

Hot discussion! Please view the discussion for this article after reading it.
This article attempts to demonstrate the use of XML support in SQL Server 2005, and its advantage over conventional data storage in terms of space and performance. Of course the solution is not completely generic, but it definitely would apply for quite a number of business scenarios.
Consider a scenario wherein you have hundreds of data points for one unique set of dimensions. Say for example, the dimensions are day (date) and location; and the data points are rainfall measurement taken regularly every hour of the day. So in a day for 100 locations we would have 100 * 24 = 2,400 data points. Another example would be exam questions and responses (data points) for a particular Candidate in a particular exam at a particular exam center (Dimensions). Say if you have 100 questions on an average in an exam, you would have 100 data points for each candidate for each test.
Here if each data point forms a record in the table, the table would be like a huge pile of records in just a few years. For the rainfall example, in just 1 year we would have 2400 * 365 = 876,000 records and in 5 years the record count would be 4,380,000. In another example, if we consider that there would be 100 Candidates taking test every day, we have 100 * 100 * 365 = 3,650,000 records in just 1 year. Sure we have options like partitioning and archival (at administration level), but ultimately the space usage is high and we also may have scenarios where we may require to keep all the data online for ready access. Moreover we can still discuss about options at development level (say within a partition itself).
Now let me mention the design solution in this article applies to a certain criteria that defines how the data points are used in real life. Firstly these scenarios are common to an OLTP database and we are trying to scale an OLTP database all right. Secondly, this kind of data is usually Read-only once it gets uploaded into the database. Thirdly most of the time the complete dataset is retrieved and kept in memory instead of hitting the database every time for individual data points.
Consider the example of rainfall data. The user would first select the location and then date for which rainfall data is required. He would then get to see the complete hourly rainfall data for that day. The user is very rarely going to manipulate that data (of course we would have to provide for this even if it is rare). This kind of data also is not uploaded or entered manually for each data point. There would more commonly be an import process in place which would import the complete data set from some data source (such as flat file) for a particular unique set of dimensions. And then there also might be an export process which exports the complete dataset to a flat file or some other OLAP system.
Of course there might be and definitely would be a requirement to access individual data points for analysis purposes. Say for example the user requires finding out how different candidates failed for one particular question in a test or it may be required to find out the rainfall at different locations on the same day and same hour. In that case, the individual data point for that particular question would be required for all candidates. The only point is that these process would be much less frequent compared to the process of accessing all data points in a set.
Good! So we have the requirements defined and in fact one conventional solution approach is also mentioned. But our main issue is the growing record count with time which would ultimately affect read performance and also write performance if the table has constraints.
Now how would it do if we have the complete dataset (for each unique set of dimensions) in one single record and that dataset is perfectly parse-able? You can dig down to each individual atomic data point within SQL Server itself and that too without having to write custom procedures for parsing the set. We sure would look at the implementation, but first let's have a look at the number of records we are going to save in each of our example:
- Rainfall example: The number of records in a day for 100 locations would be just 100 and in a year would be 36,500 (i.e. just 4.2% of 876,000).
- Exam example: The number of records in a day for 100 Candidates would be just 100 and in a year would be 36,500 (i.e. just 1% of 3,650,000)
Obviously, from the topic itself you'd have guessed how we are going to accommodate the dataset in a single record. SQL Server 2005 provides wonderful support for XML and has, as we can realize, opened a whole new world of data storage options to us.
Let's say following is the format for storing Rainfall data for a combination of Location and Date:
<RT><RN H="0" V="2.3"/> <RN H="1" V="2.5"/> <RN H="2" V="0.3"/>........</RT>
Where H is the hour and V is the rainfall value
The format for storing Candidate's questions and responses for a combination of Candidate Registration ID and Exam ID:
<ROOT>< DATA Q="1" R="2"/>.....</ROOT>
Where Q is the Question ID and R is the Response ID (Objective questions).
Let's try to generate a year size of data first. Following is the script to generate the rainfall data for the year 2008. The script makes use of rand () function to generate arbitrary rainfall values between 1 and 10. We would have 2 tables which would store the same data but in different formats.
RAINFALL_CON is the table storing the data in conventional format, 1 record for each data point and RAINFALL_XML is the table storing data points in XML format. The RAINFALL_XML table here is actually populated from RAINFALL_CON table, but in real scenario the data would come directly from the user application in XML format.
-- Create the conventional table
CREATE TABLE Rainfall_Con
(LocID int
,Date datetime
,Hour tinyint
,Rainfall numeric(10,8)
,CONSTRAINT PK_Rainfall_Con PRIMARY KEY NONCLUSTERED(LocID,Date,[Hour])
)
-- Populate the conventional table with an years data for 100 locations
SET NOCOUNT ON
DECLARE @LocID int,@Date datetime,@Hour tinyint
SELECT @Date = '20080101'
WHILE @Date <= '20081231'
BEGIN
SELECT @LocID = 1
WHILE @LocID < 101
BEGIN
SELECT @Hour = 1
WHILE @Hour < 25
BEGIN
INSERT Rainfall_Con
SELECT @LocID,convert(varchar(20),@Date,112),@Hour,rand() * 10
SELECT @Hour = @Hour + 1
END
SELECT @LocID = @LocID + 1
END
SELECT @Date = @Date + 1
END
-- In all 878,400 records inserted into the table
-- Create the XML table
CREATE TABLE Rainfall_XML
(LocID int
,Date datetime
,Rainfall xml
,CONSTRAINT PK_Rainfall_XML PRIMARY KEY NONCLUSTERED(LocID,Date)
)
-- Populate the XML table from the conventional table
INSERT Rainfall_XML
SELECT LocID,Date,(SELECT [Hour] AS H,Rainfall AS V FROM Rainfall_Con A
WHERE A.LocID = B.LocID AND A.Date = B.Date
FOR XML RAW('RN'),ROOT('RT')
)
FROM Rainfall_Con B
GROUP BY LocID,Date
-- In all 36,600 records inserted into the table
RAINFALL_CON table will have 878,400 records (366 days) while RAINFALL_XML table will have 36600 records.
Now let's have a look at the space usage of these tables:
exec sp_spaceused Rainfall_XML,true
exec sp_spaceused Rainfall_Con,true
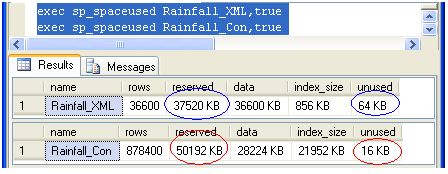
RAINFALL_CON as a whole takes around 13 MB more space than the XML table.
Please change the year part in the population script if data for multiple years is required. The below results are obtained after populating the tables with 3 years of data (2008, 2007 and 2006). That would be 109,600 records in RAINFALL_XML table and 2,630,400 records in RAINFALL_CON table.
Now let's have a look whether this format caters to our requirements:
1. Display Rainfall for a particular location for a particular day
SELECT TP.LocID
,TP.Date
,T.Item.value('./@H','tinyint') AS Hour
,T.Item.value('./@V','numeric(10,8)') AS Rainfall
FROM Rainfall_XML TP
CROSS APPLY Rainfall.nodes('/RT/RN') AS T(Item)
WHERE TP.LocID = 1 AND TP.Date = '20080106'
-- (24 row(s) affected)
2. Display Rainfall for a particular location for a particular day for a particular hour (e.g. 1500 hours)
SELECT TP.LocID
,TP.Date
,Rainfall.value('(/RT/RN[@H=15]/@H)[1]','tinyint') AS Hour
,Rainfall.value('(/RT/RN[@H=15]/@V)[1]','numeric(10,8)') AS Rainfall
FROM Rainfall_XML TP
WHERE TP.LocID = 1 AND TP.Date = '20080106'
--(1 row(s) affected)
3. Display Rainfall for a all locations for a particular day for a particular hour (e.g. 1500 hours)
SELECT TP.LocID
,TP.Date
,Rainfall.value('(/RT/RN[@H=15]/@H)[1]','tinyint') AS Hour
,Rainfall.value('(/RT/RN[@H=15]/@V)[1]','numeric(10,8)') AS Rainfall
FROM Rainfall_XML TP
WHERE TP.Date = '20080106'
ORDER BY LocID
-- (100 row(s) affected) in 1 second
Compare the performance of this query to the following query on conventional table to retrieve the same kind of data. (Don't forget to clear the cache before executing each query?):
SELECT TP.LocID
,TP.Date
,TP.Hour
,TP.Rainfall
FROM Rainfall_con TP
WHERE TP.Date = '20080106' AND TP.Hour = 15
ORDER BY LocID
-- (100 row(s) affected) in 10 seconds
The query to retrieve data from XML table turns out to be faster. Using the above script I populated the tables with 3 years of data (2008, 2007 and 2006). The query on XML table still took 1 second to retrieve the same data while the query on the conventional table required 9 seconds to give out the same data.
The query plans for the queries are attached. Con_AllLoc_PerDayHour.sqlplan (conventional) indicates more cost on Index scan of the table which is going to get slower with increasing data.
Same is the case for query to retrieve rainfall for all days for one particular location for one particular hour. Here are the queries
XML:
SELECT TP.LocID
,TP.Date
,Rainfall.value('(/RT/RN[@H=15]/@H)[1]','tinyint') AS Hour
,Rainfall.value('(/RT/RN[@H=15]/@V)[1]','numeric(10,8)') AS Rainfall
FROM Rainfall_XML TP
WHERE TP.LocID = 1 --AND TP.Hour = 15
ORDER BY TP.Date
--(1096 row(s) affected) in 2 seconds
Standard:
SELECT TP.LocID
,TP.Date
,TP.Hour
,TP.Rainfall
FROM Rainfall_con TP
WHERE TP.LocID = 1 AND TP.Hour = 15
ORDER BY TP.Date
--(1096 row(s) affected) in 4 seconds
4. Update rainfall for a particular location for a particular day for a particular hour (e.g. 2000 hours)
UPDATE TP SET Rainfall.modify('
replace value of (/RT/RN[@H="20"]/@V)[1]
with "8.12345678" ')
FROM Rainfall_XML TP
WHERE TP.LocID = 1 AND TP.Date = '20080106'
--(1 row(s) affected)
Thus we can see that all functionality of querying/updating the data can be carried out (in fact with better performance in some cases) by de-normalizing the data and saving space and without having to write any custom procedures for parsing.
Hot discussion! Please view the discussion for this article after reading it.