

Background and the SQL 2000 Methodology
Using transactional replication as a disaster recovery
(DR) option seems to be fairly standard but definitely problematic in SQL 2000 and I wanted to see if it
has become any easier for SQL 2005. Use for DR is mentioned in detail in the SQL
Server 2000 High Availability Series
here. There are well established “competing” alternative technologies
in this series of articles including log shipping, replication with updateable subscribers, and now database
mirroring, which all have their pros and cons and I won't try to do
a long comparison of all these techniques here. Let’s just assume that you have come
to the conclusion that transactional replication is the most appropriate DR
solution for your needs and want to implement it as painlessly as possible.
As mentioned in the link above, for SQL Server 2000 there exists a pretty
thorough set of recommendations and manual processes to implement. You might
wonder why it is not so straightforward to set up. Basically, the problem is
that transactional replication out of the box assumes that the subscriber is
read-only. The constraints that exist to limit the data on the subscriber are
dropped and automatically populated columns – those having defaults, identities
or timestamps - are not implemented, because quite logically
they would be never be needed for a read-only implementation. This is fine for
normal transactional replication but if we want to use the subscriber as a
failover server it simply won’t cut it. We need the schemas to be more or less
identical on the publisher and subscriber or else our application will most
likely fail when pointed at the subscriber (I'm going to completely ignore those databases not
having any identity columns, check constraints, defaults or timestamps!).
The document above recognises these issues and therefore outlines how to make a
correct synchronisation of
schemas possible. It is largely a manual process and involves setting all
constraints and identities to NOT FOR REPLICATION (NFR) on the publisher, then
manually scripting out the publisher’s tables. Certain changes are made to the
script, including modifications of timestamp columns. After that we apply the
script on the subscriber. This can be done manually or as a pre-snapshot script
but either way it must bypass the normal, initialization-generated tables.
In the publication, the article properties for all tables are set to not
overwrite the existing tables created in the script above. After that
you’ll just need to manually modify any replication stored procedures on the
subscriber that apply to any timestamp
columns.
So, if all this seems really longwinded, it really is :), and it is therefore
prone to being set up incorrectly (this is perhaps the reason why 2 of the
implementations I’ve recently seen simply could never work after failover).
Setting it up in SQL Server 2005
What I was interested in was how have things improved for
SQL Server 2005 when using transactional replication for a failover solution.
Does the above document still hold. If not, are people still using an old
methodology when things could now be done more simply?
Consider Default Transactional Replication
If we replicate a set of tables containing the usual PKs,
FKs, defaults, check constraints, indexes etc what is taken and what is left
behind when using SQL 2005?
Largely this is much the same as SQL 2000 – the defaults are left behind as are
the check constraints and FKs.
However there are 2 interesting changes, the first of which is crucial:
- the Identity attribute is modified to NFR on the
publisher if not already NFR, and is
implemented as an identity column (NFR) on the subscriber. Remember, in
SQL 2000 this would have been without the identity property.
- the Primary keys remain as PKs on the subscriber,
rather than being changed to unique indexes.
So, the schemas of the publisher and subscriber are already converging, without
any manual changes having yet being made. How can we force the schemas to converge
further without resorting to editing scripts? The remaining configuration is set
on the article properties dialog box (below).
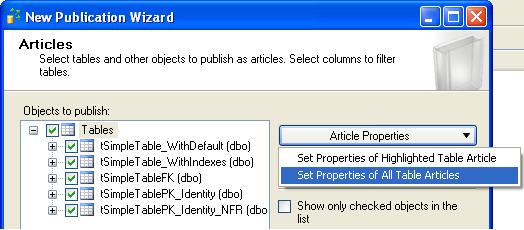
In the Article properties dialog above we see there is a massive advantage – we can set the
properties collectively for a set of tables rather than one by one in SQL 2000.
The actual properties themselves are shown below:
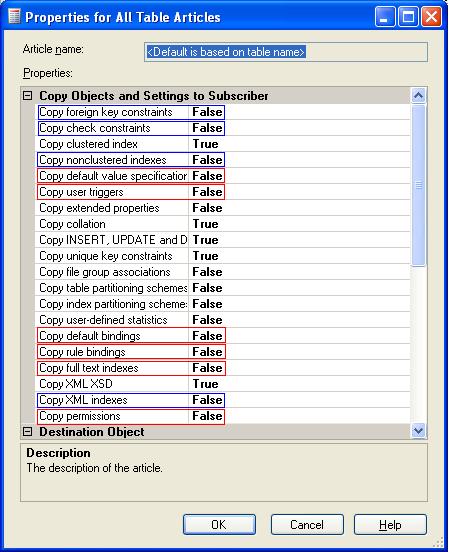
The properties in red have defaults values which need
changing for our purposes and are the "crucial" ones, while the ones in blue are
potentially less critical depending on your requirements. The simplest method is
to set them all to true. After setting these properties appropriately by reversing the
ones in red and blue I use
SQLCompare and find that apart from some inconsequential changes (eg the
foreign keys are marked as WITH NOCHECK) my subscriber schema is identical to
the publisher.
In the Additional Options section below we see that even the problem of
timestamps is automatically taken care of.
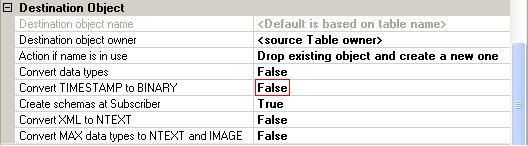
The default of “Convert timestamp to binary” is set to
false. At first I thought that some fundamental change had occurred and
timestamps were now allowed to be assigned directly on the subscriber. Looking
at the replicated timestamp data and the insert stored procedure I see that the
mechanism chosen is to allow the subscriber to select its own timestamp value
and not to try to keep it in sync with the publisher ie it isn't really
replicated at all. Obviously this leads to non-convergence of data and if later
on you are using
DataCompare or some equivalent tool you must be aware that this
column will need omitting to have a useful comparison of data.
Summary
So, by setting the properties of the table articles
appropriately we can use transactional replication in SQL Server 2005 as a DR
solution without resorting to manual table scripting and stored procedure
modifications. This is good news - it can all now be implemented much more
simply than with SQL 2000 and is therefore less prone to errors.
Article by Paul Ibison,
