

The SQL endpoint of the Fabric Data Warehouse allows programs to read from and write to tables. The flexibility of the warehouse can lead to a big debate within your company on “How to develop with this new service?”. Older programmers might want to use SQL Server Management Studio, Azure Data Studio or Visual Studio Code while newer developers might want to use Fabric web interface. Regardless of which tool you decide to use for programming, adhering to a software development lifecycle (SDLC) is extremely important.
Business Problem
Our manager has asked us to investigate different ways to develop database schemas within Microsoft Fabric Data Warehouse. This exploration will start from the ground up with a brand-new workspace. Queries within the Warehouse can be used to store code that can be executed. However, this method is not very portable between different workspaces. I really like T-SQL notebooks since the markdown language can add documentation value to your code. Exporting and importing a notebook between environments is quite simple. However, in the world of continuous improvement and continuous deployment (CI/CD) we want to use methods such as deployment pipelines to automate code migration. In short, the two main ways to create and deploy schemas within Microsoft Fabric will be explored today.
Fabric Workspace
The Microsoft Fabric workspace is how we secure objects for a particular business solution. Security can be applied to this container. The image below shows the current workspace having a trial license. That licensing strategy will not suffice for a real-world scenario. Please note that images can be associated with a workspace. Since we are going to work with S&P stock data today, I chose a stock chart as a logo. The name of our workspace is “ws-snp500-stocks-dev”.
In a prior article, I deployed a Fabric capacity in my Azure subscription. Please see the documentation on licensing for more details. In short, I assigned the capacity named cpu4fabric to my workspace.
The image below shows the deployment of a Fabric Data Warehouse named dw_snp500_stocks. Please note that certain objects in Fabric can use underscores and others can use dashes. The service will tell you when a certain character cannot be used in a naming convention.
Right now, we have deployed an empty Data Warehouse to our development workspace. Let us create the warehouse schema by using T-SQL notebooks.
Fabric Notebooks versus Warehouse Queries
It is utterly amazing how far Microsoft Fabric has changed since it was released in November of 2023. The integration of T-SQL in notebooks was release in Q3 of 2024. Please see release notes for details. All code samples will be given in full at the end of this article. It is best practice to separate data with the use of schemas. The raw data will be copied into the warehouse and stored in the STAGE schema. The refined (aggregated) data will be stored in the STOCKS schema. The code snippet below creates two schemas. While the data warehouse does not support NVARCHAR data types within tables, the system stored procedure requires that data type.
-- stage schema
IF NOT EXISTS (SELECT * FROM sys.schemas WHERE name = 'STAGE')
EXEC sp_executesql N'CREATE SCHEMA STAGE'
-- stocks schema
IF NOT EXISTS (SELECT * FROM sys.schemas WHERE name = 'STOCKS')
EXEC sp_executesql N'CREATE SCHEMA STOCKS'
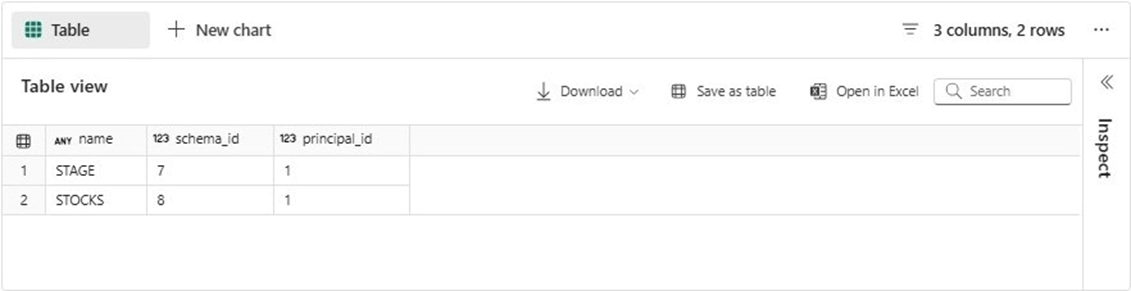
I always like to check my work. The code below is used to list the two schemas in the warehouse.
-- show user defined schemas
SELECT * FROM sys.schemas WHERE name in ('STOCKS', 'STAGE')
The image below shows the output from executing the code.
To create repeatable code, we always want to drop and create a table. This assumes that we are starting with an empty warehouse schema. Do not use this design pattern with an existing table that has a large amount of data.
-- remove staging table DROP TABLE IF EXISTS STAGE.SNP500 -- remove stocks table DROP TABLE IF EXISTS STOCKS.SNP500
The staging table contains the raw data columns. The stocks table takes averages of the data columns by month.
-- create staging table CREATE TABLE STAGE.SNP500 ( ST_SYMBOL VARCHAR(32) NOT NULL, ST_DATE DATE NOT NULL, ST_OPEN REAL NULL, ST_HIGH REAL NULL, ST_LOW REAL NULL, ST_CLOSE REAL NULL, ST_ADJ_CLOSE REAL NULL, ST_VOLUME BIGINT NULL ); -- create stocks table CREATE TABLE STOCKS.SNP500 ( ST_SYMBOL VARCHAR(32) NOT NULL, ST_DATE DATE NOT NULL, ST_AVG_OPEN REAL NULL, ST_AVG_HIGH REAL NULL, ST_AVG_LOW REAL NULL, ST_AVG_CLOSE REAL NULL, ST_AVG_ADJ_CLOSE REAL NULL, ST_AVG_VOLUME BIGINT NULL );
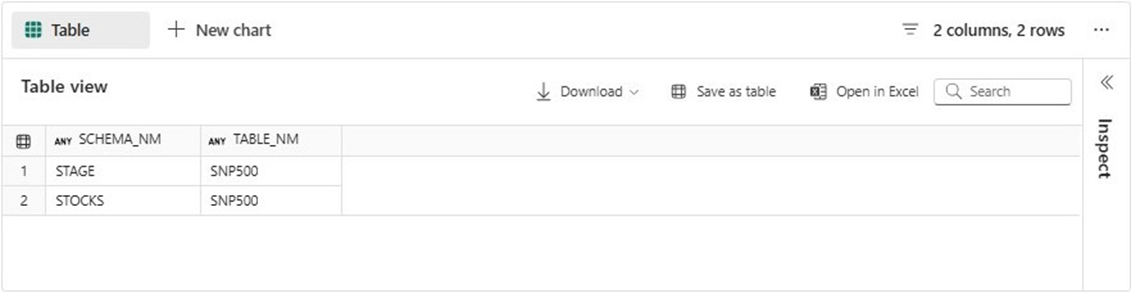
Let us make sure the two new tables exist in our database. The code uses the sys.tables and sys.schemas catalog views to return the fully qualified table name.
-- show user defined tables
SELECT
s.name AS SCHEMA_NM,
t.name as TABLE_NM
FROM
sys.tables AS t
JOIN
sys.schemas AS s
ON
t.schema_id = s.schema_id
The image below show both the raw and refined tables.
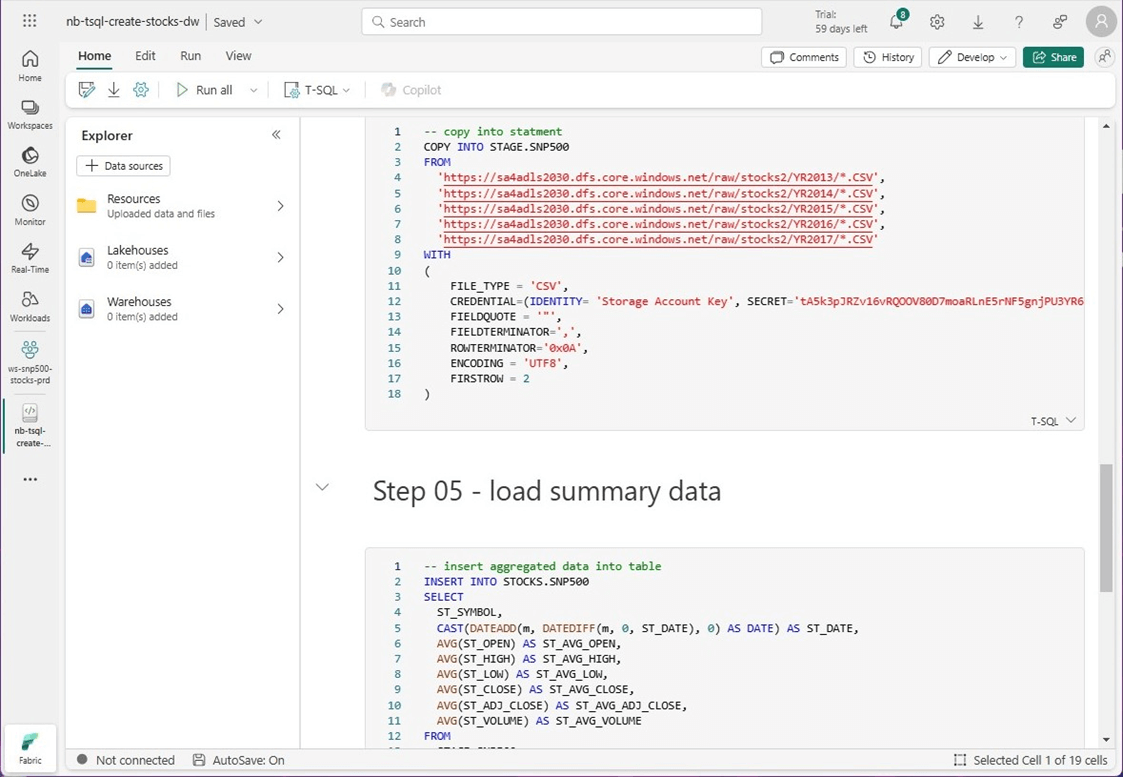
The COPY INTO statement can quickly process hundreds of files and load the data into the staging table. The code below uses a storage account key as the credential to access the storage account, storage container, and stored files in CSV format. The successful execution of this statement loads data into our table in the stage schema.
-- load data from ADLS storage
COPY INTO STAGE.SNP500
FROM
'https://sa4adls2030.dfs.core.windows.net/raw/stocks2/YR2013/*.CSV',
'https://sa4adls2030.dfs.core.windows.net/raw/stocks2/YR2014/*.CSV',
'https://sa4adls2030.dfs.core.windows.net/raw/stocks2/YR2015/*.CSV',
'https://sa4adls2030.dfs.core.windows.net/raw/stocks2/YR2016/*.CSV',
'https://sa4adls2030.dfs.core.windows.net/raw/stocks2/YR2017/*.CSV'
WITH
(
FILE_TYPE = 'CSV',
CREDENTIAL=(IDENTITY= 'Storage Account Key', SECRET='<your key here>'),
FIELDQUOTE = '"',
FIELDTERMINATOR=',',
ROWTERMINATOR='0x0A',
ENCODING = 'UTF8',
FIRSTROW = 2
)
The table in the stock schema will contain aggregated data. We can use the INSERT INTO statement with the correct SELECT statement to populate this table. See the code below for details.
-- insert aggregated data into table INSERT INTO STOCKS.SNP500 SELECT ST_SYMBOL, CAST(DATEADD(m, DATEDIFF(m, 0, ST_DATE), 0) AS DATE) AS ST_DATE, AVG(ST_OPEN) AS ST_AVG_OPEN, AVG(ST_HIGH) AS ST_AVG_HIGH, AVG(ST_LOW) AS ST_AVG_LOW, AVG(ST_CLOSE) AS ST_AVG_CLOSE, AVG(ST_ADJ_CLOSE) AS ST_AVG_ADJ_CLOSE, AVG(ST_VOLUME) AS ST_AVG_VOLUME FROM STAGE.SNP500 GROUP BY ST_SYMBOL, CAST(DATEADD(m, DATEDIFF(m, 0, ST_DATE), 0) AS DATE)
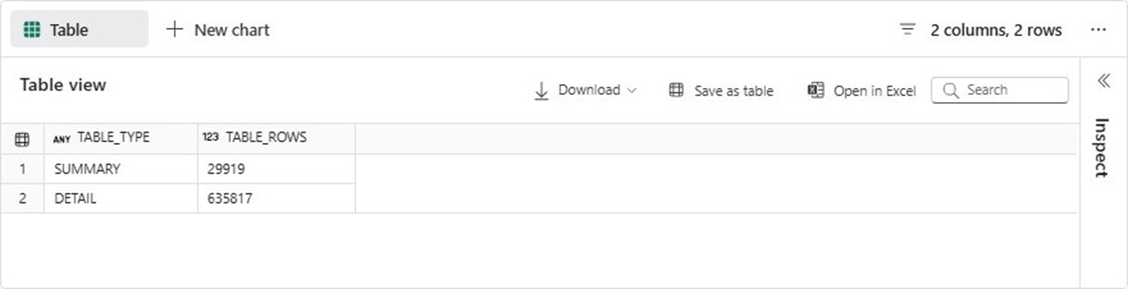
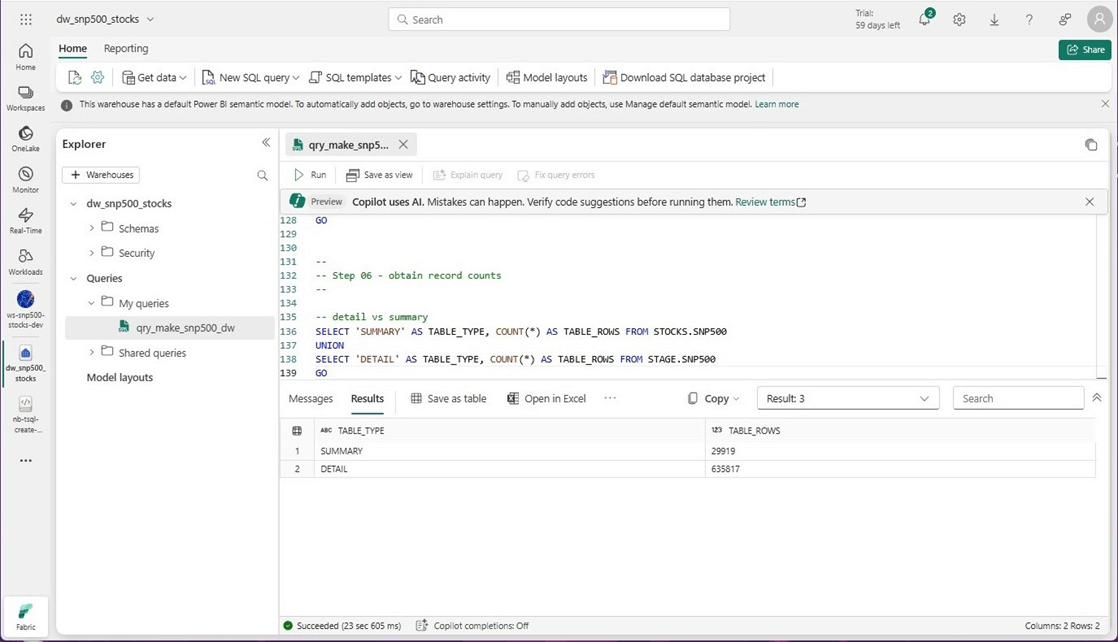
Testing is especially important in any type of coding. How can we tell if the tables have data? We can union the record counts from both tables into one result set.
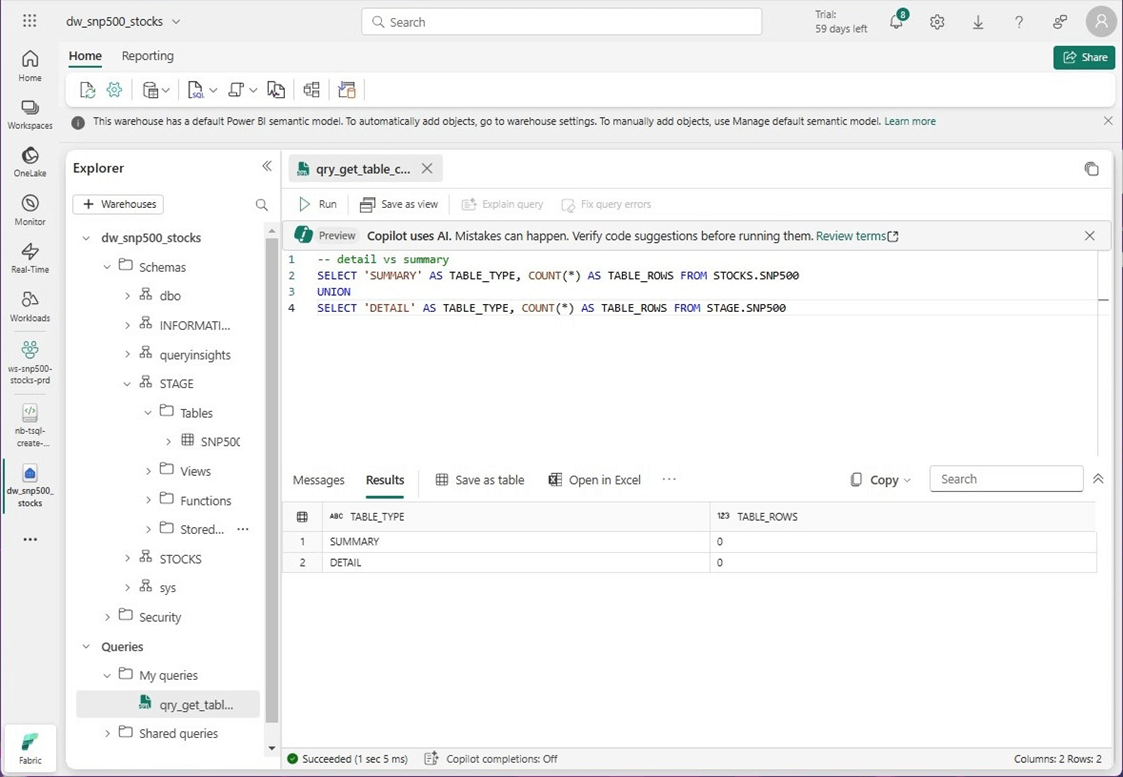
-- detail vs summary SELECT 'SUMMARY' AS TABLE_TYPE, COUNT(*) AS TABLE_ROWS FROM STOCKS.SNP500 UNION SELECT 'DETAIL' AS TABLE_TYPE, COUNT(*) AS TABLE_ROWS FROM STAGE.SNP500
The image below shows the detail (raw) table containing around 636 K records and the summary (refined) table contains around 30 K records.
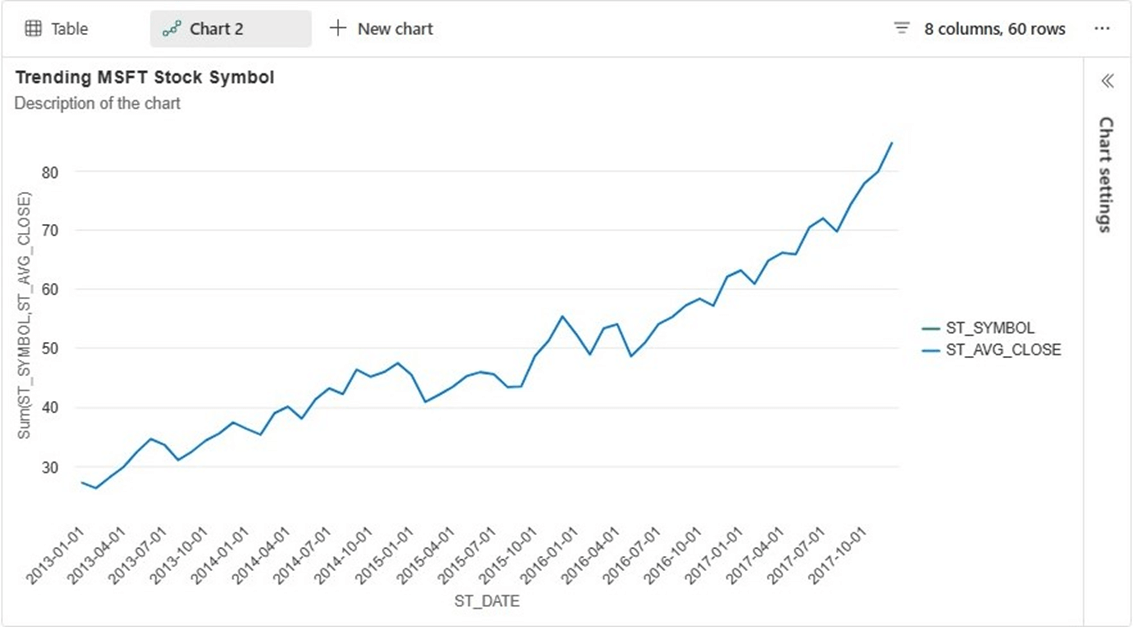
What I really like about Fabric notebooks is the ability to chart the data. This allows for trending of the aggregated stock data. Let us see how Microsoft stock has done over the past five years. Execute the code below and choose the output to be a line chart.
-- chart Microsoft stock SELECT * FROM STOCKS.SNP500 WHERE ST_SYMBOL = 'MSFT' ORDER BY ST_DATE DESC
The chart below shows that Microsoft stock started around twenty-five dollars in 2013 and has increased in value to 85 dollars in 2017.
What I did not show today is the mark down language supported by notebooks. This allows the developer to place comments between cells of code. Also, the exporting of notebook as code allows the developer to open the notebook (file) with other tools. For instance, I was cutting and pasting code snippets from VS code into this article.
Source Control
For a company to practice agile development we need two processes: source code control and deployment pipelines. The image below shows the objects that we currently have in our environment.
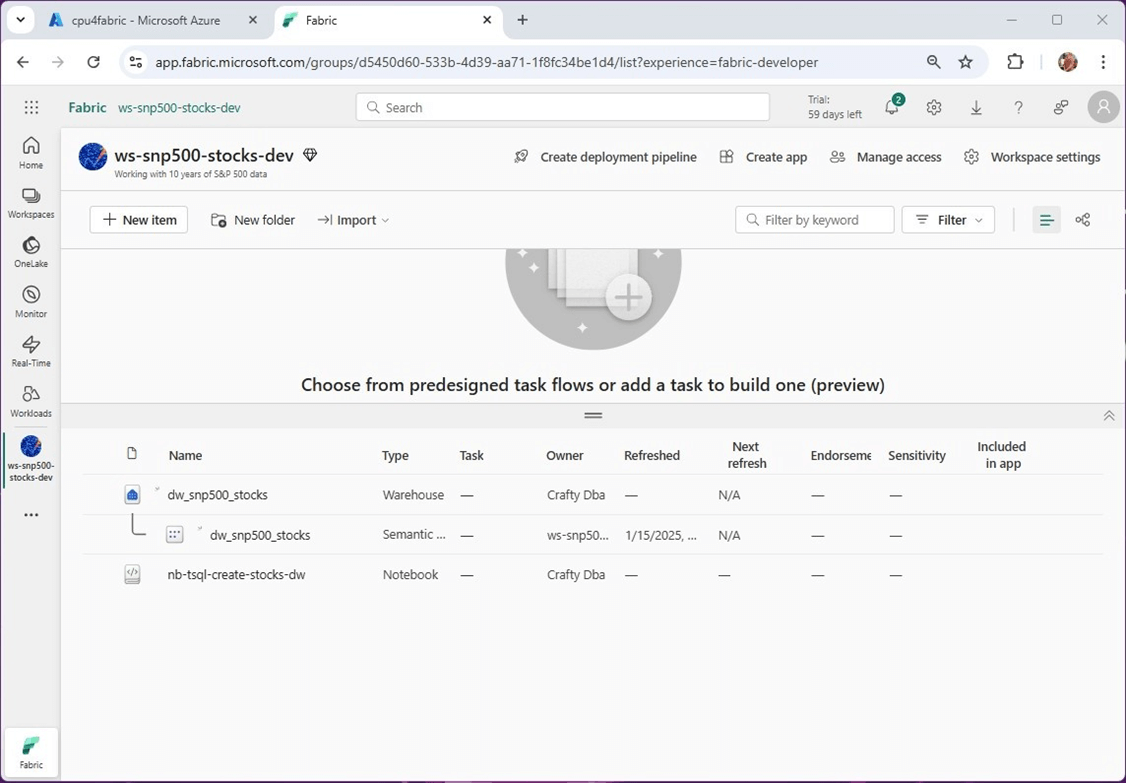
The Fabric workspace objects can be checked in using a Git provider. Both Azure DevOps and GitHub are supported by Fabric.
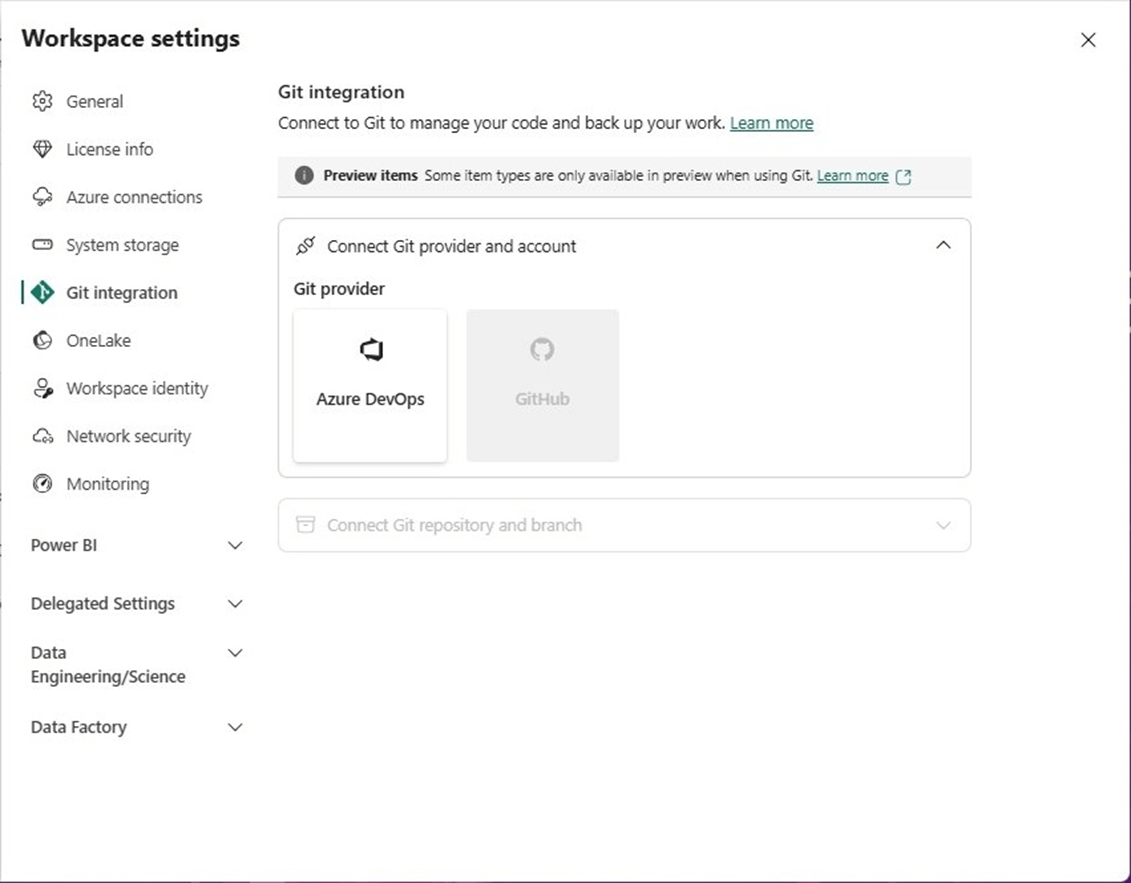
I am going to use Azure DevOps repositories today. The first step is to create a new project in the service. Please see documentation and the images for details.
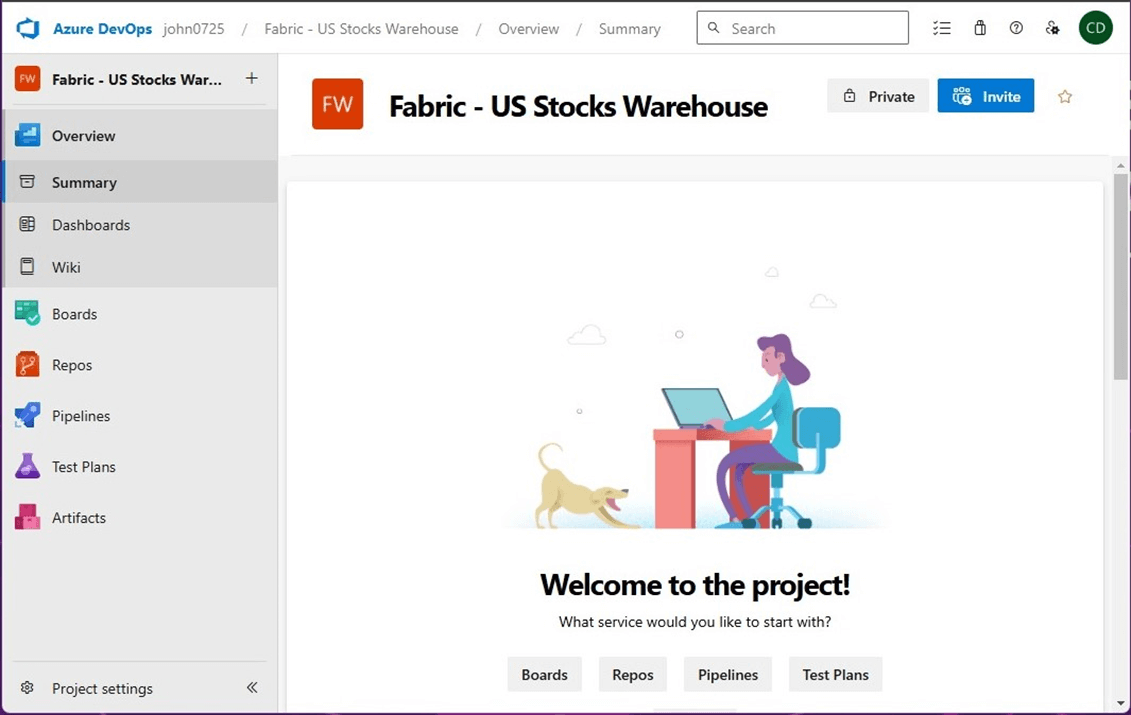
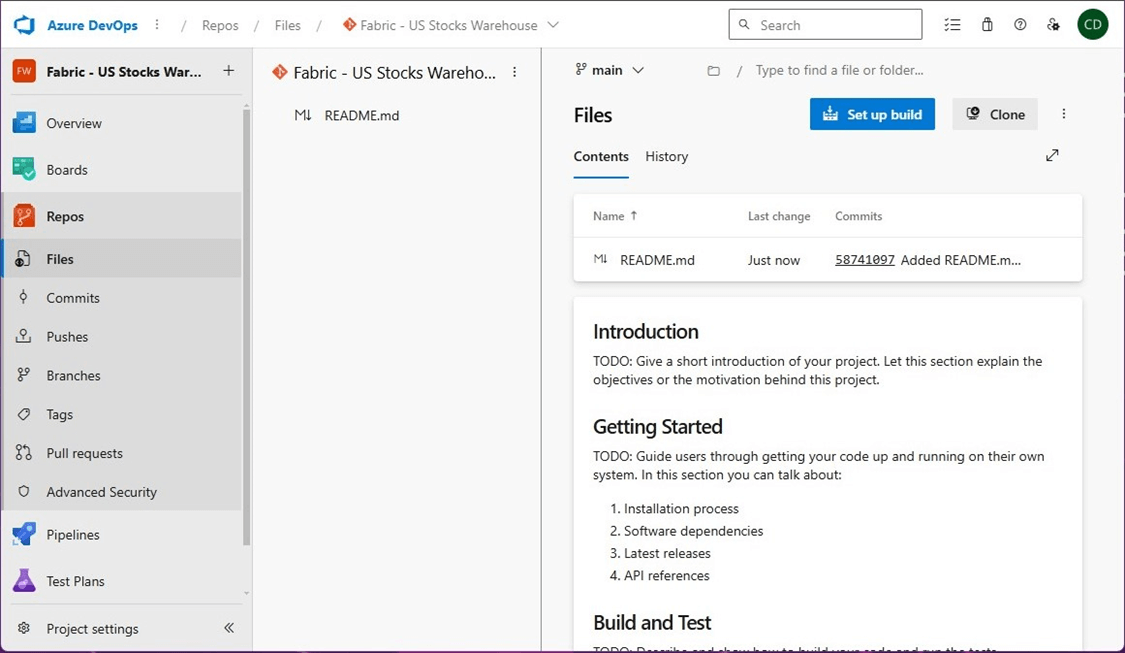
The files section under the repo’s menu allows us to view what code has been checked in. So far, the repository is empty. See image below that reflects a brand-new repository.
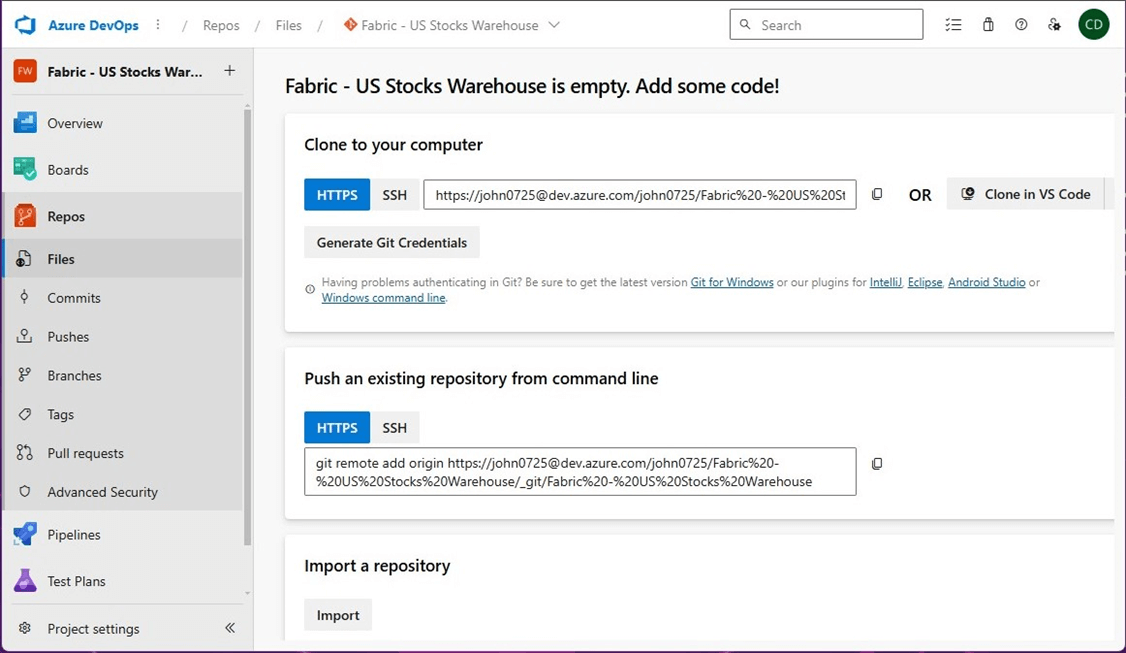
To connect the Fabric workspace to the Azure DevOps repository we must find the organization name, project name, Git repository and existing branch.
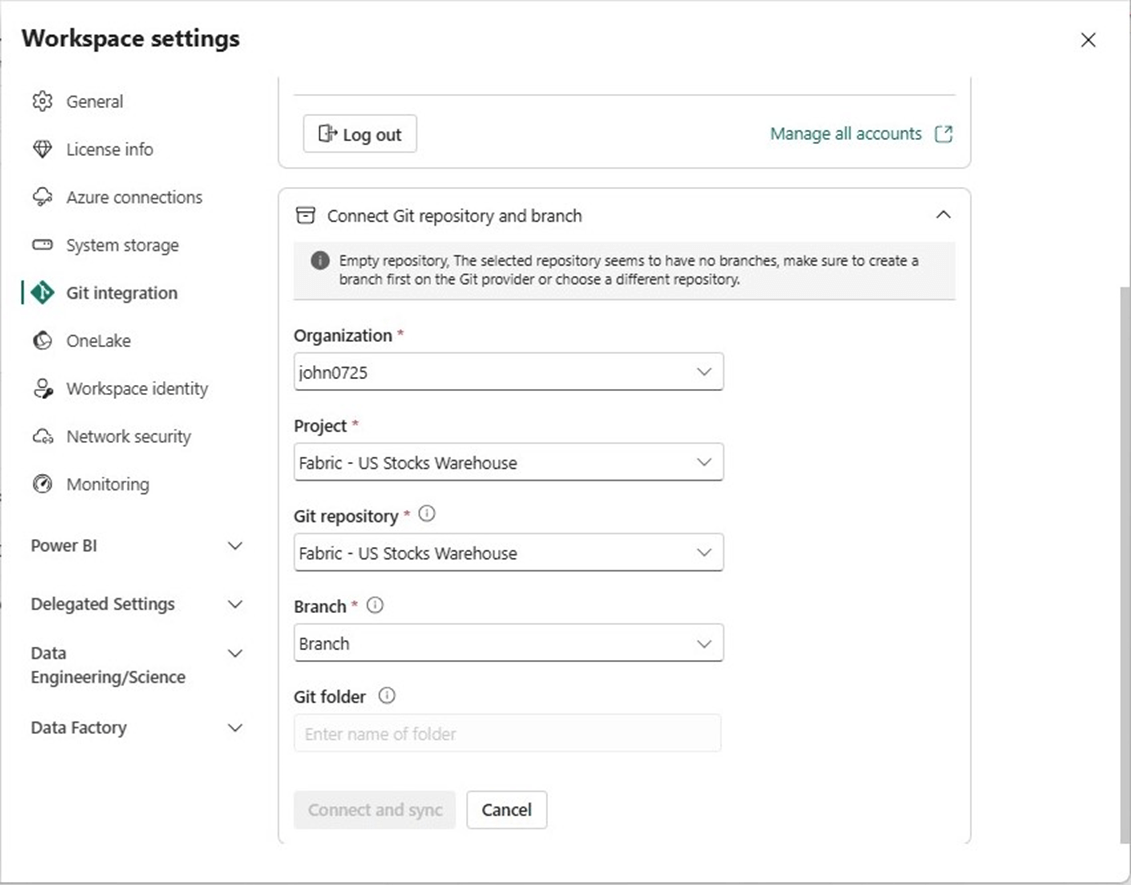
Unfortunately, we cannot complete the process since there are no branches. To complete the process, go back the files/repos and create a main branch containing a readme.md file.

If we refresh the screen to look at files in the main branch, we can see our new file.
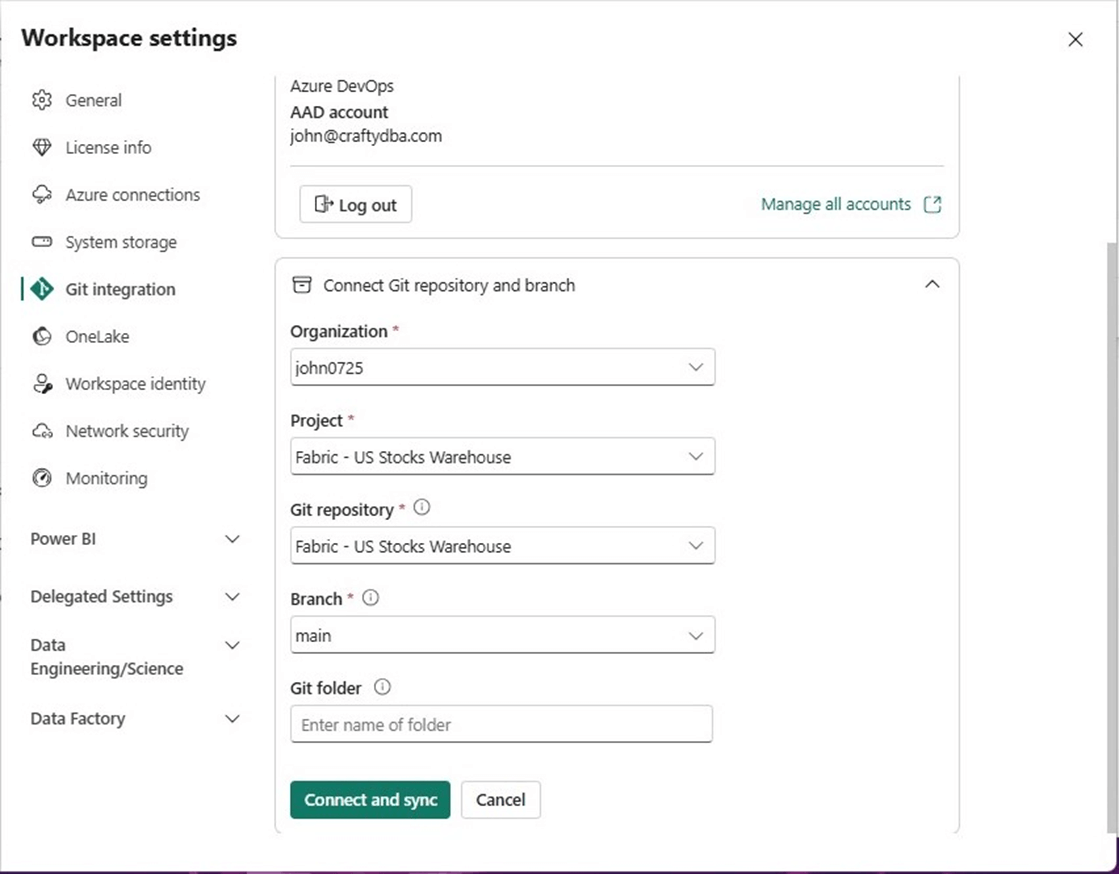
Now that we have a branch, we can go back to the workspace settings and complete the process. Please see various images for details.
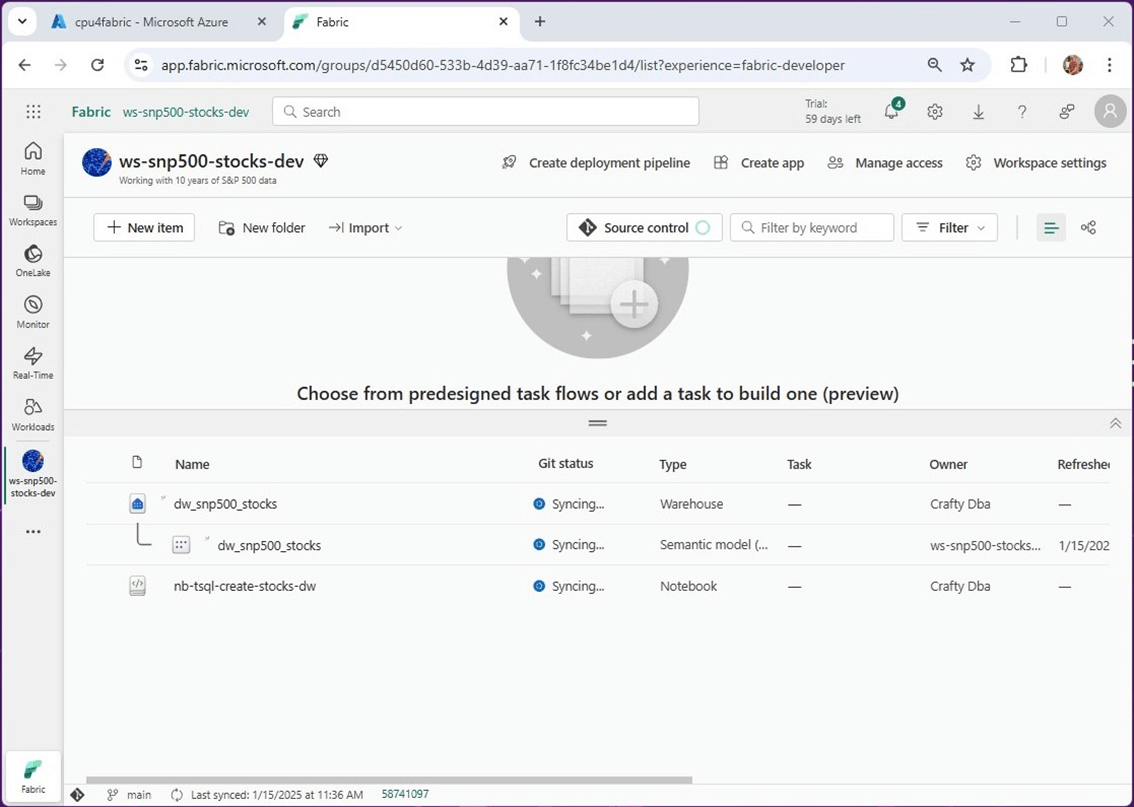
Behind the scenes, Microsoft Fabric is checking in the objects that are part of the workspace. It even has a nice Git status message stating that the code is synchronizing.
I am curious of what objects (code) was checked in. The image below shows the data warehouse code. It looks like fabric has converted the schema into a SQL project. Please see the screen shot below for details.
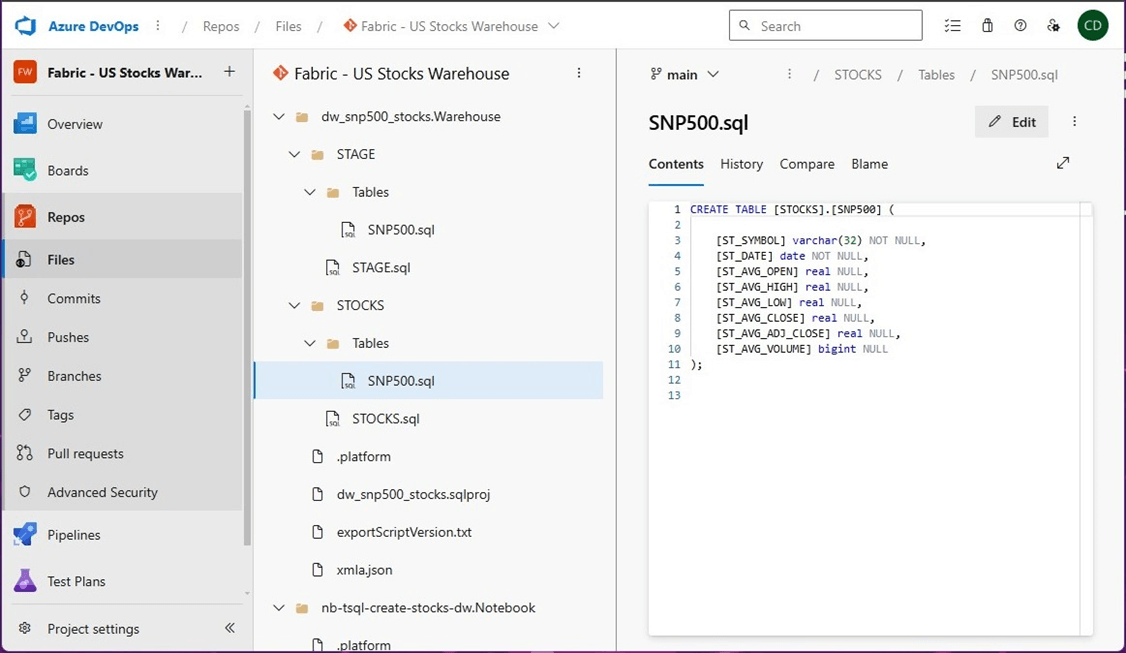
T-SQL notebooks are based upon Jupyter notebooks which is open source. If we open the file will a text editor, we will see the following contents in a JSON document. This document is being displayed as text in the content viewer seen below.
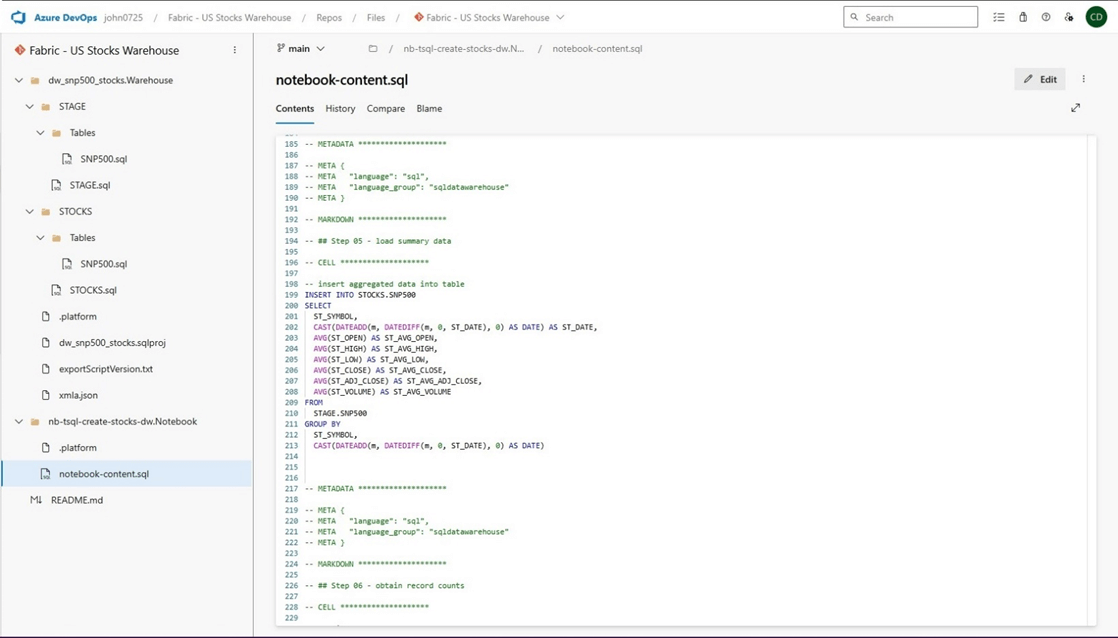
Is there anything that is missing? Yes, the Fabric Warehouse queries have not been checked into source control. To recap, certain objects from the Fabric Workspace can be checked into source control. In the next section we will cover deployment pipelines.
Deployment Pipelines
Deployment pipelines depend upon workspaces being assigned to various levels of the software development lifecycle. Many times, companies will provision development, testing, and production environments. Since the purpose of this article is to demonstrate how to use the pipelines, I decided to have only two environments. The image below shows the dev and prd workspaces.
Please refer to the documentation for more details. Please note, this feature is in preview right now. The image below shows the pipeline with the default testing stage removed. Additionally, the workspaces have been assigned to the correct environments. The three objects in the development environment are show below.
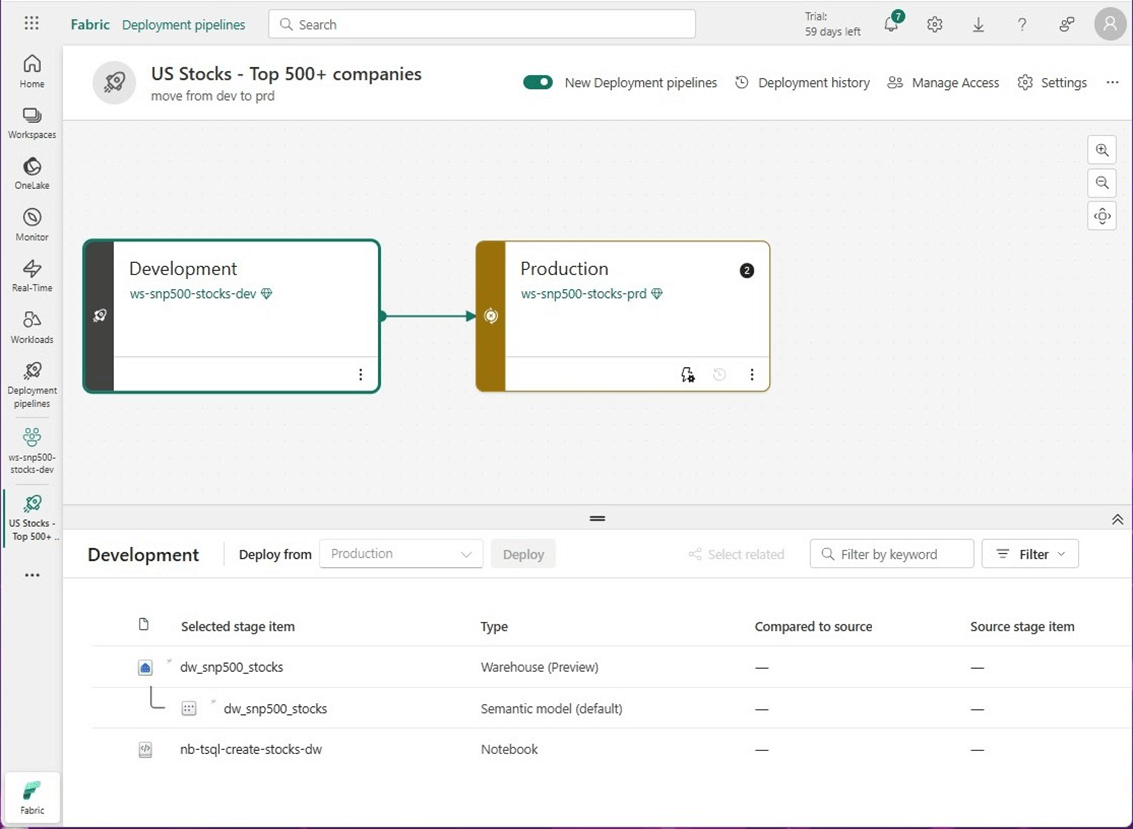
If we click on the production environment, we can see the warehouse and notebook objects in the development environment are missing.
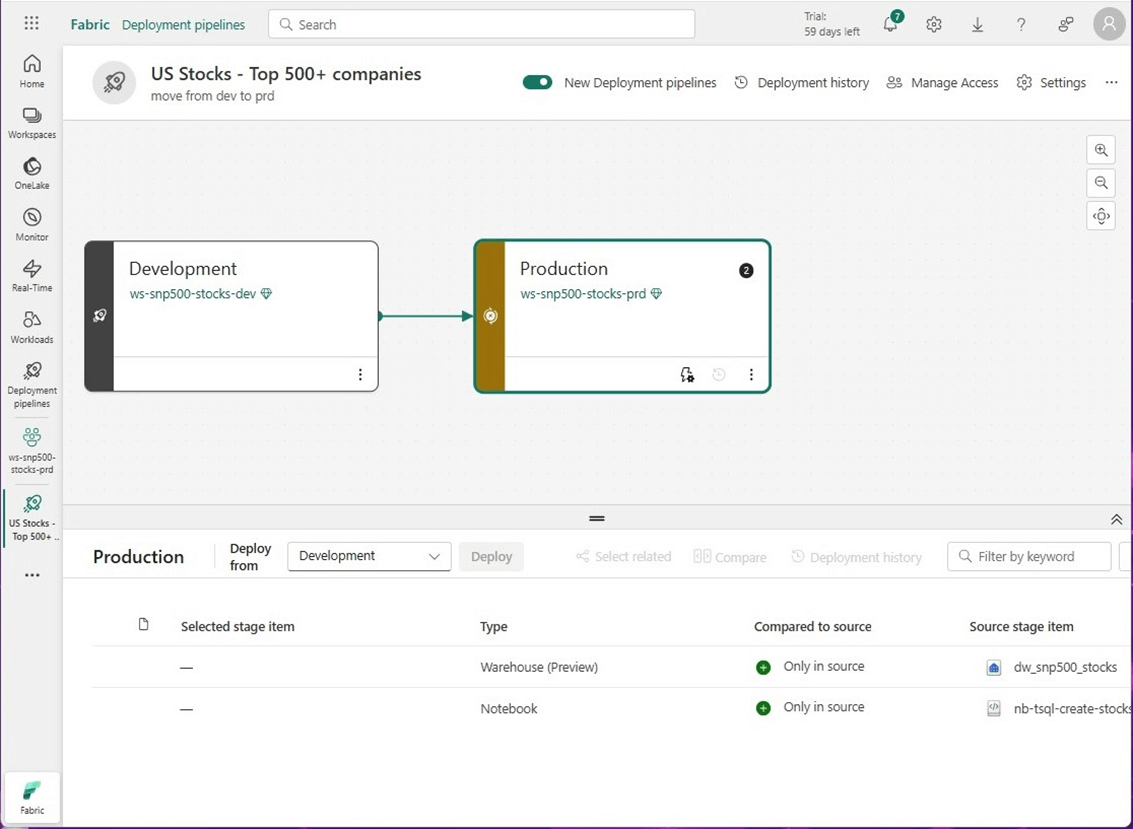
To deploy code from development, click the check marks for the objects you want to deploy. The deploy button shows two objects as being selected.
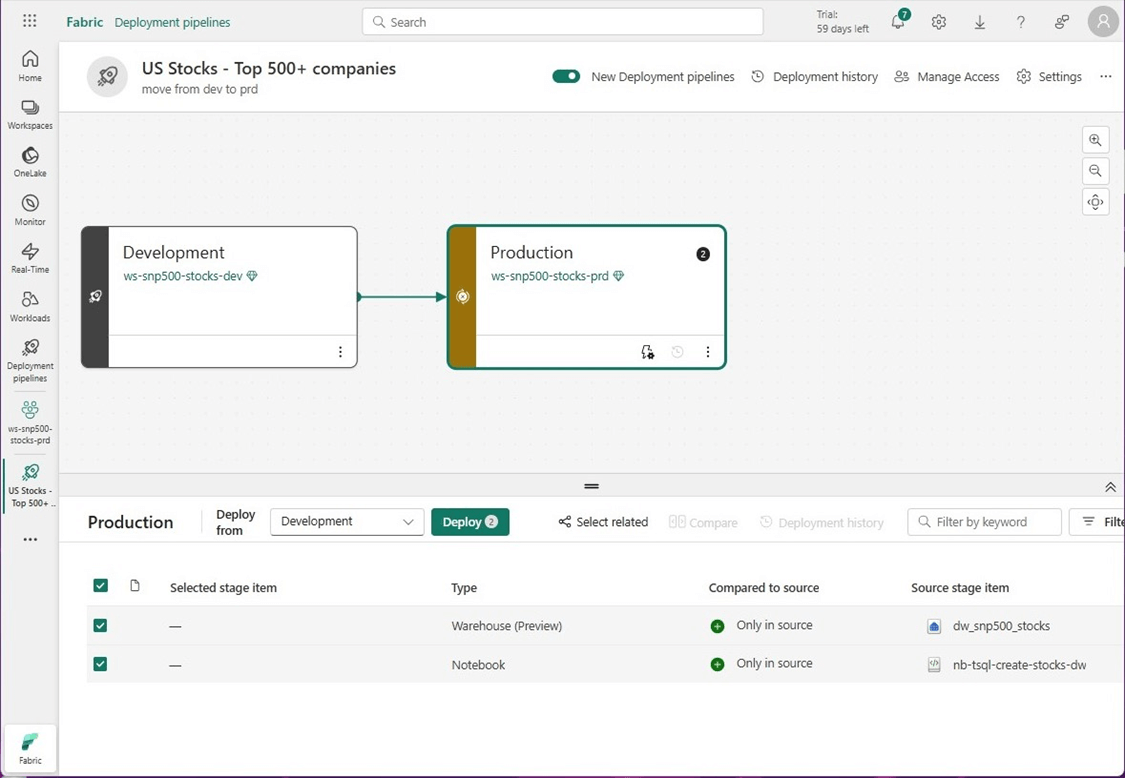
Please click the deployment button to have the content copied from one workspace to another.
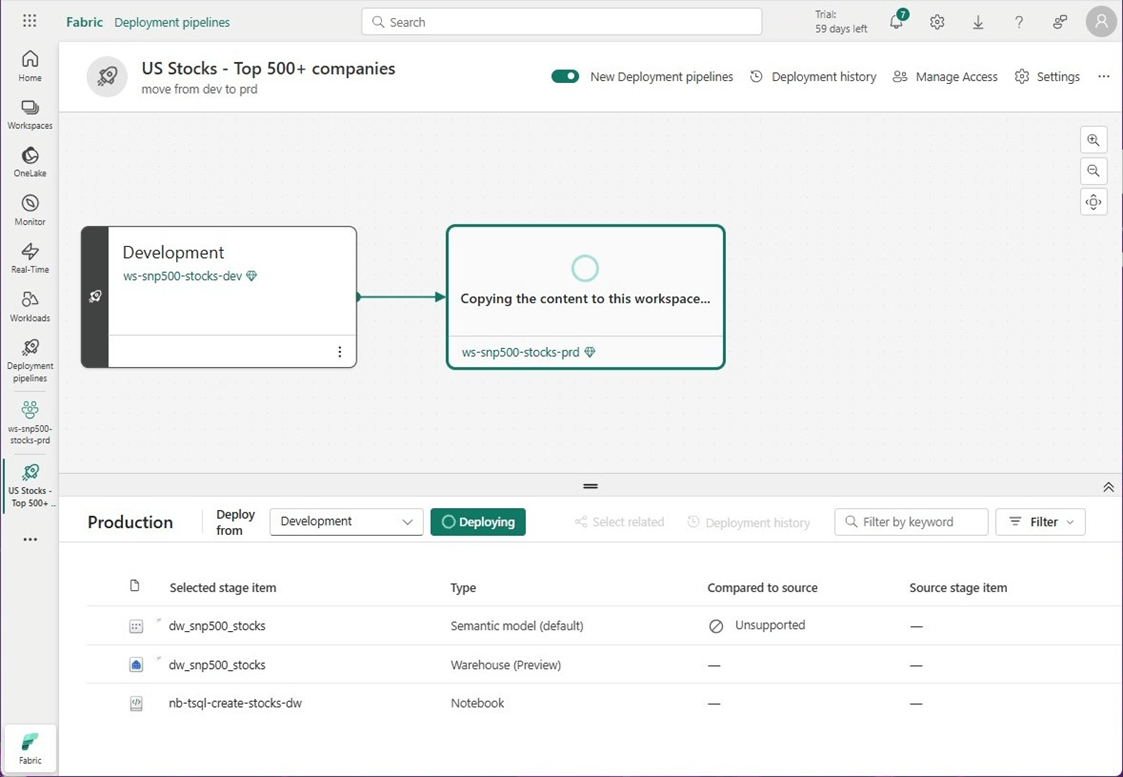
Let us see if anything is missing. First, if we look at the T-SQL notebook we notice that the warehouse is not attached. That makes sense since the name of the warehouse might be different between environments. However, that is not the root cause of the problem.
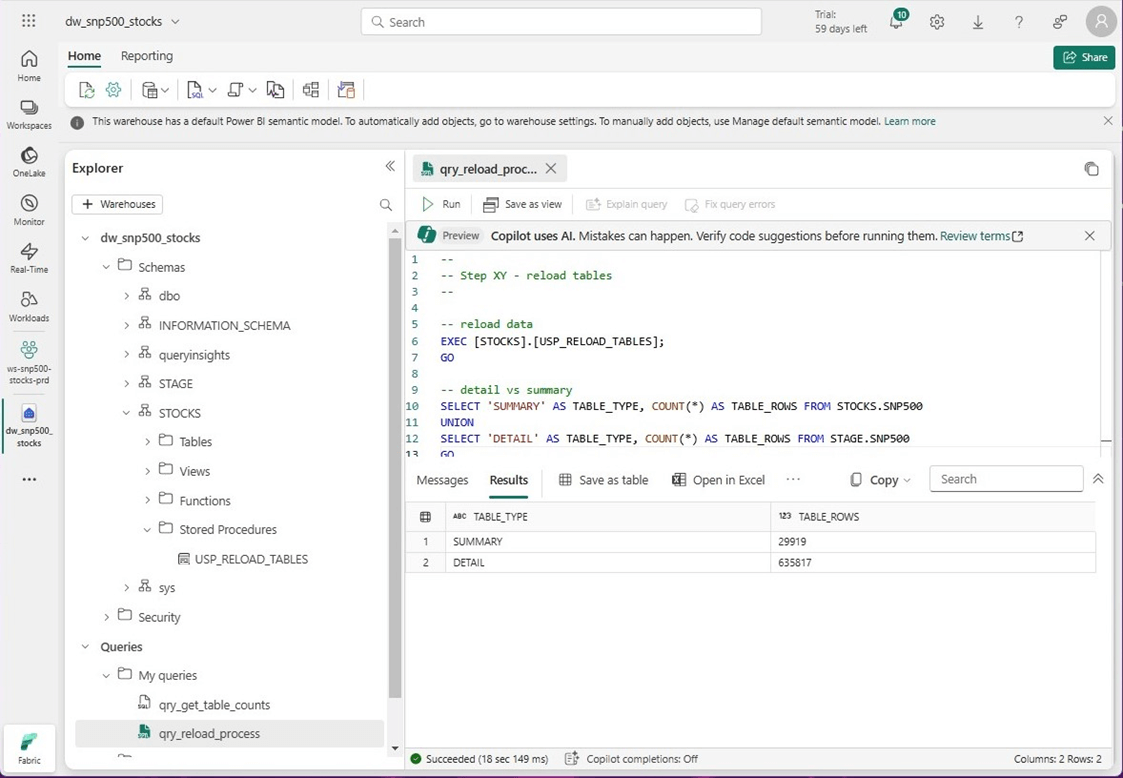
If we look at the tables in the two schemas, they are empty. Remember, deployment pipelines just moves code between environments not data. To fix this issue, we can package the code for copying data into the raw table and summarize the data into the refined table by creating a stored procedure named “USP_RELOAD_TABLES.”
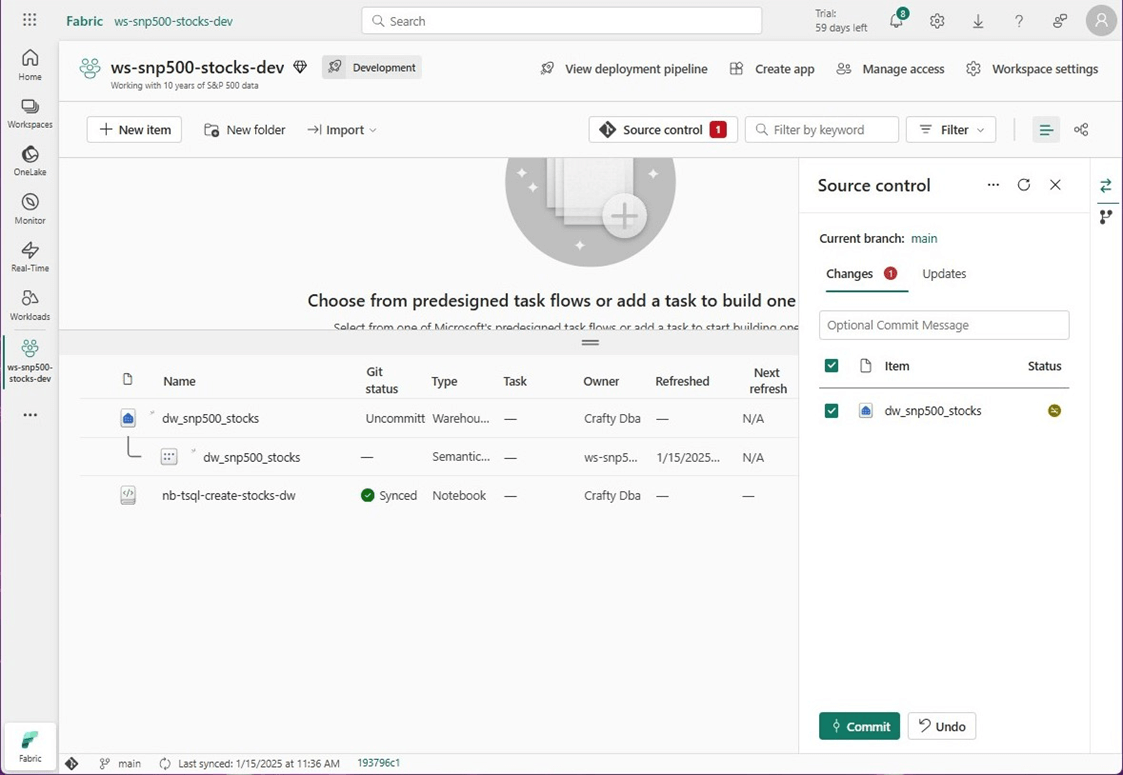
This new stored procedure is reflected in the workspace as uncommitted code. We need to commit the code into the Git repository before we can redeploy it to the production workspace.
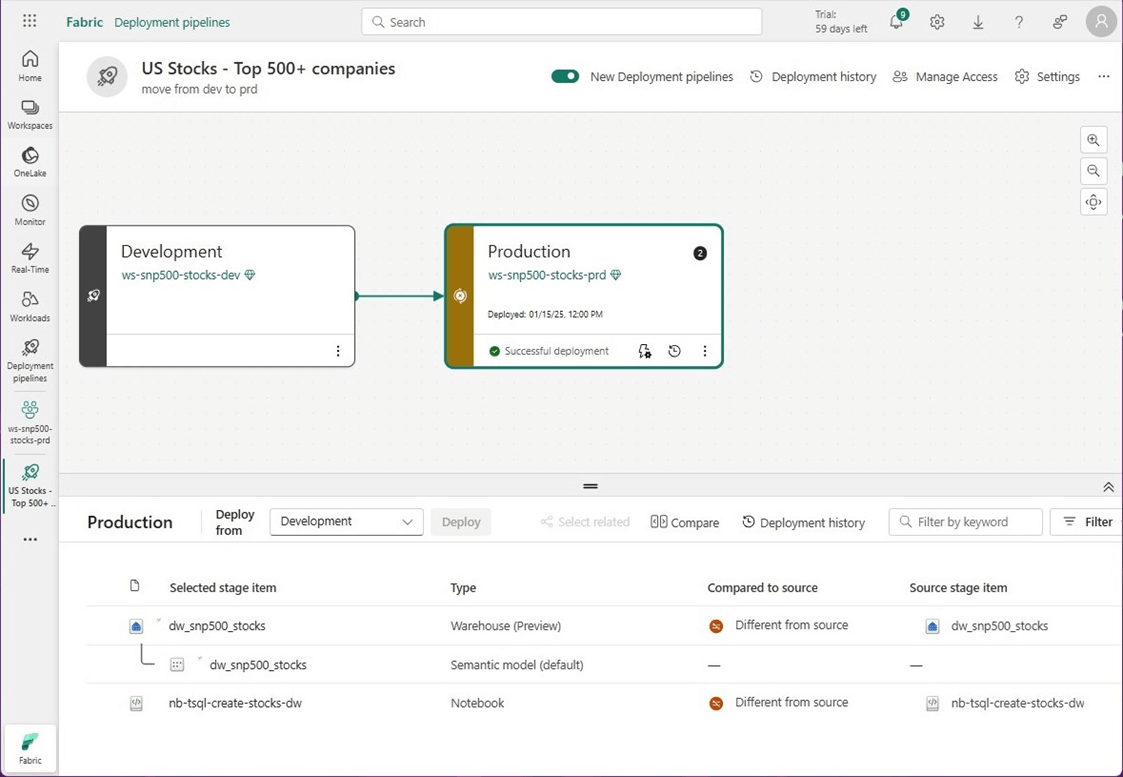
The deployment pipeline recognizes the differences between development and production workspaces. Please select and deploy the changes now.
Once the code has been redeployed to production, we can run the stored procedure to reload the tables. The image below shows the correct record counts in the stage (raw) and stocks (refined) tables.
I was pleasantly surprised with the advancement of deployment pipelines for both the warehouse objects and T-SQL notebooks. How can we make this better?
Future Enhancements
I always check the documentation for any feature that can fix a problem that I have. There is a concept called deployment rules that allows the developer to change the lakehouse for a given Spark Notebook. This feature is missing from the new T-SQL notebooks. The lightning bolt under the deployment stage is where you can create rules.
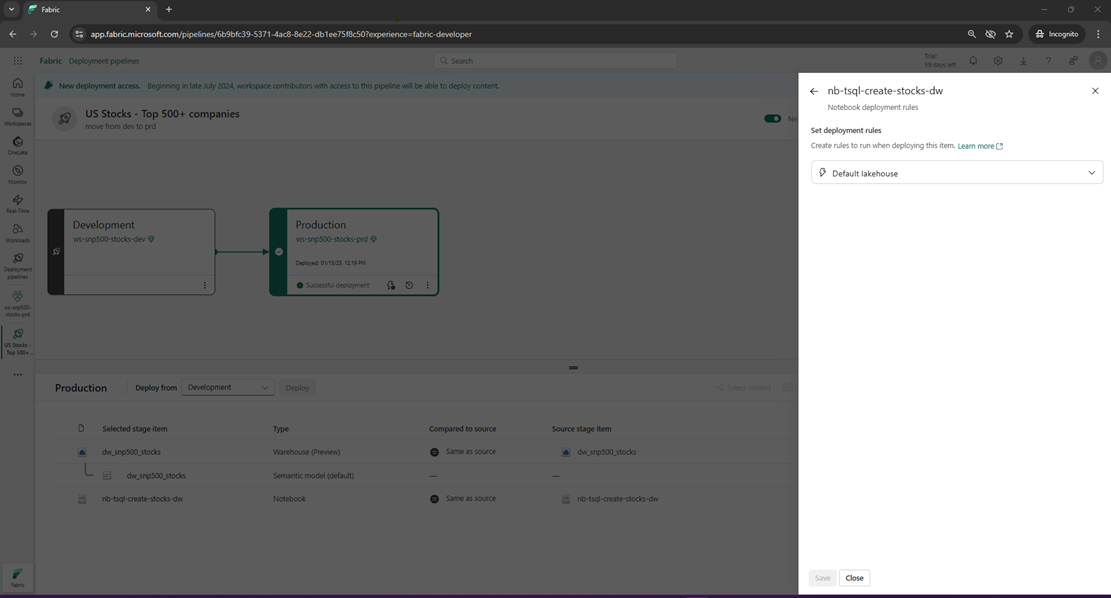
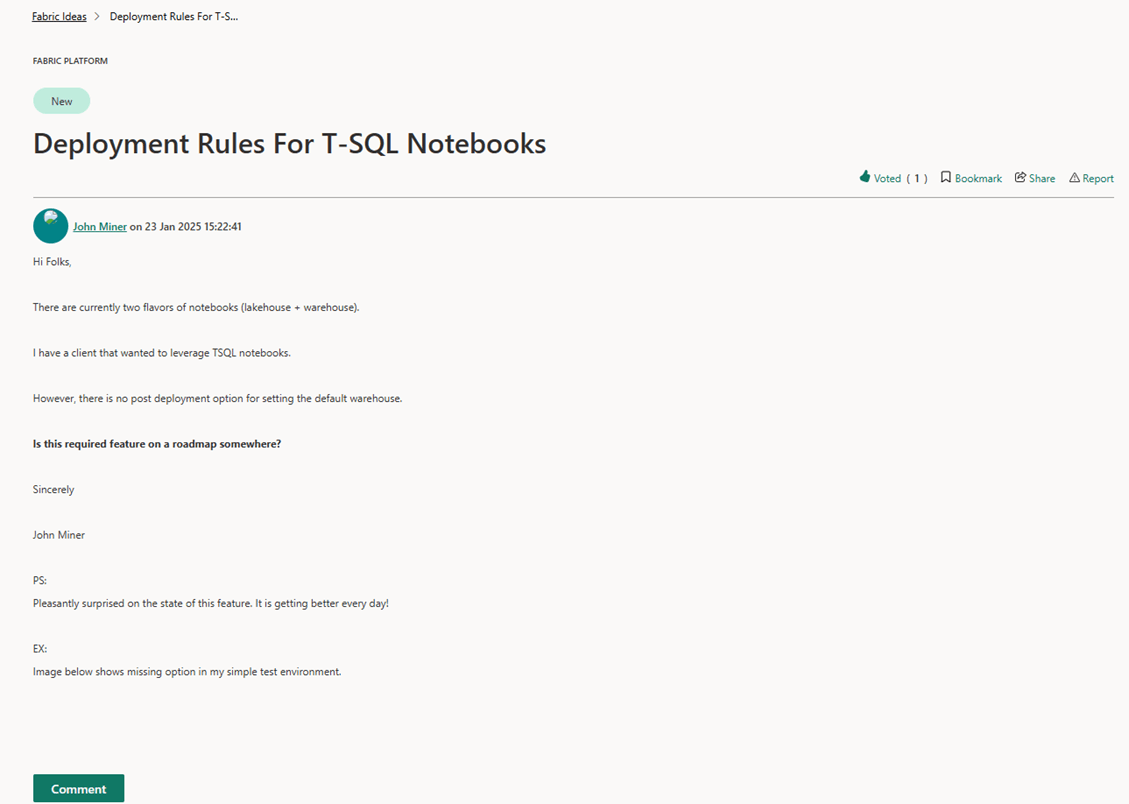
Please remember that the development team at Microsoft has been working hard at making changes to Fabric to fit business needs over the past 18 months. To help Microsoft prioritize their efforts, I added a fabric idea. Please vote yes on this idea. Otherwise, you will have to attach the T-SQL notebooks to the correct warehouse after every deployment.
Summary
There are many ways to develop SQL database schemas in Microsoft’s Fabric Warehouse. Warehouse queries can be analogous to any third-party tool that can change the records in the table via the read/write SQL endpoint. For example, we could have used VS Code to create the objects within the warehouse. Fabric notebooks now support T-SQL development which is exciting. Regardless of technique, we want to check in our code into a software repository and use pipelines to deploy code between workspaces.
Just remember, code does not equal data. Thus, the data might be and/or should be different between workspaces. If our company is storing sensitive data such as social security numbers, we want the data to be masked in the lower environments. Additionally, do we want to use some type of key value lookup to obfuscate social security numbers when copying data from higher to lower environments?
Finally, I want to point out the fact that this is a data warehouse. Single data manipulation language (DML) statements such as inserts, updates, and deletes do not scale well. Set oriented changes of substantial amounts of data will work fine. Please vote up the fabric suggestion that I have made so that deployment rules will be available for T-SQL notebooks. In closing, here is the code I used in this article bundled up into a zip file.