

Introduction
Indexes are a vital part of SQL Server and knowledge beyond the basic understanding of them is necessary to creating and maintaining a high performance server. In this article I will go into the details of the internal information that SQL Server keeps regarding the index itself and how the optimizer uses this information in determining wether or not to use the index. Indexes, both clustered and non-clustered, store statistical information in the same way. Understanding this will enable you to better build and use the indexes you have. Statistics are stored in two different ways; steps and densities.
In-Depth: Steps
SQL Server keeps detailed information on the prefix of an index. The prefix of an index is the first column. If you have a single column index, then that column is the prefix. If you have a compound index (2 or more columns), the first column is the prefix.
The prefix information is stored in 200 'steps' (you can think of them as records). Basically this means that SQL Server looks at all of the possible values for your prefix and condenses what it finds into at most 200 steps. To see this information you need to run the following command:
DBCC SHOW_STATISTICS("<owner>.<tablename>","<index_name>")
The information for IDX1 is shown below:
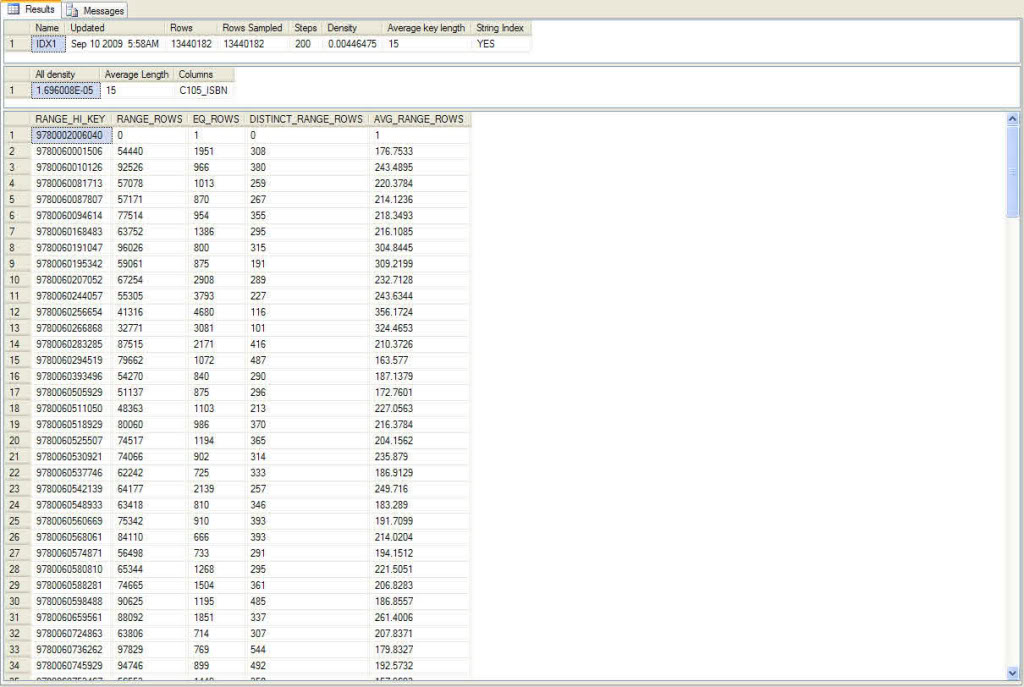
For each of these steps it keeps five pieces of information:
- RANGE_HI_KEY: Starting boundary for the step.
- RANGE_ROWS: How many rows in the base table fall between this Range_HI_KEY and the next (not including either).
- EQ_ROWS: How many rows in the base table match the Range_HI_KEY.
- AVG_RANGE_ROWS: How many rows for each distinct value within the range.
- DISTINCT_RANGE_ROWS: How many distinct values between, but not including this RANGE_HI_KEY and the next.
If you have less than 200 distinct values for your prefix you will have that many steps. If you have over 200 distinct values for your prefix, SQL uses a more complex set of formulas to compress this information into the 200 steps (see the reference link for more details on this).
Let's look at the second line of the bottom (3rd) pane. It has these values:
- Range_Hi_Key: 9780060001506 --value (ISBN in this example)
- RANGE_ROWS: 54,440 --number of records between, but not including 9780060001506 and the next key 9780060010126
- EQ_ROWS: 1951 -- number of records that equal Range_Hi_key
- DISTINCT_RANGE_ROWS: 308 -- number of distinct values between, but not including 9780060001506 and the next key 9780060010126
- AVG_RANGE_ROWS: 176.7533 -- number of records for each distinct value (those within the DISTINCT_RANGE_ROWS)
The above is to give you a deeper understanding of how the optimizer sees an index and it helps you understand your data. Let's see what the above numbers tell me.
The above step starts at ibn 9780060001506 and goes to 978006001025. If you are looking for isbn 9780060001506, the optimizer would know there are 1,951 records. There are 308 distinct values between 9780060001507 and 9780060010125. For each of those distinct values, there are on avg. 177 (rounding up). If you decided to do, say a between 9780060001507 and 9780060010125, the optimizer knows there are 54,440 records.
In-Depth: Densities
I mentioned before that SQL Server stored index information in two ways. The second way is density. Look in the second pane under the column All density. For the given column, C105_ISBN, SQL Server thinks there are (0.00001696008*13440182)=227.94 records for each C105_ISBN. The lower this number, the greater the selectivity and the better the index is. This information is used when SQL Server needs to do a join, since it does not know the exact value. The density information is crucial to understand since it is the basis for all compound indexes. Here is another example:
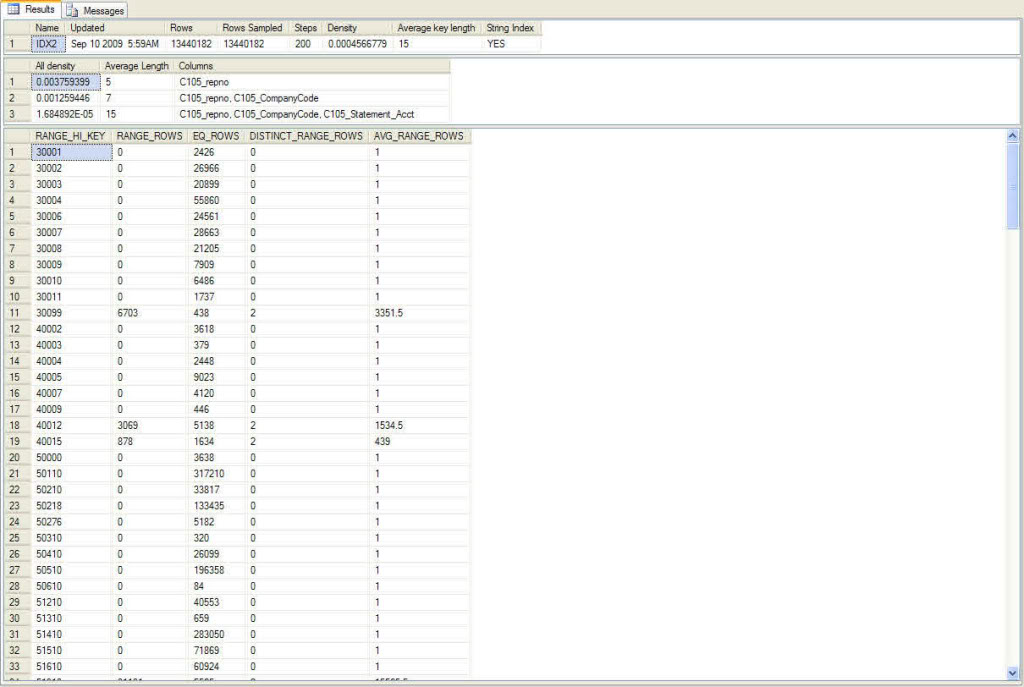
If you look at the second pane you will see each of the three columns in the order they exist in the index itself. If you notice, SQL Server only knows the density for the following combinations:
The group below will has the densities listed above.
- C105_RepNo
- C105_RepNo,C105_CompanyCode
- C105_RepNo,C105_CompanyCode,C105_Statement_Acct
This combination is implied:
- C105_RepNo,C105_Statement_Acct
The combinations listed below are not supported, because SQL Server does not have statistics for them. SQL Server only keeps statistics for the prefix (first column of the index) and densities for combinations, so long as those combinations contain the prefix. Without the prefix, there is no density and without the density there are no statistics. The need for the prefix is due to how SQL Server determines densities. He does not present every combination (as that could go astronomical with large indexes).
- C105_CompanyCode
- C105_Statement_Acct
- C105_CompanyCode,C105_StatementAcct
Conclusion
When joining up tables, the optimizer must use the density calculations stored within the index meta-data. These calculations are wholly dependent upon the prefix, so remember this when considering an index:

