

Introduction
Counting. It's a simple but very powerful tool in the proverbial toolbox of many an SQL Ninja. There are many advanced methods that use, nay, depend on the simple act of counting. For example, you can "quickly" build a list of dates for an entire year simply by counting from 0 to the number of days in the year minus one and then adding the resulting list of numbers to a starting date. Why would you do such a thing? Perhaps it is so you can join to the full year's worth of dates to produce daily totals and successfully display the total for days with no data as "0" for a report. Perhaps it's to produce a list of days and "next days" to make aggregation by day a lot easier and quicker. Perhaps it's to find weekdays in the absence of a Calendar Table. There are many possibilities.
If you go back and read the paragraph above, the word "quickly" has been braced in quotes because it's not always done quickly. Judging from many of the posts on this and other SQL forums, more and more well meaning folks are counting with Recursive CTE's because they're relatively simple to write and don't require such things as a Tally table to drive them. They have no idea of the performance problem they've just instantiated with their code nor do the people who pick up on the technique. It's becoming a nearly viral problem.
The purpose of this article is to demonstrate why counting with Recursive CTE's is such a bad idea and 3 ways you can quickly (and I do mean quickly, this time) get around the Hidden RBAR1 associated with the simple act of using Recursive CTE's to count.
What is a "Recursive CTE"?
From here forward, I'll simply refer to a "Recursive CTE" as an "rCTE" (pronounced "ar-see-tee-e"). For those of you who already know what an rCTE is, you still might want to read this section because we have a couple of surprises coming up.
The best way to show you what an rCTE is, is to show you one in action. We'll keep this real simple to start with. Suppose someone wants to create a list of the dates for the first of the month for every month in the year 2011. The obvious answer to how to do that, in all cases, is to produce a list of sequential numbers from 0 to 11 and then add those values as months to a given start date which, of course, would be 1 January, 2011 in this case.
A Simple Counting Solution
Hopefully, by now, everyone knows how bad the performance and how complicated the code for a While Loop to do this would be, so we'll not cover that method. A lot of other people have come to the same conclusion. "No RBAR1" is their mantra, and that's a good thing. Instead, they turn to the very clever rCTE because it's easy to write and it doesn't contain an explicit loop like a While Loop does. So, they write...
WITH
cteCounter AS
(--==== Counter rCTE counts from 0 to 11
SELECT 0 AS N --This provides the starting point (anchor) of zero
UNION ALL
SELECT N + 1 --This is the recursive part
FROM cteCounter
WHERE N < 11
)--==== Add the counter value to a start date and you get multiple dates
SELECT StartOfMonth = DATEADD(mm,N,'2011')
FROM cteCounter
;
... and that's NOT a good thing as you'll soon see.
The Parts of a Counter rCTE
For "counter" rCTE's like the one above, the "anchor" is usually a single SELECT of a starting point and the SELECT has no FROM clause. It simply selects either a constant or a value from a variable, which contains the starting value. Simple enough, so far, eh? (Sorry... I live in Michigan and a couple of the dust bunnies in my home-office are Canadian. I promised them I'd say "eh" at least once in this article. ;-))
The "anchor" SELECT is then UNION ALL'd with what is known as the "recursive" part of the rCTE. If you look closely, the thing that makes it recursive is the fact that it calls itself (the rCTE, that is) in the FROM clause. In theory, rCTE's would run forever except for two things. One would be the default limit on such recursive structures being 100. If the query above didn't have the WHERE clause, it would "iterate" 100 times and then fail with a "recursive limit" failure.
Obviously, the other thing that stops the recursion is the WHERE clause. The WHERE clause acts like the WHILE statement in a loop in that that's where the "recursive limit" is defined just like the "iteration limit" in a While loop is defined.
How the Counter rCTE Works
The basic, non-technical, non-scientific explanation for the operation of the code above would be this...
- The "anchor" value is set to "0" (zero). This now means the rCTE has a row with a zero in it.
- The recursive part takes over. It looks at itself and says "What's the last value that I put into myself?", does a SELECT to add 1 to that value, and then checks the predicate in the WHERE clause.
- If the value that was just made is within the limits defined by the WHERE clause, the rCTE saves that value in itself and then it loops back to Step 2
- The process continues to re-iterate through the loop formed by Steps 2 and 3 until the value being built (N+1) exceeds the limits of the WHERE clause. Once that happens, the rCTE exits to the SELECT (or other) statement that immediately follows the rCTE.
Notice some of the highlighting I made in the steps above where we're talking about the rCTE having rows in it and saving to itself. Does it really do that? You bet it does. If we SET STATISTICS IO ON, we get the following result for the code above...
(12 row(s) affected)
Table 'Worktable'. Scan count 2, logical reads 73, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
See that "Worktable" in the stats above? That's a temporary table formed in TempDB where the rows formed by the rCTE are stored until the complete result set is formed and can be returned by the final SELECT.
To be sure, here's how MSDN ( http://msdn.microsoft.com/en-us/library/ms186243.aspx ) defines an rCTE:
"A common table expression (CTE) provides the significant advantage of being able to reference itself, thereby creating a recursive CTE. A recursive CTE is one in which an initial CTE is repeatedly executed to return subsets of data until the complete result set is obtained." (yes, the highlighting is mine...)
Hmmmm... "repeatedly executed"... "return subsets"... "until the complete result set is obtained". I don't know about you but that sounds just exactly like what a While Loop writing to a Temp Table would look like if it were written for the same problem. In fact, looking back at the number of reads produced when STATISTICS IO was set to on, it's actually a bit worse than a While Loop. As my good friend and resident System DBA, Paul Herbert would say, "Really? 73 reads... to make 12 rows? Really???"
To make matters worse, rCTE's only "cost out" the first iteration in Estimated or Actual Execution plans and that makes them look faster than any set-based code even though they can be horribly slow, as in this case. That's probably how the rumor that rCTE's are fast got started.
Nah... Microsoft wouldn't do THAT to us, would they? Heh, yes they would and REALLY! So what's the damage done?
The Performance Hit of a Counting rCTE
Take a look at the following chart:
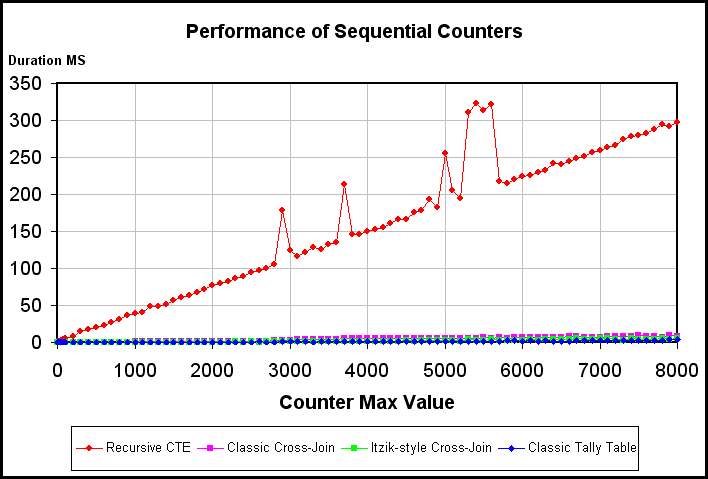
The chart above shows 4 different methods for counting from 1 to some number up to 8000. The painfully obvious loser in this race is the rCTE (the Red line). The "bumps" in the line show something else that I never expected; rCTE's are very sensitive to other things going on in the system (these charts are an average of 4 runs so you know the "bumps" were bad!). I had nothing loaded other than SSMS when I ran these tests and I had turned off my Internet connection to make sure my virus scanner didn't try to do an auto-update, etc. The "bumps" in the line you see are because of the "heartbeat" you can see on my system that uses about 10% of the CPU about every 6 seconds for just an instant or two.
Where are the other 3 lines on this chart for the other 3 tests? Take a look at the multi-colored clutter at the bottom of the chart. That's them and that's how comparatively fast they are. You can see how fast they are in the following chart where I changed the maximum "Y" axis value to display their true worth.
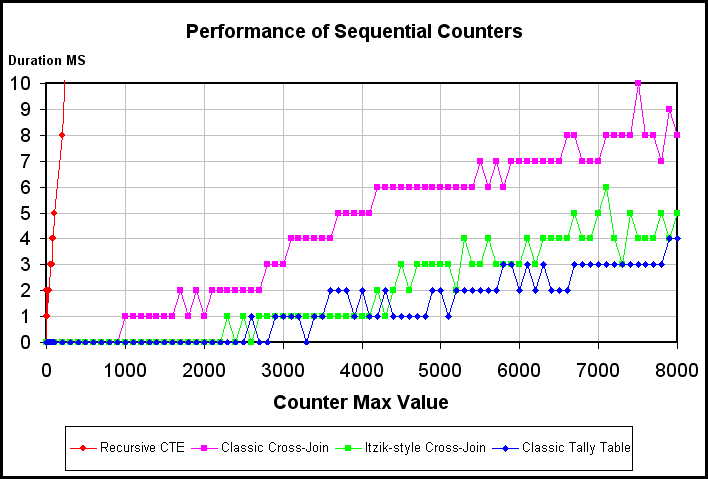
As a bit of a sidebar, notice that the "Classic Tally Table" and the "Itzik-Style Cross Join" methods are pretty much neck-and-neck until after the counter value of about 4,000 in the chart above. Then, it looks like the Tally Table starts winning. That's just for simple counting. Be advised that the Itzik-Style method will sometimes outstrip the Tally Table method depending on what the problem being solved is because actual data from the Tally Table has to "move". Everything in the Itzik-Style is basically "in memory" which can make it a bit faster than the Tally Table, at times. In true "IT" fashion, "It Depends"!
Some of that looks pretty bad until you realize that the maximum value on the "Y" axis is set to only 10ms. If you look to the left of the chart, that Red "sky-rocket" is the rCTE. It gets pretty bad really quickly. In fact, I recently had someone try to justify using counting rCTE's if they only had a few counts so let me show you just how quickly things get bad by showing you the same data but zoomed in so the "X" axis only goes up to a count of 100.
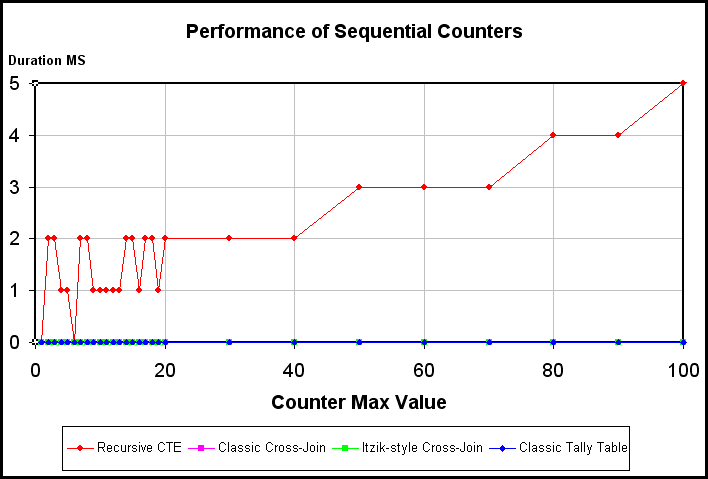
Ok... let's put this into terms that everyone can understand. At a count of 5, the rCTE is more than 200% slower than the other methods. At a count of 8,000, the rCTE is about 3,300% slower than the slowest of the other 3 methods.
What About the Reads?
You've just got to see this, folks...
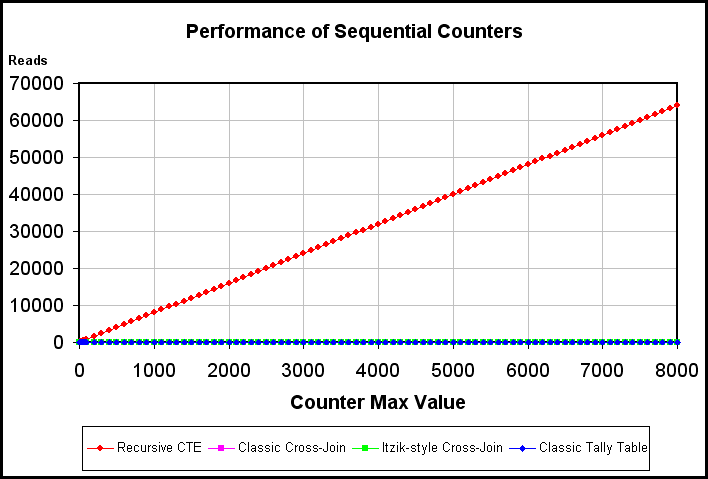
Well, at least it's not as bad a "Triangular Join". Still, more than 64,000 reads to build a lowly 8,000 rows? Seriously? C'mon...
Again, the other 3 methods are shown as the blob of color very close to the zero line in the chart above. The largest number of reads by any of the 3 methods at count of 8,000 is only 110 reads.
All right... let's shift gears for a minute. It's time to talk about things that are a whole lot faster.
Definition of a "Pseudo Cursor"
If you've been an active reader of the SQLServerCentral forums long enough, then you probably know a very well spoken gentleman by the name of R. Barry Young. Barry coined the term "Pseudo Cursor". So what is a "Pseudo Cursor"?
How a "Pseudo Cursor" Works
A "Pseudo Cursor" is nothing more than what I used to call a "set based loop". Yeah, I know. That doesn't say much so bear with me for just a minute. I'm going to set the stage with some absolutely mind-numbing, stupid-simple code and ask what seem to be some really dumb questions (I taught the dust bunnies how to code this way ;-)). I want you to see just how simple the concept of "Pseudo Cursors" really is.
What does the following code do?
SELECT *
FROM dbo.SomeTable;
Heh...yeah... Because of the SELECT *, it violates at least one best practice but that's not what I'm after. Yes, it returns all columns. Forget about that. Since it doesn't have a WHERE clause, what else does it do?
Absolutely correct! It returns all of the rows in the table.
Let's try something just a little more difficult. If "SomeTable" contains precisely 4,000 rows, what does the following code do?
SELECT 1
FROM dbo.SomeTable;
Correct! It returns precisely 4,000 ones. See how easy this is?
One of the things I really want you to notice in the code above is that it didn't use even a single bit of data from the table. It did, however, use the "presence" of rows from the table. It returned one "1" for every row in the table. We simply used the rows in the table as a "Row Source" to drive our "Pseudo Cursor".
Ok... just a bit more difficult... If "SomeTable" contains precisely 4,000 rows, what does the following code do?
SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM dbo.SomeTable;
Don't let the "SELECT NULL" throw you. We can't order by a constant in ROW_NUMBER() and ROW_NUMBER() won't work without the ORDER BY clause. Since we don't actually care what's in the table, we use "(SELECT NULL)" to get around both requirements. We just want to use the "Psuedo Cursor" formed by the SELECT as a "Row Source". So, just like the "SELECT 1" code, this will also return 4,000 rows. Because of ROW_NUMBER(), what else will it do?
See? You folks are brilliant! It will, of course, return sequential numbers from 1 to 4,000. We counted from 1 to 4,000 just as if we had a Cursor and/or While Loop running but we only used the "presence" of rows to drive our code. That's the basis of what a "Pseudo Cursor" is. It works like a cursor but it's not a cursor (or WHILE loop). And, just in case I just confused you, a lot of us call anything with a loop in it a "cursor".
Classic Cross-Join Pseudo Cursor Counter
Ok... we're in the 7th inning stretch. If "SomeTable" has precisely 4,000 rows in it, what does the following code do?
SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM dbo.SomeTable st1
CROSS JOIN dbo.SomeTable st2;
See how easy this is? You're absolutely correct. A Cross-Join will return all the rows in the "Right" table for every row in the "Left" table forming a "Cartesian Product". Since both tables are the same table and that table has 4,000 rows in it, our Cross-Joined Pseudo Cursor will return 4,000 * 4,000 rows for a count of 1 to 16 MILLION!
Classic Tally Table Counter
Ok. Final easy question. What does the following code do?
SELECT t.N
FROM dbo.Tally t
WHERE t.N BETWEEN 1 AND 4000
;
If you don't know what a "Tally" table is, then it's time to learn because it's a very, very important tool. Please see the article at the following URL to learn what a Tally Table is and how it can be used to replace a WHILE loop and other forms of RBAR.
http://www.sqlservercentral.com/articles/T-SQL/62867/
To be brief (you should still read the article at the above link), a Tally Table is nothing more than a very well indexed single column of sequential numbers usually beginning at 0 or 1 and ending at some reasonable finite number. My Tally Table usually ends at 11,000 so it's big enough to cover a counter for each character in a VARCHAR(8000) for splits, but it'll also generate 1 count for each day in more than 30 years.
Anyway, the answer to that last question is that the code will produce a count of 1 to 4000. Even though it's using something from a table, it's still considered to be a Pseudo Cursor... just like any SELECT can be.
Itzik-Style Cross-Join
Ready for a more difficult question? What does the following code do?
WITH
E1(N) AS (
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
), -- 1*10^1 or 10 rows
E2(N) AS (SELECT 1 FROM E1 a, E1 b), -- 1*10^2 or 100 rows
E4(N) AS (SELECT 1 FROM E2 a, E2 b), -- 1*10^4 or 10,000 rows
E8(N) AS (SELECT 1 FROM E4 a, E4 b) -- 1*10^8 or 100,000,000 rows
SELECT TOP (4000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E8
;
You can probably guess what it does just by looking at the last line. It counts from 1 to 4000.
Now, for the difficult question. How does it work? The answer is surprising simple.
The CTE called "E1" (as in 10E1 for scientific notation) is nothing more than ten SELECT 1's returned as a single result set because of UNION ALL.
"E2" does a CROSS JOIN of "E1" with itself. That returns a single result set of 10*10 or up to 100 rows. I say "up to" because if the TOP function is 100 or less, the CTE's are "smart" enough to know that it doesn't actually need to go any further and "E4" and "E8" won't even come into play. If the TOP has a value of less than 100, not all 100 rows that "E2" is capable of making will be made. It'll always make just enough according to the TOP function.
You can follow from there. "E4" is a CROSS JOIN of E2 and will make up to 100*100 or 10,000 rows and "E8" is a CROSS JOIN of "E4" which will make more rows than most people will ever need. If you do need more, then just add an "E16" as a CROSS JOIN of "E8" and change the final FROM clause to "FROM E16".
What's really amazing about this bad-boy is that is produces ZERO READS. Absolutely none, nada, nil.
And, yes... it's also a Pseudo Cursor just like the "Classic Cross Join" and "Classic Tally Table" methods. The one thing that it is not, is a Recursive CTE. It's a "CROSS JOINED Cascaded CTE" result set and except for the underlying machine-language-level loops that power it and all other Pseudo Cursors, there's absolutely no recursion in it.
Testing on Your Own
If you're interested in how I ran the performance tests, I've attached the code for the tests. I had SQL Profiler running at the statement level and captured the "Big 5"... Duration (in micro-seconds), CPU, Reads, Writes, and Rowcounts. I saved the trace as a Profile Table, ran a piece of code to pluck out, average, and pivot the important parts, imported the data into Excel, and charted the attribute (Duration in MS and Reads).
A "Rosetta Stone"
Just in case you don't know what a "Rosetta Stone" is, please see the following link. (I used something similar to learn how to talk to the dust bunnies in my home office. It was well worth the effort because they taught me how to make beer popsicles ;-))
http://en.wikipedia.org/wiki/Rosetta_Stone
Our "Rosetta Stone" will be in code. In case you haven't looked at the test code I attached to this article, let's solve the problem of producing 10 years of days starting in the year 2000 along with a "NextDay" column using all 4 methods we've talked about just to see how we can implement the methods and how they compare. (Heh... I WIN! The dust bunnies bet me I couldn't make 3 sentences in this article that MS Word labeled as "Long Sentence" and still have them make sense. It's their turn to make the beer popsicles. ;-))
--===== Declare and preset some obviously named variables
DECLARE @StartYear DATETIME,
@Years INT,
@Days INT
;
SELECT @StartYear = '2000',
@Years = 10,
@Days = DATEDIFF(dd,@StartYear,DATEADD(yy,@Years+1,@StartYear))
;
--=======================================================================================
-- Demonstrate the Recursive CTE. Don't ever use this method in production.
-- It's just too bloody slow compared to simpler methods.
--=======================================================================================
WITH --===== Recursive CTE
cteTally AS --("Tally" is another name for counting things)
( --=== Counter rCTE counts from 0 to the number of days needed
SELECT 0 AS N --This provides the starting point (anchor) of zero
UNION ALL
SELECT N + 1 --This is the recursive part
FROM cteTally
WHERE N < @Days - 1
) --=== Add the counter value to a start date and you get multiple dates
SELECT WholeDate = DATEADD(dd,N ,@StartYear),
NextDate = DATEADD(dd,N+1,@StartYear)
FROM cteTally
ORDER BY N
OPTION (MAXRECURSION 11000) --Needed more than the default of 100
;
--=======================================================================================
-- Demonstrate the Classic Cross Join method.
--=======================================================================================
WITH --===== Classic Cross Join method
cteTally AS
( --=== Pseudo Cursor counts from 0 to the number of days needed
SELECT TOP (@Days)
N = ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) -1
FROM sys.all_columns st1
CROSS JOIN sys.all_columns st2
)--==== Add the counter value to a start date and you get multiple dates
SELECT WholeDate = DATEADD(dd,N ,@StartYear),
NextDate = DATEADD(dd,N+1,@StartYear)
FROM cteTally
;
--=======================================================================================
-- Demonstrate the Classic Tally Table method.
-- Ya just gotta love the simplicity of this code.
--=======================================================================================
SELECT --===== Classic Tally Table method
WholeDate = DATEADD(dd,N-1,@StartYear),
NextDate = DATEADD(dd,N ,@StartYear)
FROM dbo.Tally
WHERE N BETWEEN 1 AND @Days
ORDER BY N
;
--=======================================================================================
-- Demonstrate the Itzik-Style CROSS JOIN method.
-- The code is a bit complex but you could turn the CTE's into an iTVF
-- ("iTVF" = "Inline Table Valued Function")
--=======================================================================================
WITH --===== Itzik-Style CROSS JOIN counts from 1 to the number of days needed
E1(N) AS (
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
), -- 1*10^1 or 10 rows
E2(N) AS (SELECT 1 FROM E1 a, E1 b), -- 1*10^2 or 100 rows
E4(N) AS (SELECT 1 FROM E2 a, E2 b), -- 1*10^4 or 10,000 rows
E8(N) AS (SELECT 1 FROM E4 a, E4 b), -- 1*10^8 or 100,000,000 rows
cteTally(N) AS (SELECT TOP (@Days) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E8)
SELECT WholeDate = DATEADD(dd,N-1,@StartYear),
NextDate = DATEADD(dd,N ,@StartYear)
FROM cteTally
;
Here's the SQL Profiler output (see next graphic) for a typical run. The rows above the "Trace Pause" have the output going to the "Great Duration Equalizer", the screen. The rows below the "Trace Pause" have had the output discarded and you can see just how fast the 3 fast methods are compared to the rCTE.
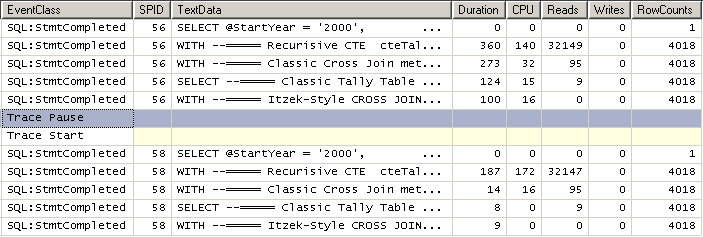
In this case, even the slowest of the 3 Pseudo Cursor methods is still more than 12 times faster than the rCTE method. In terms meant to impress, that's more than 1,200% faster. BWAA-HAAA!!!! Bosses always like to hear the BIG numbers when you tell them how much you've improved the code. 😉
Conclusion
If it wasn't already known, we learned that counting is important to many advanced techniques in T-SQL. We also learned 4 different ways (there are others, as well) of counting. Hopefully, we've also learned that using an rCTE shouldn't be one of the ways to count because it's relatively slow (200% to 3,300% slower) than 3 other very simple methods of counting.
We also learned that the 3 faster methods of counting in this article use a thing that R. Barry Young coined a phrase for... "Pseudo Cursors". To summarize, Pseudo Cursors use the "presence" of rows and the very high speed machine-language-level loops behind simple SELECT's to drive counting processes at blinding speeds.
As a couple of sidebars, we've also learned that you must take display time out of the picture when testing performance and that dust bunnies know the secret formula for making beer popsicles. 😉
Thanks for listening, folks.
--Jeff Moden
1 "RBAR is pronounced "ree-bar" and is a "Modenism" for "Row-By-Agonizing-Row"
