

Like many of you, I recently had to import some data in a CSV (comma-separated file) into SQL Server. This wasn't a new process, or an application that needed enhancing, or even an ongoing ETL (Extract, Transform, Load) process that needed to be built. This was an ad hoc, semi-one-off request. It's a similar type of request that I've had come across my desk over the years from many sources. Whether I was a DBA or developer, often someone gets a little data and wants it cleaned up and in a structured format to easily run a report or analyze the information.
In this case, the request was from my wife, to help her with business taxes. She had a number of exports from various bank and accounting systems that she wanted to consolidate and run reports again. I offered to help, thinking this would be just a few minutes to load and then export the data.
I was wrong.
This article looks at some of the hassles and frustrations of working with CSVs in SQL Server, some of which I think are quite unnecessary.
Messy Data
Like some of you, I don't like getting CSV data from others. From me, it's fine. I usually export things in a way that make it easy for my to import them. When I get your CSV, I'm usually not pleased. In this case, my wife emailed me 2 zip files with data. One was from Venmo and the other from Paypal. The Venmo one had 12 files, one for each month. Each lovingly named something like venmo_statement (1).csv, venmo_statement (2).csv, etc. The Paypal data had monthly PDFs, but one csv for the year. At least I'll only be cursing Paypal once during this process.
The first step is often to look at the data. When I looked at the Venmo stuff, it was a lot of fields, with a header row containing the starting balance and a final row with the ending balance. There were also some lovely sections in the middle with interesting characters. Here's an example of a field inside the CSV.
![]()
Apparently I won't be importing things into varchar() fields.
When I opened this in Sublime Text to get an idea of the structure, I saw this:
Username,ID,Datetime,Type,Status,Note,From,To,Amount (total),Amount (fee),Funding Source,Destination,Beginning Balance,Ending Balance,Statement Period Venmo Fees,Terminal Location,Year to Date Venmo Fees,Disclaimer HerdofTwo,,,,,,,,,,,,$500.00,,,,, ,5555555555555555,2020-01-10T02:50:47,Payment,Complete,Stock show,Cowboy Joe,My Wife,+ $10.00,,,Venmo balance,,,,Venmo,, ,555555555555555,2020-01-16T14:12:08,Payment,Complete,"You're magic ?? (sorry, totally spaced it)",Random Person,My Wife,+ $50.00,,,Venmo balance,,,,Venmo,,
The Paypal data was simpler and more structured, similar to this:
"Date","Time","TimeZone","Name","Type","Status","Currency","Amount","Receipt ID","Balance" "01/01/2020","19:04:43","PST","Sandra Dee","Mobile Payment","Completed","USD","500.00","","1,000.00"
This shouldn't be too bad, right? Let's get started.
Setting Up in SSMS
The first step was to create a database. That's easy. Then I decided to use the Import Flat File Wizard to load my data. It's 12 files, and by the time I actually program something, I could easily run through the wizard 12 times.
This wizard is simple, and it allows you to pick a file and create a table. I'll walk through that. After starting the wizard, I pick the file and give a table name. It suggests one, and a schema, but I can change these.
I can't select more than one file, so this is really a one-off type wizard. That's fine. I can do this 12 times.
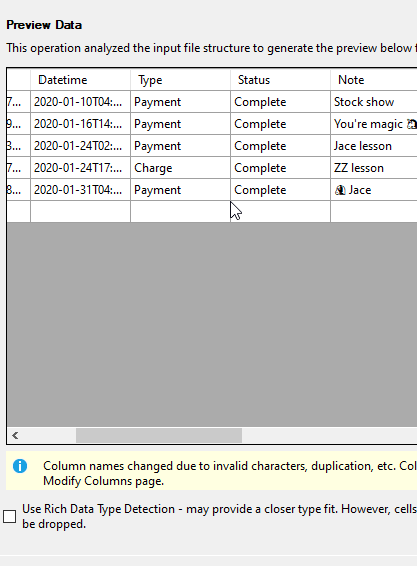
Next I preview the data. I scrolled over and didn't show everything below as some of this is PII data. However, you can see there is a warning that some names were changed. I suspect these are column names as the CSV likely has some keyword clashes. I could have used rich data type detection here, but not sure that would be better. There's only 5 rows here, so there isn't a lot to sample.
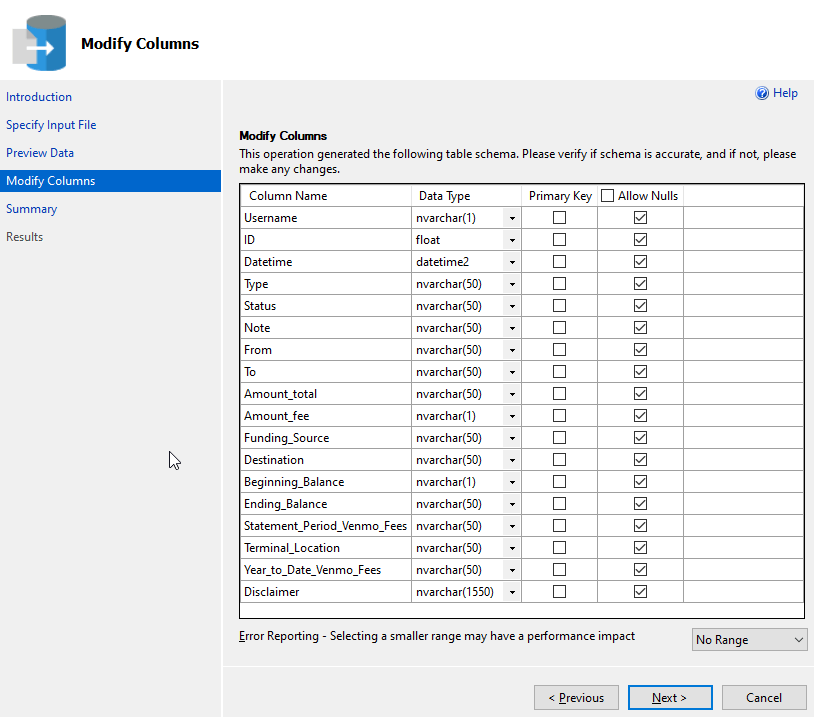
The next step in the wizard is the datatype mapping for the table. Here I can change the types, set a PK, nulls, etc. In my case, the nvarchar() works well for these fields. The one issue is the ID field, which really needs to be a string type. In reality, I later realized I didn't care about most of these fields, but to get started, I needed to load them up.
After this I get the summary and can click Finish to load the data. This works quickly, and successfully.
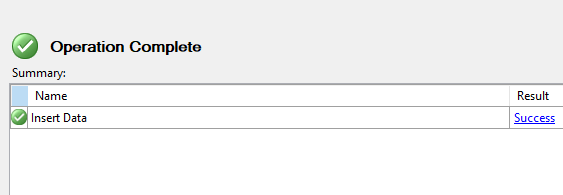
This worked well, and I had a strange staging table. However, each time I run this, I get a different table name, which means I then need 12 statements to consolidate this data together. Not the end of the world, but clunky. If I try to re-run this and pick a different flat file and use the same table name, I get this:
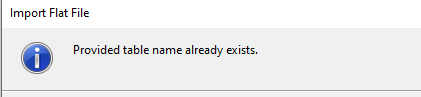
I'm not sure why there's a restriction here. My guess is that the wizard is so basic that no one programmed in the logic to deal with an existing table. Seems an oversight to me, poor specifications, and a developer that locked down on specific tasks without thinking how people might use this. And poor leadership from management, but it works.
All in all, this wasn't a bad experience, but it was a repetitive way to import 12 files. Actually 13 since I had to get the consolidated PayPal statement loaded.
The SSMS Import Data Wizard
After my first import, I thought about using the Import Data Wizard. This is in the right click, Task context menu for a database, as shown here.
I thought this might be better because it can build an SSIS package, maybe one I can add a loop to and load data to one table. I also thought this might be a nice once-a-month execution as my wife gets new files.
This starts with a data source choice. I picked a flat file and then picked my file. My first complaint came when I went to pick a file. Despite saying "flat file source", the explorer box defaults to .txt files, as shown here.
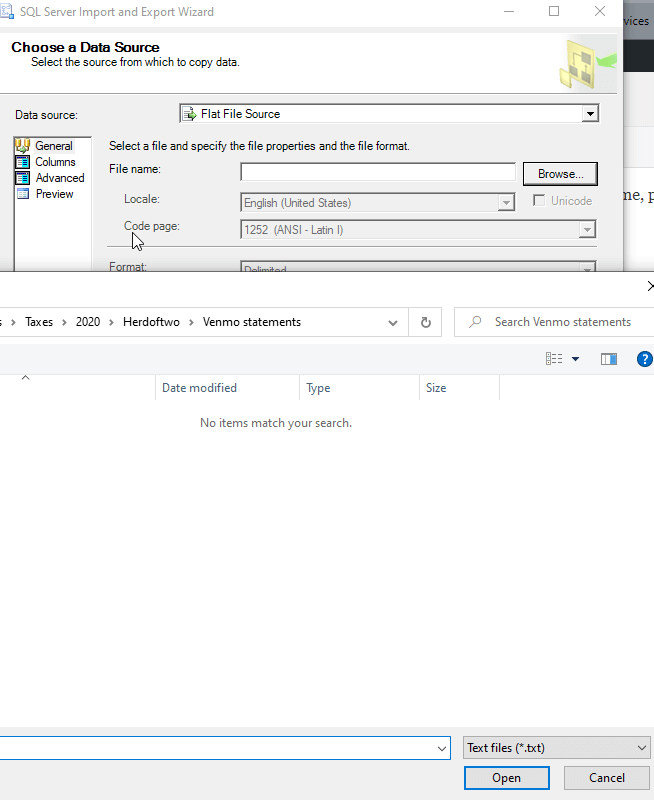
This is really poor UI. I'd think .txt, .csv, and .tsv would be options by default. I know Explorer can do this, it's just lazy programming.
In any case, I can pick my file and it detects most things correctly. This looks like it will pick up the data from the file just fine.
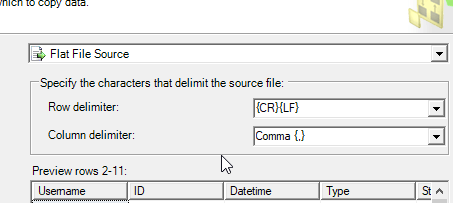
Next I pick a destination. I tend to use the OLEDB driver, mostly because the connection string settings are simple. This has worked the same as the .NET provider in this case.
Here, a few annoying defaults. First when I select the properties for the driver, it always opens the dialog box in the upper right corner of my default monitor. In my case, that happens to be the left monitor, and it's out of my direct vision. I didn't notice this wizard, and why it doesn't open near the existing open dialog is beyond me.
Second, it defaults to SQL auth. Almost every recommendation I've seen from Microsoft is use Windows Authentication, so why isn't that the default here? Next, it has a blank password checkbox checked, which violates secure by default, in my mind.
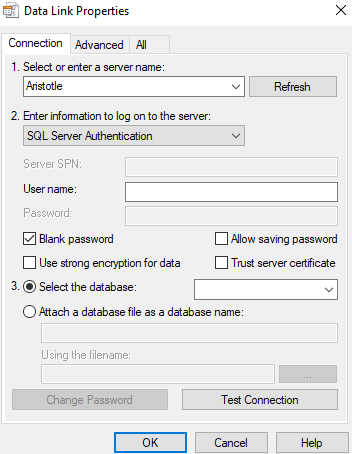
Maybe the last thing is that this is got a lot of settings for things that I don't often change. I'm guessing most people don't. Most of us want to enter an instance and choose a database. I have to mouse around, change the auth, etc. Put the things I use a lot first, and drop everything else on other tabs. After all, it's not like tabs aren't a thing in this dialog.
Once I get past my annoyance, I see the source and destination. I can edit the mappings and they mostly look OK.
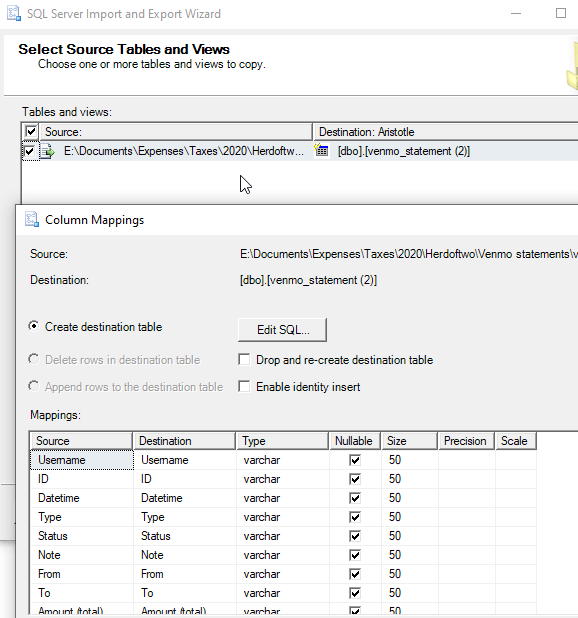
At this point, I can review the summary, save an SSIS package, and run this. However, I get this from a simple import.
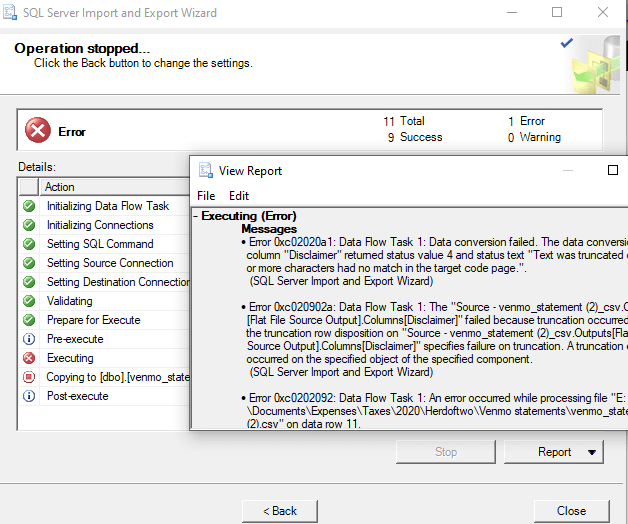
Hmmm, the disclaimer field has a truncation error. There are only 5 rows in this file, so how did the wizard not pick the right size? I go back and check and find this field defaulted to varchar(50). Too low, and the wrong data type, so I change it to nvarchar(1050). Again, I get a failure. I then change to 4000, which is far beyond what the Flat File Import did. Still doesn't work.
At this point, I suspect some code page error, but debugging that seems like more work than importing 12 files every year for a decade. I suspect someone knows the issue, and I hope they can tell me because at this point, I feel quite a bit of rage toward the developers that built this thing. It's supposed to make life easier, but it doesn't.
ADS
Azure Data Studio (ADS) has a SQL Server Import extension you can try. This is installed from the marketplace, and then you see this when you click the extension.
If you scroll down, you see CTRL+I starts this wizard. For me, it took about 8-10s to get a connection dialog to open the first time, so be patient. After that the dialog opened quickly. There also isn't any sign this connection for the import wizard is different from the normal server connection, so beware of that.
I connected to my database and then got a settings page, much like the SSMS Flat File Wizard.
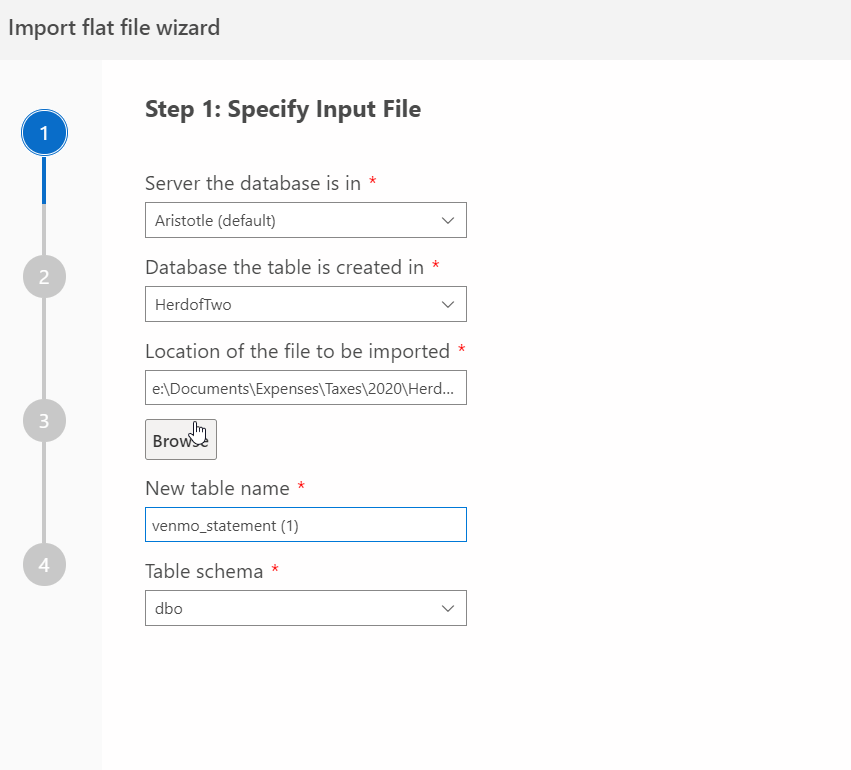
I clicked Next and got a preview of my data.
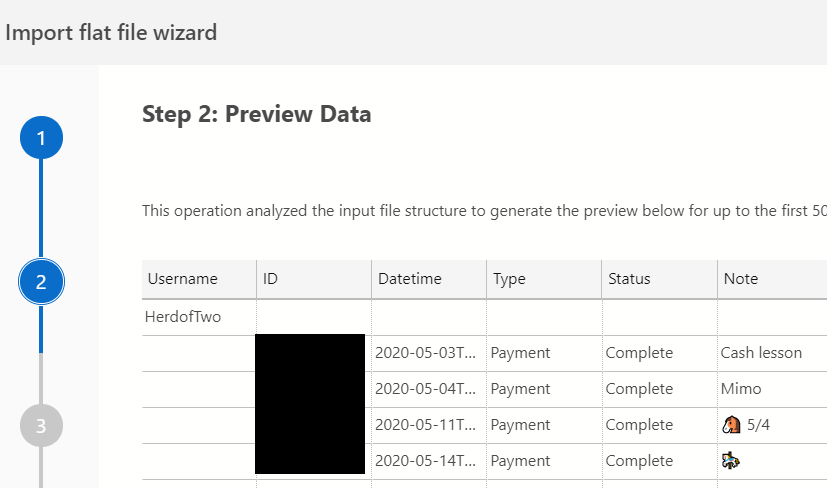
Next I had the chance to check data types. I left these alone as I was curious how well this worked, especially as all of my data was in a few rows.
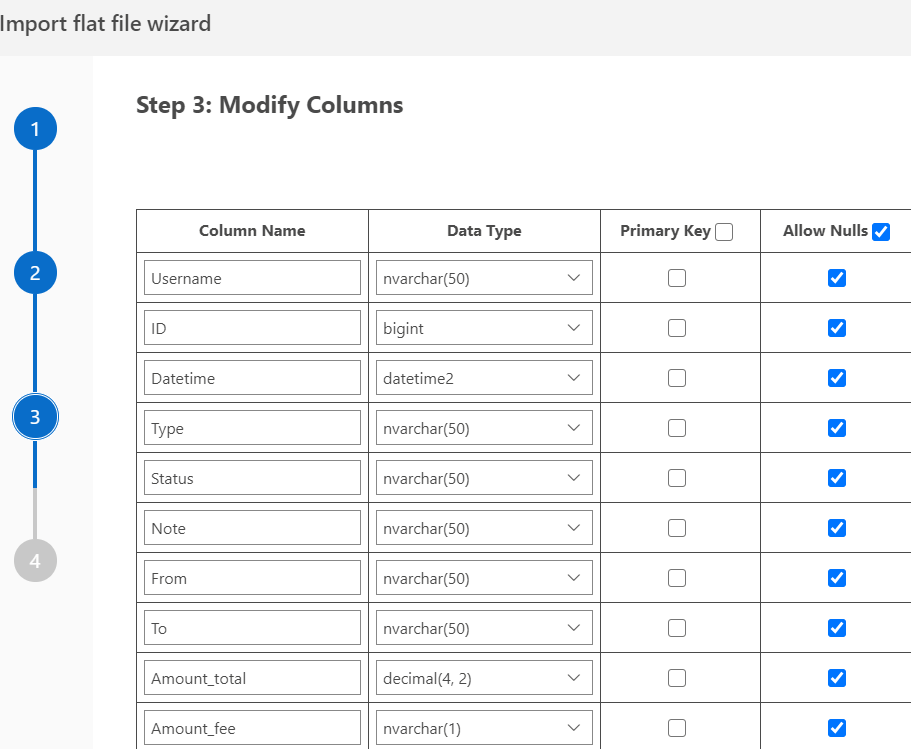
Then we get to the final page and the import starts. For me, I got an error right away. In this case, it's a currency -> numeric error. While I get that the database shouldn't know all the currency symbols, I do think this is a place where the wizard ought to be smarter. If it detects this as numeric, then it ought to strip the thousands and currency symbols out, especially for my current regional settings.

I went back and changed all the numeric fields to nvarchar and went to the end of the wizard. This time things worked.

What I liked about this wizard was that rather than only a "Done" or "OK" button, there as also a "Import new file" button. This allows me to restart the wizard without having to press a few keys. That's something software should do. This opens the wizard with my connection settings, and the "browse" button for the flat file takes me back to the last location.

When I did this and selected a new file, I choose the same table name as I'd used for the previous file. I walked through the wizard to the end, when I got the error below. I wish that as soon as I'd picked an existing file it would tell me, rather than have me click Next a couple times.

Overall, however, the ADS wizard was quicker to use than SSMS.
PowerShell
In the midst of trying to get the wizards to work, I complained on Twitter. A few people suggested PowerShell and others noted dba tools has an Import-DbaCsv cmdlet. I decided to try this. My first attempt was to be as simple as possible. I used this cmd (paths changed)
Import-DbaCsv -Path "E:\Documents\Taxes\2020\Venmo statements\venmo_statement (6).csv" -SqlInstance Aristotle -Database HerdofTwo -Table "VenmoData"
I got an error, as the table didn't exist.
I didn't try the Import-Csv cmdlet, as I'd then need to do my own manipulation to get the results into SQL Server.
Summary
I was given some simple files to import for my wife. In this case, I had 12 of one format and 1 of another. All I wanted to do was load these into a couple tables and then export them again. I was surprised that the SSMS tools were clunky and cumbersome to use. PowerShell, or more specifically, dba tools, proved to be the best way to do this repeatable task 13 times. Once I'd done this, I had a short script that I can use in the future to import other files as needed.
This was only part of my job, as I had to delete some rows (starting/ending balance items) and then pull common fields into a table where I can export them for my wife. However, what I thought might be a 5 minute task turned into a 20-30 minute journey, mostly because I was learning just how poorly Microsoft tools handle a simple csv file. I'd have expected that aiming for a simple import to a new table, with all string columns, would be a simple option. I'd also expect to be able to repeat my import to an existing table.
I know ETL is a complex topic, and CSVs can be quite frustrating to deal with, but in this case, I think the software isn't built or developed anywhere near as well as it could be.
