

Representational State Transfer (REST) is a software architectural design that has been employed throughout the software industry to create stateless web applications. An application that adheres to the REST may be informally described as RESTful. This term is more commonly associated with the design of HTTP-based APIs to interact with data that is stored on a vendors web site. Today, we are going to explore how Python can be used in a Fabric notebook to interact with a popular website called Spotify.
Business Problem
Our manager has asked us to create a prototype notebook that can be used to interact with a web site using the REST API endpoints. This code will demonstrate the following concepts: how to grab an access token; how to perform a single read from an endpoint; how to save simple JSON data to a file; how to perform paged reads from an endpoint; and how to convert multiple JSON files into a single delta table. To make this code somewhat reusable, we will want to write python functions.
Client Information
The image below was taken from the online developer documentation for the Spotify Website. Signing into the web service and retrieving an access token is the first step for any future REST API calls.
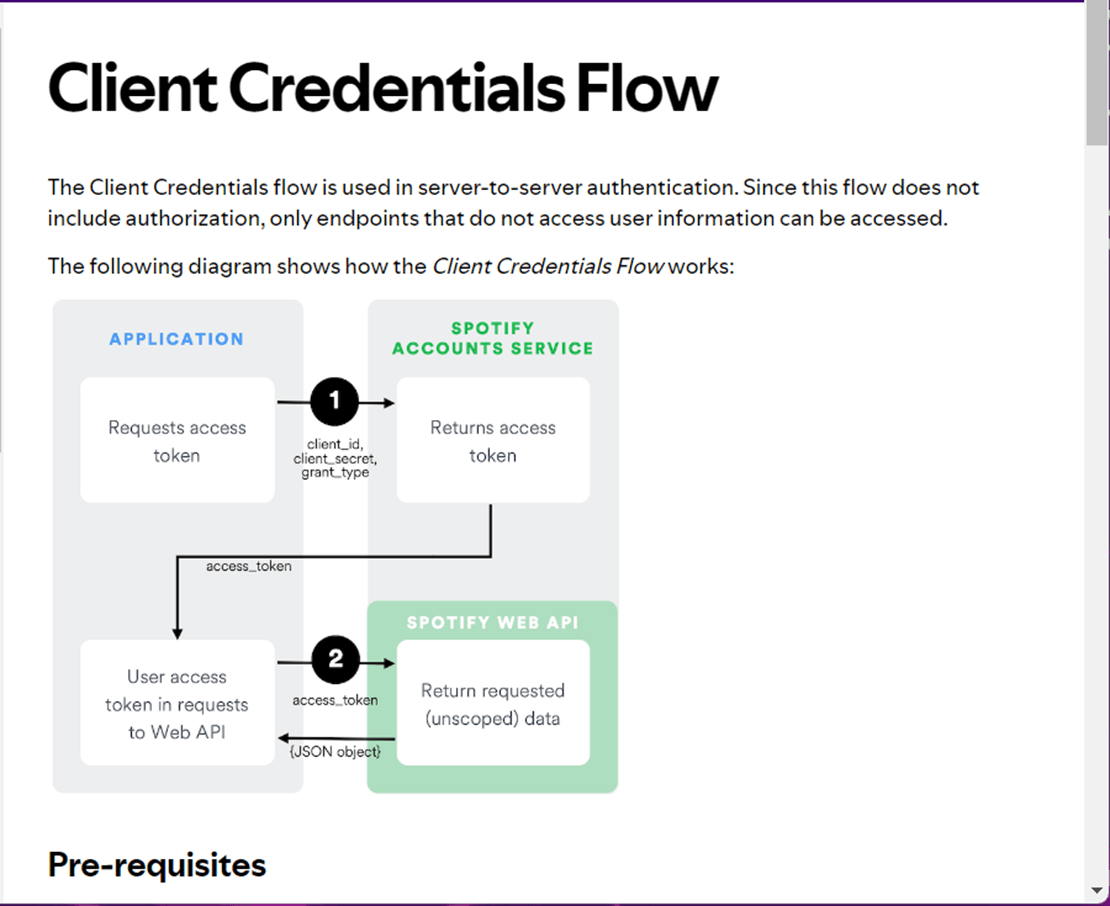
Each client id and client secret are associated with an application. In the image below see that I am logged into the website and created an application called “Spotify2Fabric”. Once the application is in place, we can retrieve the client information that we need.
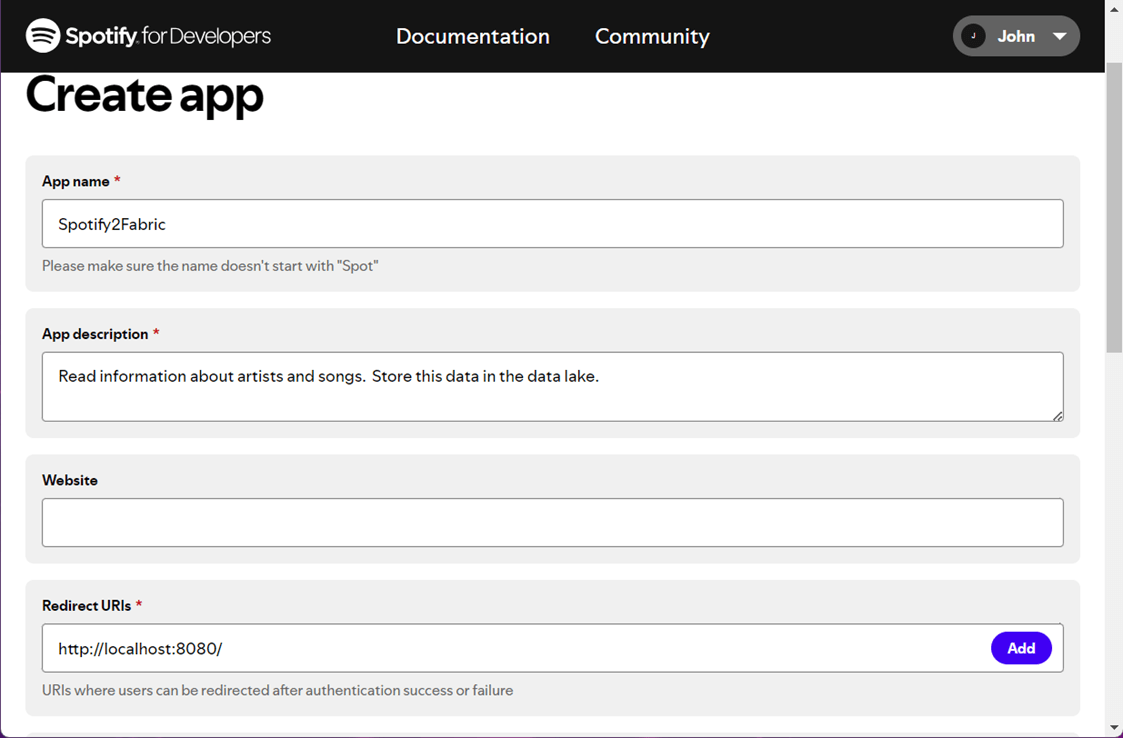
Find the basic information screen for our application called “Spotify2Fabric”. Capture both the client id and client secret.
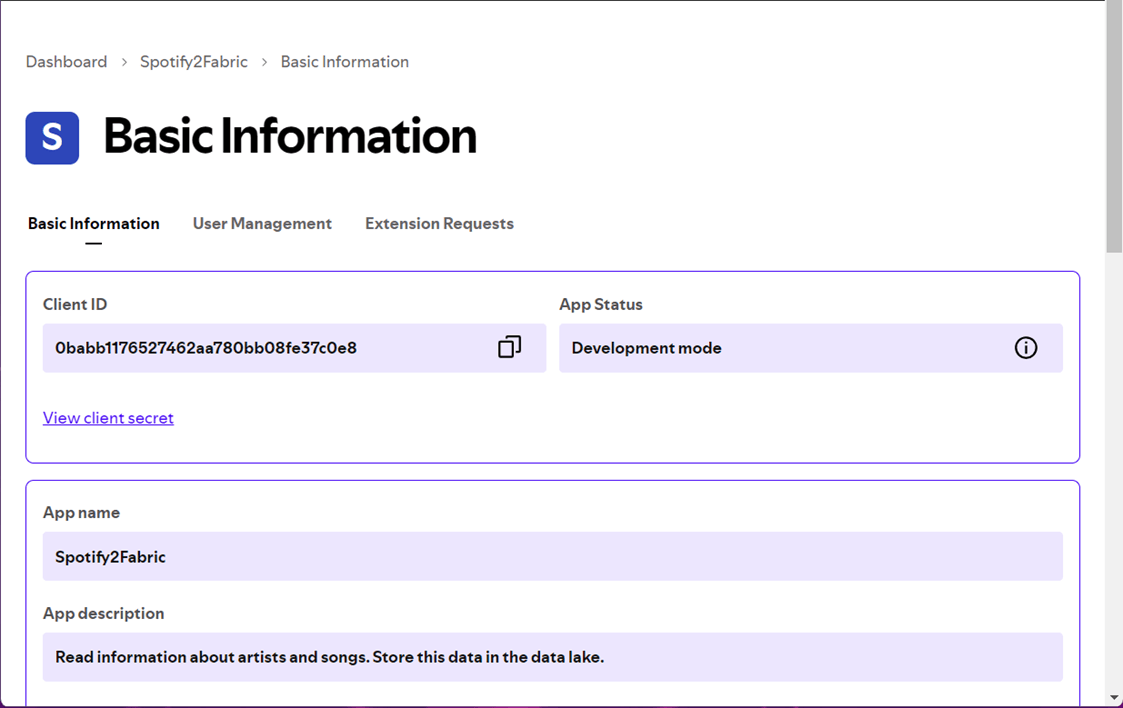
We never want to hard code secrets into our code. Therefore, the best place to store this data is in a Key Vault.
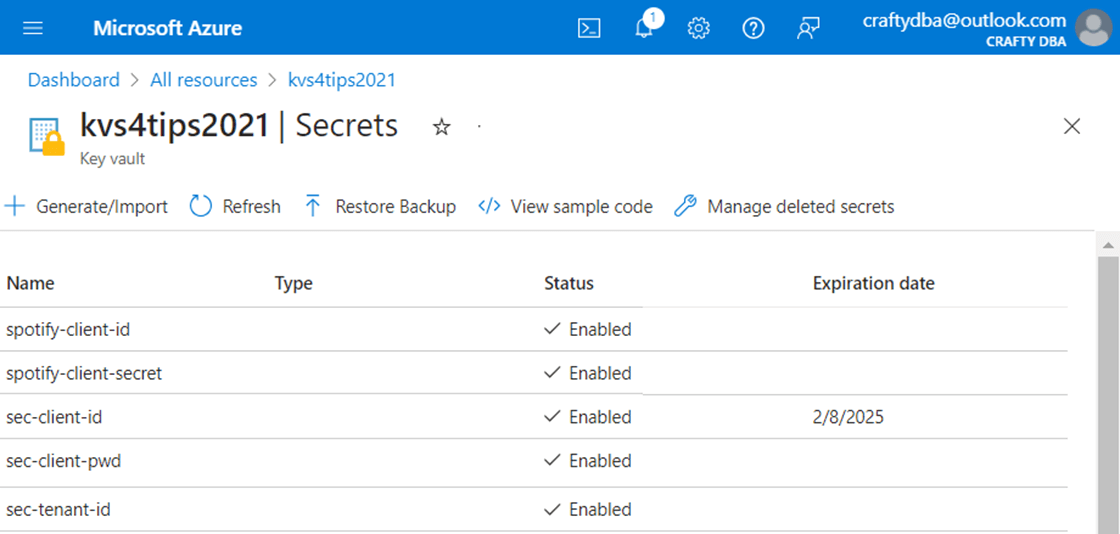
Our first function is called “grab_spotify_secrets”. This function is specific to our website. How can we make this function more dynamic? I will leave this as an exercise for you to complete. But here are two ideas. Pass the URL to the key vault as a parameter as well as a list (array of secrets). Use the for each loop to retrieve the secrets by order and return a dynamic list of real secrets.
#
# 1 - grab_spotify_secrets() - return client id + client secret
#
def grab_spotify_secrets():
# location of key vault
kvs = "https://kvs4tips2021.vault.azure.net/"
# spotify-client-id
usr = mssparkutils.credentials.getSecret(kvs, "spotify-client-id")
# spotify-client-secret
pwd = mssparkutils.credentials.getSecret(kvs, "spotify-client-secret")
# return str array
return [usr, pwd]
The developer might want to look at the value stored as a secret. However, it shows up as “[redacted]” when we attempt to print the variable. How can we see the masked data? Our second function shown below is named “grab_secret_text” and will allow us to look at this secret information in an unmasked form.
#
# 2 - grab_secret_text() - expose the key vault secrets
#
def grab_secret_text(secret_txt):
plain_txt = str('')
for c in secret_txt:
plain_txt = plain_txt + str(print(c, end = ' ')).strip("None")
return plain_txt
To wrap up this section, let’s assume we called the “grab_spotify_secrets” function and stored the results into a list named “client_info”. The first test below shows the unmasked data with spaces between each character. Now that we have the client information and can validate its contents, we should work on retrieving an access token in the next section.

Access Token
Most web services deal with an access (bearer) token that allows custom built software to interact with the REST API endpoints for a given period. Typically, the token is valid for 60 minutes.
Our third function named “grab_spotify_token” will take the client information as input and return a JSON document. There are two libraries that we need to import into the Spark Session: json – used to work with JSON documents and requests – used to make the REST API call using an HTTP action.
#
# 3 - grab_spotify_token() – grab an access token
#
import requests
import json
def grab_spotify_token(client_info, debug):
# api end point
url = 'https://accounts.spotify.com/api/token'
# define header
headers = {
"Content-Type": "application/x-www-form-urlencoded"
}
# define body
body = {
"grant_type": "client_credentials",
"redirect_uri": "http://localhost:8080",
"client_id": client_info[0],
"client_secret": client_info[1]
}
# send request
response = requests.post(url, headers=headers, data=body)
# bad response
if response.status_code != 200:
if debug:
print(f"FAILURE - the function grab_spotify_token() returned the following failure status: {response.status_code}")
raise Exception(f"Error retrieving access token; response status code: {response.status_code}; full response json: {response.text}")
else:
if debug:
print(f"SUCCESS - the function grab_spotify_token() returned the following success status: {response.status_code}")
token = json.loads(response.text)
return token
The most important part about writing code for HTTP requests is to include error handling. Additionally, we can use a debug variable to turn on and turn off messaging when executing the function. The image below shows the groups of error codes. We are expecting an okay code which is 200. Any other code results in an error being raised.
Did you know that Mozzilla was founded in 1998 by members of Netscape. Some notable products from free software community are Firefox web browser, Thunderbird e-mail client, and the Bugzilla bug tracking system, Here is the link to the error codes from the Mozilla website.

I am not using an object-oriented software design. Thus, some cells will be functions while other cells will be part of our main program. The first step in the main program calls the “grab_spotify_secrets” function to obtain the client id and client secret. The next step calls the “grab_spotify_token” function to get our access token from the Spotify Web Service.
# # Main - Step 1 # # grab secrets client_info = grab_spotify_secrets() # grab tokens token = grab_spotify_token(client_info, False)
The image below displays the contents of the token variable. It is a Python Dictionary since we use the json.dumps function to convert the return string to a dictionary. I am not worried about sharing this token since it has already expired.

In a nutshell, every REST API call has both a header and body. The access token is usually part of the header so that the web service knows you are a signed in application. In the next two sections, we will talk about downloading the list of genres for songs and search for artists from the 1980s.
Genre Entity
The Spotify website might have all the data stored in a SQL or NoSQL database. However, our only way to interact with the vendor is through REST API web calls. That is why I am naming this section of the article using the key word entity versus table.
Since most calls are very similar, we are going to write a generic function. Our fourth function is called “grab_spotify_single_data”. The purpose behind the word single is the fact that it is a one-time call. We will talk about paged retrieval of data from these services in the future. We use paging since there is a limit to the number of bytes returned in a response. Please see your vendor documentation for details.
#
# 4 - grab_spotify_single_data() - various end points
#
import requests
import json
def grab_spotify_single_data(url, token, debug):
# define header
headers = {
"Authorization": f"Bearer {token}"
}
# send request
response = requests.get(url, headers=headers)
# bad response
if response.status_code != 200:
if debug:
print(f"FAILURE - the function grab_spotify_single_data() return the following failure status: {response.status_code}")
raise Exception(f"Error retrieving access token; response status code: {response.status_code}; full response json: {response.text}")
else:
if debug:
print(f"SUCCESS - the function grab_spotify_single_data() return the following success status: {response.status_code}")
data = json.loads(response.text)
return data
The image below shows the details of the GET action for retrieving the different Genres of media in Spotify.
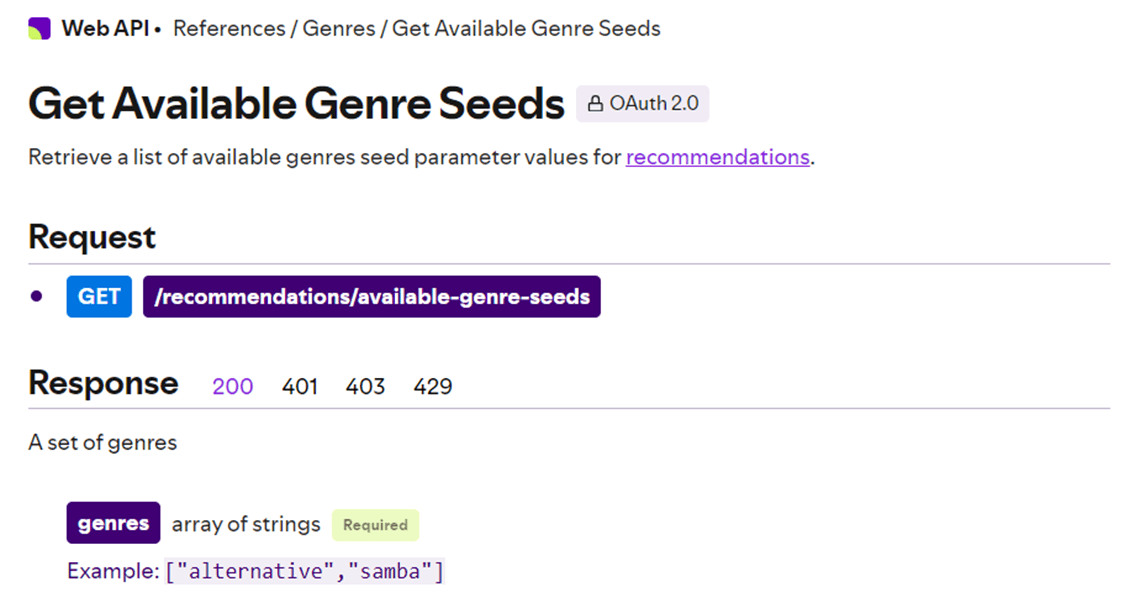
Here is a little spoiler alert. What are we going to do with the dictionary once it is returned from the function call? We should save the data on the local file system for a given timestamp. Since the data is a dictionary, I have decided to save the data as a JSON file. Next, we will want to read the data from the file directory and create a Delta table that end users can utilize.
#
# Main - Step 2
#
# read genres from api
key = token["access_token"]
url = "https://api.spotify.com/v1/recommendations/available-genre-seeds"
data = grab_spotify_single_data(url, key, True)
# write genres to json file
write_json_file(data, "spotify", "genre", True, True)
# read existing json + over write delta table
write_delta_table("spotify_genre", "Files/spotify/genre/", True)
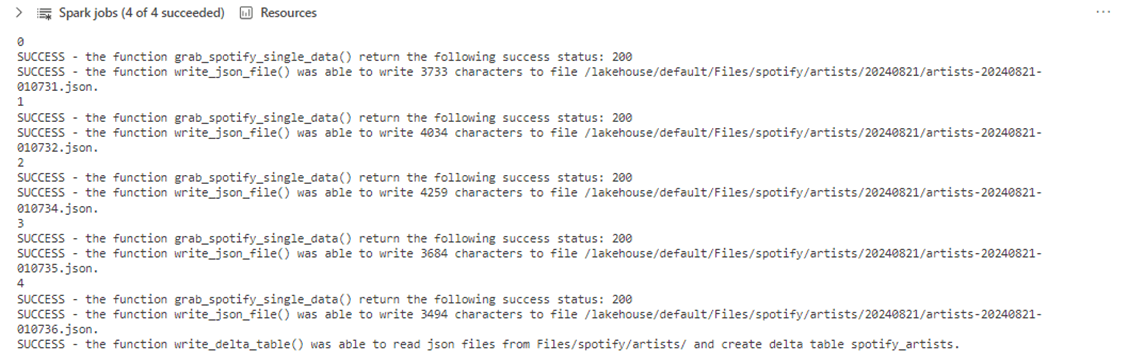
The above code is step 2 in the main program. The output below shows 1436 characters were written in a sub-directory as a JSON file and a Delta table has been created. Let us discuss the details of the write_json_file() and write_delta_table() functions next.

The fifth function is called “write_json_file”. The input parameters are the following: data – a Python dictionary, source – the name of the service, entity – the name of the information, rebuild – do we want to remove the directory; and debug – print out messages for the developer.
#
# 5 - write_json_file()
#
import json
import pandas as pd
from datetime import datetime
def write_json_file(data, source, entity, rebuild, debug):
try:
# time stamp
stamp = datetime.now().strftime("%Y:%m:%d-%H:%M:%S").replace(":", "")
# create vars 0
path0 = f'Files/{source}/{entity}/'
# remove directory?
if (rebuild):
try:
mssparkutils.fs.rm(path0, recurse=True)
except:
pass
# create vars 1
folder = stamp.split("-")[0]
path1 = f'Files/{source}/{entity}/{folder}/'
# make directory
try:
mssparkutils.fs.mkdirs(path1)
except:
pass
# create vars 2
root = '/lakehouse/default/Files'
path2 = f'{root}/{source}/{entity}/{folder}/{entity}-{stamp}.json'
# create df from json
# pdf = pd.read_json(json.dumps(data))
pdf = pd.DataFrame(eval(str(data)))
# write df to files dir
pdf.to_json(path2, orient='records')
# message user
if debug:
size = len(json.dumps(data))
print(f"SUCCESS - the function write_json_file() was able to write {size} characters to file {path2}.")
except Exception as e:
if debug:
print(f"FAILURE - the function write_json_file() return the following failure message {e}.")
if path2 is None:
path2 = ""
raise Exception(f"Error writing json file ({path2}) to storage. Here is the error message {e}.")
Here is a brief description of the algorithm used in the above code. Please note that the variable pdf represents a Pandas Dataframe and sdf represents a Spark Dataframe.
- Use datetime library to grab a timestamp.
- Optionally remove root directory.
- Create directory and subdirectory (timestamp).
- Use pandas library to covert dictionary to dataframe.
- Write dataframe to JSON file using a records orientation.
The sixth function reads up all JSON files in a root directory and creates a new Delta Table. The following lists the parameters to the function: table – name of the Delta Table to create; path – the location of all the JSON files; and debug – optionally turn on messaging.
#
# 6 - write_delta_table()
#
from pyspark.sql.functions import *
def write_delta_table(table, path, debug):
try:
# drop existing
stmt = f"drop table if exists {table}"
ret = spark.sql(stmt)
# read in json
sdf = spark.read.format("json")\
.option("recursiveFileLookup", "true")\
.load(f"{path}")
# load date
sdf = sdf.withColumn("_load_date", current_timestamp())
# add folder path
sdf = sdf.withColumn("_folder_path", input_file_name())
# add folder date
sdf = sdf.withColumn("_folder_date", split(input_file_name(), '/')[7])
# add file name
sdf = sdf.withColumn("_file_name", split(split(input_file_name(), '/')[8], '\?')[0])
# save a table
sdf.write.format("delta").saveAsTable(f"{table}")
if debug:
print(f"SUCCESS - the function write_delta_table() was able to read json files from {path} and create delta table {table}.")
except Exception as e:
if debug:
print(f"FAILURE - the function write_delta_table() return the following failure message {e}.")
raise Exception(f"Error writing delta table. Here is the error message {e}.")
Wow. The hard part is done. Let us look at the outputs from calling step 2 in the main program. The image below shows a snippet of the dictionary returned by calling “grab_spotify_single_data”.

This dictionary is saved as a JSON file in the correct subdirectory. Please see image below for details.
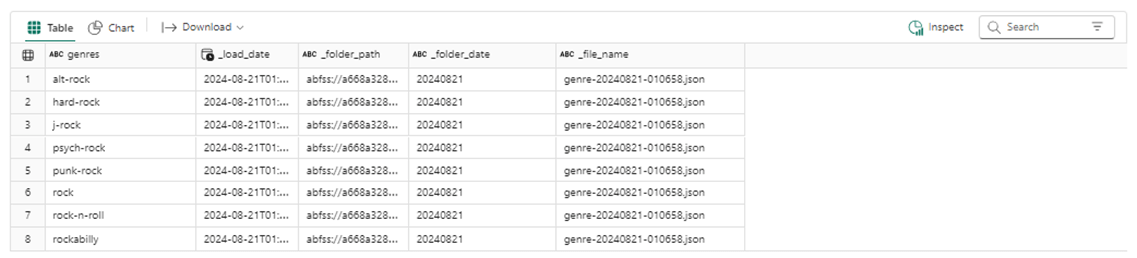
Finally, we can save the information as a Table. We added additional fields to the data such as load date, folder path, folder date, and file name. We can use the max folder date column to find the most recent records by Genres if needed.
In summary, working with single REST API calls is easy. In the next section we will search for artists using a paging technique. Other than picking elements out of the response body, the same functions we created will be re-used.
Artists Entity
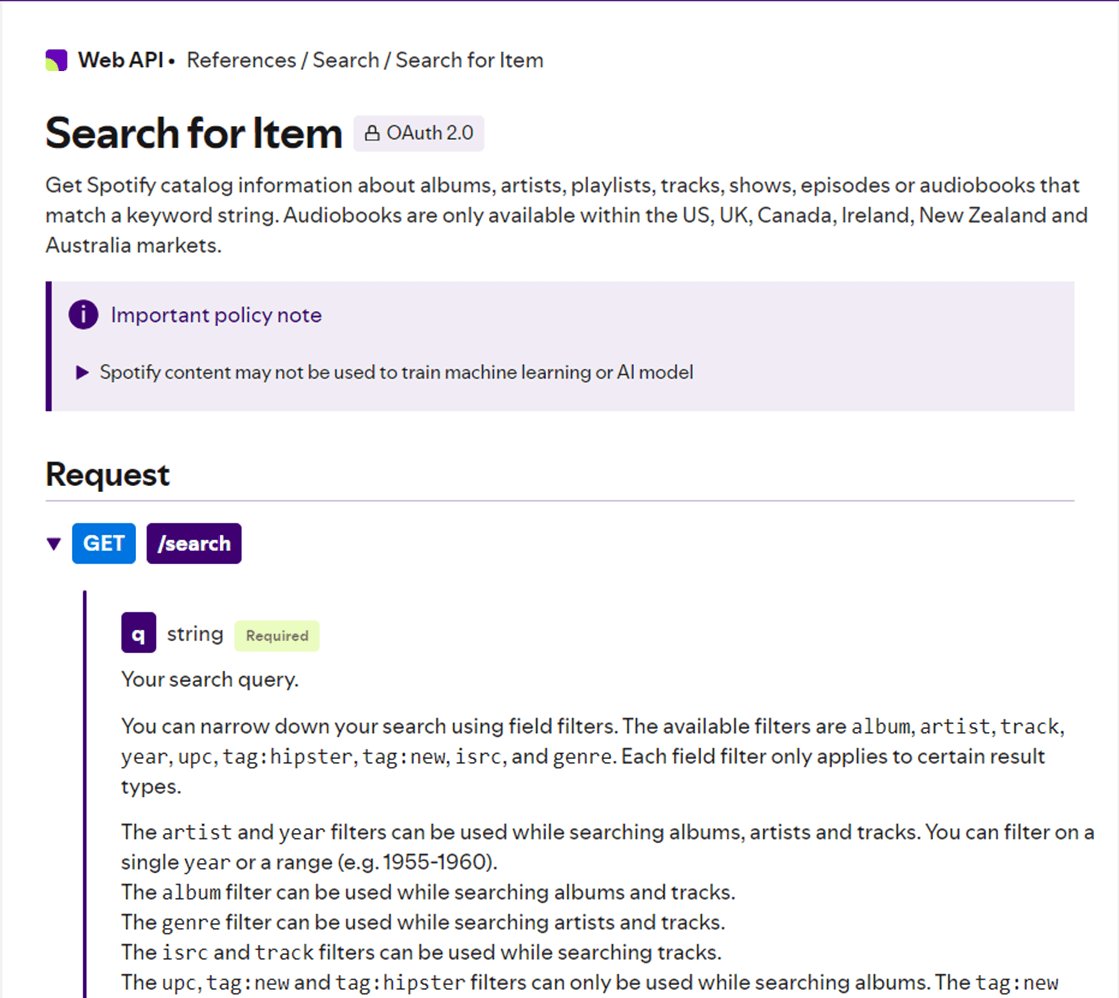
The screen shot shows the details of the search endpoint. You can look at the details using this link. Since there can be hundreds of resulting matches, the service returns the data by paging. Use the limit to control the batch size and the offset to control the page.
The code below represents the third step of the main program. There are no new functions to develop. I decided to search for artists between 1980 and 1989 whose music is considered rock. I decided to filter the result set for Bruce Springsteen. The program stores the results in batches of 20 to JSON files. I could have written the program to keep pulling data until an error occurs (end of search results). However, I decided to save only 5 batches to disk. The first batch rebuilds the directory and other batches just add files to the directory.
#
# Main - Step 3
#
import time
# define empty array
results = []
# read api - view 5 pages of 20 results
for i in range(0, 5):
# base url
base = "https://api.spotify.com/v1/search"
# page
print(i)
offset = i * 20
# query - rock between 1980 and 1989, filter B.S.
query = f"?q=Bruce Springsteen&type=artist&genre=rock&year=1980-1989&offset={offset}&limit=20"
url = base + query
# return data
rows = grab_spotify_single_data(url, key, True)
# process each row
for row in rows['artists']['items']:
ele = {
"id": row["id"],
"type": row["type"],
"name": row["name"],
"popularity": row["popularity"],
"genres": row["genres"]
}
results.append(ele)
# write artists to json file
if (i == 0):
rebuild = True
else:
rebuild = False
# want separate files
time.sleep(1)
# rebuild only first time
write_json_file(results, "spotify", "artists", rebuild, True)
# reset array - list
results = []
# read existing json + over write delta table
write_delta_table("spotify_artists", "Files/spotify/artists/", True)
There are two ways to process the JSON that is returned by the service. We can pre-process the data before saving. This eliminates any unwanted data. Otherwise, we can save the complete JSON document to disc and allow a complex Spark Schema to decode the data for us. I choose the first option for its simplicity. For each row, we create a dictionary called element and append it to the results list. This list is written as a JSON file in the corresponding directory. After writing all JSON files to disc, the Files directory in the Lakehouse, we can rebuild the Delta Table off these files.
The image below shows the raw response from the web service. The item property under the artists section is an array of search results.
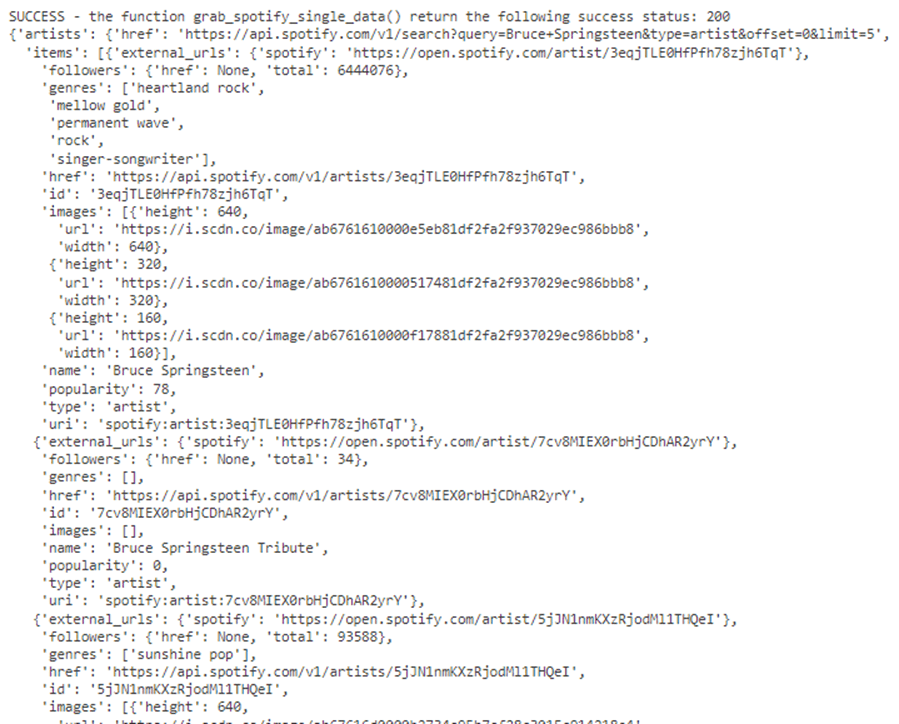
If we execute step 3 of the main program, we will see the following output. I used the sleep method of the time class to pause the program for 1second. We want each page to be associated with a unique file name.
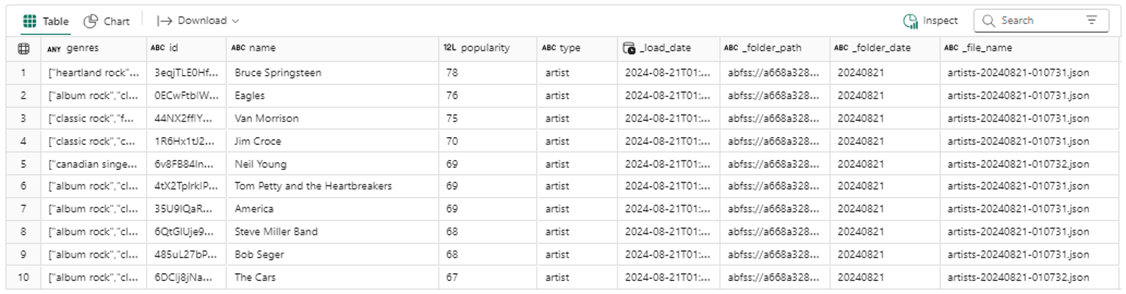
My first question is what are the most popular bands in the 1980s that are being listened to nowadays. Bruce Springsteen is ranked number one. However, the Eagles and Van Morrison are in the top 3.
%%sql -- -- Test 2 -- select * from spotify_artists order by popularity desc limit 10
Run the code above to answer our question. The output is shown below. Here are two observations about the Spotify service. It uses the search criteria for inclusion but not exclusion of records. Additional query string filters are not applied in exclusion manor.
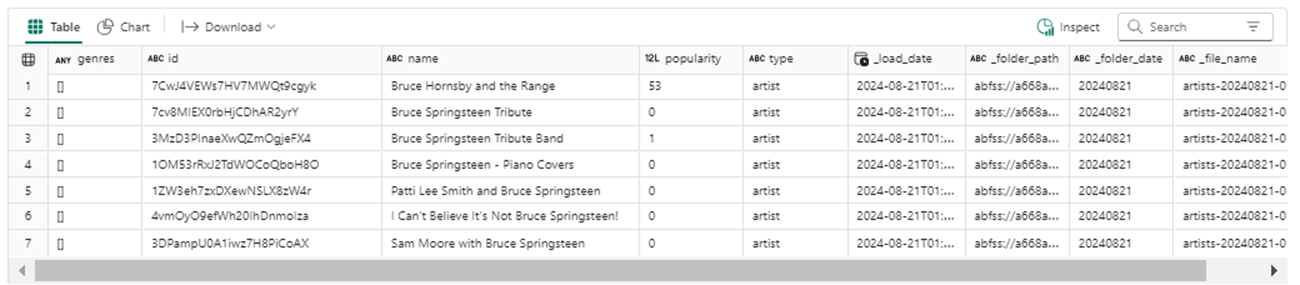
A better example of this functionality is to look at all records that have no genres. If we using a database and filtered by “rock”, all records will have this genre.
%%sql -- -- Test 6 -- select * from spotify_artists where size(genres) = 0
Run the above query to see the below results. The reason why the 7 records are included in the 100 records we pulled from the web service is the name of the artist. All of them are a full or partial match to the search value.
To recap, the whole purpose of this section was to talk about how to call a REST API service using the paging method.
Summary
Most REST API services supply the developer with a client id and client secret. If you use the Spotify service, you will want to create a logical application to retrieve these values. Confidential information like this should always be stored in an Azure Key Vault. The mssparkutils library can used to retrieve the secret for a given name.
To access most REST API services, we need to login to the service to retrieve a bearer (access) token. This token usually has a lifespan of 60 minutes. During that time, multiple calls to various endpoints can be made. Once the token expires, an HTTP error will occur. To resolve this error, just ask for another token.
I like using a modular design when coding in Python. You can even take it one step further by using object-oriented programming. Each task is broken into functions. We created functions for the following tasks.
- Grab key vault secrets
- Decode a redacted secret
- Grab an access token
- Make a GET http request
- Write a JSON file given a dictionary
- Read all JSON files and recreate a Delta Table.
Each one of these tasks were coded into a function and tested separately. These components were called one or more times to load both the genres and artists entities. Today’s article was not meant to be a complete coverage of the Spotify REST API. Instead, its purpose was to show design patterns that you might encounter when writing Python code in Microsoft Fabric to talk to Web Services.