

Introduction
Microsoft's marketing documentation marks indexed views an Enterprise (or higher) Edition feature. But Microsoft's SQL Server documentation says that indexed views can be used in lower editions if you use the NOEXPAND hint.
So I wrote that little feature up as a Question of the Day, thinking it might be useful information for the SQL community. But I got a very quick response saying that that feature was not, according to references on the web, available anymore as of SQL Server 2008R2.
My first reaction was that I had made a mistake; that I was looking at the 2005 or 2008 version of Microsoft's SQL documentation, and not 2008R2. A quick check verified that their most recent documentation claims that NOEXPAND still works in lower editions.
So I searched other sites for issues with NOEXPAND on lower editions. I found anecdotal evidence without any detailed testing. That didn't sit right with me, so I decided to test indexed views and NOEXPAND on as many versions and editions of SQL Server 2008 or higher that I had available.
The Plan
I wanted to make sure that I was testing only if NOEXPAND would allow the query optimizer to use an indexed view, and not other features or limitations of each edition. So I decided on a very simple testing methodology:
- Create a new database with default settings.
- Create a table with three columns: an identity bigint, set to primary key, a date column, and an nvarchar(50) column.
- Fill the table with a large number of psuedorandom dates and filler data in the nvarchar column, taking care to ensure that the dates are very much not in order when inserted, so that a query based on the date would benefit from an index based on the date.
- Query the table, filtering based on date range, to ensure that the query optimizer identifies that a date index would help.
- Create a simple view based on the table, and run the same query against the view, to show that the same query plan is used.
- Add two indexes to the view: a clustered index on the identity column (required to add a non-clustered index), and a non-clustered index based on the date column.
- Run the same query two more times: once without modification, to show whether the index will be automatically used, and once with the NOEXPAND hint, to show whether we can convince the query optimizer to use the index.
For my own curiosity, I also added the following two steps at the end of testing:
- Insert more data into the table, to see how the indexed view affects inserts.
- Run the query twice more, with and without NOEXPAND, to show how the index reacts to added rows.
The Subjects
I had the following versions and editions of SQL server close at hand, so I used them for testing and comparison:
- 2008 SP3 Express
- 2008R2 Express
- 2008R2 SP1 Express
- 2008R2 SP1 Standard
- 2008R2 SP1 Enterprise
- 2012RC0 Express
- 2012RC0 Enterprise (Evaluation)
1. Creating the Database
In all instances, I created the database using SQL Server Management Studio, and simply accepted the default settings for the database.
2. Creating the Table
Here is the code I used for creating the table in all instances.
-- Create Table CREATE TABLE [dbo].[tblIndexTest]( [ID] [bigint] IDENTITY(1,1) NOT NULL, [SomeDate] [date] NOT NULL, [SomeText] [nvarchar](50) NOT NULL, CONSTRAINT [PK_tblIndexTest] PRIMARY KEY CLUSTERED ( [ID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO
I originally used SSMS to create the table, and then generated a script, so, again, all default settings. I ran all testing using the above script for the table. Note that ID is a bigint field, to allow for as many rows as you'd like to test. My tests used approximately 4-8 million rows.
3. Filling the Table
To Fill the table, I used the following code. Note that it is dependent upon the number of rows in the master.sys.all_objects view, but in my brand-new installation SQL 2008R2 Express, that was 2,002 rows, and since I'm cross joining it, that made 4,008,004 rows -- sufficient for my purposes:
-- Generate Data insert tblIndexTest (SomeDate, SomeText) select cast( cast(cast(rand(checksum(newid()))*2000 as int)+ 1000 as varchar(10)) + '-' + cast(cast(rand(checksum(newid())) * 12 as int) + 1 as varchar(10)) + '-' + cast(cast(rand(checksum(newid())) * 28 as int) + 1 as varchar(10)) as date), N'Test Entry ' + cast(row_number() over (order by a1.object_id, a2.object_id) as nvarchar(40)) from master.sys.all_objects a1 cross join master.sys.all_objects a2 order by a1.parent_object_id, a2.parent_object_id, a2.object_id, a1.object_id GO
The first column, SomeDate, is made from three random numbers: first, a year from 1000 to 2999, then a month from 1 to 12, and a day from 1 to 28. SomeText is filled with a bit of text with a row number added at the end for variability. Finally, the data is sorted by other fields to ensure that neither SomeDate or SomeText will be sequential with respect to the autonumber ID column.
4. Creating the View
I'm going to break out of the order of testing for a moment, and show how the view and indexes are created. I'll go back to the query I used for testing once all of the structures have been explained. Then we can go directly from the query to the results.
The view is a simple, direct view of the underlying table, with the addition of the "with schemabinding" option, which is necessary to allow for indexes on a view.
-- Create View create view [dbo].[vwIndexTest] with schemabinding as select ID, SomeDate, SomeText from dbo.tblIndexTest GO
5. Creating the Indexes
For the testing I did, I needed two indexes. This is because the data I really wanted to index, SomeDate, is not unique. The first index on an indexed view must be a unique clustered index (). So I created a unique clustered index on the ID column and a nonclustered index on SomeDate:
-- Create Indexes CREATE UNIQUE CLUSTERED INDEX [ci_vwIndexTest_ID] ON [dbo].[vwIndexTest] ( [ID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO CREATE NONCLUSTERED INDEX [ix_vwIndexTest_SomeDate] ON [dbo].[vwIndexTest] ( [SomeDate] ASC ) INCLUDE ( [ID], [SomeText]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO
Once more, this is code from SSMS designer; I'm not testing if some custom implementation of indexed views will work; only if they will work in a standard situation.
6. Querying the Table or View
I used this code to query the view with the NOEXPAND hint:
-- Test Select from View With Index and NOEXPAND hint select * from vwIndexTest with (noexpand) where SomeDate between '2000-1-1' and '2009-12-31' order by SomeDate Go
To query the view without the NOEXPAND hint, I used the same code without the "with (noexpand)" line in it. To query the table, I replaced "from vwIndexTest with (noexpand)" with "from tblIndexTest". This ensured that any differences could be attributed to the existence of the view index, the use of the NOEXPAND hint, and the edition being queried against.
7. Results
If you just want an executive summary, here it is: indexed views can be created in all tested versions. When the query optimizer deems the index is useful, it will use it in the Enterprise editions, regardless of whether you use the NOEXPAND hint. It will also use it in the lower editions if the NOEXPAND hint is used and it determines the index is useful.
I ran all tests with "Include Actual Execution Plan" on, and saved all of the execution plans. They are included with the attached .ZIP file which also contains the full test script.
(One thing I wish I had done, but didn't, was to take screenshots of the execution plans before saving them. I have found that when you open a previously saved execution plan, then "Missing Index" hint for one query can show up for all queries, as you will see in the screenshots below. Originally, queries 7 and 9 (and 6 and 10 for the Enterprise editions) did not show a "Missing Index" hint. However, the query plan still shows that the index was used, so the evidence is preserved.)
Without further ado, here are the selected excerpts from the execution plans which I believe are most relevant to this question. As I've said, you can view the full execution plans in the attached .ZIP file. Note that differences in cost percentages and index impact are related to the randomness of the data and not considered to be differences in the query plan.
Query 1: Inserting the data into the table for the first time
This query was identical in all editions. I've included it to contrast with Query 8, which shows the extra work SQL Server does to maintain an indexed view.

Queries 2 and 3: Selecting from the table or the view with just a clustered index on the table
These queries were also identical in all editions. Note that the most expensive step is the Clustered Index Scan.
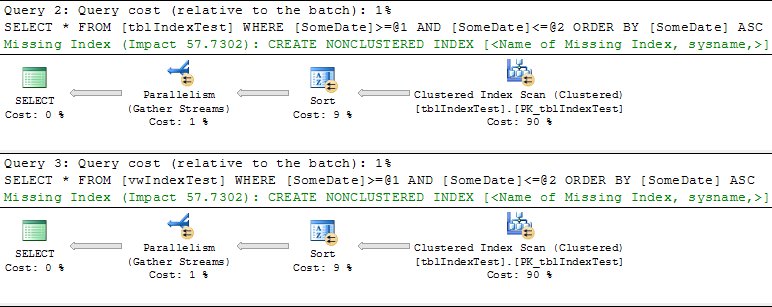
Queries 4 and 5: Creating the indexes on the view
Again, these were identical in all editions. If you look at the test code, there is no explicit insert to the view -- these queries actually derive from the CREATE INDEX statements. I include them here to show that SQL Server actually creates data in the database to create the indexes. This is sometimes referred to as "materializing the view".
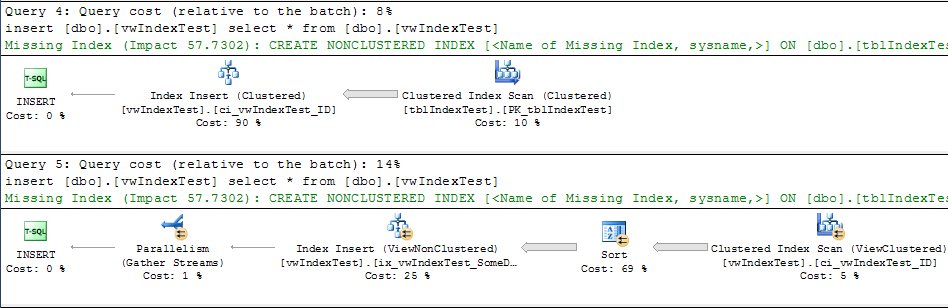
Queries 6 and 7: Querying against the indexed view
Here is where we start to see different execution plans. In all of the non-Enterprise editions, query 6 (the query without the NOEXPAND hint) runs a Clustered Index Scan:
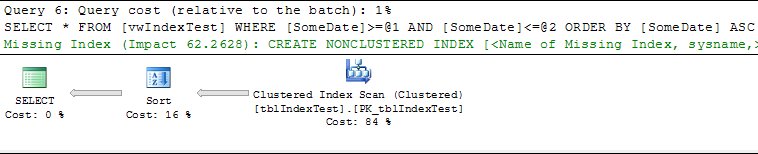
But the Enterprise editions run an Index Seek on the SomeDate index on the view:
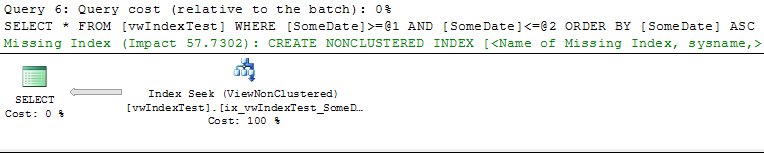
In query 7 (with the NOEXPAND hit) all editions run the Index Seek:

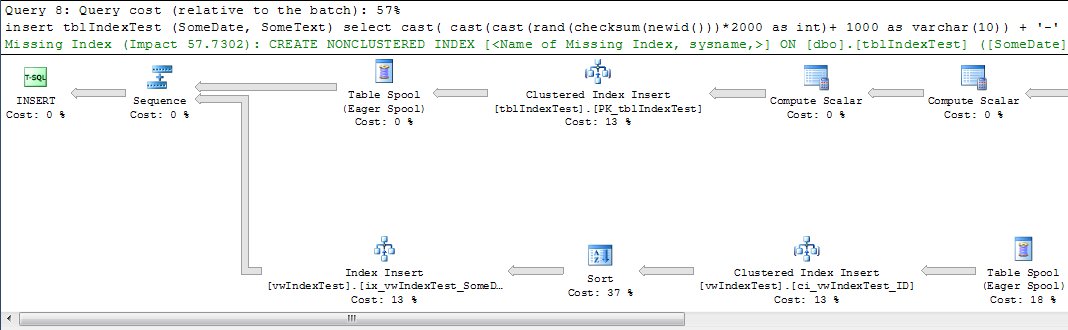
Query 8: Inserting into a table with an indexed view
Take a look at how this query plan differs from query 1. It's the same source data, but now SQL Server has to update the indexes on the view as well. As I said, the percentages aren't definitive because of the random nature of the data I'm using, but it's no coincidence that query 1 used roughly 25% of the batch resources in all instances, while query 8 was somewhere around 50%.
Queries 9 and 10: Querying against the indexed view with additional data
Here is where we start to see different execution plans. In all of the non-Enterprise editions, query 6 (the query without the NOEXPAND hint) runs a Clustered Index Scan:
In query 9 (with the NOEXPAND hit) all editions run the Index Seek:

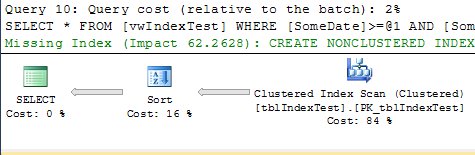
In query 10 (without the NOEXPAND hint), Enterprise editions still run an Index Seek on the SomeDate index on the view:

But the non-Enterprise editions still rely on the Clustered Index Scan:
Conclusion
Then NOEXPAND hint still works in non-Enterprise editions of SQL Server. I think there has been some confusion as to what this hint actually does. It forces the query optimizer to rely on the view, rather than the underlying table, for optimization. It does not force the query optimizer to use any given index on a view.
The sites I found online stating that NOEXPAND does not work did not include any testing methodology, so I can't say why it did not work for them.I can say that it can work in situations where the query optimizer decides the index is useful. Remember that the query optimizer is a "black box". We can impute some of its working properties from how it treats different sets of data, but only Microsoft knows completely how it works.Also, it is working from a lot more information (statistics, physical layout information) about your data than you likely have. This leads to it making decisions that we sometimes disagree with. Here are some possible conditions that can lead the query optimizer to choose not to use an index:
- A small original dataset is involved. If there's not that much data in the table, it can be faster just to do a direct scan of the data rather than an index seek followed by clustered index seeks. Think, for example, if all of your data resides on one page. A scan in that case would be loading one page. An index seek would require loading at least two pages.
- The index is not relevant. In the tests above, do you think the query optimizer would have used my index if I'd filtered and ordered based on SomeText rather than SomeDate? The answer to that is (hopefully) obvious. But what if you've created an index based on col1 and col2 in that order, and then weeks later, you find that col1 is no longer necessary in your filter and so remove it from your query? Then your index is no longer relevant to the query optimizer because it's sorted first by a column that is not filtered on.
- The index is not covering. If an index does not include all of the columns you're querying, then SQL Server has to go back to the original data (table or view clustered index) to retrieve additional data. This additional expense can make the advantage of the index dissappear.
- Something else. There are people who are much more versed in SQL Server than I am who could probably rattle off several more factors that affect the query optmizer's decision, and those whom I've talked to about the subject almost always end with "sometimes, it just does it the way it wants to."
So if you've been scared off of the idea of using indexed views because you thought they required Enterprise Edition, or that they were somehow "broken" in the lower editions, they deserve a second look. They can work. Whether they're the right way to go depends on your data and how you use it.
References
- Comparison of SQL Server 2008R2 Editions: http://www.microsoft.com/sqlserver/en/us/product-info/compare.aspx
- MSDN - Designing Indexed Views: http://msdn.microsoft.com/en-us/library/ms187864.aspx
- Network World article which seems to be the source of the idea that NOEXPAND no longer works: http://www.networkworld.com/community/blog/indexed-views-are-good-feature-which-edition?source=nww_rss


