

How to break replication
Introduction
Like most aspects of SQL Server my first exposure to replication came as a result of a requirement on a project I was assigned to. As usual it was a case of browsing a few websites, buying book and then trial and error.
This was back in the days when SQL Server 7.0 was just released and my first project was pretty much "set it up and forget it" as far as replication was concerned. As a consequence I only touched on the basics.
The general gist of what I learnt back then was
Snapshot | = | Copy everything |
Transactional | = | Copy some things |
Merge publication | = | Don't touch with a barge pole and that if you were wise the barge pole you weren't touching it with wasn't yours! |
From such naive beginnings a decade ago I have seen replication go from being a specialist area to a bog standard mainstream activity.
I have learnt a great deal about replication along the way, mainly by breaking it and then desperately trying to fix it. If you are just starting out with replication then perhaps some of my experiences will be of use to you.
Adventureworks
For simplicity sake I am going to illustrate my various mistakes using the Adventureworks database replicated to a copy called AW_Target.
In the real world I work on systems where various flavours of snapshot and transactional replication are used. All alterations to replication has to be done via scripts as deployment is to multiple environments (development, testing, live).
The volumes of data in LIVE are very large so a great deal of care has to be taken to protect the sanctity of the data. For this reason we set up replication in all our environments precisely so we can test changes to replication.
Replication plays such a key role that all replication jobs are set to email the DBAs on failure in order to ensure that problems are resolved as a matter of priority.
I freely admit that I am not an expert but my goal here is to show you my mistakes and give you the opportunity to learn from them.
Replication Monitor
There have been many improvements in SQL Management Studio and Replication Monitor is a major leap forward. Particularly the ability to manage old legacy SQL2000 instances as well as SQL2005 instances.
To launch replication monitor right-click on the "Replication" folder in "Object Explorer" and choose "Launch Replication Monitor" as shown below.
This will produce a screen similar to the one shown below
We will use replication monitor extensively in this article.
Mistake One - Putting data into the subscriber
The scenario
Your organisation has multiple SQL Servers with each live server aligned to a line of business.
Your organisation has some master data that is common across all lines of business and rather than have a dependency on a single server holding that master data you replicate a database containing the master data to each "line-of-business" server. If one database server goes down then although you will have lost that line of business the others will continue to bring in sales.
The mistake
As a rookie I didn't know which server was the master source of data or even that there was a master source of data. So when I go a request to put data into the LIVE environment I put it in one of the slave copies rather than the master.
Of course the mistake didn't show up immediately as the master data I had inserted was initially only relevant to the "line of business" server I had inserted it on. It was only when a separate "line of business" server required the data and another DBA correctly inserted it into the master source that the error showed up.
Simulating the problem
To simulate the problem I inserted four records into AW_Target.Person.AddressType in my subscriber as follows
AddressTypeID | Name | Rowguid | ModifiedDate |
|---|---|---|---|
9 | Vacation | BC122786-B94A-451E-9DE5-6B09E75A1EFF | 2007-12-28 13:21:28.577 |
10 | Vacation1 | 544E1F25-1505-40FF-8010-1968D90592DC | 2007-12-28 13:35:19.827 |
11 | Vacation2 | EC785826-058F-45D2-9B2D-A4F980E39913 | 2007-12-28 13:35:27.543 |
12 | Vacation3 | BD91F406-A4CF-4931-9A7A-5389CABD300A | 2007-12-28 13:35:36.797 |
I then inserted AddressTypeID 10 and 12 into Adventureworks followed by a 3rd legitemate entry.
To see the problem this creates perform the following tasks
Launch replication monitor as described earlier
Double-click on the problem subscription
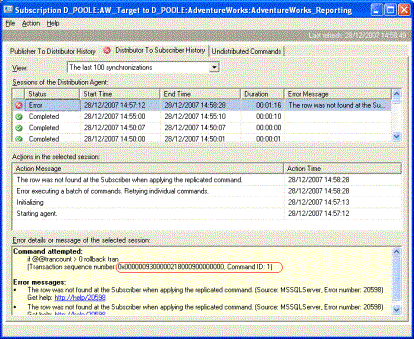
Choose the "Distributor to Subscriber History" tab on the resulting dialogue as shown below

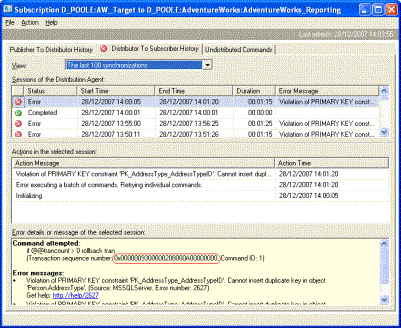
As expected this shows that there has been a primary key violation as our AddressTypeID values (10 and 12) already exist. Although in this case we know what is causing the fault this would not necessarily be the case if we were doing this for real.
Diagnosing the problem
Make a note the transaction sequence number that I have highlighted in red in the dialogue.
First of all we need to find out what the transaction actually contains, to do this carry out the following procedure.
Connect to your distibutor
In your distribution database run the following query
exec sp_browsereplcmds @xact_seqno_start = '0x0000009300000208000A'
Note that @xact_Seqno_start is 22 characters long therefore the trailing zeros have been truncated.
These will list all the commands that are being executed as part of this sequence.
If you scroll across to the "Command" column in the result grid you will see the following statements
{CALL [sp_MSins_PersonAddressType] (10,N'Vacation1',{544E1F25-1505-40FF-8010-1968D90592DC},2007-12-28 13:35:19.827)}
{CALL [sp_MSins_PersonAddressType] (12,N'Vacation3',{BD91F406-A4CF-4931-9A7A-5389CABD300A},2007-12-28 13:35:36.797)}
{CALL [sp_MSins_PersonAddressType] (13,N'Dave',{A9B4C362-9348-4CAE-BF9F-762B39491291},2007-12-28 13:42:01.793)}The first two statements belong to our problem sequence, we could have isolated our sequence by using the following statements however for illustration purposes we showed all statements
exec sp_browsereplcmds @xact_seqno_start = '0x0000009300000208000A' , @xact_seqno_end = '0x0000009300000208000A'
Note that the Replication Monitor message also mentions CommandID: 1. This indicates that the error is detected with the first command.
In the real world there may be thousands of commands in a transaction sequence so the ability to drill down to the specific problem command is extremely useful. This can be done using the following arguments.
exec sp_browsereplcmds @xact_seqno_start = '0x0000009300000208000A' , @xact_seqno_end = '0x0000009300000208000A' , @publisher_database_id = 1, @command_id = 1
Note that the value for @publisher_database_id is not the DB_ID() value for the database. It is the value from the field publisher_database_id from the msdistribution_agents table in your Distribution database.
Fixing the problem
We can see that command 1 contains an instruction to insert AddressTypeID=10 therefore we need to check on both the subscriber at publisher to see what AddressTypeID=10 represents.
Bear in mind that if data was entered onto the subscriber then at a later date the publisher a single ID value may have completely different meanings, in which case further remedial action is required.
In our case we know that the values at both publisher and subscriber are the same so we can delete the ones at the subscriber
USE AW_Target GO DELETE FROM Person.AddressType WHERE addresstypeid=10
Having done so we can now either wait for the distribution agent to run again or force it to run by choosing "Start Synchronising" from the Action menu.
In this case we get a new error message as follows.
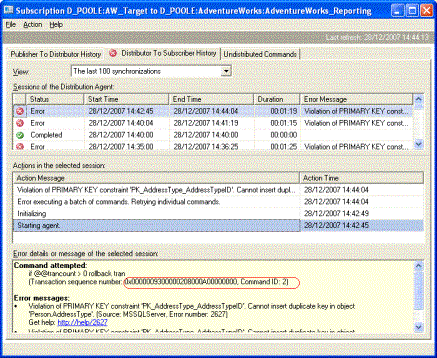
This means that we now have to repeat the process for the 2nd command.
exec sp_browsereplcmds @xact_seqno_start = '0x0000009300000208000A' , @xact_seqno_end = '0x0000009300000208000A' , @publisher_database_id = 1, @command_id = 2
Investigate AddressTypeID=12 and take any remedial action.
This time when we remove AddressTypeID=12 and force the distribution agent to run the job succeeds and our final legitimate AddressTypeID=13 is safely replicated across to AW_Target from Adventureworks.
Other considerations
In our example it was simply a case of inserting the correct data at the wrong end of a replication chain. In the worst case scenario different data could have been inserted for the same AddressTypeID values in different servers and then dependent data on each server built up. This would have meant that unpicking the problems caused in this situation would become extremely difficult, particularly in the LIVE environment.
Mistake Two - Removing data from the subscriber
The diagnosis and fix for this mistake is similar to that taken when data in inserted at the subscriber.
The initial error message is very similar showing a transaction sequence number and command id.
Simulating the problem
In our AW_Target database we simply run the following command
DELETE FROM Person.AddressType WHERE AddressTypeID=13
The in our Adventureworks database we run an update on the published table for AddressTypeID=13
Diagnosing the problem
The same procedure should be used as for the insertion of data into the subscriber.
Fixing the problem
As we actually want to delete a record for an explicit AddressTypeID field, all we have to do to fix it is put a record in place for that AddressTypeID field in the knowledge that next time the distribution agent runs it will remove our newly inserted record.
Strictly speaking it doesn't matter what the actual record contains provided that the AddressTypeID value is correct. As a matter of personal preference I always prefer to put the true values in the record.
General comments on my first two mistakes
Prevention
As long as there are human beings involved in a process there will always be mistakes. If you want to prevent this sort of mistake from happening in your environment I would take the following steps.
Make sure that the necessary user education has taken place. The environment is understood and the source of data is known.
Make sure there is a simple, clear and easy to find repository of information on how your organization deploys data.
Make sure the existence of a master source of data is known.
Cure
Although the cure is straightforward it can be laborious. Let us suppose that you have a transaction sequence with many thousands of items in it and an unknown number are going to cause you problems. You could easily lose a great deal of valuable time trying to fix this problem.
In both scenarios the use of SQL Data Compare is ideal for identifying the differences in data between the publisher and subscriber. It clearly identifies those items that are in one data source but not the other, which is precisely what you need in this case.
Mistake Three - Reinitializing a subscription
The scenario
Imagine that you have two servers
Server | Purpose |
|---|---|
Front end | Holds minimal data, geared up to fast response to customer activity |
Back end | Holds large amount of historical data. Intended as a repository to allow marketing to examine trends over time. |
Front end data is replicated to the back end database server where it is retained for a long period of time. The front end database server holds as little data as it can get away with and still fulfill customer activity.
All the replication DELETE stored procedures at the back end have had there internal workings stripped down to "RETURN 1" in order to prevent deletes from being replicated from the front end.
I have never had any luck with the replication options to exclude deletes. No matter what option I choose deletes are always replicated.
The mistake
I had to add an article to an existing publication and subscription and chose to do it using the user interface rather than via scripts. At the end of the wizard I received a dialogue box asking whether I wanted to cancel or reinitialize the subscription.
I knew I didn't want to cancel so I chose the only other action open to me.
This had three manifestations although there were no explicit errors.
- Front end customers experienced timeouts as the end of the snapshot generation process locks all affected tables.
- The vast majority of backend data was removed leaving only the data that was in LIVE.
- The replication delete stored procedures were overwritten meaning that deletes were replicated across to the back end database.
In the final manifestation this did not become apparent until after a lot of time was lost restoring data from back ups only have to repeat the process again.
General comments on mistake three
Consider the stored procedure that adds an a subscription to a publication
use AdventureWorks GO exec sp_addsubscription @publication = N'AdventureWorks_Reporting', @subscriber = N'D_', @destination_db = N'AW_Target', @subscription_type = N'Push', @sync_type = N'automatic', @article = N'all', @update_mode = N'read only', @subscriber_type = 0
If @sync_type = N'automatic' is used then a reinitialization will attempt to carry out whatever actions are set against the article.
With the benefit of hindsight, where the retention period at the subscriber is different to the retention period at the publisher I would not reinitialize the subscription.
I would also have set up the subscription with @sync_type = N'none'
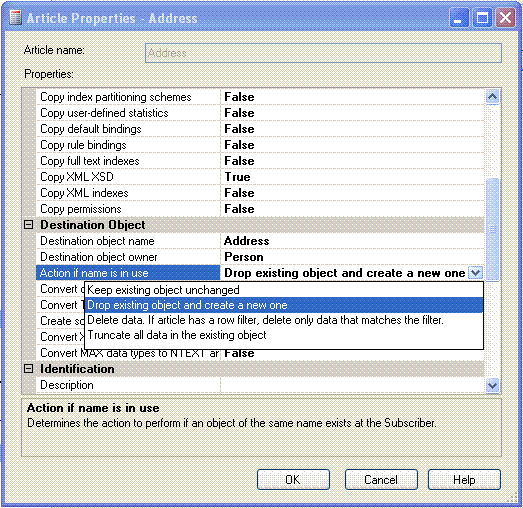
As the default was "Drop existing object and create a new one" this simply wiped out all data that I had before and replaced it with LIVE data. The same happened to the supporting replication stored procedures.
The "Keep existing object unchanged" option would have generated errors wherever the data in the snapshot already existed in LIVE. In which case I would have had to go through the laborious job of identifying which data in which tables would cause the errors.
Mistake Four - Reinitializing an expired subscription
The scenario
Downtime is scheduled on a publishing database server. The period of downtime is such that subscriptions to data on that server expire and you receive messages asking to reinitialize the subscription.
The mistake
You do as asked and reinitialize the subscription
In this case some articles are set to "Keep existing object unchanged". This results in the snapshot failing to apply as the data already exists at the subscriber and replication remains inactive.
Fixing the problem
The problem in this case is that all "Keep existing object unchanged" articles have to be identified and then data in these tables that already matches in both the publisher and subscriber will need to be removed from the subscriber. Although this is not complicated it is very time consuming.
Again, using SQL Data Compare is a big help in identifying the matches between data sources.
General comments on both mistake three and four
In both cases reinitializing the subscription caused the problems. Both mistakes highlight the need to know exactly how replication is configured in a particular subscription.
If you had a publication containing fairly static data such as lookup tables, application configuration data etc where the subscription should always be exactly the same as the publication then configuring the publication to drop and recreate objects is the correct thing to do. Reinitializing the snapshot has little affect other than the locking of tables at the end of the snapshot run.
If your publication is to add increments to a much larger data store then reinitializing the subscription is not a good thing to do and having the articles set to drop and recreate is suicidal.
You probably have a mix and match of different types of data in your database so there is nothing to stop you defining more than one publication per database and any one table to appear as an article in more than one publication depending on what it is you want to do.
For example, let us suppose that you have a customer feedback form that is database driven. For resilience purposes the supporting configuration tables are replicated to each "line of business" server but in each case the actual customer feedback is replicated from the "line of business" server down to the marketing server.
The configuration tables would be set up as @sync_type = N'automatic' and objects set to drop and recreate. This could be reinitialized if need be with no ill effects.
The actual customer feedback would be set to @sync_type=N'nosync' and the objects set to "keep existing object unchanged".
Mistake Five - Reactivating expired subscriptions
The scenario
A subscription has expired. You know that you don't want to reinitialize the subscription due to the sheer size of the data contained in the articles so you decide to drop the subscription and re-add it using sp_dropsubscription and sp_addsubscription
The mistake
Everything seemed to work fine, the old data was retained, new data replicated successfully through from the publication to the subscription.
The problem that was identified later was that there was some missing data from the time the subscription was expired to the time the subscription was dropped and recreated.
Fixing the problem
Provided the problem is identified before the data is purged from the publisher the solution is to identify the data that falls in the gap between the expiration and recreation of the subscription and copy it across to the subscriber manually.
Once again this is an ideal job for SQL Data Compare.
If the data has vanished from the publisher due to legitimate purge activity but should exist on the subscriber then there is no option but to restore a copy of the publishing database and copy the data from there.
General comments on recreating expired subscriptions
Before recreating the subscriptions it is important to identify the last record in each article that was successfully copied across to the subscriber. It is far easier and quicker to find the last occurrence of a record than it is to find a gap that may or may not be as a result of the expired subscription.
To give an example, if you have a table with a numeric sequence such as an IDENTITY column it is quite possible that there is a gap in the number range due to deletions or rolled back transactions in the publisher database. Identifying a specific gap amongst several gaps is more involved than simply running SELECT MAX(id) FROM table.
Mistake Six - sync_type =N'none' subscriptions
The scenario
You want to add an article to an existing subscription and script up the addition of both the article to the publication and to the subscription.
USE AdventureWorks GO exec sp_addarticle @publication = N'AdventureWorks_Reporting', @article = N'ContactType', @source_owner = N'Person', @source_object = N'ContactType', @type = N'logbased', @description = N'', @creation_script = N'', @pre_creation_cmd = N'delete', @schema_option = 0x000000000803509F, @identityrangemanagementoption = N'manual', @destination_table = N'ContactType', @destination_owner = N'Person', @status = 16, @vertical_partition = N'false', @ins_cmd = N'CALL [sp_MSins_PersonContactType]', @del_cmd = N'NONE', @upd_cmd = N'SCALL [sp_MSupd_PersonContactType]' -- Adding the transactional subscriptions exec sp_addsubscription @publication = N'AdventureWorks_Reporting', @subscriber = N'D', @destination_db = N'AW_Target', @subscription_type = N'Push', @sync_type = N'none', @article = N'all', @update_mode = N'read only', @subscriber_type = 0 GO
The script runs fine with no errors but then the replication monitor lights up with a number of error messages similar to the one shown below
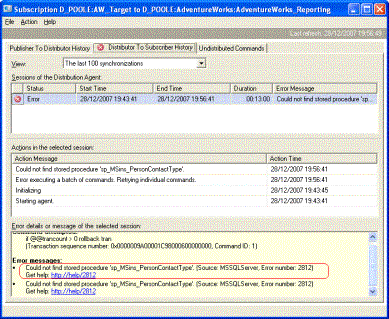
The problem
A nosync subscription requires you to generate the replication stored procedures yourself. This is telling you that the stored procedures cannot be found and therefore an error is occurring.
Fixing the problem
Given that @sync_type=N'automatic' will cause the article objects and supporting stored procedures to be created when the snapshot agent runs the easiest solution is to generate a @sync_type=N'automatic' subscription in your development environment and copy the resulting stored procedures to the LIVE environment.
Once you have the stored procedures drop and recreate the subscription in the development environment as a nosync subscription so that your development environment is configured in the same way as LIVE.
The alternative is to create them from scratch yourself and strictly speaking you should not be creating objects on the fly in a LIVE environment.
General comments on sync_type =N'none' subscriptions
Again, this is a case of knowing how replication is configured for your environment. When deploying replication in the LIVE environment you should know in advance whether you are setting up a @sync_type=N'automatic' or a @sync_type=N'none' subscription
When deploying @sync_type=N'none' subscriptions I prefer to deploy the subscription stored procedures first so that these essential items are waiting for me to add the article and subscription at a later date.
Conclusion
Although it sounds as if I am a one-man disaster area reading through the mistakes condensed into a single article the mistakes I made actually took place over a long period of time.
Although I have learnt a great deal about replication (and have even more to learn) the main lessons are not about replication but about the background tasks that should take place in any environment and for any task.
Documentation | For any environment there needs to be an easily read, easily accessible knowledgebase to refer to. No one likes to write documentation and project managers often use it as a pseudonym for contingency tasks. Well written documentation is an absolute must if applications are to be supported properly |
|---|---|
Education | Some people learn well from books, others prefer face to face contact. If LIVE data is at stake then it is important to make sure that all DBAs are up to speed with the environment and its configuration. |
Rehearsal | If the effect of a mistake in a LIVE environment costs money then that cost should be weighed against the cost of having a "rehearsal" environment. Finding out that an error has occurred in a test environment is no big deal, in fact it is the whole purpose of having a test environment. Finding out that an error has occurred in a LIVE environment can be both expensive and extremely stressful. |
Planning | Determining how replication should have been configured in the first place is an absolute must. |
