

Clustering as a technology
Clustering your SQL 2008 R2 Server is a great way to gain high availability for your environment. The benefits are simple and powerful; seamless fail over of your SQL Server and all services, within 30 seconds. However, clusters are costly compared to stand alone services. The hardware stack alone contains a shared storage, two or more servers, and additional networking infrastructure, not to mention the licensing costs.
Compared to other mainstream HA technologies for SQL Server, Microsoft clustering offers the best granularity due to its native integration with SQL Server. What do I mean by this? Well MS Clusters are able to integrate directly with SQL Server services, and they can detect an individual service failure and take action to remedy, something most other HA technologies will not do.
For example, if using hypervisor HA, the hypervisor will only Fail-over upon loss of the OS or connectivity, it would not for example, fail-over on loss of Transaction Coordinator service, as it does not monitor services within the OS. Loss of this service would stop external transactions being allowed to run against said SQL server, resulting in loss of service. This is a key point many overlook when considering your recovery point objectives.
So, good and bad news. Microsoft Clustering is one of the best HA solution's for SQL server, but its expensive compared to other mainstream HA technologies. But is that all we need to consider? It only things were so simple.
Clustering wasteful compared to virtualisation?
The IT industry has learned through virtualization to reduce server waste. The benefits are well documented and I really don't want to regurgitate them here. Typically, every server will comprise of a capital expenditure (CAPEx - the purchase of new server) and consume power, cooling and operation activities such as patching from an Operational budget (OPEx). CAPEx is a one-off payment for an asset (in this case a physical server), which usually depreciates off an organization's assets register and typically costs more during the lifetime of a server. OPEx is not a measurable asset to the company. This is why virtualisation has become so popular to IT Managers and Directors. Virtualisation reduces the operations budgets (non-asset) by reducing the footprint of the physical tin.
Clustering still (typically) has a "physical tin" redundancy overhead. A typical Active-Passive cluster will leave a server in the cluster that is not used until it's needed, consuming power and rack space, cooling etc. We have found clients are less inclined to choose a cluster because of the lessons they have learnt from the virtualisation argument. But as discussed above, Clustering can be a more robust solution. A difficult sell though when hit by the reduce redundancy overhead argument.
Planning for Failure
There are also more subtle points to consider when planning and implementing a clustered environment. We all heard the adage; a backup is only as good as its restore. Well, HA is only as good as the failure it resolves. A cluster is not an uber complex environment, but it is not a simple one either. If we look at a support aspect, a healthy working SQL server on a MS cluster requires a stable DNS, Active Directory, Distributed Transaction Coordinator, Network, Shared Storage to name but a few. Ok these are known quantities for most Operational IT departments, and operations usually have full control of these services. But there are also development / operational issues to think about.
Before we go into the Developer / Operational divide, let's take this up a notch and consider what applications databases will be hosted on this cluster? If we look at an application as a service, the database becomes a key part of most applications end to end solution. So how can clustering a SQL Server and its subsequent databases affect this?
Most main off shelf applications (SharePoint, Dynamics to name but a few) are very much "Cluster aware" applications. What does this mean? Well nothing more really than they have been tested and verified they work on a SQL Server which is in a cluster. The important piece of the puzzle being the how the fail-over event (if and when one occurs), affects the operation of the application end to end. Fail-over events lose their "session state" information. i.e. in memory operations not persisted to disk, logins, user connections - all will be lost.
SQL Server, due to its ACID-compliant transactional log, will take good care of rolling backward and forward in-flight transactions, so data loss is highly unlikely. However, to a poorly written application, a fail-over event could potentially be disastrous.
A common example: a database has a User table, storing login information. One of the key fields is a Login / logout date/time. During normal operation, a user will log into the application, run a few processes and then log out. During the login process, a check is made of last login and last logout dates, to see if the user is already logged in (to ensure people do not give out their usernames). If they are already logged in, raise an error and exit. When the user logs out, the field gets updated with logout time. Sounds reasonable?
In a fail-over event, all users would be disconnected from the database unexpectedly, as the database services fail over from one server to the other. The process that updates the logout time cannot run (the database is offline for 30 seconds while it is failing over). This leaves all the users who were logged into the application when the fail-over occurred unable to log back into the application once the database has come back on-line. Ouch!. Your very expensive HA solution has worked as expected, but poor planning and understanding of the application means it is pretty much for nothing. The recovery is flawed and users (who won't care anything about shiny SQL clusters, developer code and the like) are left unable to work.
So it is important to factor in a clustered environment when purchasing or developing applications which will have their databases hosted on a SQL cluster. We must consider how the application will perform on a fail-over event? Does the application recover successfully? It is all very well having a highly available database tier, but it is not worth anything to end users if the applications that use it do not work when required.
Developer / Operational divide
We are starting to understand the implications of implementing a SQL cluster, it is important to consider not only "hey I have a new HA, isn't it cool", but the recovery objectives and time for the applications that are serviced but a clustered database server. As already mentioned, most off-shelf products are mostly tested, if you're not sure, I am sure your vendor will be able to answer your questions on clustering the databases.
This doesn't solve the problem for applications developed in-house though. If you talk to your development team about clustering and how it will integrate with their "brilliant" application, they will typically give you the answer "we won't know until we test it on the cluster". Let's be honest, that's a fair point.
But we know clusters are expensive, is it feasible to purchase another set of shared storage, servers etc. etc. to ensure developers know how to build apps that are cluster savvy? Well yes it is! But more often than not, because of this cost barrier, Test, UAT and Development environments usually become a poor cousin to a production cluster and clusters purchased for testing and development don't happen.
Making the most of the cluster
Having planned and implemented numerous clustered environments for our clients, we wanted to look at how we can:
- Give development access to a cluster to test
- Not re-invest in new hardware
- Make use of redundant hardware within the cluster
- Not impact the live environment
During a recent project, we architected a 4 Node Active-Active-Active-Passive Cluster (see figure 1) which would replace their stand-alone servers. The project included an upgrade to SQL 2008 R2 and a move from 32bit to 64bit architecture. We encountered the issues discussed earlier during our design phase. The client wanted to be able to test their bespoke applications on the cluster without purchasing new hardware or compromising their production cluster. Additional to this, due to timeline and budget constraints we were struggling to find a suitable location to test applications against SQL 2008 R2.
After some consideration and a check with Microsoft Licensing, we proposed the Passive cluster Node Host a Developer Edition UAT Only instance of SQL server.
This would:
- Allow Development teams to test applications against a live cluster in a controlled instance of SQL Server on a typically non-production node.
- Make use of the passive node, reducing the redundancy overhead
- Because the project included an upgrade from SQL 2005 to SQL Server 2008, this also allowed us to test the migration of services prior to release.
The UAT instance was installed using SQL Server 2008 R2 Developer edition, which is has a minimal license overhead and seamlessly supports clustered environments, just like the Enterprise Edition of SQL server.
During normal operation, all production instances would be hosted on their active node. The UAT instance would be hosted on the Passive node, in this case NODE4. While the UAT instance was hosted on NODE4, any testing would be at low risk to the rest of the production environment. CPU, Memory are hosted on a different server to that of the production instances. Disk was provided by shared storage which also had separate raid LUNs, although very high throughput on the Shared storage may increase disk wait times if production disks are on same SAN due to bottleneck on backplane or Raid control cards.
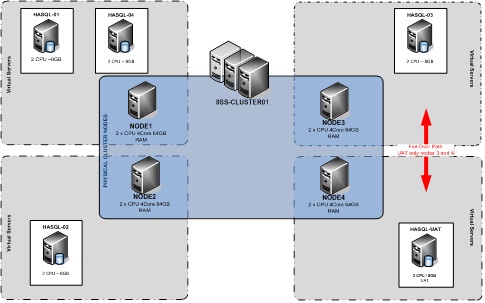
Figure 1 - 4 Node Cluster
To ensure the UAT instance would remain segregated from the rest of the cluster, the UAT instance had its "Automatic Fail-over" disabled. This prevented the UAT instance from being able to fail-over unexpectedly. As a backup, the preferred owners list were set to allow the UAT instance to only fail-over to preselected production nodes (red arrow on Figure 1). In a manual fail-over, the UAT instance would only fail-over to a preselected node as shown in Figure 2, in this case NODE3.
Testing of fail-overs was permitted by operations only, under strict change control. Access to the UAT instance was limited to development teams, but they could investigate enough to see how the application performed during a fail-over event.
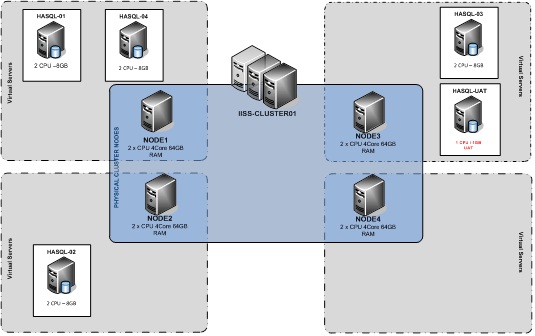
Figure 2 - Manual Fail-over
To safeguard UAT did not impact the performance of production services, the instance made use of the server configuration for memory and CPU. A startup script was applied to the instance which would detect if the instance was on a production node or on the passive node. If UAT was on the passive node the server config was changed to use half available CPU's and 8GB of physical memory (each node had 64GB). If not, then the server config restricted the UAT instance to use 1 CPU and 2 GB only of memory. This is shown in Figure 1 and Figure 2.
If a production fail-over were to occur, the instance hosted on the production node would fail-over to NODE4. The UAT instance would then be assessed and if required taken offline (see figure 3), allowing the passive node to function normally as a fail-over for production.
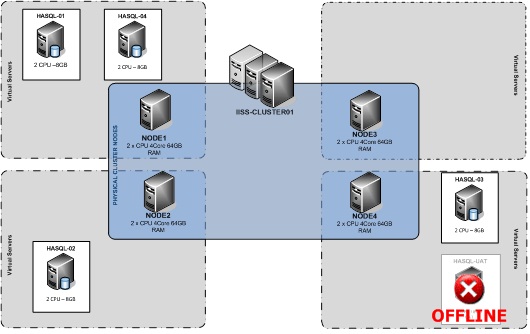
Figure 3 - Production Fail-over
Conclusion
This solution did have a win-win for the client. Their Development teams were happy that we had given them a sandbox for testing on a production cluster. The Operations staff were pleased they could control the management of this UAT instance, and management were happy we made use of what would typically be a redundant node, offsetting the cost of the OPEx and CAPEx expenditure to a new UAT environment.
So what did we learn from this? Clustering can be used to power not only your high availability requirements, but also elegantly facilitate your development and UAT requirement. With careful consideration and planning, clusters can become a flexible. Making the most of these environments is critical to achieving a good return on their investment, using them for UAT could just be one of those ways.

