

This is the first article in what I hope will be a series on leveraging the rich and varied metadata available to us in SQL Server for automating common operations.
There are times when working with data in SQL Server when temporarily disabling indexes can result in much better performance. Two prime examples of this would be:
- performing purges of historical data from large tables
- bulk insertion of data.
The first one is quite easy to witness. All we need to do is pick a large table that has a number of indexes on it, write a simple "DELETE TOP (100000) FROM table" statement, and grab the estimated execution plan from Management Studio. What you'll typically see is something like this:
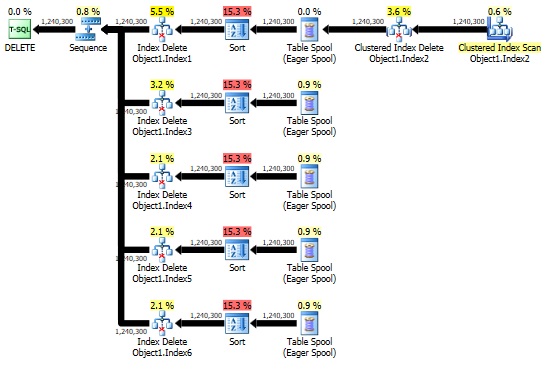
If we actually run the delete, we'll find that the amount of IO is quite high, as will be the amount of log records generated. Thus, in many cases, it is advantageous to first disable all but the clustered index (we don't want to do that, since "Disabling a clustered index on a table prevents access to the data").
Unfortunately a common pattern I've seen in code is that someone has scripted out individual drop statements of all the indexes on a table and pasted it into a related block of code (such as a purge procedure). This approach is wrong for a number of reasons, the biggest being that the code is expensive to maintain. Any time an index is added, removed, or modified, the code must be updated. Needless to say this can get tiresome, especially if this operation needs to be done in multiple places.
A much more flexible and resilient approach is to use the rich metadata exposed by SQL Server's system views to auto-generate commands to either disable or re-enable indexes on a particular table. This template driven approach can be generic enough to be used anywhere, so the code is written once and used many times. At the end I'll link to a complete stored procedure which can be used for this very purpose, but first let's walk through some of the steps involved, as well as some best practices.
First, how do we determine which indexes need to be disabled? Given and schema and table name, this is rather trivial. All we need to do is join a few system views together, specifically, sys.schemas, sys.objects, and sys.indexes.
SELECT
ssch.name AS schema_name,
sobj.name AS object_name,
sidx.name AS index_name
FROM
sys.schemas ssch join sys.objects sobj
on ssch.schema_id = sobj.schema_id
and ssch.name = 'dbo'
and (sobj.name = 'some table')
join sys.indexes sidx
on sobj.object_id = sidx.object_id;To exclude the clustered index, we simply add a filter to the join on sys.indexes for index_id > 1, since an index_id of 1 indicates a clustered index (an index_id of 0 would indicate a heap, which we obviously cannot disable).
We also want to exclude the primary key, as well as (at least as an option) any unique indexes. We can do this by excluding rows where the sys.indexes.is_primary_key column equals 1, or where the sys.indexes.is_unique column equals 1.
on sobj.object_id = sidx.object_id
and sidx.is_primary_key = 0 -- exclude primary keys
and sidx.is_unique = 0Better yet, we can allow the user to determine if they want to disable the unique indexes or not.
and sidx.is_unique = case when @i_Exclude_Unique_Fl = 1 then 0 else sidx.is_unique end -- exclude unique indexes
Now, we add a parameter so that we know if we’re trying to enable or disable indexes. It would be foolish to rebuild indexes which we have not disabled, nor would we want to attempt to disable indexes which are, well, already disabled! Again, we're trying to make this as flexible and resilient as possible. Fortunately this is easy enough, thanks to the "is_disabled" column of the sys.indexes view.
and sidx.is_disabled = case @i_EnableDisable_Fl
when 'E' then 1 -- only include disabled indexes when the "Enable" option is set
when 'D' then 0 -- only include enabled indexes when the "Disable" option is set
ENDFinally, we want to add two nice-to-have features: first, we want to give the ability to use online index rebuilds if the engine edition supports it (i.e. we're using SQL Developer Edition or Enterprise Edition), and we want to be able to specify a maximum degree of parallelism for the rebuild operation.
Putting all this together, and we can generate the actual ALTER INDEX statements easily, and either print them out or actually execute them (a not-for-real mode is an often overlooked but critical feature in my book).
The actual SQL that puts all these pieces together looks like this:
SELECT
'RAISERROR('
+ QUOTENAME(CASE @i_EnableDisable_Fl
WHEN 'E' THEN 'Enabling '
ELSE 'Disabling '
END + ' index ' + sidx.name + ' on table ' + ssch.name + '.' + sobj.name,
'''') + ',10,1) with nowait;'
+'ALTER INDEX '
+ quotename(sidx.name)
+ ' ON '
+ quotename(ssch.name)
+ '.' + quotename(sobj.name)
+ ' '
+ case @i_EnableDisable_Fl
when 'E' then 'REBUILD' + ' WITH (MAXDOP='+CASE
WHEN @i_MaxDOP IS NULL THEN convert(varchar,1)
ELSE convert(varchar,@i_MaxDOP)
END +
',ONLINE=' + CASE
WHEN (@i_Online = 1 AND SERVERPROPERTY('EngineEdition') = 3)
THEN 'ON'
ELSE 'OFF'
END +
')'
when 'D' then 'DISABLE'
END
+ ';'
FROM
sys.schemas ssch join sys.objects sobj
on ssch.schema_id = sobj.schema_id
and ssch.name = @i_Schema_Name
and (sobj.name = @i_Table_Name or @i_Table_Name = '')
join sys.indexes sidx
on sobj.object_id = sidx.object_id
and sidx.is_primary_key = 0 -- exclude primary keys
and sidx.is_unique = case when @i_Exclude_Unique_Fl = 1 then 0 else sidx.is_unique end -- exclude unique indexes
and sidx.index_id > 1 -- exclude clustered index and heap
and sidx.is_disabled = case @i_EnableDisable_Fl
when 'E' then 1 -- only include disabled indexes when the "Enable" option is set
when 'D' then 0 -- only include enabled indexes when the "Disable" option is set
ENDBecause sometimes we do things like bulk deletes by filtering on a column, we want to be able to specify that indexes having that column as the leading key are not disabled, thereby causing the purge operation to require a painful scan of the table.
WHERE
NOT EXISTS (
SELECT 1
FROM sys.index_columns ic JOIN sys.columns c
ON c.column_id = ic.column_id
AND c.object_id = ic.object_id
WHERE ic.index_id = sidx.index_id
AND ic.object_id = sidx.object_id
AND c.name = @i_Column_To_Exclude_Nm
AND ic.key_ordinal = 1
AND ic.is_included_column = 0Using the nifty trick of the FOR XML PATH clause, we can concatenate all the statements into one row, which we can then either print out or execute if we like.
Put these all together, and we now have a flexible, re-usable routine that is defined in one place and can be called from anywhere. We can even mark it as a system object in the ‘master’ database. Thereby allowing it to be called in the context of any database.
A word of caution though: don't take this operation lightly. Rebuilding indexes is a very costly bit of processing, and should always be tested prior to including in any batch process. There may well be times when the cost of rebuilding indexes does not outweigh the cost of maintaining them during bulk operations; caveat emptor is good advice in this case.
If you have ideas on how to improve this, let me know!

