

Inserted identity column value
As a Senior Database Developer I am involved in different aspects of business process automation for my company and SSIS is very widely used for that purpose. I think I do not need to explain how important sometimes it could be to get identity column values for inserted rows. In SQL 2005 you can obtain inserted identity values in several ways – for example, use identity functions or the OUTPUT clause for INSERT statements.
The problems come when you need to catch inserted identity values in SSIS and save them into package variables to be used later. Sure, it can be done by developing with the special tracking output tables using for OUTPUT clause in an INSERT statement. The pattern for such a T-SQL statement is provided below.
INSERT INTO <table name> (<columns>)
OUTPUT Inserted.<columns>into <tracking table name>
SELECT ...
This works perfectly in the Execute SQL Task control for both SSIS versions - 2005 and 2008, but the main disadvantage is that you have to develop custom logic for inserted values for each tracking table. Actually there is another way to do that. Let’s imagine that we have a log table defined as shown below.
CREATE TABLE [dbo].[JobLog](
[JobLogID] [int] IDENTITY(1,1)NOT NULL,-- Process execution time ID
[JobID] [int] NOTNULL, -- Process ID
[Status] [smallint] NULL, -- Execution Status
[ts_Start] [datetime] NOT NULL, -- Process execution start time
[ts_End] [datetime] NULL -- Process execution end time
)
Then we could develop SP as shown below to retrieve inserted ID value.
CREATE PROCEDURE [dbo].[GetJobLogID]
@Job_ID int,
@Job_Log_ID intoutput
AS
BEGIN
SET NOCOUNT ON;
insertinto JobLog (JobID, ts_start, status)
values (@Job_ID,getdate(),0)
select @Job_LOG_ID = scope_identity()
END
This SP can be executed in the Execute SQL Task control and package variables can be used to save values for each inserted ID. This is an elegant enough solution except for the fact you need create such a SP for each logging table.
I expected to have this functionality enabled in SQL 2008 - according to the citation below (May 2008 SQL 2008 BOL).
Enhanced SQL Statements
Integration Services includes the following enhancements to Transact-SQL statements:
- …
- Retrieve data about changes to a data source The INSERT operation supports inserting rows into a target table that are returned by the OUTPUT clause of an INSERT, UPDATE, DELETE, or MERGE operation. For more information, see INSERT (Transact-SQL).
- …
But by some reason it was not implemented in SQL 2008 RC0 (or maybe I just couldn’t find the right way…)
That’s why the way #3 – described below - was chosen.
Solution
I am going to provide a description for how to assign result generated by OUTPUT clause to package variable – it works perfectly for both – 2005 and 2008 – versions. An ADO.NET connection type was used for provided examples.
To get the values generated by the OUTPUT clause as a single row you need:
- Define package variables with proper types by using package level scope
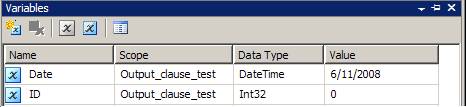
- Configure Execute SQL Task control
2.1. Select Single Row as a Result Set
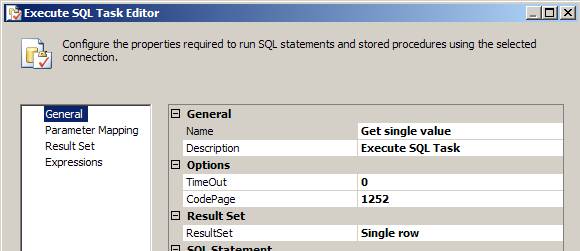
2.2. Provide the following code for the SQLStatement parameter
set nocount on
insert into test_table (ID, date)
output inserted.id, inserted.date
select top 1 object_ID,getdate()
from sys.objects
2.3. Configure Result Set
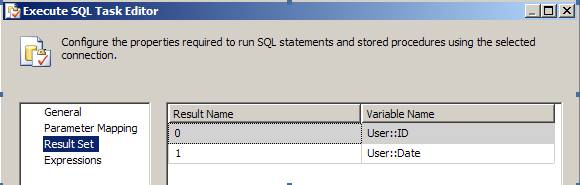
- Click the OK button in the Execute SQL Task editor to save changes – that’s it for a single row result.
To get the values generated by the OUTPUT clause as a row set you need:
- Define additional variable with Object data type
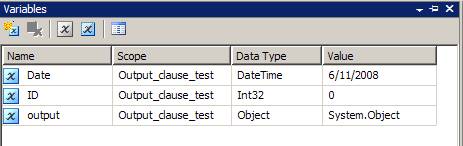
- For Execute SQL Task control
2.1. Select “Full Result Set” as a Result Set value
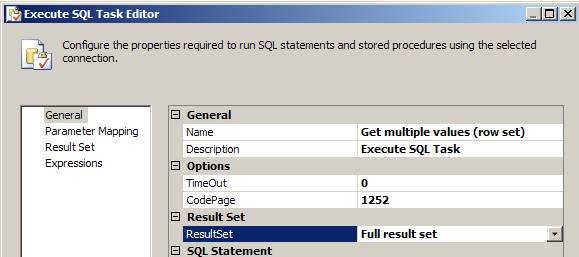
2.2. Provide the following code for the SQLStatement parameter
set nocount on
insert into test_table (ID, date)
output inserted.id, inserted.date
select top 5 object_ID,getdate()
from sys.objects
2.3. Configure Result Set as show below
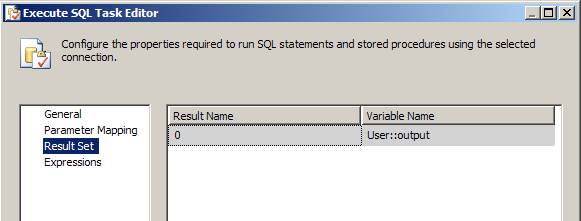
- Click OK button in Execute SQL Task editor to save changes.
- To process obtained row set you need to use For Each Loop container to get the values from each row into set of package variables.
4.1. Set up Collection properties as shown below

4.2. Provide Variable Mappings
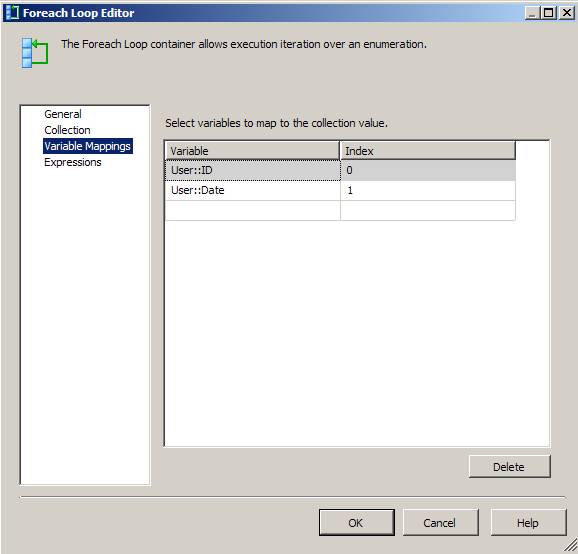
- Press OK. Now you can provide the needed functionality for your For Each Loop container – for example process the rows from User::@output variable one-by-one and save it into different tables with different attributes according to your business logic needs.
Summary
I think this functionality could be very helpful if you need for example provide predefined process execution monitoring, custom logging and auditing. In my case I have several automated production processes and each process may have several steps. Process (and process’s step) execution may be triggered at any time by a predefined set of events but execution may be terminated if process / step pre-requests is not completed. The process execution conditions, input and output process parameters, and process / step verification rules are described in a set of tables where each process and step has its own “definition” ID. During the execution time each process / step gets its own “execution”/ logging ID that’s used for process monitoring.
For example one of the processes generates set of PDF reports. If the report consumers are internal users, then reports can be delivered via email immediately. If reports have to be delivered to outside consumers, delivery will not provided until confirmation of the reports verification will be provided from the QA group. In other words one “definition” ID produced two “execution” IDs with its own process execution rules.
The attached package represents 2005 version and can be run in 2008 as well (it’ll be converted automatically if you open the solution in 2008 BIDS)
Gennadiy Chornenkyy
Senior Database Developer, Empathica Inc.
MCITP (DBA & Dev), MCDBA, MCAD

