

When I first learned about triggers in the SQL language, I was excited by the prospect of being able to perform some task based on data changes. This seemed like a very powerful tool for the database developer. However, like many new developers to SQL, I soon realized that triggers were more complex than I expected, often not quite working as I expected.
Triggers aren't good or bad, but the do impose additional load on your system, and they can be problematic for developers to write properly. They aren't difficult to code, but they can be a bit complex to completely understand. This article isn't designed to delve into the implications and complexity of triggers, but rather show you a few ideas on how you can practice writing triggers, as well as build a sandbox in which you can experiment when you need to write one.
What is a DML Trigger?
When I started working with SQL Server, triggers were triggers. Over time, the platform has evolved, and we now have three types of triggers: DML,DDL, and Logon triggers. This article covers DML triggers, which are pieces of code that react to Data Manipulation Language events. These are the INSERT, UPDATE, and DELETE statements used to manipulate data. There are a number of different triggers that can be set, and this article will begin the discussion of basic triggers. More in depth looks at advanced triggers will be covered in another article.
DDL triggers are triggers that fire when Data Definition Language statements are fired. Those are statements like CREATE, ALTER, DROP, etc. This article will not cover these types of triggers, but defer those to a later piece.
Logon triggers are pieces of code that fire whenever a login actually connects to an instance and creates a LOGON event. These are useful for tracking sessions or restricting access. This article will not cover login triggers.
Trigger Code
A trigger is defined in Books Online as a special stored procedure that is fired when DML events are fired that affect a table or view. I think that's a good description because a trigger is a set of code that runs in a similar fashion to a stored procedure. The code is structured inside of a block, similar to a stored procedure, though this code is bound to a table or view. Whenever an event takes place on the table or view that is defined in the trigger, the trigger code is fired inside of the same transaction (explicit or implicit) that contains the DML.
There are actually a couple types of DML triggers. This article looks at AFTER triggers, which are the most common type of trigger. There are also INSTEAD OF triggers, but we will not cover those in this basic introduction.
A trigger often allows more complex enforcement of business logic than can be achieved with a CHECK CONSTRAINT. This is because that each trigger can have multiple statements, access resources, and even change data.
As a quick example, let's create a short trigger that notes what data is inserted into a table. I'll use the Customer table in my database. Here is the code that creates the trigger:
CREATE TRIGGER Customer_Insert ON dbo.Customer FOR INSERT AS SELECT * FROM Inserted
This code will bind itself to the dbo.Customer table with the ON clause in the header. The FOR clause let's me know this works for INSERT statements only. The code inside is a simple SELECT. When I insert a value into dbo.Customer, the trigger fires. Here is the result:
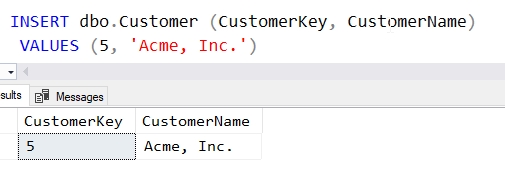
Note that a result tab appears. If I look at the messages tab, I see two messages. One is from the INSERT and the other comes from the SELECT.
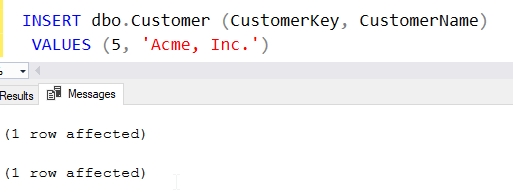
This isn't a very good trigger, but it gives us a short example of how they work. Let's alter this trigger in a way that might be more helpful. I'll add another column to my table and then use a trigger to update this column. First, we'll add a common field, ModifiedDate, to the table.
ALTER TABLE dbo.Customer ADD ModifiedDate DATETIME2 DEFAULT SYSDATETIME();
Next we'll alter our trigger to update this data when a row is changed. We do this by issuing an update statement against our table, joining the inserted table to the main table. This let's us only update the rows that were inserted or updated. I'll first drop the old trigger and then create a new one that includes a few better coding practices. Our trigger code will look like:
CREATE TRIGGER dbo.Customer_SetModifiedDate
ON dbo.Customer
FOR INSERT, UPDATE
AS
BEGIN
UPDATE dbo.Customer
SET ModifiedDate = SYSDATETIME()
FROM Inserted i
INNER JOIN dbo.Customer c
ON c.CustomerKey = i.CustomerKey;
END;
GO
Let's see if this works. Let's change the name of one customer first and determine if the update worked. I'll use this code:
SELECT CustomerKey,
CustomerName,
ModifiedDate
FROM dbo.Customer
WHERE CustomerKey = 15
GO
UPDATE dbo.Customer
SET CustomerName = 'Acme Inc.'
WHERE CustomerKey = 15
GO
SELECT CustomerKey,
CustomerName,
ModifiedDate
FROM dbo.Customer
WHERE CustomerKey = 15
This returns the following results. Note that the ModifiedDate column is originally NULL, but it is later updated to a new value automatically.
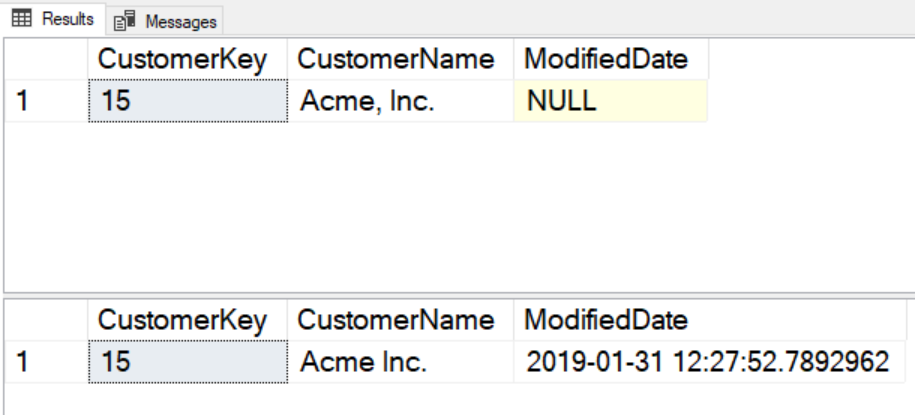
Next, let's try adding a new customer and updating the existing one. We'll use this code:
SELECT CustomerKey,
CustomerName,
ModifiedDate
FROM dbo.Customer
WHERE CustomerKey IN ( 15, 16)
GO
INSERT dbo.Customer ( CustomerKey, CustomerName, ModifiedDate)
VALUES
(16, 'Microsoft Corp.', SYSDATETIME())
UPDATE dbo.Customer
SET CustomerName = 'Apple Computer'
WHERE CustomerKey = 15
GO
SELECT CustomerKey,
CustomerName,
ModifiedDate
FROM dbo.Customer
WHERE CustomerKey IN ( 15, 16)
This returns one row before the DML statements. After the trigger fires, we see that both the update and the insert statement have the same value for the ModifiedDate.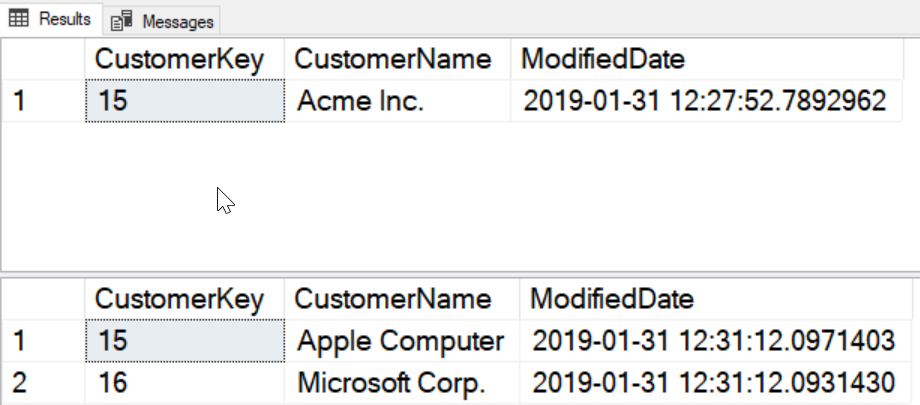
The trigger is providing us an automatic audit trail of the last time that data was changed.
This example shows how you can use triggers in implementing a rudimentary auditing system. This is not a recommendation to implement auditing in this manner, but rather a way that shows how a trigger can be used to update data in a table.
Finding Triggers
Triggers are often hidden sections of code that confuse many individuals. This is because we don't usually see them easily in SSMS or Azure Data Studio when examining the Object Explorer. We usually see the table or view, but not any clue that a table might have a trigger bound to it. Here is the view in Azure Data Studio of the Object Explorer.
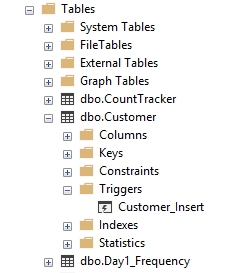
Below the table, however, we have a folder in our Object Explorer that is below a table where we can find any triggers associated with this object.
There is a similar folder under each View as well.
The trigger(s) that exist for this object will be listed below the Trigger folder. As we will see, there can be multiple triggers for an object, each of which is designed to enforce different logic. There can also be multiple actions that are handled by a single trigger. Above we see an example of each. First a trigger that only handles INSERT events, and second a trigger that handles both INSERT and UPDATE events.
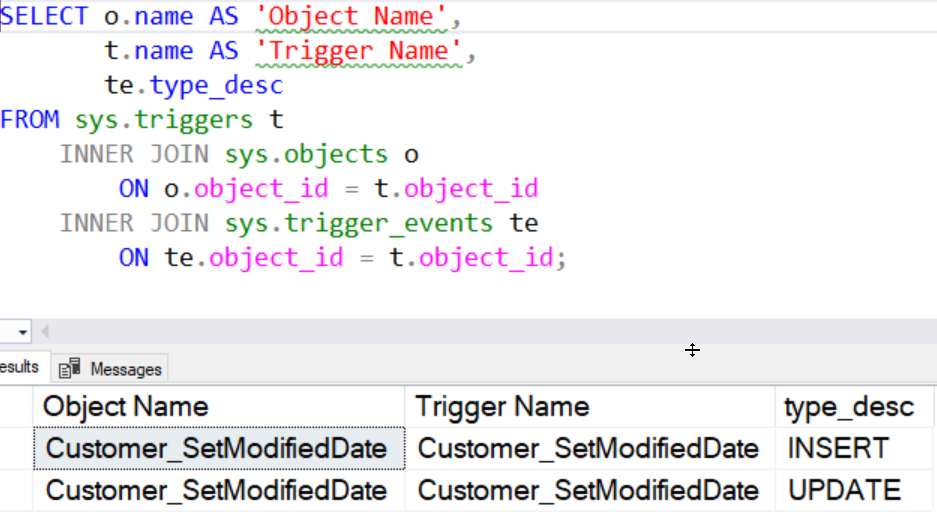
Trigger information is also stored in various DMVS. There are sys.triggers, sys.trigger_events, and sys.trigger_event_types. I have a short query below that will programmatically find triggers and their parent objects.
SELECT o.name AS 'Object Name',
t.name AS 'Trigger Name',
te.type_desc
FROM sys.triggers t
INNER JOIN sys.objects o
ON o.object_id = t.object_id
INNER JOIN sys.trigger_events te
ON te.object_id = t.object_id;
If we run this on my sample database, we will see these results:
DML Data
When an INSERT, UPDATE, or DELETE statement is executed, this often adds, changes, or removes data from a table. The affected data might be important to enforcing some business rule or data integrity. As a result, the database code needs to have access to the set of data that is being added, changed, or removed. SQL Server has implemented this access through a set of virtual tables that are available to trigger code while it is executing. These are discussed below.
Note that these exist for both tables and views. For the ease of explanation, I will just write "table", but unless otherwise specifed, these apply to views as well.
Inserted
When data is added or changed in a table, the new data (being inserted, or the changes in the table rows) is captured in a virtual table, called "inserted". This is a table that can be accessed by the trigger, but isn't available anywhere else. This table has the same schema as the underlying table. I used this table above to join to the original table on the CustomerKey column.
This table will have data for INSERT and UPDATE statements, if there are rows that are affected.
Deleted
The data that is removed from a table, or the data that existed prior to an update, is included in the deleted table. As with the inserted table, this is the same structure as the original table.
For UPDATE statements, this table contains the data before the change, which can be compared to the inserted table to determine what changed. For DELETE statements, this table has the rows that are being removed from the table in this transaction.
Multiple Triggers
A table can have multiple triggers bound to it, and each can react to the same events. For example, above I have a trigger that provides rudimentary auditing for INSERT and UPDATE statements. I can add another UPDATE trigger that performs other actions. Let's see an example.
Suppose I have a dbo.CustomerAddress table where I have information used to contact a customer. In this case, I look at the row with CustomerKey = 15. I see a problem.
After my earlier update, the name of the company is incorrect. I should have updated both tables, but it is easy to forget this. One solution here is to use a trigger to keep data in sync. Let's write a trigger to do this:
CREATE TRIGGER Customer_UpdateAddress ON dbo.Customer FOR UPDATE
AS
BEGIN
UPDATE dbo.CustomerAddress
SET CustomerName = i.CustomerName
FROM Inserted i
WHERE i.CustomerKey = dbo.CustomerAddress.CustomerKey
END
Now, if I issue another update against the dbo.Customer table, I should see the dbo.CustomerAddress table updated.
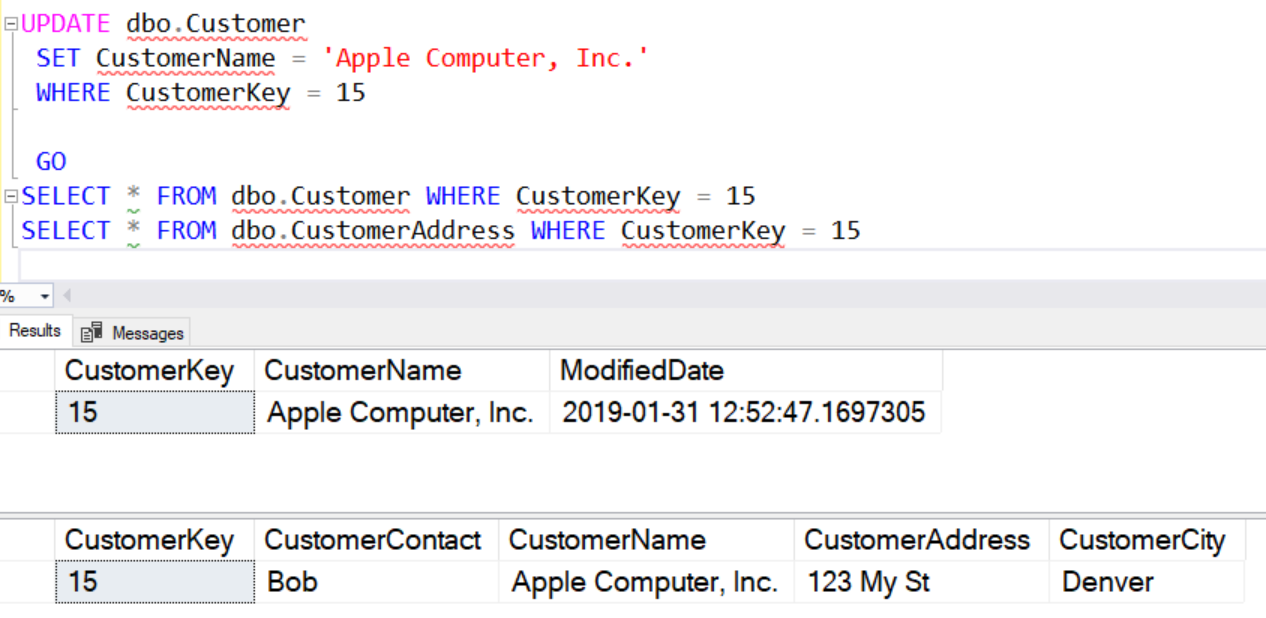
I do, and my data remains correct according to the logic I've implemented in the trigger.
Note: This trigger applies to the dbo.Customer table only. If I update the dbo.CustomerAddress table, the changes will not be reflected in the dbo.Customer table. I would have to write a different trigger to handle the reverse updates.
If there are multiple triggers, you can use the sp_settriggerorder command to reorder triggers to execute in a certain way, but be careful as this can change over time. Each trigger ought to execute independently and not depend on other triggers.
Moving Forward
This is a basic look at triggers and how they can be written to respond to DML events against a table. This article covered the basic INSERT and UDPATE events and multiple triggers. I have given a short look at structuring code with the inserted and deleted tables to capture all rows affected, but there is more to discuss in this area.
In the next article, I will examine how to better structure code to design efficient triggers. In a future article, we will look forward at how DELETE triggers can be implemented to preserve or capture data changes. Future articles will also cover setting the order of execution, look at INSTEAD OF triggers, as well as explaining logon and DDL triggers.
