

The Delta file format supports ACID properties by storing data in parquet files and actions in JSON files. This storage format allows the developer to time travel to a given version number or timestamp. However, it means the files keep on growing until an optimize statement (file compaction) and vacuum statement (file removal) are executed. Once these commands are executed, the time travel is limited to the file retention in hours. The default file retention is 168 hours or 7 days.
If you are writing single threaded notebooks, the Delta file format looks very attractive. If you do not update the same row of data, then no write conflicts will occur. However, let us pretend we have a log table that is used to reflect the current load status of a given entity. We decided to run two jobs in parallel to load historical data by year and month. The jobs finish at the same time and the write conflict occurs when updating the log table. Please see the details on isolation levels and row level concurrency.
Business Problem
Our manager has asked us to research and explain how time travel can be used by the analysts in our company. Additionally, the development team has just discovered a bug when updating a status table during a current load of data. Our manager has asked us to research the issue and propose a solution that will not cause write conflicts.
Time Travel
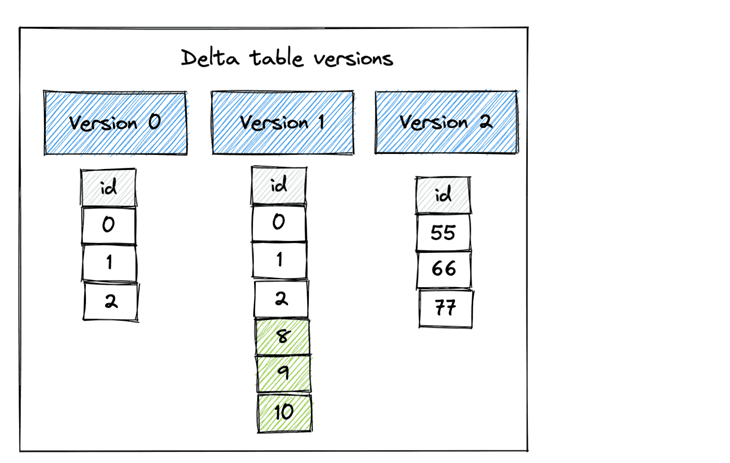
Comparing the two tasks, the time travel is the easiest to complete. The image below was taken from Mathew Powers’ article on delta lake time travel. For each write action (update, merge, or delete), a new version is created. Thus, we can travel back in time using either the version number or the timestamp.
The next few cells go over Spark SQL that can be used with databases and tables. I have already created a lakehouse in Microsoft Fabric through the portal. The show databases Spark SQL command lists all databases in my workspace.
%%sql -- -- 1 - list databases -- show databases
The image below shows five different Lakehouse’s. Today, we are using the last one named ls_ssc_articles_2024.

During our exploration, we are going to create two tables named logs and logs2. Let make sure to start fresh and delete these demonstration tables if they exist.
%%sql -- -- 2 - delete tables used in exercise -- -- del tbl 1 drop table if exists logs; -- del tbl 2 drop table if exists logs2;
At this time, we are going to create a table called logs that has two fields: id – an identifier and date – timestamp of the entry.
%%sql -- -- 3 - create new table -- -- add tbl create table if not exists logs ( id int, date timestamp );
The show tables Spark SQL command lists all the tables in the current lakehouse.
-- -- 4 - show tables -- show tables;
The image below shows the logs table is part of the lh_ssc_articles_2024 lakehouse.

The next few cells go over Data Manipulation Language statements that are available in Spark SQL. First, let us clear the data from the table using the delete statement.
%%sql -- -- 5 - clear table -- -- remove all data delete from logs; -- show empty table select * from logs;
Statements that perform an action return the number of rows affected. Since the table is empty, not data is shown by the select statement.

Please execute the code below to insert a row using Spark SQL into the table with id equal to 1 and date representing the current timestamp.
%%sql -- -- 6 - insert row -- -- add data insert into logs(id, date) values (1, current_timestamp()); -- show data select * from logs;
The image below shows the one row of data in the table.

The code below uses the Spark SQL update statement to change the one row to have a different value for the id field.
%%sql -- -- 7 - update row -- -- update data update logs set id = 2 where id = 1; -- show data select * from logs;
Because we have two Spark SQL statements, multiple active result sets are returned as output. One row was changed, and the id has been changed from 1 to 2.

The describe history command displays the different versions of the logs table.
%%sql describe history logs;
We can travel back in time to any of the displayed versions as long as the file removal (vacuum) has not been performed.

The command below uses the VERSION AS OF clause of the select statement to travel back to version 1.
%%sql -- -- 8 - time travel -- select * FROM logs VERSION AS OF 1;
The expected result is shown below.

The Delta file format keeps track of history and the big data analysts can go back to any valid point in time.
Write Conflicts
Today, we are going to focus on two or more parallel processes writing to the same row of data. However, write conflicts can happen when the metadata for the Delta table is changed at the same time by more than one process.
The code below defines a Python function called process1. Dynamic Spark SQL is used to increase the id field from 1 to 3 by 1.
#
# 9 - simple function to update row
#
# generic process
def process1(id):
# three's company
for n in range(3):
# debug line
stmt = f"{id} - {n}"
print(stmt)
# update the one entry
stmt = f"update logs set id = {n+1}"
try:
spark.sql(stmt)
except Exception as e:
print(e)
# show output
process1("a")
Let’s execute the code. It works fine since we are running this program as a single thread.

The table history shows 3 more updates have been executed with a total of 6 different versions that can be used for time travel.
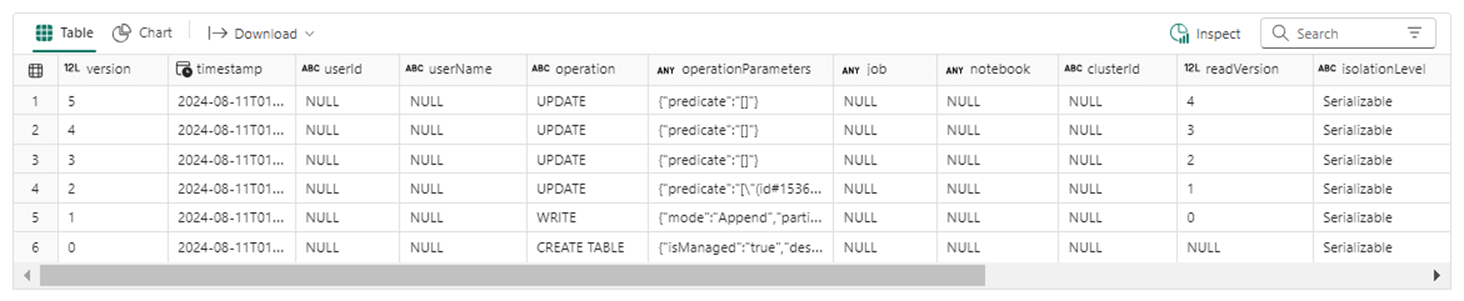
The cell below uses the two threading libraries to create three processes called A, B, and C. Each process executes the update function defined above.
#
# 10 - run process 3x - updates fail on collisions
#
from threading import Thread
import concurrent.futures
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:
executor.submit(process1, "a")
executor.submit(process1, "b")
executor.submit(process1, "c")
The concurrent write conflict occurs right away. The screen shot is a small snippet from the 9 calls to the process1 function.
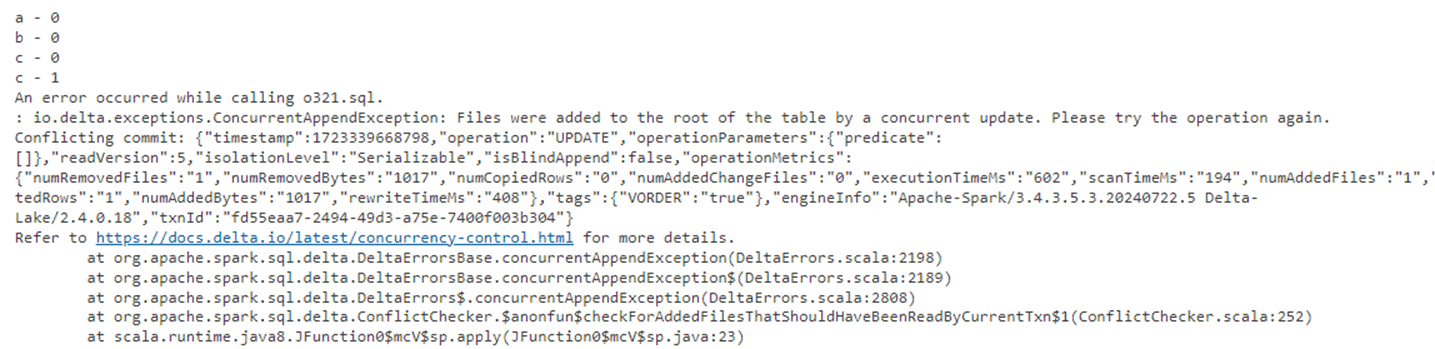
Writing to a Delta table takes some time since it is located on Azure Data Lake Storage. It is not surprising that only 3 actions are successful for the 9 executed calls to the function.
To recap, the update, delete and merge statements can have write conflicts. In the next section, we will create a new function that will not have this issue.
No Conflicts
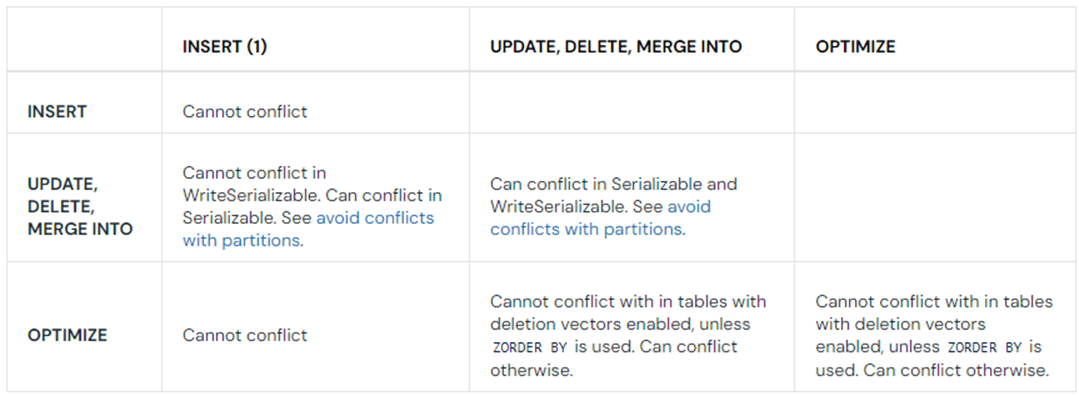
The table below was taken from the Databricks documentation. We can see that inserts do not cause any conflicts. If we want a log table, use inserts that have updated values paired with an up-to-date timestamp. Then we can use a row number window function over the last updated field to return the most recent record. We should use a soft delete flag to indicate the record should be removed in the future.
The cell below defines a Python function called process2. It inserts records into the log table instead of updating them.
#
# 11 - simple function to insert row
#
# generic process
def process2(id):
# three's company
for n in range(3):
# debug line
stmt = f"{id} - {n}"
print(stmt)
# insert row into log table
stmt = f"insert into logs(id, date) values ({n}, current_timestamp());"
print(stmt)
try:
spark.sql(stmt)
except Exception as e:
print(e)
# show output
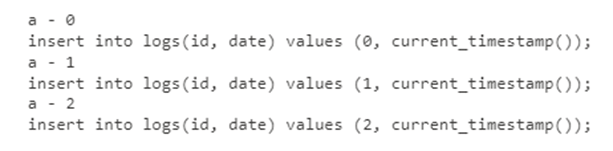
process2("a")
The single execution of process2 function works fine.
Let’s try a concurrent execution next by running the code seen below.
#
# 12 - run process 3x - inserts succeeded
#
from threading import Thread
import concurrent.futures
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:
executor.submit(process2, "a")
executor.submit(process2, "b")
executor.submit(process2, "c")
Of course, the execution was successful.

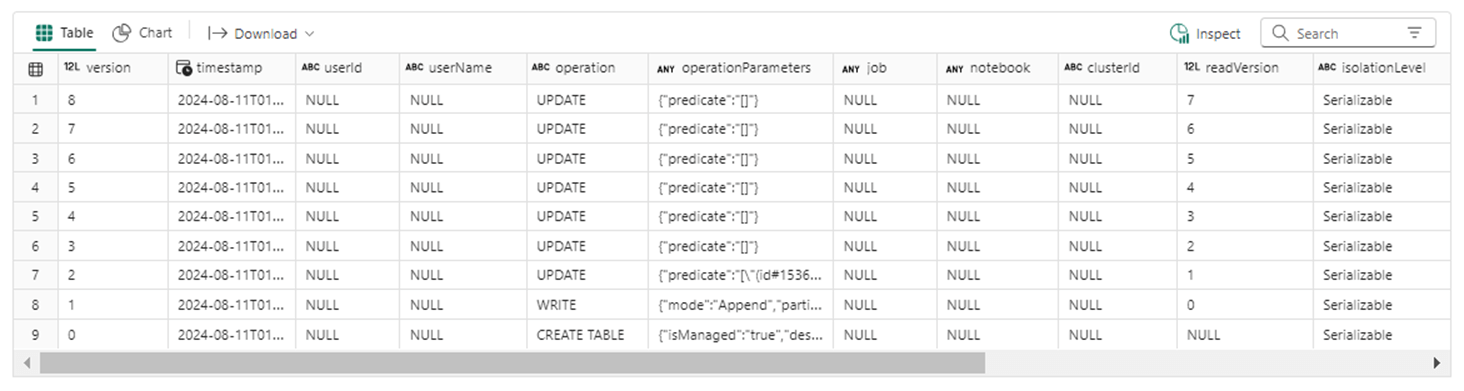
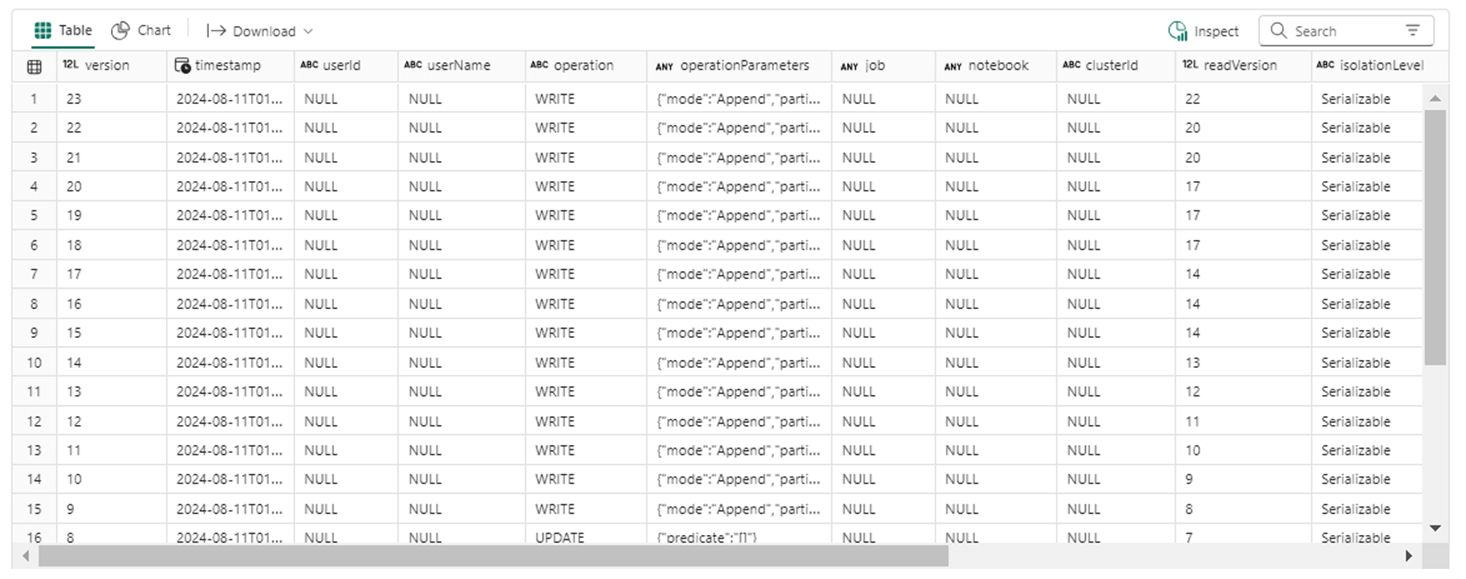
There should be an additional 12 entries in the table history. It looks like I must have manually ran the function twice since there are 15 write entries.
To avoid writing conflicts, insert data into tables that have concurrent writes.
Merge Statement
To round out the Data Manipulation Language statements, I want to introduce the merge statement. This statement can execute inserts, updates, and deletes. We have a requirement to remove all records from the log table and update the table with a new time stamp. How many records currently have id equal to one?
%%sql -- -- 13 - how many rows with rec id = 1 -- select * from logs where id = 1
Please execute the above select statement. The output shown below shows five rows with the matching id.

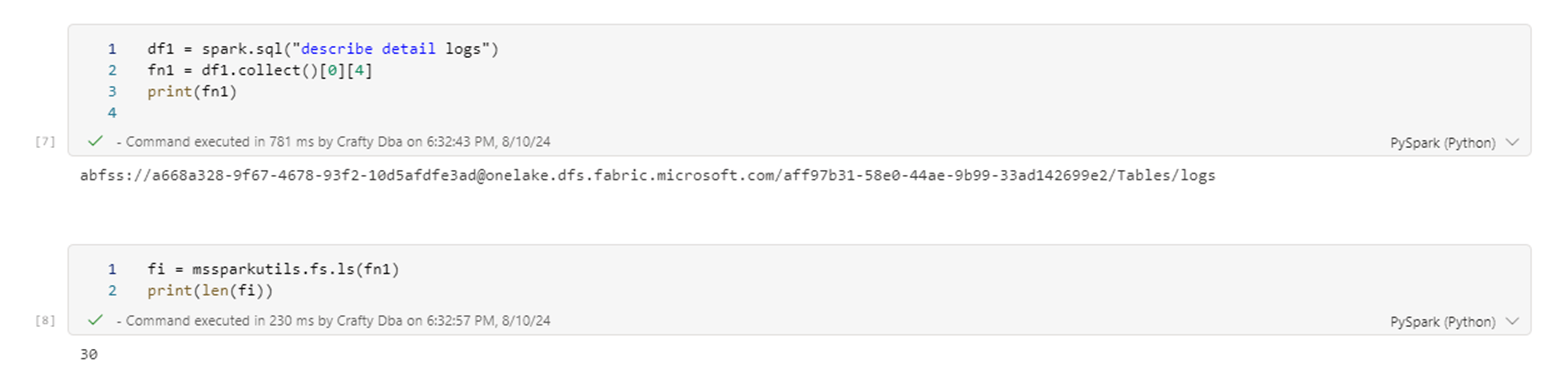
If we are curious about the number of actual parquet files, we can call the mssparkutils library to list out the directory that contains the Delta table named logs. We have 29 files at this point. Remember the _logs directory is counted as one.
To use the merge statement, we need a source and target table. The code below creates a new table named logs2 with one row of data.
%%sql -- -- 14 - make source table for merge -- -- add tbl create table logs2 ( id int, date timestamp ); -- rec with id = 1 insert into logs2(id, date) values (1, current_timestamp()); -- show data select * from logs2;
The merge statement below updates the target table (logs) when matches occur with source (logs2). All other records are deleted from the table.
%%sql -- -- 15 - merge - update matches, delete non matches -- -- update / delete merge into logs as trg using logs2 as src on trg.id = src.id when matched then update set * when not matched by source then delete; -- show data select * from logs;
We can see we had 16 rows of data before the merge statement was executed. After execution, only 5 rows of data exist.
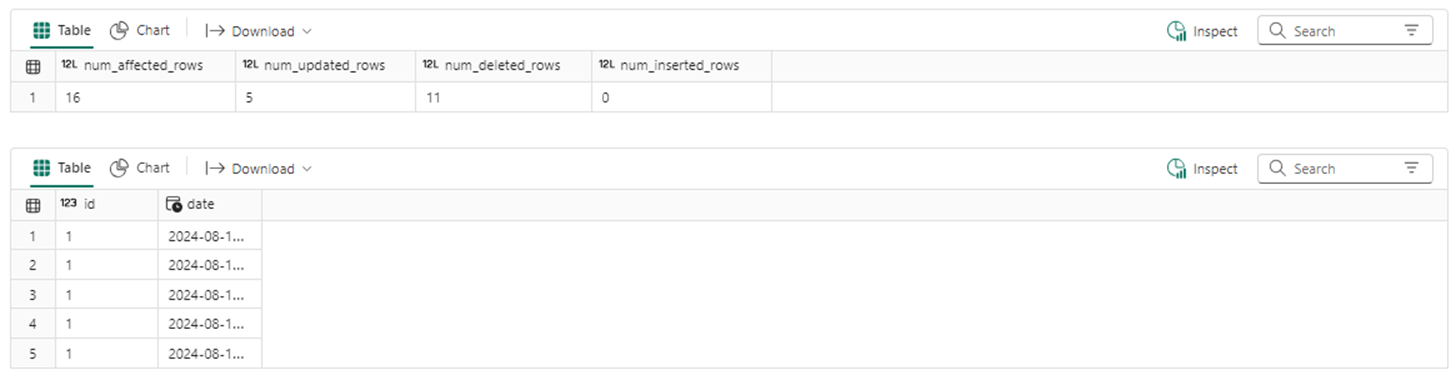
The merge statement can perform one or more actions. It works very well with small to medium-sized tables.
Optimize and Vacuum
The optimize statement re-organizes the files for the delta lake. See the documentation for more details. The vacuum statement removes files that are no longer used. The code below defines a function to call both optimize and vacuum in order. Warning! I am turning off the duration checking of 7 days since all these write actions happened within the last hour. Using a retention of zero gets rid of all prior versions before the optimize statement.
%%sql
#
# 16 - Perform maintenance
#
# https://docs.databricks.com/en/sql/language-manual/delta-vacuum.htm
def maintenance(table_name, optimize_hrs, retain_hrs):
# turn off 168 hr check
spark.conf.set("spark.databricks.delta.retentionDurationCheck.enabled", "false")
# reduce number of files
if optimize_hrs is None:
stmt = f"OPTIMIZE {table_name};"
else:
stmt = f"OPTIMIZE {table_name} WHERE date >= current_timestamp() - INTERVAL {optimize_hrs} HOURS;"
print(stmt)
spark.sql(stmt)
# remove all files
if retain_hrs is None:
stmt = f"VACUUM {table_name};"
else:
stmt = f"VACUUM {table_name} RETAIN {retain_hrs} HOURS;"
print(stmt)
spark.sql(stmt)
# turn on 168 hr check
spark.conf.set("spark.databricks.delta.retentionDurationCheck.enabled", "true")
The image below shows the maintenance Python function will call the optimize and vacuum statements with default values.
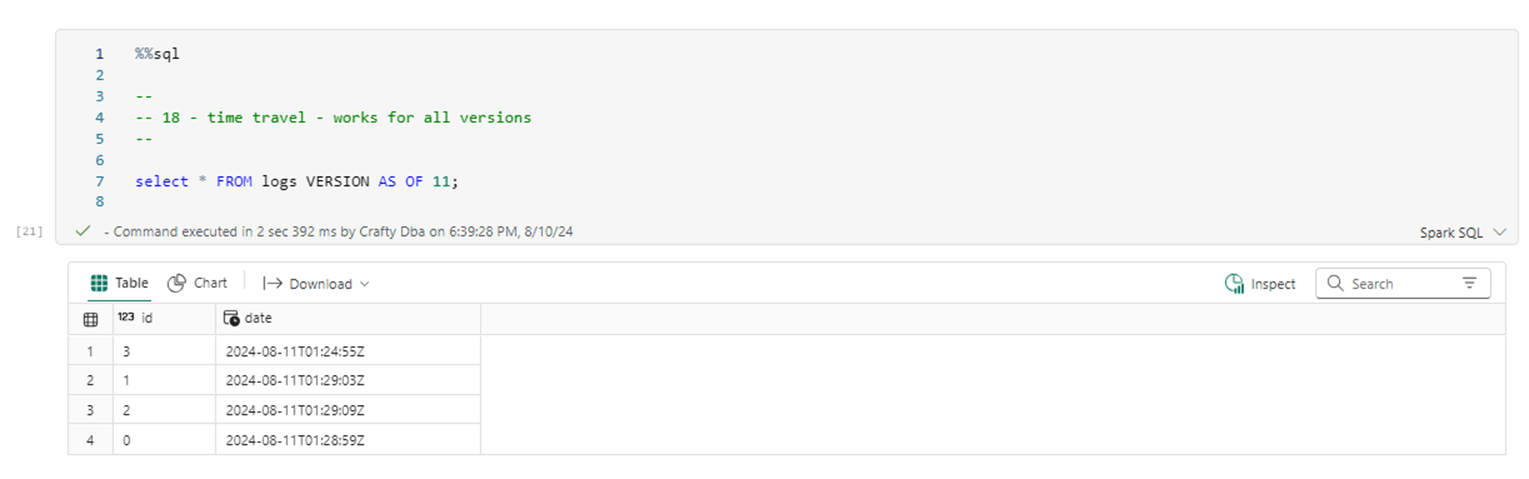
While the files have been consolidated, the history files still exist. Therefore, time travel works as expected. The image below shows version 11 of the table that has four distinct ids.
Let us call the maintenance function with a retention period of zero.

If we query the table history, we can see that two calls to the vacuum statement were completed.
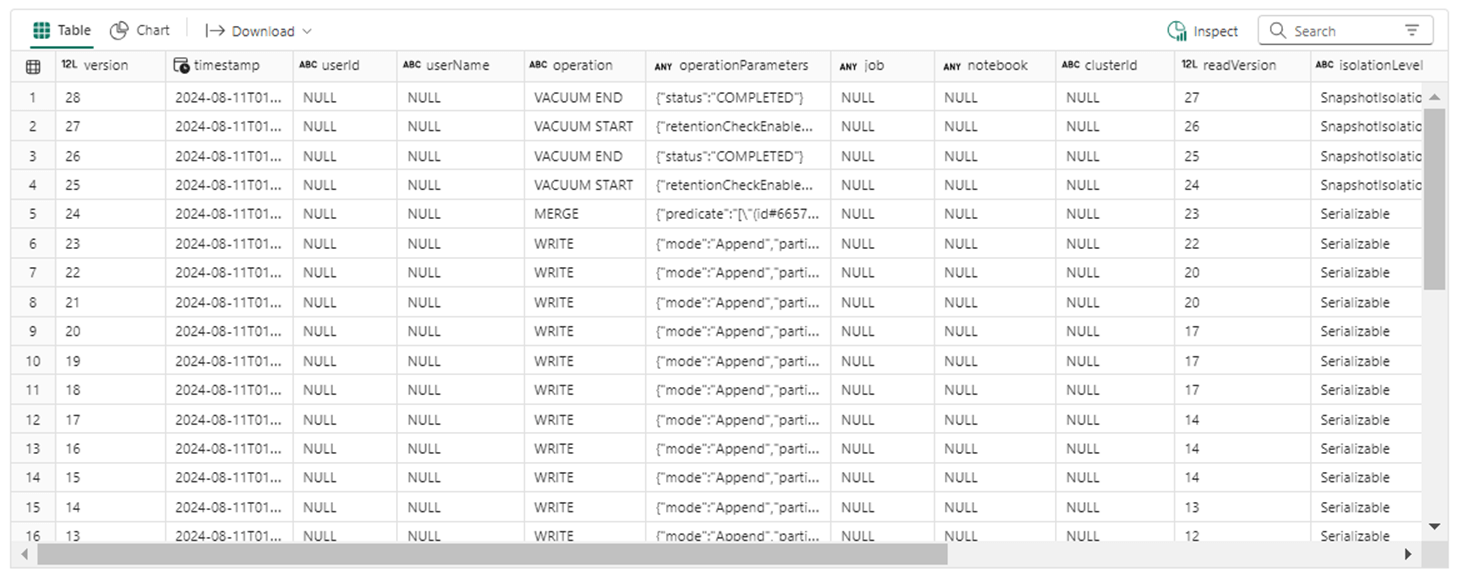
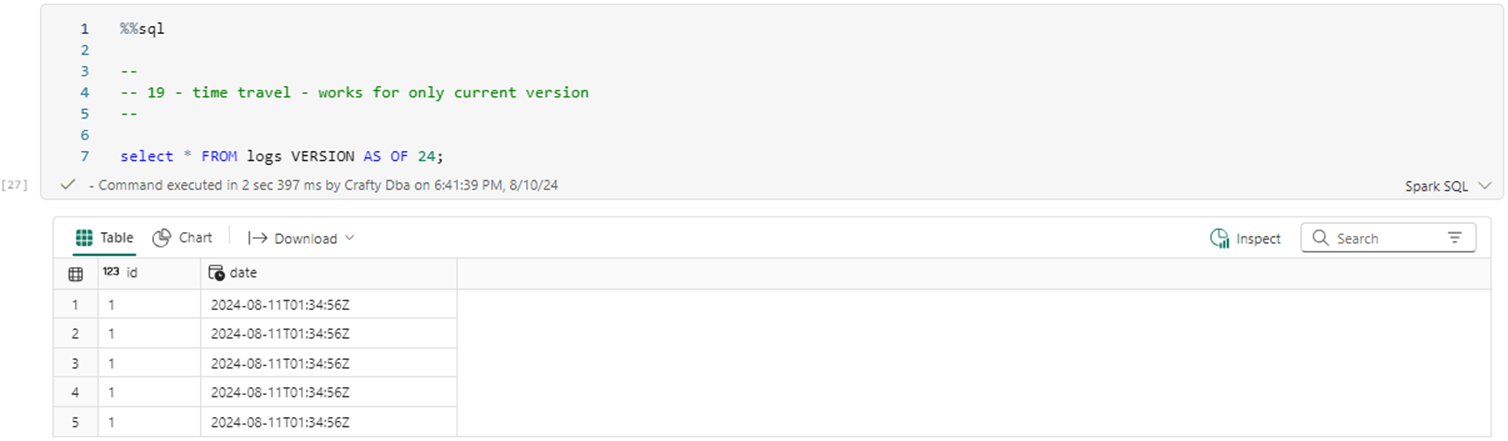
The last action was the merge statement that only left records with id equal to one in the table. We can travel back to version 23 without any issues.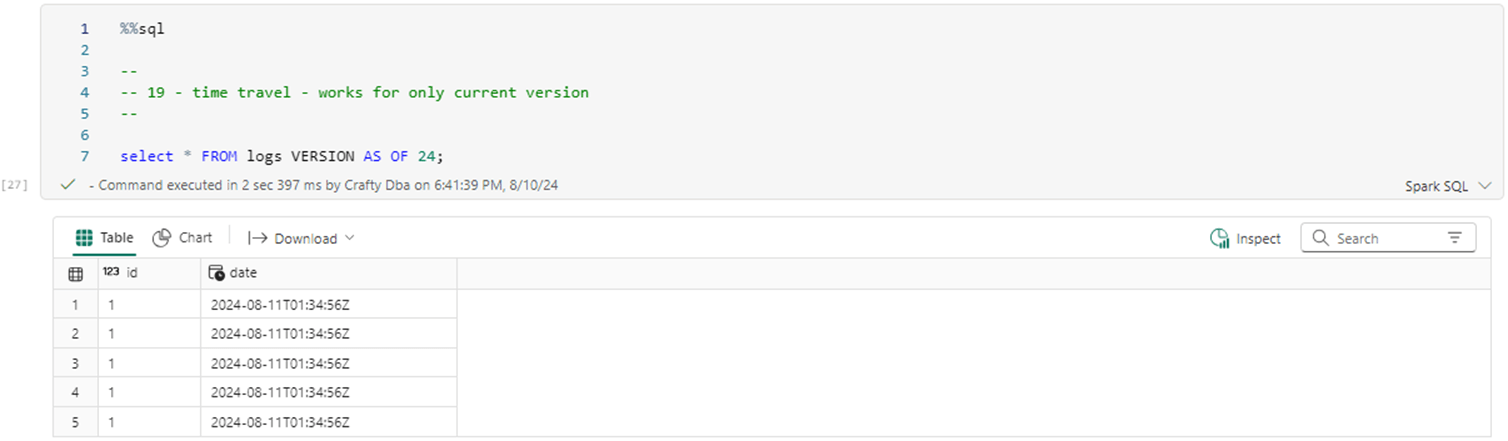
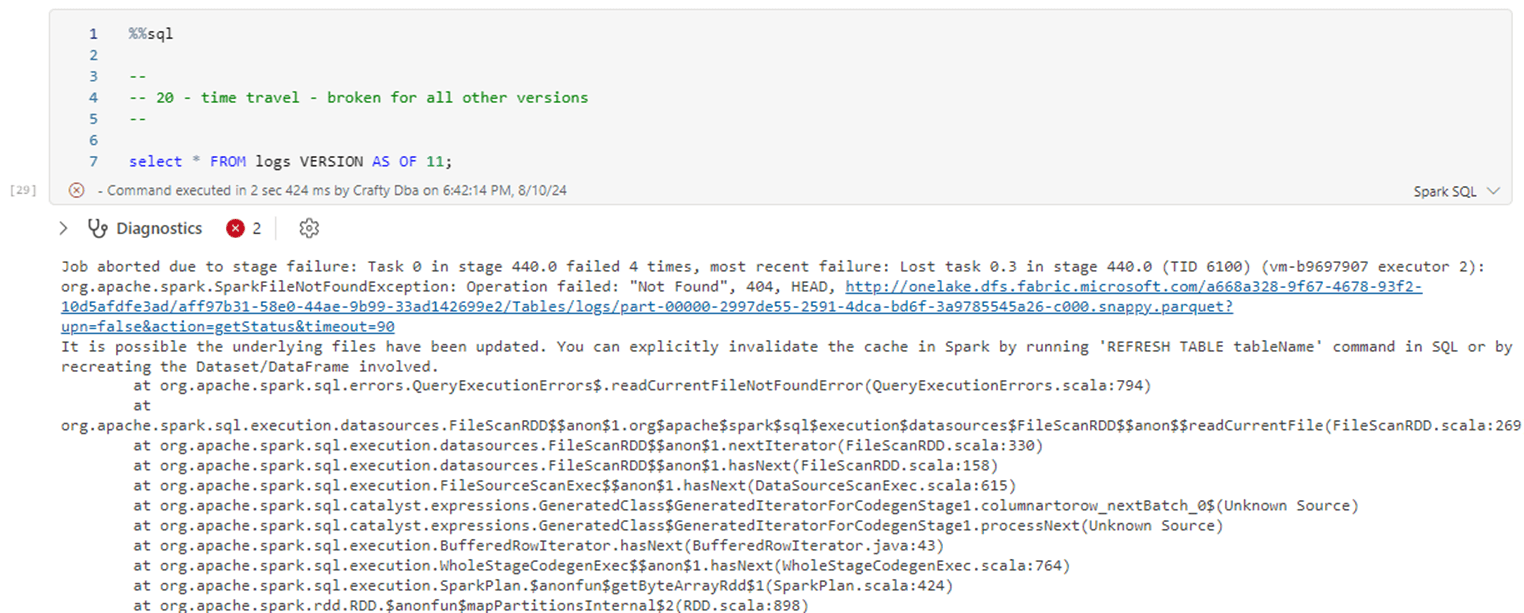
The supporting history files have been removed from the system. If we try to time travel back to version 11, we will get an error message.
If you want to remove old history, use the create table as syntax of Spark SQL. You will start again with version 0that indicates a table was created. This will prevent users from having time travel issues.
Summary
Today, we learned that the Delta table is composed of parquet (data files) and transaction files (JSON files). This design allows for end users to travel back in time to a prior version. However, this feature is at the expense of continuous file creation. If we optimize a table, the time travel history is still available, and the data is consolidated. If we vacuum a table, the time travel is limited to the retention period. The default value is 7 days.
While the Delta table supports ACID properties, there is no real locking or latching mechanisms. This means that writes can fail due to multiple concurrent updates to the row data and/or metadata. The only write operation that does not cause a conflict is the insert statement. If you are thinking of a dashboard built over a log table, use the windowing functions to return the most recently inserted data by the reporting fields.
On one hand, the Delta file format has a couple of shortcomings. On the other hand, it is a great improvement over files which do not support ACID properties.