

Introduction
Assume you have already made a decision to learn more about “Big Data”, and its common implementation on Hadoop ecosystem. You certainly may wonder how much of your SQL Server experience is relevant. The SQL language comes to mind initially because it is universal in the relational database world. So, setting aside the gory details of systems internals, how different are SQL implementations on Hadoop from Microsoft T-SQL?
This article explores the most popular SQL layers inside Hadoop ecosystem, their appropriate usage scenarios and highlights the most striking differences between Microsoft T-SQL and the SQL implementations that those layers employ.
It appears that a new “SQL over Hadoop” project is being released every month. So, which of the projects are in a high demand? Judging by the advertised “Data Engineer” job postings that reflect current demand in the high tech job market, Hive, ImpalaSQL, SparkSQL and Presto are the most popular among employers.
From the high level `SQL over Hadoop` implementations can be easily presented as stacks of technologies.
From Fig.1 you can see that each stack consists of an “SQL layer” on the top, a “Compute Engine” in the middle and an HDFS file system at the bottom. Here, each “Compute Engine” does heavy lifting behind the scenes by translating SQL commands into the language that is relevant to the engine programming. At the bottom, there is a common to each stack HDFS file system that stores our data in the form of the files.
In short, Hadoop SQL = “SQL layer” + “Compute Engine” + File system
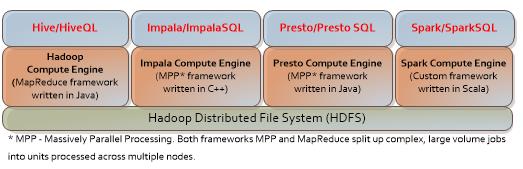
Fig. 1 The Hadoop ecosystem and its popular SQL engines.
Historically, SQL Server Analysis Services (SSAS) was the biggest contributor to data analysis software solutions , aggregating large amounts of data and producing reports.
However, the licensing cost of SQL Server and the deep learning curve of learning MDX (the query language for OLAP databases) present a significant challenge.
While working with large volumes of data, the activities can be broadly categorized as
- traditional Data Warehouse ETL queries,
- interactive, ad-hoc queries for quick analysis, and
- repetitive queries used for predictive analytics ( that is “machine learning”)
It is worth noting from the start, that Hadoop SQL implementations do not qualify as relational databases (RDBMS). One of the reasons: Unlike RDBMS, these implementations do not “own” underlying data which can be accessed and manipulated from the outside. (More differences are available here)
Some features of all “SQL on Hadoop” implementations, familiar to SQL developers, are:
- the presence of databases, tables and views,
- table partitioning (by directories, often by date … /year/month/day/hour …),
- support for SQL 2003-compliant analytic window functions (aggregation OVER PARTITION, RANK, LEAD, LAG, etc.), and
- support for query execution plans (the ordered set of steps used to access data in a SQL relational database management system)
Interesting limitations of Hadoop SQL layers:
- no referential integrity, NOT NULL or other column constraints (because they cannot be enforced – no one owns the data),
- no support for SQL stored procedures. Instead, similar functionality can be implemented by creation of User-Defined-Functions (UDF) using application programming languages such as Java and Python (the concept is similar to using CLR stored procedures in SQL Server)
Apache Hive and HiveQL
Hive is the original and the most common SQL implementation layer over Hadoop ecosystem. Hive defines a language called HiveQL, loosely modeled after MySQL flavor of SQL. HiveQL translates SQL-like queries into MapReduce jobs (a framework for processing and generating large data sets with a parallel, distributed algorithm on a cluster).
The intermediate results of MapReduce computations are stored on the disk, which makes HiveQL queries slower, but at the same time, resilient to failures. Since Hive is built on a MapReduce platform where everything is done in a bulk mode, it is good for the batch ETL processing but does not offer real-time queries.
HiveQL supports indexing and complex (i.e. non-atomic) data types such as arrays. Moreover, the latest version of Hive provides support for transactions and Insert/Update/Delete operations.
Impala and Presto
Both engines are designed for “interactive queries” (when you want to wait for your query result to come back before taking break) but not for long-running ETL processes.
Impala is a C++ based SQL engine (latest version is 2.1) that was built by Cloudera, one of the major commercial Hadoop distributors. Presto (latest version is 0.121) is a Java-based SQL engine that was developed by Facebook and recently started to get support from Teradata.
Both engines
- run in memory only (unlike Hive, which runs on both memory and disk), so their queries run much faster than Hive queries,
- are implemented via an MPP framework (Massively Parallel Processing, the type of computing that uses many separate CPUs with their own dedicated memory running in parallel to execute a single program). Microsoft uses the same framework for its Parallel Data Warehouse (PDW) which is part of its PolyBase technology ,
- provide ANSI-92 SQL syntax support but contain less SQL keywords than HiveQL,
- are capable of executing long-running HiveQL queries, and
- are not fault-tolerant (if your query fails you need to start over; the intermediate results are lost)
It is important to note that, running these processes in memory brings its own challenges. For example, only smaller datasets can be handled (hundreds of GB vs. terabytes with Hive).
The benchmark testing of Impala 2.0 with alternatives, including Presto, shows that Impala outperformed Presto in both single-user and multi-user loads (see Fig 2). The testing was performed by Impala engineers. [1]
Up until now it appeared that Presto was lagging significantly behind Impala in terms of the speed, references in the press and also documentation.
However, as Teradata threw its weight behind the Presto SQL engine, we may see a catch-up game between Presto and Impala and very soon.
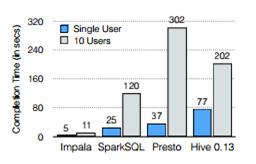
Fig. 2: Comparison of query response times. [1]
Apache SparkSQL
Apache Spark SQL uses a Spark computing engine and runs on a top of the Hadoop file system HDFS.
Spark data processing engine, built by UC Berkeley, is being heavily promoted by Databricks, its commercial parent company. Currently, Spark is the most talked-about SQL implementation.
Here are a few reasons for Spark being so popular:
- Speed - performance is comparable to ImpalaSQL.
- Use of abstractions, called “DataFrames” that function like a ” linked server” to a good number of data sources, including Hadoop and various RDBMS.
- It runs in memory with added fault tolerance.
Although the Spark engine runs in memory, it also saves intermediate results on a disk (“cache”). This cache is usable for future queries as well, making the queries to return results faster.
However, as Spark”s proponents explain [3], Spark SQL really shines in the area of predictive analytics (also known as machine learning - the process of repetitively running various statistical models on large sets of data).
Loved by “Data Scientists” (who often have a background in statistics) the Spark engine allows the use of familiar languages, such as R, Panda and Scala, and seamlessly incorporates SQL statements.
As noted above, the Spark engine supports a great number of data sources. That flexibility provides for the next great use case – ETL.
However, and unfortunately for SQL Server developers, Spark ETL scripts cannot be written entirely in SQL. Instead they must be written in Scala, Java or Python languages with incorporated SparkSQL snippets.
Conclusion
This article attempted to compare the most interesting SQL language features for the most popular “SQL on Hadoop” implementations.The SQL implantations were selected based on their popularity in currently posted “Data Engineer” advertisements.
In my view, T-SQL certainly remains a much richer language. Moreover, as T-SQL can be used for almost any task within SQL Server; there are cautionary notes to consider for each `SQL on Hadoop` implementation.
HiveQL is the best used within long running ETL scripts. Both ImpalaSQL and Presto SQL work well for high concurrency Business Intelligence (BI) style workloads (that is interactive queries). And SparkSQL is actually a developer tool for building machine learning applications with SQL constructs.
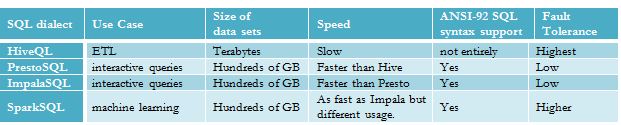
The following table compares and contrasts Hadoop SQL implementations.
References
[1] Impala: A Modern, Open-Source SQL Engine for Hadoop , January 2015
[2] Presto: Interacting with petabytes of data at Facebook , November 2013
[3] Spark SQL: Relational Data Processing in Spark , June 2015

