

In this article, we will learn how to use a PowerShell script to track network latency issues in an Always On Availability Group (AOAG). Network latency sometimes is a real issue for the AOAG. If the network latency is too high, the primary replica will lose the network connection to the secondary replica. This may cause an automatic failover in the AOAG. In this case, we use System Center Operation Manager (SCOM) to monitor our AOAG, and we found this automatic fault occurs regularly.
Fault Phenomenon
We have an AOAG based on two SQL Server 2017 nodes, and we found that we received the alert from SCOM weekly from System Center Operation Manager. Here is the description of the alert:
Description: MSSQL on Windows: Availability Replica Role Changed, Description: Event ID: 19406. The state of the local availability replica in availability group 'AG1' has changed from 'RESOLVING_NORMAL' to 'SECONDARY_NORMAL'. The state changed because the availability group state has changed in Windows Server Failover Clustering (WSFC). For more information, see the SQL Server error log or cluster log. If this is a Windows Server Failover Clustering (WSFC) availability group, you can also see the WSFC management console.
We can find more details about "Event ID 19406" from Microsoft at this link: https://systemcenter.wiki/?GetElement=Microsoft.SQLServer.Windows.EventRule.AvailabilityReplica.RoleChanged&Type=Rule&ManagementPack=Microsoft.SQLServer.Windows.Monitoring&Version=7.0.20.0
Referring to this explanation, the WSFC failure caused the AOAG failover, therefore I analyzed what happened on WSFC first.
Here are the components of AOAG mentioned in this article. Server names have been partly masked by "*".
1. SQL Servers:
- ***PN1 (called PN1 below, the primary replica in AOAG)
- ***PN2 (called PN2 below, the secondary replica in AOAG)
- the Always On Availability Group name is AG1 which is composed of ***PN1 and ***PN2 based on WSFC
2. File share server for this Windows cluster witness: ***ON1
Fault analysis
First, I collected the Critical Event log of the Windows-FailoverClustering in PN1. Here are the relevant portions:

I collected the Critical Event log of the Windows-FailoverClustering in PN2 and see this:

Regarding these event logs, the WSFC issue happened around 5:18 PM on 10/13/2021.
Second, I collected evidence about the network disconnection between PN1 and PN2 around 5:18 PM on 10/13/2021. I used a tool, named hrping (https://www.cfos.de/en/ping/ping.htm), to help with my diagnosis. This is a very useful free tool. Please refer to this tool's guide about using the tool to log the "time out" to the text files.
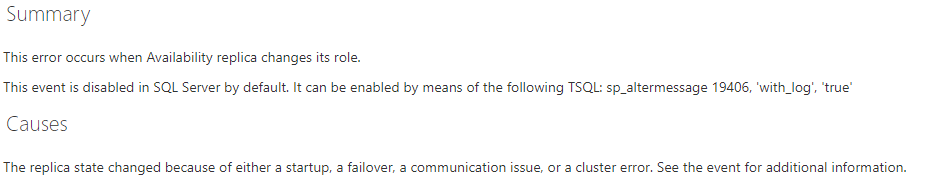
Here are records of the ping time-out from PN2 to PN1, the timestamp of "time out" are as the same as the WSFC failure which marked in blue:
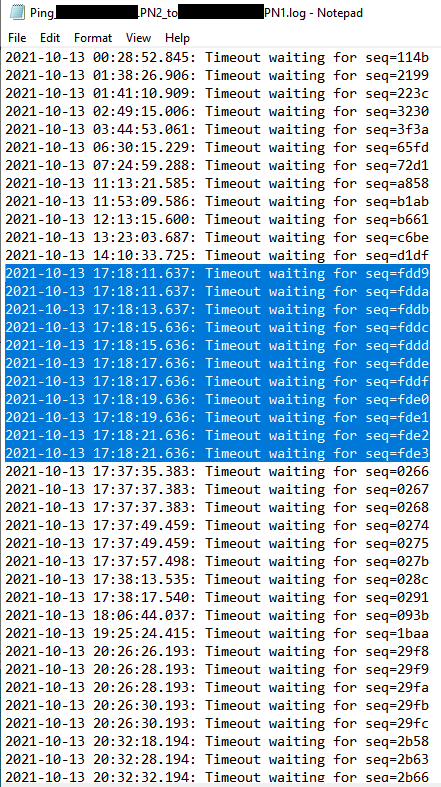
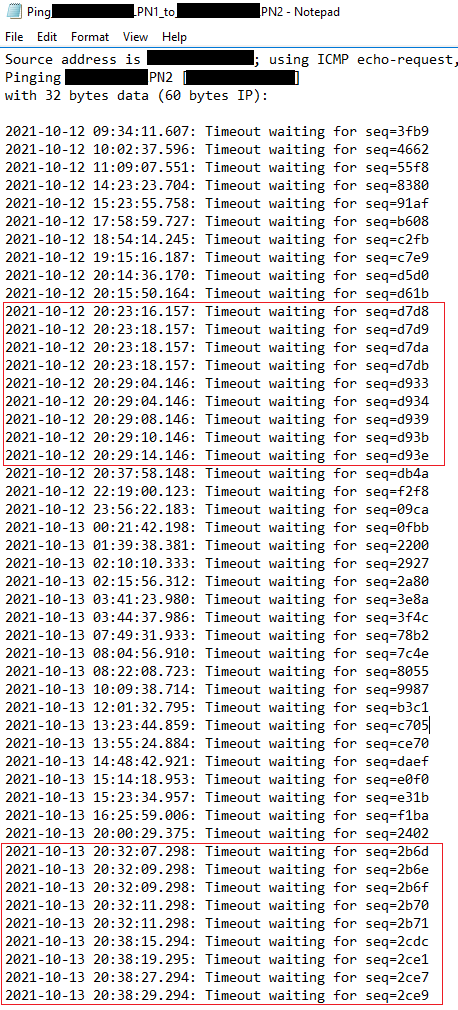
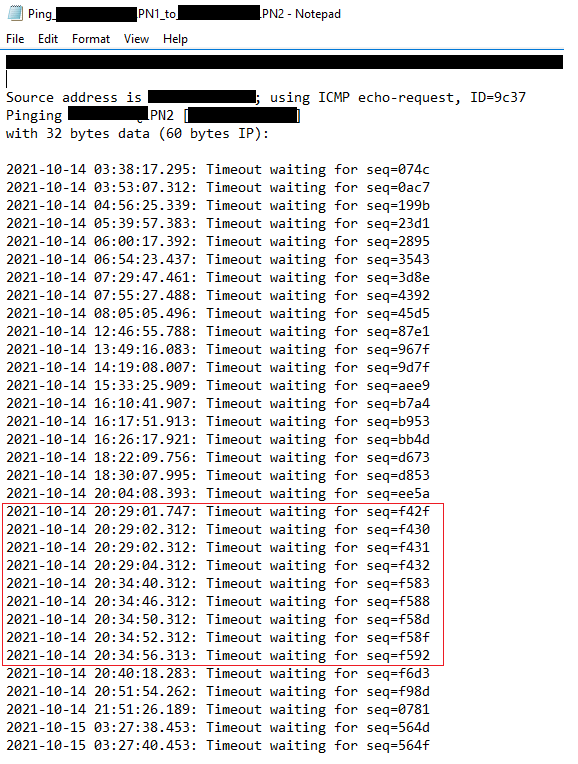
I searched for more records of "network time out" in the log files. I circled them in red in the image below. The following two figures show the records of ping time-out from PN1 to PN2:
Then I also checked the network bandwidth usage of PN1 and found the regular network bandwidth usage peak in vCenter:
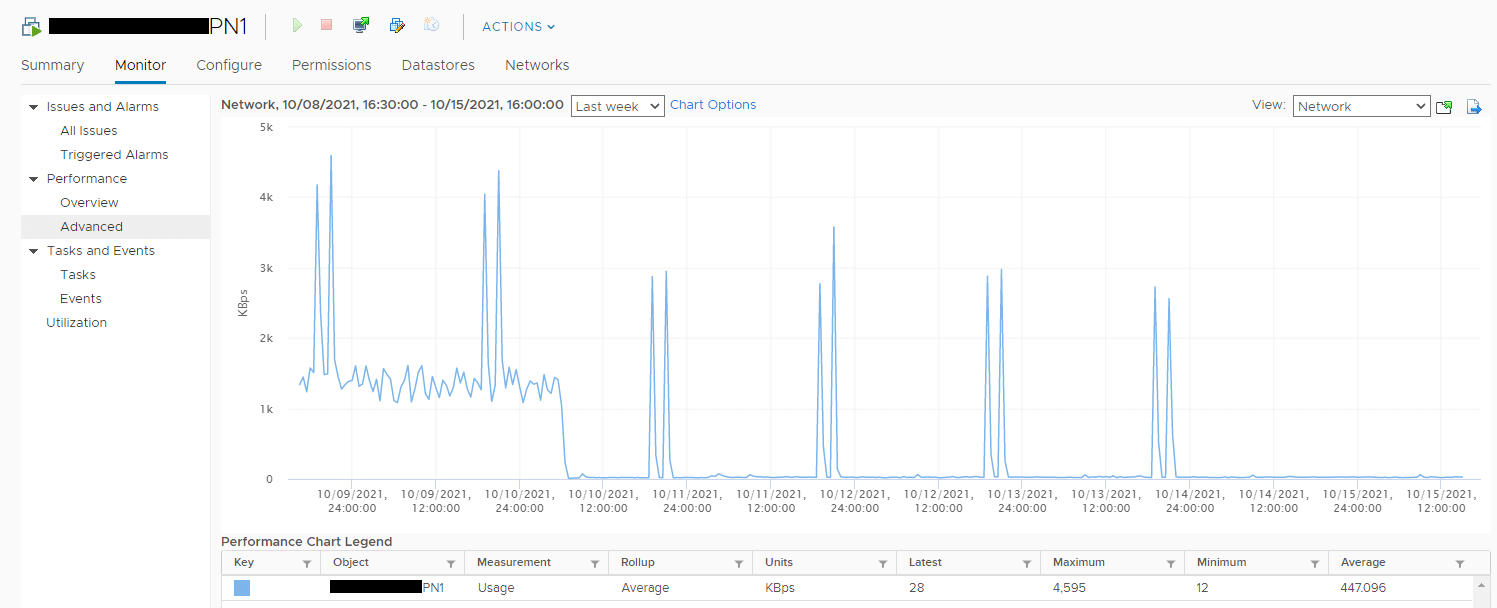
To analyze what happened during the high network bandwidth usage in the figure above, I research the activities of the SQL Servers at that time, I found the full backup job of both AOAG replicas always happened at that time every day.
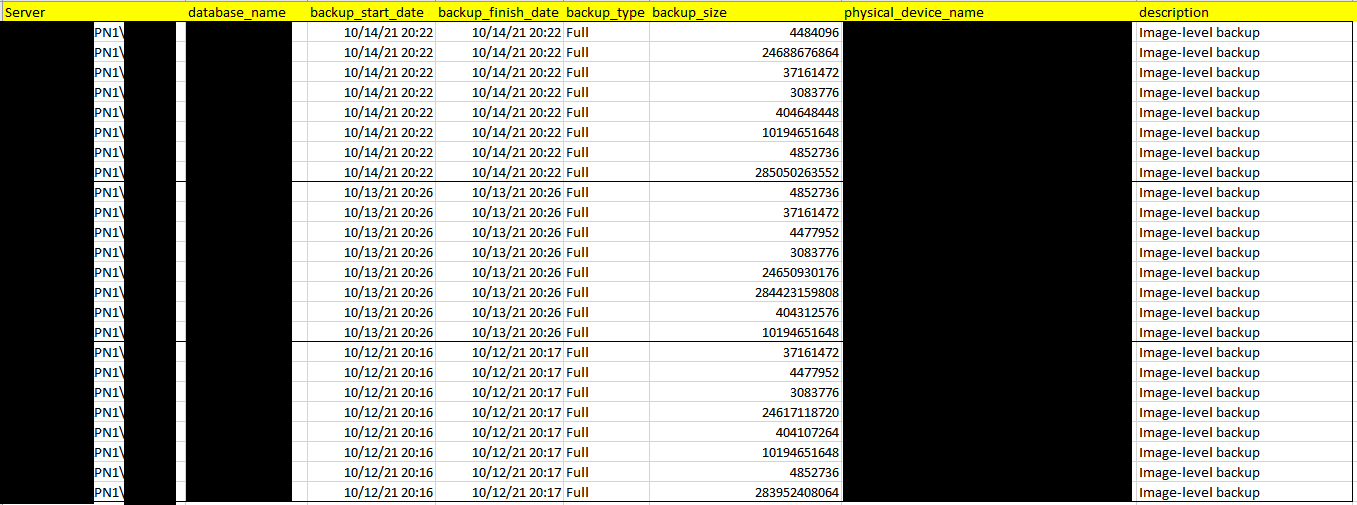
Here is the full backup history of PN1 in this image:
Here is the full backup history of PN2:
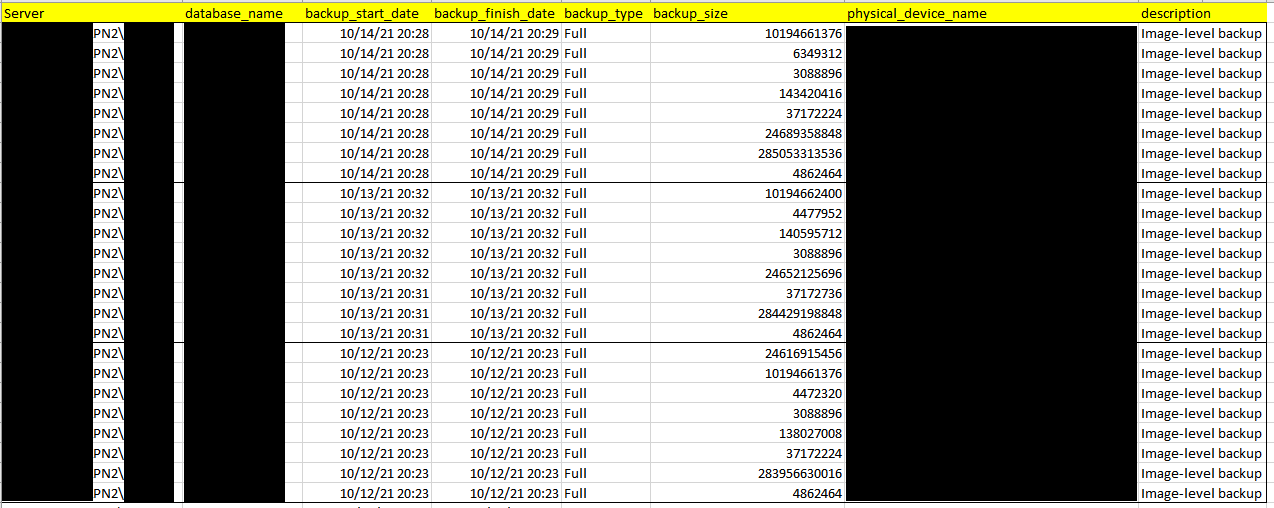
The diagnosis results of the analysis: referring to the full backup history, we can find the timestamp of the full backup job running is as same as the timestamp of the network timeout between AOAG replicas, and when full backup happened the network bandwidth usage of NIC is very high, so the full backup job caused the network jam on the NIC which caused WSFC failed then caused AOAG automatic failover.
I found hrping cannot run in the background if the user does not sign in, so I researched it, and I used the following PowerShell scripts instead of it. I set the following PowerShell scripts on PN2, and set the scheduled task to monitor the ping from PN2 to PN1 and ping from PN2 to ON1:
ping.exe -t ***PN1 |Foreach{"{0} - {1}" -f (Get-Date),$_} | select-string "timed out" >> C:\Users\Public\Ping_***PN2_to_***PN1.txt
ping.exe -t ***ON1 |Foreach{"{0} - {1}" -f (Get-Date),$_} | select-string "timed out" >> C:\Users\Public\Ping_***PN2_to_***ON1.txt
I set the following PowerShell scripts on PN1, and set the scheduled task to monitor the ping from PN1 to PN2 and ping from PN1 to ON1:
ping.exe -t ***PN2 |Foreach{"{0} - {1}" -f (Get-Date),$_} | select-string "timed out" >> C:\Users\Public\Ping_***PN1_to_***PN2.txt
ping.exe -t ***ON1 |Foreach{"{0} - {1}" -f (Get-Date),$_} | select-string "timed out" >> C:\Users\Public\Ping_***PN1_to_***ON1.txt
As you can find the output log files under the folder C:\Users\Public:

Solution
Since the full backup job of both replicas happened at the same time and our databases are very large (400GB) causing very high bandwidth usage on their NIC, then network time out between two replicas caused AOAG automatic failover, network bandwidth shouldn't be a usual problem of the backup, but we can change the backup policy to save the network bandwidth usage, so I disabled the full backup job on the primary replica in AOAG, then I monitor it in next several days and it never happens again.
