

Big data processing plays a pivotal role in the development and efficiency of Generative Artificial Intelligence (AI) systems. These AI models, which include examples like language models, image generators, and music composition tools, require substantial amounts of data to learn and generate new, coherent, and contextually relevant outputs. The intersection of big data processing techniques with generative AI poses both opportunities and challenges in terms of scalability, data diversity, and computational efficiency.
This paper explores the methodologies employed in processing large datasets for training generative AI models, emphasizing the importance of data quality, variety, and preprocessing techniques. We discuss the evolution of data processing frameworks and tools that have enabled the handling of vast datasets, highlighting their impact on the performance and capabilities of generative AI. Furthermore, the paper delves into the challenges of big data processing in this context, including data bias, privacy concerns, and the computational demands of training large-scale models.
We also examine case studies where big data processing has significantly contributed to advancements in generative AI, providing insights into the practical aspects of deploying these technologies at scale. Additionally, we explore the emerging trends and future directions in this field, considering the potential of new data processing technologies and architectures to further enhance the capabilities of generative AI systems.
The paper underscores the critical role of big data processing in the advancement of generative AI, offering a comprehensive overview of current practices and future prospects. Through this exploration, we aim to provide a foundational understanding for researchers and practitioners alike, fostering further innovation and development in this dynamic and impactful area of artificial intelligence.
At first, it is important to have a grounding on how the data is stored and the formats that are used to store the data to achieve an effective compression ratio that is ideal for processing large volumes of data.
Iceberg and Parquet
Iceberg and Parquet are both columnar storage formats used in the realm of big data processing, but they serve different purposes and have distinct features. Here's a comparison between Iceberg and Parquet.
Storage Model
Parquet is a columnar storage format that organizes data into row groups and column chunks. It efficiently stores data by compressing and encoding column values separately, enabling high compression ratios and efficient query processing, especially for analytical workloads.
Iceberg is more than just a storage format; it's a table format that sits on top of existing storage systems like Parquet, ORC, or Avro. It introduces additional metadata and structural improvements to support features like schema evolution, ACID transactions, time travel, and incremental processing.
Schema Evolution
Parquet's schema is static once data is written, meaning that any changes to the schema require rewriting the entire dataset. Schema evolution in Parquet typically involves creating a new version of the dataset with the updated schema.
Iceberg supports schema evolution natively, allowing for changes to the table schema without requiring a rewrite of the entire dataset. It maintains historical versions of the schema, enabling backward compatibility and easier data evolution over time.
Transaction Support
Parquet does not inherently support transactions. Any form of transactional guarantees or atomicity needs to be implemented at a higher level, typically by the processing engine or data management system.
Iceberg provides built-in support for ACID transactions, ensuring atomicity, consistency, isolation, and durability for data writes. It allows multiple writers to concurrently update the same table while maintaining transactional consistency.
Data Management
Parquet focuses primarily on efficient storage and query performance. It lacks built-in features for managing table metadata, versioning, and incremental updates.
Iceberg provides robust data management capabilities, including schema evolution, time travel, data versioning, and incremental processing. It simplifies the process of managing large datasets over time, making it easier to maintain and evolve data pipelines.
Query Performance
Parquet's columnar storage format and efficient encoding techniques contribute to fast query performance, especially for analytical workloads that involve scanning large datasets and aggregating column values.
Iceberg's performance is comparable to Parquet since it can leverage underlying storage formats like Parquet or ORC. However, Iceberg's additional metadata and transactional features might introduce some overhead compared to raw Parquet files.
Choosing Formats for Workloads
While both Iceberg and Parquet are columnar storage formats used in big data processing, Iceberg offers additional features such as schema evolution, ACID transactions, and data management capabilities, making it more suitable for scenarios requiring schema flexibility, data versioning, and transactional guarantees. Parquet, on the other hand, excels in storage efficiency and query performance, particularly for read-heavy analytical workloads.
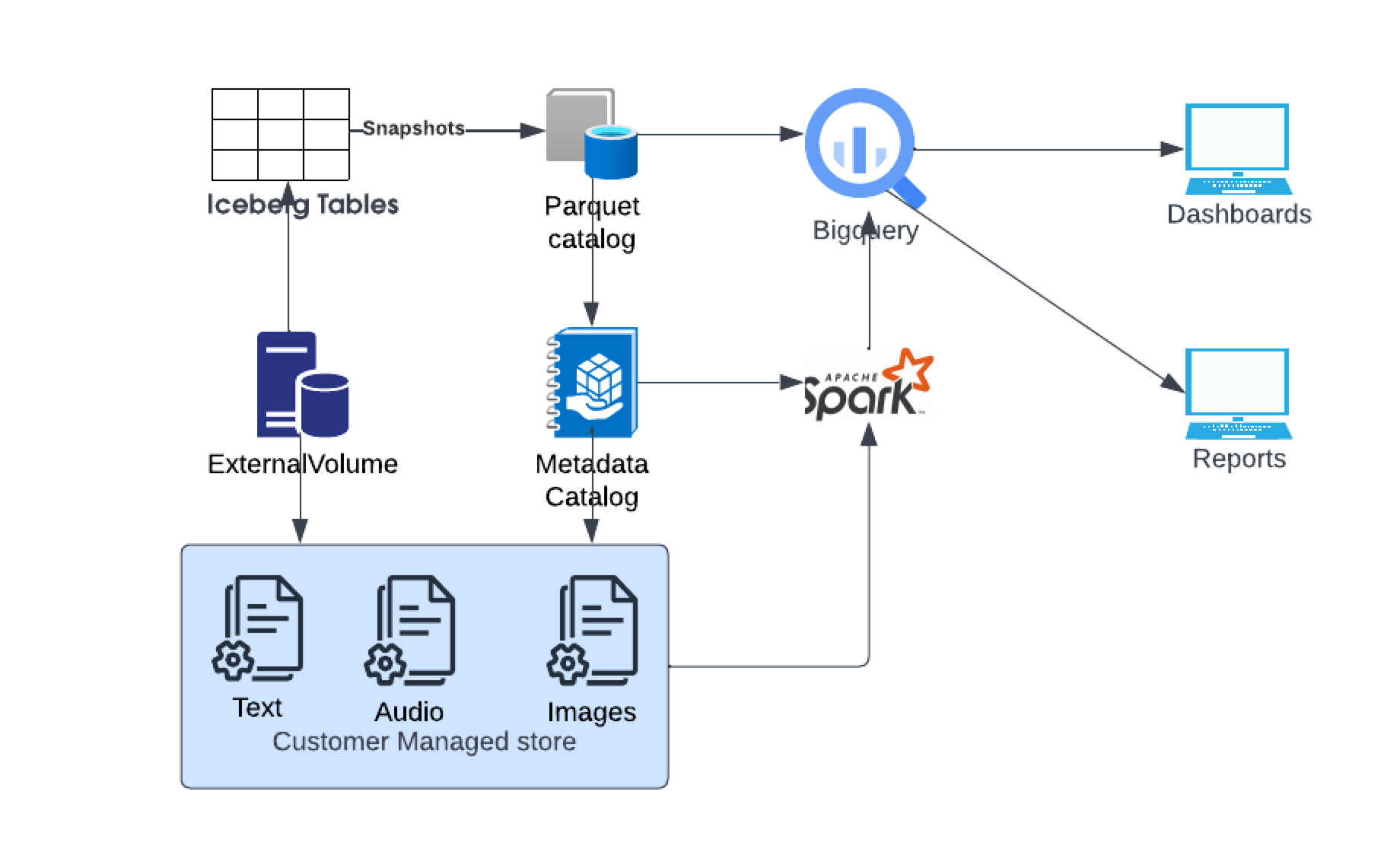 Figure 1: Iceberg and Parquet working together
Figure 1: Iceberg and Parquet working togetherIceberg and Parquet can work together in a data processing pipeline, leveraging the strengths of each format to achieve different objectives within the same ecosystem. Use tools like Apache Spark or other ETL (Extract, Transform, Load) frameworks to process and transform the data stored in Parquet format. Spark can read data from Parquet files, perform various transformations, and then write the transformed data into Iceberg tables. After transforming the data, store the processed data in Iceberg tables. Iceberg provides additional features such as schema evolution, ACID transactions, time travel, and incremental processing, which can be beneficial for managing structured data over time.
Once the data is stored in Iceberg tables, you can query and analyze it using SQL engines, like Trino (formerly Presto SQL) or Apache Hive. These engines can seamlessly query Iceberg tables, leveraging the transactional capabilities and schema evolution features provided by Iceberg. Iceberg supports incremental processing, allowing you to efficiently update and append data to existing tables without rewriting the entire dataset. This is particularly useful for scenarios where you need to ingest new data incrementally and maintain data versioning. In some cases, you may want to use a hybrid approach where certain data is stored in Parquet format for optimized storage and query performance, while other data, especially data requiring schema evolution and transactional guarantees, is stored in Iceberg tables. This approach allows you to leverage the benefits of both formats based on your specific requirements.
Overall, integrating Iceberg and Parquet in your data processing pipeline enables you to take advantage of Parquet's efficient storage and query performance, while also benefiting from Iceberg's additional features for data management, schema evolution, and transactional processing. This combination provides a flexible and scalable solution for managing and analyzing large volumes of structured data.
Apache Spark and HDFS (Hadoop Distributed File System) are both integral components of the ecosystem for processing and storing big data, but they serve different purposes and operate at different layers of the big data stack. Apache Spark is a unified analytics engine for large-scale data processing. It provides an interface for programming entire clusters with implicit data parallelism and fault tolerance. Spark can perform batch processing, real-time stream processing, machine learning, and graph processing. HDFS (Hadoop Distributed File System) is a distributed file system designed to run on commodity hardware. It provides high throughput access to application data and is designed to store large files running into terabytes or petabytes across multiple machines.
Apache Spark is primarily concerned with data processing. It reads data from various sources, processes it, and can write the output to various sinks. Spark does not store data; it processes data in-memory, which makes it much faster for certain computations compared to disk-based processing. HDFS is a storage system and does not have the capability to process data. It is designed to store a large amount of data reliably, and it works closely with Hadoop's processing modules (like MapReduce) or other processing systems like Apache Spark, which can perform the data processing.
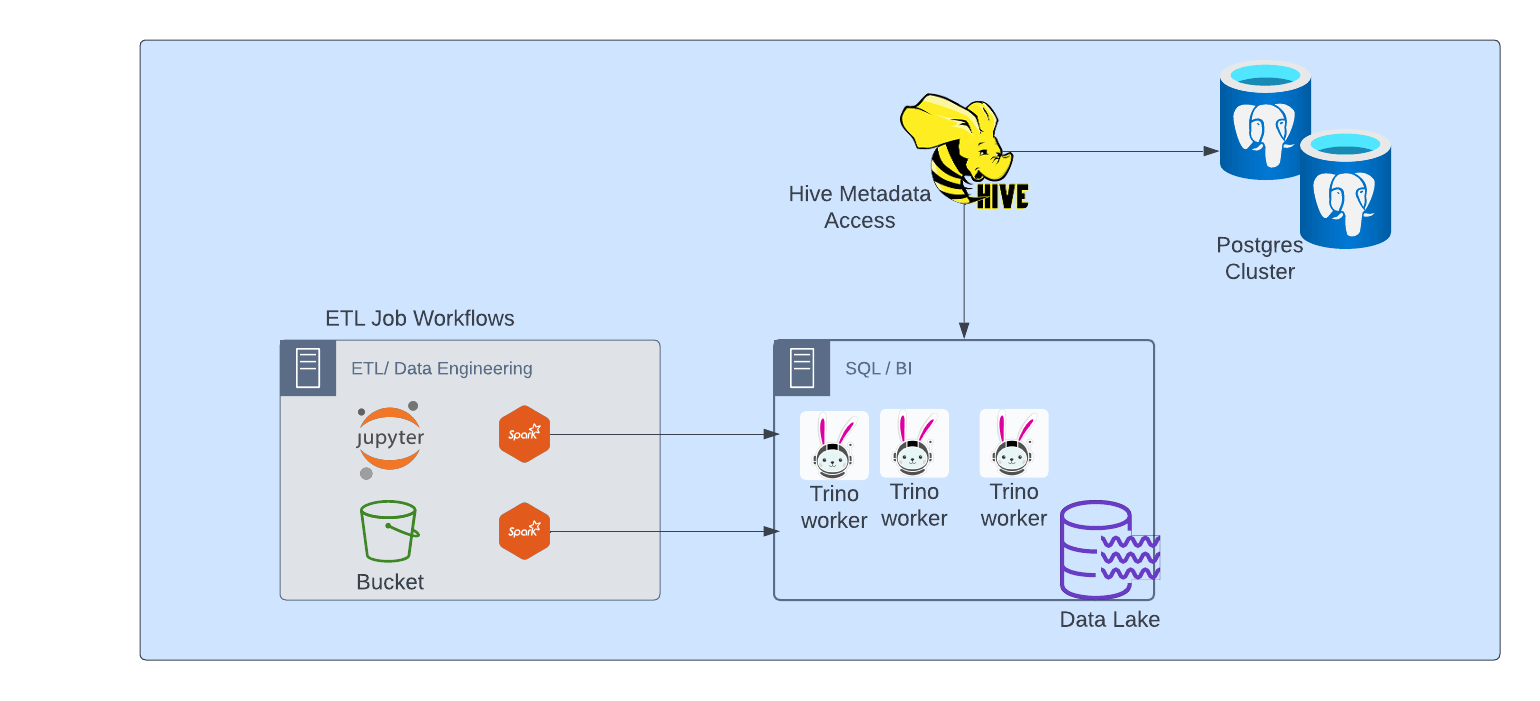
Figure 2: A new ETL approach with Spark feeding to a BI engine that allows Trino to query the Data Lake objects.
Spark and Trino
Spark and Trino (formerly known as Presto SQL) are both powerful tools used for data processing and analysis, but they serve slightly different purposes and have different strengths. While Spark is a distributed computing framework primarily used for batch and stream processing, Trino is a distributed SQL query engine designed for interactive querying of large datasets across multiple data sources.
Despite their differences, there are scenarios where Spark and Trino can complement each other, and they can work together in a data processing pipeline.
Data Transformation with Spark
Spark can be used for ETL (Extract, Transform, Load) tasks where data needs to be processed, cleaned, and transformed before it's ready for analysis. Spark's rich set of libraries and support for various data formats make it suitable for these tasks. You can use Spark to preprocess raw data, perform complex transformations, and store the processed data in a format that Trino can efficiently query.
Data Querying with Trino
Once the data is transformed and stored, Trino can be used for ad-hoc SQL queries and interactive analysis. Trino excels at querying large datasets across different data sources without needing to move or replicate the data. It can seamlessly integrate with various data lakes, data warehouses, and databases, providing a unified interface for querying data.
Optimizing Performance
In some cases, you might find that certain queries perform better in Trino than in Spark, especially when dealing with complex SQL operations or large-scale data aggregations. By leveraging Trino's query optimization capabilities, you can offload these queries from Spark to Trino, thereby improving overall performance and resource utilization.
Data Pipelines
Spark and Trino can be integrated into a data processing pipeline where Spark handles data ingestion, transformation, and preprocessing stages, while Trino handles data querying and analysis stages. You can orchestrate this pipeline using workflow management tools like Apache Airflow or Kubernetes to schedule and monitor the execution of tasks.
Hybrid Approaches
In some scenarios, you might need to combine the strengths of both Spark and Trino within the same workflow. For example, you can use Spark for initial data processing and transformation, then leverage Trino for interactive querying and analysis on the processed data. This hybrid approach allows you to take advantage of the strengths of each tool where they are most suited.
Overall, integrating Spark and Trino in your data processing architecture enables you to leverage the strengths of both platforms and build scalable, efficient, and flexible data pipelines for various use cases.
AI and Big Data
Big data processing has been a cornerstone in the advancement of generative AI across various fields, from natural language processing and image generation to predictive modelling and beyond. The ability to process and learn from vast amounts of data has allowed generative AI models to achieve remarkable levels of performance and realism. Lets now examine some case studies that highlight the significant contributions of big data processing to the development of generative AI technologies.
GPT (Generative Pre-trained Transformer) Models
The GPT series by OpenAI represents a leap in natural language processing and generation capabilities. These models, especially from GPT-3 onwards, have been trained on diverse internet text datasets, encompassing hundreds of billions of words. The success of GPT models lies in their ability to process and learn from an enormous corpus of text data, enabling them to generate human-like text across various styles and topics. The big data processing capabilities required to train such models include advanced natural language processing techniques, massive distributed computing resources, and sophisticated data cleaning and preprocessing pipelines.
DeepMind's AlphaFold
AlphaFold by DeepMind represents a significant advancement in the field of biology by predicting the 3D structures of proteins with unprecedented accuracy. This breakthrough has implications for drug discovery, understanding diseases, and synthetic biology. AlphaFold's success is partially attributed to the processing of vast datasets of known protein structures to train its deep learning models. The integration of big data processing with advanced machine learning techniques allowed AlphaFold to learn complex patterns in protein folding, a task that requires analyzing a vast space of possible structures.
DALL·E and Image Generation
OpenAI's DALL·E is a generative AI model capable of creating images from textual descriptions, showcasing impressive creativity and understanding of both text and visual concepts. DALL·E's training involved processing a large dataset of text-image pairs, enabling the model to understand and generate images based on textual prompts. The big data processing techniques involved in training DALL·E include sophisticated image processing methods, data augmentation strategies, and the management of a diverse dataset that spans various styles and subjects.
Predictive Modelling in Climate Science
Generative AI models are increasingly used in climate science to simulate complex climate systems and predict future climate scenarios. These models process vast datasets from satellite imagery, sensor data, and historical climate records. The processing of large-scale environmental data allows these models to capture the intricacies of climate systems accurately. Big data processing techniques, including spatial data analysis, time series forecasting, and handling high-dimensional datasets, are crucial for training these generative models to predict climate patterns and extreme weather events accurately.
Comparative Insights
Each of these case studies demonstrates the transformative impact of big data processing on generative AI development:
- Diversity of Data: From textual to visual and scientific data, the diversity of datasets processed showcases the broad applicability of generative AI across domains.
- Scale of Data: The sheer volume of data processed highlights the importance of scalable data processing architectures and distributed computing in training state-of-the-art generative AI models.
- Complexity of Tasks: The complexity of tasks achieved, from language understanding to protein folding prediction, illustrates the advanced capabilities that can be unlocked through sophisticated big data processing and machine learning techniques.
These advancements underscore the synergy between big data processing and generative AI, pointing towards a future where even more complex and nuanced tasks can be addressed as data processing techniques continue to evolve.
Conclusion
Big data is the backbone of generative AI, providing the extensive and diverse datasets necessary for training sophisticated models capable of producing realistic and contextually accurate outputs. The interplay between big data and generative AI has led to groundbreaking advancements across various domains, from natural language processing and image generation to scientific research and predictive modelling. The capacity to process and learn from vast amounts of data enables generative AI to mimic complex patterns, understand nuanced contexts, and generate content that is increasingly indistinguishable from that created by humans or observed in the natural world.
The scalability of big data processing techniques, coupled with advancements in machine learning algorithms, has allowed for the development of models that can handle an ever-growing volume of information, leading to improvements in accuracy, realism, and creativity of the generated outputs. Moreover, big data processing addresses critical challenges in generative AI, including reducing biases, enhancing privacy, and ensuring the ethical use of AI technologies.
In conclusion, big data not only fuels the development of generative AI but also pushes the boundaries of what is possible, driving innovation and enabling applications that were once considered science fiction. As big data processing techniques continue to evolve and become more sophisticated, we can expect generative AI to achieve even greater feats, transforming industries and impacting society in profound ways.

