

This article will seek to detail how to go about creating a corrupted database which you can readily attach to your SQL Server instance. It's quite possible that at some point you would want to have a corrupted SQL Server database to use for checking your maintenance scripts or sanitising and practising your disaster recovery techniques (we all perform DR tests at regular points, right!).
Now, you could trawl the internet looking for them or you could try to create them yourself but how exactly do you corrupt a database intentionally and still get to be able to bring it back online afterwards! 😉
For this we need to dig in a little into the SQL Server database file structure. The tools to use here are pretty simple, to create the corrupted database you will need an instance of SQL Server and a Hex editor. I use the popular XVI32, it's free of charge and requires no installation, unlike some other editors that are available.
We're going to use a simple script and go through it in stages, with diagrams, to see what's happening. Let's start with actually creating the database, this is done with the following T-SQL code
Don't forget to modify any drive letters and paths before executing the script 😉
USE [master]
GO
CREATE DATABASE [Corrupt2K8] ON PRIMARY
( NAME = N'Corrupt2K8', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\DATA\Corrupt2K8.mdf' ,
SIZE = 524288KB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB )
LOG ON
( NAME = N'Corrupt2K8_log', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\DATA\Corrupt2K8_log.ldf' ,
SIZE = 262144KB , MAXSIZE = 2048GB , FILEGROWTH = 1024KB)
GO
USE [Corrupt2K8]
IF OBJECT_ID('dbo.NoddyTable', 'U') IS NOT NULL
BEGIN
DROP TABLE dbo.NoddyTable
END
CREATE TABLE dbo.NoddyTable(
NoddyID UNIQUEIDENTIFIER NOT NULL DEFAULT NEWID()
, NoddyName VARCHAR(128) NULL
, NoddyInt BIGINT NULL
, NoddyDate DATETIME NULL
)
INSERT INTO dbo.NoddyTable
SELECT NEWID(), name, ROUND(RAND(object_id)*856542, 0), GETDATE() FROM sys.columns
UNION ALL
SELECT NEWID(), name, ROUND(RAND(object_id)* 1048576, 0), GETDATE() FROM sys.columns
ALTER TABLE dbo.NoddyTable ADD CONSTRAINT PK_NoddyID
PRIMARY KEY CLUSTERED (NoddyID)
WITH (IGNORE_DUP_KEY = OFF)
CREATE NONCLUSTERED INDEX IDX_NoddyName_NoddyDate
ON dbo.NoddyTable(NoddyName, NoddyDate)
WHERE NoddyName IN ('password','length','created','crtype','offset','intprop')
CREATE NONCLUSTERED INDEX IDX_NoddyDate
ON dbo.NoddyTable(NoddyDate)Once you have the database created, take a full backup followed by a differential and then a transaction log backup, you can then use these in future testing scenarios.
We now want to choose an object as the source of our corruption. I am going to choose a non clustered index on the table 'dbo.NoddyTable', to get a list of indexes on this table use the following query;
SELECT OBJECT_NAME(object_id), name, index_id, type_desc FROM sys.indexes ORDER BY 1
I will be using the non-clustered index 'IDX_NoddyDate', this has an index id of 3. To find details of the page numbers in use by this index we now need to turn to an undocumented DBCC command 'DBCC IND'. Full details of how to use this command may be found at the links below but basically this is used as follows:
DBCC IND (DatabaseName, 'tablename', index_id)
So, I have
DBCC IND (Corrupt2K8, 'dbo.NoddyTable', 3)
Below is the output from the command above:
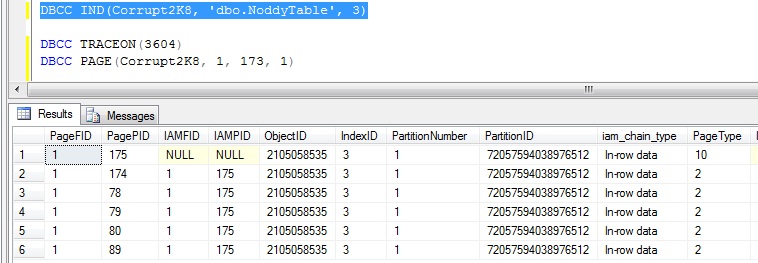
I'm going to pick a page of page type 2 (an index page), my chosen page number here is 174.
Next I need to go view a dump of this page just to have a look at the records it contains. This requires the use of another undocumented DBCC command called DBCC PAGE. Again full details of this are in the links below but basically it's used as follows:
DBCC PAGE (DatabaseName, filenumber, pagenumber, printoption)So, I have the following
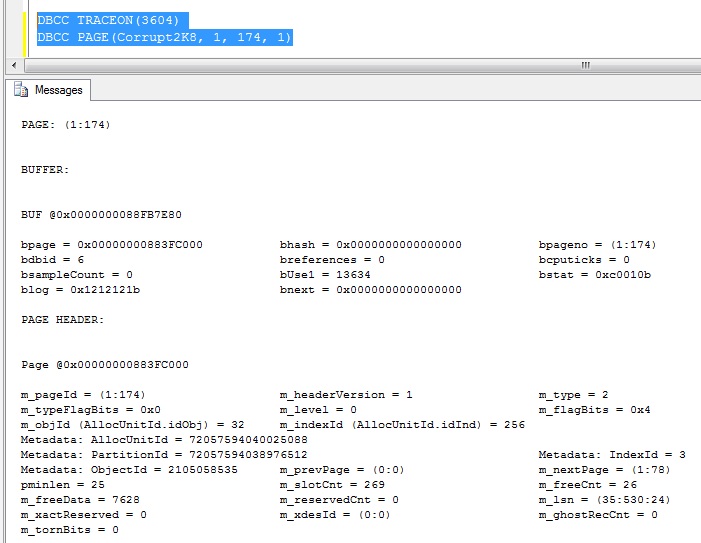
--switch on client output first DBCC TRACEON(3604) --now read the page DBCC PAGE (Corrupt2K8, 1, 174, 1)
This is the page header:
Below are the record details. I'm going to home in on slot7 or record 7. I'll use the Hex editor to modify this record in the page which will then generate an error when DBCC CHECKDB is run. The detail for slot 7 looks as follows;
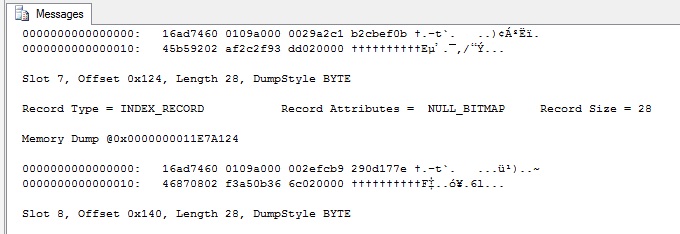
To hack the record at slot 7 on page 174, I first need to work out some figures to find the address locations within the file. Convert the record offset from hex to decimal first and then the address for slot 7 is calculated as follows:
page number x 8192 + record offset
This equates to 174 x 8192 + 292 = 1425700. Take the database offline and now open the primary data file using XVI32. From the File menu select open and then browse to the MDF file
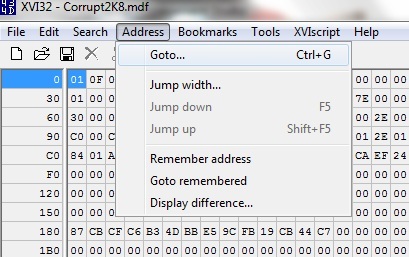
Now, from the File menu select "Address" > "Goto". In the dialog box which appears ensure you select the decimal radio button and enter the address which was calculated above, in my case 1425700. As you can see from the screenshot below, the editor has placed me at the start of my chosen record in page 174.
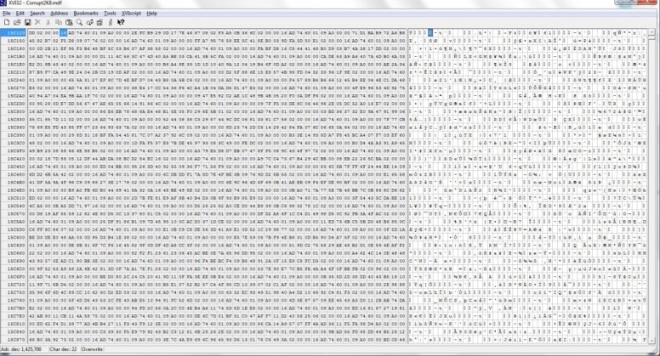
This record has a length of 28 bytes, i'm going to have a little fun here. First switch the editor to Text and Overwrite Mode if it isn't already. From the File menu ensure "Tools" > "Text Mode" and "Tools" > "Overwrite" are selected. Now I'll mark the blocks i wish to mangle. To do this, from the File menu select "Edit" > "Block <n> chars". Switching to decimal i enter the record length of 28. The blocks have now been marked in red as shown below
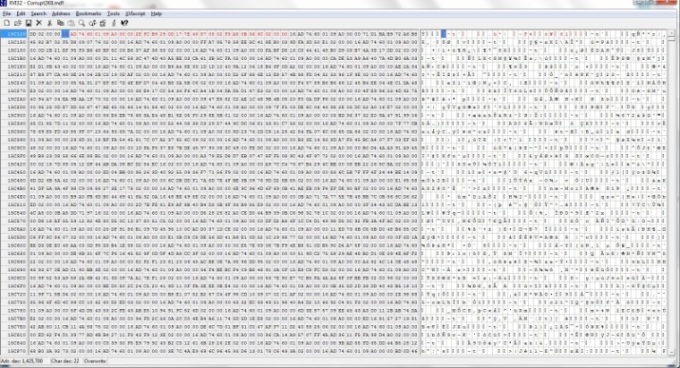
Now to overwrite the record in slot 7 as shown below in text mode

Now click "File" > "Exit" and save the file when prompted to do so. In SQL Server you may now bring the database back online. We'll re run the page dump and check the results which are shown below;
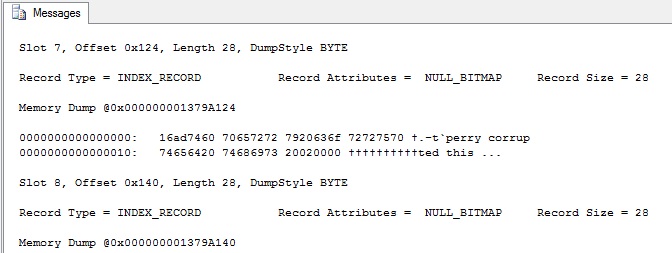
Well as we can see above the record was modified in the anticipated location, of course the only part hosed here is the non clustered index which is easily fixed by dropping and re creating it. What does DBCC CHECKDB show us

Now you have a corrupt database which you may use for your DR and script tests. Give this a go in your test systems and by all means post back if you're stuck.
Credits:
Information on these undocumented procedures was digested from Paul Randal's blogs at the following links
- http://blogs.msdn.com/b/sqlserverstorageengine/archive/2006/12/13/more-undocumented-fun_3a00_-dbcc-ind_2c00_-dbcc-page_2c00_-and-off_2d00_row-columns.aspx
- http://blogs.msdn.com/b/sqlserverstorageengine/archive/2006/08/09/692806.aspx
- http://blogs.msdn.com/b/sqlserverstorageengine/archive/2006/06/10/625659.aspx
Warnings:
Obviously you should not perform this on your production databases\servers, complete all tests in your offline environments. I will not be held responsible for those who wish to apply this is online environments.

