

Series Overview
This series of articles looks at how the optimizer builds up an executable query plan using rules. To illustrate the process performed by the optimizer, we'll configure it to produce incrementally better plans by progressively applying its internal exploration rules.
Example
Here's a simple query (using the AdventureWorks sample database) that shows the total number of items in the warehouse for each of a small number of products:

Heaps of work is done by SQL Server to parse and bind the query before it hits the query optimizer, but when it does, it arrives as a tree of logical relational operators, like this:
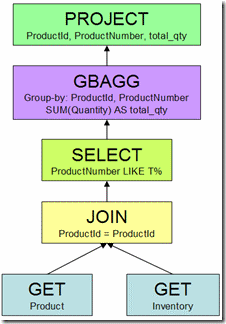
The optimizer needs to translate this into plan that can be executed by the Query Processor. If the query optimizer did nothing more than translate the logical relational operators to the first valid form it found, we would get a plan like this:
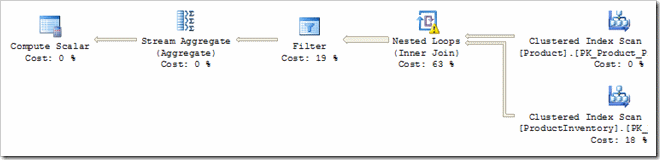
This executable plan features two full table scans, a Cartesian Product, a Filter on the two predicates, and an Aggregate. This is a long way from being an optimal query plan, but it does produce correct results. (In case you are wondering, the Compute Scalar is there to ensure that the SUM aggregate returns NULL instead of zero when no rows are processed).
Matching and Applying Rules
The optimizer found this plan by replacing logical operations with one of the physical alternatives it knows about. This type of transformation is performed by an implementation rule within the optimiser. For example, the logical operation "Inner Join" was physically implemented by Nested Loops (other implementation rules exist for Merge and Hash join).
To get from the logical tree to the executable plan shown, a total of five implementation rules were successfully matched and run by the optimiser:
- GET to Scan
- JOIN to Nested Loops
- SELECT to Filter
- Group By Aggregate to Stream Aggregate
- Group By Aggregate to Hash Aggregate
The first rule replaces the logical GETs with table scans. The second rule implements the logical JOIN using Nested Loops as mentioned before. The third converts all the predicates (including the join predicate) into a Filter operator. The fourth and fifth rules represent two alternative strategies to physically perform the group by aggregation. In this case, the optimizer chose a Stream Aggregate over a Hash Aggregate, based on costing.
Ok, but no-one would buy SQL Server if it produced that sort of plan on a regular basis. Luckily, there are many other rules that the optimiser can use; in fact there are nearly four hundred in total. Rest assured that the query optimiser fought hard to resist producing such a dismal plan: more than one dozen separate rules had to be turned off for it to do so.
As well as more implementation rules, there are a number of exploration and substitution rules. These transform some part of the logical request into an equivalent form, based on mathematical equivalences or heuristics. A simple example of an exploration rule is 'Join Commute'. This rule exploits the fact that A JOIN B is the same as B JOIN A (for inner joins).
The optimizer also has simplification rules and enforcer rules. Application of all these rules generates alternative strategies, the best of which will be incorporated in the final plan. As an aside, a single simplification rule was responsible for the transformation shown in my Segment Top blog entry. That amazing transformation goes by the understated name "Generate Group By Apply".
Improving the Plan
An obvious deficiency in the executable plan above is that it performs a Cartesian Product of the two source tables followed by a Filter. It would be much more efficient to evaluate the join predicate at the same time as performing the physical join.
The rule that performs this task is called SELonJN (SELECT on JOIN). I should stress that this is not the T-SQL SELECT statement, it is the relational SELECT operation: a filter applied to rows. By enabling the SELonJN optimisation rule, we get a better plan:
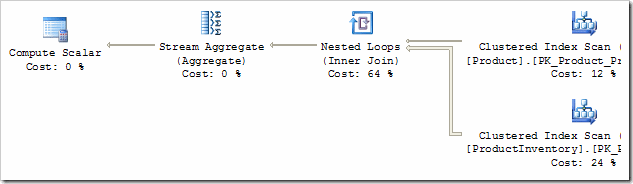
The Cartesian Product has been replaced by a more normal-looking Nested Loops operator, which is a result of the join predicate being moved from the Filter into the join. In fact, the Filter operator has disappeared completely - where has the predicate "ProductNumber LIKE 'T%'" gone? It has also been pushed down the plan - all the way to the Product table scan.
That's still not a great plan: we are scanning the whole Inventory table once for every row from the Product table that matches on the ProductNumber predicate. We need rules that know about non-clustered indexes - the basic rule we have relied on so far simply translates a GET to a table scan. Enabling a couple more rules produces:
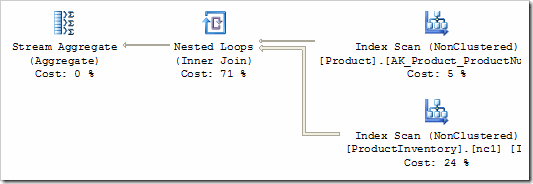
That's a little better, we are now using the correct non-clustered indexes but the predicates are being applied to a scan - not the index seek we might have hoped for. There are quite a few rules left to apply before we get a really efficient plan. I'll cover those next time.
Paul White
Twitter: @PaulWhiteNZ
Blog: SQLblog.com
