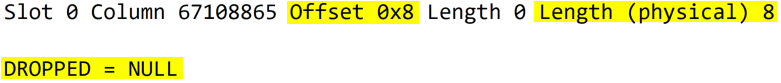In my last article - Identify Tables With Dropped Columns - we saw how we can identify tables that have columns that were dropped. Today, we are going to check a way to approximately calculate how much space we can expect to recover if we rebuild our table.
If you want to read the 1st article I published on this subject, you can read it here - What happens when we drop a column on a SQL Server table? Where's my space?
Why can this be important?
Rebuilding a table is, by default, an offline operation! This means the table will have a lock and other sessions can't read from it while the rebuild is running. However, if you are running an Enterprise edition you can use the `ONLINE = ON` option to minimize this. The table won't be locked for the whole period of the rebuild.
That is why it's important to estimate how much space we can recover from a rebuild, after dropping a column. Your mileage will vary but if you expect to recover dozens or even hundreds of GB maybe it will be more interesting to do the rebuild soon rather than later, but if it is just a dozen of MB and that won't make a big difference, you can defer that to a later maintenance window.
Picking Up From the Last Article
NOTE: I haven't mentioned this before but, these scripts don't work on Azure SQL DB, but it does work on Azure SQL Managed Instance.
In the last article, I ended with the following code block as an option to find the dropped columns.
SELECT object_name(p.object_id) table_name, c.[name] as column_name, pc.partition_column_id, pc.is_dropped FROM sys.system_internals_partitions p JOIN sys.system_internals_partition_columns pc ON p.partition_id = pc.partition_id LEFT JOIN sys.columns c ON p.object_id = c.object_id AND pc.partition_column_id = c.column_id WHERE pc.is_dropped = 1
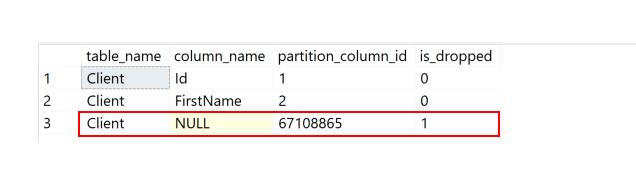
This doesn't output a lot of columns on purpose. We just needed the columns `table_name` and `column_name` (which is always `NULL` in this case) where `is_dropped = 1` to know the objects with dropped columns.
But...there is more!
If we explore the columns that belong to the `sys.system_internals_partition_columns` system view, we can see that it returns a total of 28 columns (at least for the SQL Server 2022 version).
As mentioned before, this system view is not documented. This means we can only infer/assume some info based on the column name and its contents.
To be able to calculate the space being wasted by the column that was dropped, we will need to know the size that column occupies on each record. For fixed-length data types, that will be the `max_length` column.
To have the total KB that our dropped column is still occupying, we will need to multiply the `max_length` column by the number of records that we have on the table. For that, we will need to use the column `rows` that we can obtain from the `sys.system_internals_partitions` system view.
A Practical Example
Picking our `Client` table where we have dropped the `DoB` column, let's see if this math works.
A column of data type `datetime` occupies 8 bytes. We can see that from the `max_length` column.

Let's say our table has 50000 rows. This will mean that 50000 (rows) * 8 (bytes) = 400000 (bytes). To convert that to KB, we will need to divide this result by 1000 we will get 400 KB. Knowing that each data page has 8 KB we can say that we are wasting 50 pages (400 / 8).
Confirming the Math
To confirm this is true, I have added some columns to our query.
SELECT
OBJECT_NAME(p.object_id) AS table_name,
COALESCE(cx.[name], c.[name]) as column_name,
pc.partition_column_id,
pc.is_dropped,
/*
New columns added
*/ pc.max_length,
p.[rows],
pc.max_length * p.[rows] AS total_bytes,
(pc.max_length * p.[rows]) / 1000 AS total_kb,
(pc.max_length * p.[rows]) / 1000 / 8 AS total_pages
FROM sys.system_internals_partitions p
JOIN sys.system_internals_partition_columns pc
ON p.partition_id = pc.partition_id
LEFT JOIN sys.index_columns ic
ON p.object_id = ic.object_id
AND ic.index_id = p.index_id
AND ic.index_column_id = pc.partition_column_id
LEFT JOIN sys.columns c
ON p.object_id = c.object_id
AND ic.column_id = c.column_id
LEFT JOIN sys.columns cx
ON p.object_id = cx.object_id
AND pc.partition_column_id = cx.column_id
CROSS APPLY sys.dm_db_index_physical_stats(DB_ID(), p.object_id, p.index_id, DEFAULT, 'LIMITED') AS ddips
WHERE p.object_id = object_id('dbo.Client')
AND p.index_id IN (0, 1)
AND is_dropped = 1
![]()
Before and After
With the previous query, we already have an idea of the number of pages and therefore the amount of KB that we may be able to recover after a rebuild. However, to add a bit more detail to our investigation let's put the current size and the expected one, after rebuilding, side-by-side.
For this, we will need to know what the actual number of pages that our table is using is. For that, we can use the dynamic management function (DMF) `sys.dm_db_index_physical_stats` that returns the `page_count` column. As it is a DMF, to add to our query we will use a `CROSS APPLY`.
SELECT
OBJECT_NAME(p.object_id) AS table_name,
COALESCE(cx.[name], c.[name]) as column_name,
pc.partition_column_id,
pc.is_dropped,
pc.max_length,
p.[rows],
pc.max_length * p.[rows] AS total_bytes,
(pc.max_length * p.[rows]) / 1000 AS total_kb,
(pc.max_length * p.[rows]) / 1000 / 8 AS total_pages,
ddips.page_count AS current_page_ount /* New column added */ FROM sys.system_internals_partitions p
JOIN sys.system_internals_partition_columns pc
ON p.partition_id = pc.partition_id
LEFT JOIN sys.index_columns ic
ON p.object_id = ic.object_id
AND ic.index_id = p.index_id
AND ic.index_column_id = pc.partition_column_id
LEFT JOIN sys.columns c
ON p.object_id = c.object_id
AND ic.column_id = c.column_id
LEFT JOIN sys.columns cx
ON p.object_id = cx.object_id
AND pc.partition_column_id = cx.column_id
CROSS APPLY sys.dm_db_index_physical_stats(DB_ID(), p.object_id, p.index_id, DEFAULT, 'LIMITED') AS ddips
WHERE p.object_id = object_id('dbo.Client')
AND p.index_id IN (0, 1)
AND is_dropped = 1
![]()
With this, we can see that we have 180 data pages.
Now, all we need to do is some math 😁
SELECT
OBJECT_NAME(p.object_id) AS table_name,
COALESCE(cx.[name], c.[name]) as column_name,
pc.partition_column_id,
pc.is_dropped,
pc.max_length,
p.[rows],
pc.max_length * p.[rows] AS total_bytes,
(pc.max_length * p.[rows]) / 1000 AS total_kb,
(pc.max_length * p.[rows]) / 1000 / 8 AS total_pages,
ddips.page_count AS current_page_ount,
/*
New columns added
*/ ddips.page_count - (pc.max_length * p.[rows] / 1000 / 8) AS new_page_count,
ddips.page_count * 8 AS current_data_size_kb,
(ddips.page_count - (pc.max_length * p.[rows] / 1000 / 8)) * 8 AS new_data_size_kb
FROM sys.system_internals_partitions p
JOIN sys.system_internals_partition_columns pc
ON p.partition_id = pc.partition_id
LEFT JOIN sys.index_columns ic
ON p.object_id = ic.object_id
AND ic.index_id = p.index_id
AND ic.index_column_id = pc.partition_column_id
LEFT JOIN sys.columns c
ON p.object_id = c.object_id
AND ic.column_id = c.column_id
LEFT JOIN sys.columns cx
ON p.object_id = cx.object_id
AND pc.partition_column_id = cx.column_id
CROSS APPLY sys.dm_db_index_physical_stats(DB_ID(), p.object_id, p.index_id, DEFAULT, 'LIMITED') AS ddips
WHERE p.object_id = object_id('dbo.Client')
AND p.index_id IN (0, 1)
AND is_dropped = 1

The Final Proof
To confirm if our math works, let's rebuild our table so we can get rid of the extra space left by the drop action and check how many data pages is the table using.
-- Let's clear the dropped column and tidy up things ALTER TABLE Client REBUILD
Checking the current number of data pages - for that we can run the following query:
SELECT
OBJECT_NAME(p.object_id) AS table_name,
COALESCE(cx.[name], c.[name]) as column_name,
pc.partition_column_id,
pc.is_dropped,
pc.max_length,
p.[rows],
ddips.page_count AS current_page_ount
FROM sys.system_internals_partitions p
JOIN sys.system_internals_partition_columns pc
ON p.partition_id = pc.partition_id
LEFT JOIN sys.index_columns ic
ON p.object_id = ic.object_id
AND ic.index_id = p.index_id
AND ic.index_column_id = pc.partition_column_id
LEFT JOIN sys.columns c
ON p.object_id = c.object_id
AND ic.column_id = c.column_id
LEFT JOIN sys.columns cx
ON p.object_id = cx.object_id
AND pc.partition_column_id = cx.column_id
CROSS APPLY sys.dm_db_index_physical_stats(DB_ID(), p.object_id, p.index_id, DEFAULT, 'LIMITED') AS ddips
WHERE p.object_id = object_id('dbo.Client')
AND p.index_id IN (0, 1)

As we can see on the image, the `current_page_count` is now `130` which matches the `new_page_count` column in the previous query.
How Accurate Is This?
You should use this script and analyse the results with a pinch of salt. My idea wasn't to build a one-size-fits-all script but rather to check if the math would add up and would be enough to rely on it for specific situations. Feel free to pick the script and adapt it as you wish.
Also, check below for some of the reasons why it isn't a one-size-fits-all.
This works well for fixed-length columns and no compression and...
The attentive reader may be wondering "Ok, this was on a HEAP!".
- What if the table has a CLUSTERED index?
- What if our column that was dropped doesn't have a fixed length?
- Or if it was nullable?
- Will these calculations work the same way if we are using compression?
- And, what happens if I have NONCLUSTERED indexes using the column?
Let me answer all these five questions.
"Will these calculations work the same way if we are using compression?"
Let me address this one first because this is a show-stopper for this script. If the table is compressed, the script can/will return some odd results as it doesn't take into account that the data type used by the column can occupy less space (can be compressed), which will lead to abnormal (ultimately can lead to negative) values.
Therefore, the answer is no. The way the script is built won't be a good fit for tables that are compressed.
"What if the table has a CLUSTERED index?"
As long as the table isn't compressed, the same script can still be used to have a good guess. You can test by yourself, create a CLUSTERED index on the table and run the scripts again.
"What if the column that was dropped doesn't have a fixed length?
When a column doesn't have a fixed length, and it's already dropped, you won't have any metadata to give you an approximate size (an average_record_size). In this case, probably your best bet is to decide on a value as the average occupied by that column to do the calculation.
Example:
If we have a `VARCHAR(50)` column, we will see the `max_length` showing `50` however, if we know that on average, we only have 20 chars, we can use that to have an estimate.
If you don't have that info, I would suggest using half of the size `25` in this example. At this point, it will be as good of a guess as any other.
"Or if it's nullable?"
If the column has a fixed length being nullable or not doesn't matter. It occupies the same number of bytes as when the column has a value different than `NULL`.
NOTE: Unless you use Sparse Columns but that is a different story with some restrictions/caveats.
"And NONCLUSTERED indexes?"
We can't drop a column that is part of a NONCLUSTERED index without disable/drop that same index first.
This script is written to do calculations on the actual data (HEAP/CLUSTERED index) and not on a copy of the data (NONCLUSTERED index).
Wrap up
In this article, we modified the script to get the table with dropped columns to have more detail to be able to calculate how much space we are wasting after that column is dropped.
We also mentioned a bunch of caveats that you need to be aware of, depending on the table structure, that can make this script not produce the expected value.
I hope you find this example educational and that you can use it to do some testing by yourself.
Thanks for reading.