non standard) corporate description, if necessary.
CODE_ID | CODE_NO | CODE_TYPE_GROUP_CD | CODE_DESC | CODE_CONSTANT | STATUS | STANDARD_FLAG | CORP_DESC |
1 | 23 | EFTP | FTP ERR 1 | ERROR_FTP_WRITEFILE | A | N | |
2 | COUN | USA | A | I | US | ||
3 | LANG | ENG | A | I |
And finally, CODE_TO_CODE table keep links between codes.
CODE_ID_1 | CODE_ID_2 | CODE_TO_CODE_DESC | STATUS |
2 | 3 | USA English | A |
2 | 4 | USA Spanish | A |
As you can see, those 4 tables allows handle any code types including government or industry standard codes. Sometimes additional columns may be required to satisfy additional criteria’s. I am using ‘codename’, ‘codetypegroupname’, ‘codetocodename’ and other columns if additional information is required to be stored.
In real world, there is almost impossible to use design 2 in it’s pure form. Usually, the architect chooses design 1 or (less often) design 3.
Lookup Tables Location
Many companies work with completely separated databases and do not want to mix the tables between databases or schemas.
But there are situations where it is reasonable to combine lookup tables (and not only lookup as well) into one administrative database. For example, companies specializing in clinical trial research or telemarketing are working with hundreds of databases for the various clients but using the same non client specific codes such as languages, states, countries, application specific errors, transmissions, etc. Those codes can be centralized in one database. It will provide a greater security, encapsulation, reusability, data integrity, and maintainability. It allows for keeping lesser number of tables in each production database and makes database structure simpler. Plus, and that very important, lookup data is always synchronized between databases and can be maintained by one person. However, it is almost impossible to implement such scenario with design 1 because of sheer number of tables and references to the administrative database. I implemented lookup table solution using design 3 for some of my clients with 100+ clinical trials. Non-client specific codes become centralized in one database, while client specific data is stored in each trial database. Each trial database is created with some predefined views (select permissions only) that allow usage of reference codes while residing in the trial database.
Create view VW_CODE as
Select C.CODE_ID, C.CODE_NO, C.CODE_TYPE_GROUP,
C.CODE_CONSTANT, C.STATUS,
C.STANDARD_FLAG, C.CORP_DESC,
CTG.CODE_TYPE_GROUP, CT.CODE_TYPE
From DBNM.DBO.CODE C
INNER JOIN DBNM.DBO.CODE_TYPE_GROUP CTG
ON CTG.CODE_TYPE_GROUP = C.CODE_TYPE_GROUP
INNER JOIN DBNM.DBO.CODE_TYPE CT
ON CT.CODE_TYPE = CTG.CODE_TYPE
Create view VW_CODE_TO_CODE as
Select CTC.CODE_TO_CODE_DESC, CTC.CODE_ID_1
, C.CODE_NO AS CODE_NO_1, C.CODE_DESC AS CODE_DESC_1
, C.CODE_CONSTANT AS CODE_CONSTANT_1
, C.CODE_TYPE_GROUP AS CODE_TYPE_GROUP_1
, CTC.CODE_ID_2 , C1.CODE_NO AS CODE_NO_2 , C1.CODE_DESC AS CODE_DESC_2
, C1.CODE_CONSTANT AS CODE_CONSTANT_2, C1.CODE_TYPE_GROUP AS CODE_TYPE_GROUP_2
FROM DBNM.DBO.CODE_TO_CODE CTC
INNER JOIN DBNM.DBO.CODE C
ON CTC.CODE_ID_1 = C.CODE_ID
INNER JOIN DBNM.DBO.CODE C1
ON CTC.CODE_ID_2 = C1.CODE_ID
The disadvantage for this implementation is that the referential integrity can’t be controlled by a foreign key constraint.
Referential integrity was implemented by using triggers.
Conclusion
This article shows only the logical way of thinking for the lookup table design. Lookup table design implementation may have some variations from the described above and should be implemented very carefully based on the specific business conditions.
