

Overview
Last year I spent a considerable amount of time attempting to produce an enterprise wide view of reference data used within my organisation. This started off as a task to unify reference data for a couple of the most profitable lines of business. These would represent the first iteration of an agile data warehouse project.
In this case by reference data I mean principally data that is represented by key value pairs or data with a very limited set of attributes, typically that which powers up drop down boxes on web forms.
The task quickly expanded once I started to look at reference data common to both lines of business and found that an amount was actually common across many lines of business albeit described differently. And therein began the first challenge...
Challenge One - What is common and what is not?
This is best summed up in the table below.
| Data class | Description |
|---|---|
| Truly common across multiple lines of business | This is data that comes from a single source shared across the different lines of business |
| Should be (and usually is) common across multiple lines of business | This is data where the commonality between the lines of business was originally recognised but instead of a single source the data from one line of business was copied to the other. Over time the two datasets have diverged. This can happen for a number or reasons:-
|
| Different names but common subject | In this scenario the name for the reference dataset differs between the lines of business but is fundamentally the same such as in the example below: -
|
| Same name but different meaning | There are lots of reasons for this: -
To illustrate the latter you cannot buy pet insurance to insure your dog for "3rd party fire and theft" (even if you have read The Wasp Factory), neither can you insure your car for distemper though mine would qualify if it were possible. |
| Subsets and super sets | One line of business may capture a limited range of salutations (Mr, Mrs, Ms, Miss, Dr) Another may capture a plethora of titles including the above but also ecclesiastical,military or other status. |
| Different names but ambiguous subject | Consider "Relationship" Vs "Marital Status". Should they be considered a superset/subset situation or regarded as totally different things? This is a business decision and not an IT one. |
No good deed goes unpunished!
It is tempting, in the interests of rapid progress, to take it upon yourself to make decisions that really should be driven by business requirements. What you are likely to find is that people are only too happy for someone to take charge and make the difficult decisions.
Where you need to be careful is who gets assigned the responsibility for the consequences of those decisions. Are you going to come off worse in a blamestorming session?
The approach I would recommend is to keep a decisions log that is available to all business and technical stake holders, development team members etc.
- Decision required
- Whether or not the absence of a decision is a blocking issue for the project
- When the decision needed to be made to avoid becoming a blocking issue
- The eventual decision maker
- When the decision was actually made
- Who ratified the decision and when.
Such a log makes it clear what is expected, of whom, when and what the implications are of not taking a decision
Challenge Two - Where is the reference data?
I thought that finding where the reference data sits would be a simple task. Run through the databases looking for tables with only two columns and/or very low number of records. What could be simpler?
It is here where the unaddressed technical debt chickens come home to roost. The issues I found are listed below.
| Issue | Description |
|---|---|
| Data not in the expected database | This came in two forms and both were mixed blessings:-
The silver lining in these two scenarios is that they both represented an earlier attempt to unify reference data between two systems. As such their discovery reduced the size of the challenge |
| Data not in the database | Reference data was embedded in the application code and not in the database. This came in two forms:-
In some cases systems were actually external or outsourced so there was no option other than to trawl through the HTML pages to identify reference data. |
| Data not held as reference data | This situation tended to manifest itself in situations where the reference data was not in the database in a normalised form. Instead of there being a reference data table for marital status or salutation title the actual values were stamped out in the principal table. For the purposes of unifying reference data this did not necessarily represent a problem other than in finding it in the first place. Where the data came from a hard-coded drop-down box on a web form there wasn't even a data quality issue but in some cases there was data that was entered free-form which almost certainly should have been normalised out or selected from a defined list of values. |
| Conflicting views of reference data in a single database | In a large system there can be hundreds if not thousands of reference data tables. With such a large number of tables it is almost inevitable that duplications will occur. Without significant software archeaology it is difficult to determine whether systems use none, one or more than one reference data table. There is also the issue of old data being left around after superceding systems have been put in place. For example, where your environment has challenging project timescales it is very easy for the task of cleaning out obsolete items to be overlooked or descoped. Zero impact for the project at the time, ticking timebomb for future projects and major headache for data unification projects. |
| Who knows where the bodies are buried? | If an organisation experiences high staff turnover then finding the people who know the intricacies of a system can be challenging. Even when the old hands are around there will still be systems that where all knowledge as to their workings has been lost. Their data is backed up, reindexed etc and they chug away ad infinitum. Because these vintage systems fulfill their purpose, don't cause production issues, don't throw errors (unlike their "legacy" bretheren) they are not on anyones radar. There may be the situation where the source code for the systems is lost. All this will hamper any software archeaology and increase the time required to locate reference data |
Challenge Three - Choosing a Slow Changing Dimension Strategy
Carrying out a unification exercise is all very well but a key business decision is how changes to the source reference data should be reflected in the unified set.
A brief summary of the options are as follows:-
| Dimension Type | Description |
|---|---|
| 0 | Data is a one off snapshot at a point in time |
| 1 | Data is updated with the current version |
| 2 | Versions of records are recorded in the reference data itself. There are a number of ways to indicate the current version
|
| 3 | Records gain columns for previous versions |
| 4 | Versions stored in separate audit tables |
The best choice will depend on how the business chooses to look at historical data. If we discount Type 3 then in the absence of a clear business decision recording as either Type 2 or Type 4 will allow reference data to be presented as any of the other types.
In my case I chose Type 4 because the predominant view of data is "as it is today". As described above this can be presented as Type 0,1 or 2 by overlaying a view on the reference data table.
In hindsight it may be beneficial to implement type 4 slow changing dimensions in the actual source systems themselves. More on this later.
Challenge Four - The structure of the reference data tables
When I looked carefully at the structures of the various pieces of reference data in the organisation I noticed that they fell into four distinct categories
| Structure Category | Description |
|---|---|
| Simple | Little more than an ID, Name and an active flag |
| Number Banded | This is where someone is asked to choose which band (such as salary or age) they belong to |
| Sequential Number | This is where someone is asked to choose from a contiguous list of values |
| Miscellaneous | These fit no particular pattern. For example a reference table holding MIME types actually consists of two VARCHAR fields where most normal reference data tables consists of one. Then there are reference data tables with foreign key relationships to others. For example "Salutation Title" has a foreign key to "Gender". |
By categorising the reference data tables templates/snippets of SQL can be built up to aid generation of the physical reference tables.
In my case I created a SQL Prompt snippet for the "Simple" category attached to the "ref" abbreviation as follows (note the use of an explicit "Reference" schema):-
----------------------------------------------------------------------------- -- Build the <TableName,sysname,> table -----------------------------------------------------------------------------IFNOT EXISTS(SELECT*FROMINFORMATION_SCHEMA.TABLESWHERETABLE_NAME='<TableName,sysname,>'AND TABLE_SCHEMA='Reference')BEGIN CREATE TABLEReference.<TableName,sysname,>( <TableName,sysname,>IDTINYINTNOT NULL ,CONSTRAINTPK_<TableName,sysname,>PRIMARY KEY CLUSTERED(<TableName,sysname,>ID), <TableName,sysname,>Name VARCHAR(<RefnameSize,tinyint,50>) NOT NULLCONSTRAINTUNQ_<TableName,sysname,>UNIQUE, ActiveBITNOT NULLCONSTRAINTDF_<TableName,sysname,>_ActiveDEFAULT(1), LastUpdatedUserVARCHAR(128) NOT NULLCONSTRAINTDF_<TableName,sysname,>_LastUpdatedUserDEFAULT(SUSER_SNAME()), CreatedDate DATETIME NOT NULLCONSTRAINTDF_<TableName,sysname,>_CreatedDateDEFAULT(CURRENT_TIMESTAMP), UpdatedDate DATETIME NOT NULLCONSTRAINTDF_<TableName,sysname,>_UpdatedDateDEFAULT(CURRENT_TIMESTAMP),CONSTRAINTCK_<TableName,sysname,>_<TableName,sysname,>CHECK(LEN(LTRIM(<TableName,sysname,>Name))>0),CONSTRAINTCK_<TableName,sysname,>_CreatedDateToCHECK(CreatedDate<=UpdatedDate) )'TABLE CREATED: Reference.<TableName,sysname,>'END ELSE PRINT'TABLE ALREADY EXISTS: Reference.<TableName,sysname,>'GO
This meant that hitting the keystroke CTRL+SHIFT+M brought up the dialogue box shown below:-
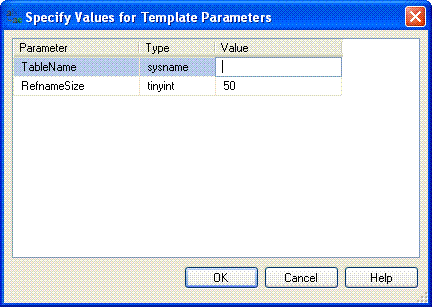
If I entered "MaritalStatus" in the TableName dialogue then the resulting script would be as follows:-
----------------------------------------------------------------------------- -- Build the MaritalStatus table -----------------------------------------------------------------------------IFNOT EXISTS(SELECT*FROMINFORMATION_SCHEMA.TABLESWHERETABLE_NAME='MaritalStatus'AND TABLE_SCHEMA='Reference')BEGIN CREATE TABLEReference.MaritalStatus( MaritalStatusIDTINYINTNOT NULL ,CONSTRAINTPK_MaritalStatusPRIMARY KEY CLUSTERED(MaritalStatusID), MaritalStatusNameVARCHAR(50) NOT NULLCONSTRAINTUNQ_MaritalStatusUNIQUE, ActiveBITNOT NULLCONSTRAINTDF_MaritalStatus_ActiveDEFAULT(1), LastUpdatedUserVARCHAR(128) NOT NULLCONSTRAINTDF_MaritalStatus_LastUpdatedUserDEFAULT(SUSER_SNAME()), CreatedDateDATETIMENOT NULLCONSTRAINTDF_MaritalStatus_CreatedDateDEFAULT(CURRENT_TIMESTAMP), UpdatedDateDATETIMENOT NULLCONSTRAINTDF_MaritalStatus_UpdatedDateDEFAULT(CURRENT_TIMESTAMP),CONSTRAINTCK_MaritalStatus_MaritalStatusCHECK(LEN(LTRIM(MaritalStatusName))>0),CONSTRAINTCK_MaritalStatus_CreatedDateToCHECK(CreatedDate<=UpdatedDate) )'TABLE CREATED: Reference.MaritalStatus'END ELSE PRINT'TABLE ALREADY EXISTS: Reference.MaritalStatus'GO
As you can see I have been rather heavy handed with the constraints in the table definition.
- MaritalStatusName is protected by both a unique constraint and a check constraint to prevent the entry of zero length strings.
- UpdatedDate must be on or after the CreateDate
- All fields are NOT NULL
If there was a business rule stating the permitted characters for the MaritalStatusName then I would include this in a CHECK constraint too. Long a bitter experience means I have no truck with any argument that data quality rules should sit outside the database. Fashions come and go but bad data is an embarassment forever.
Number Banded reference data
For banded data such as salary bands I added two fields to the "Simple" table definition after the primary key field as follows:-
LowerLimit INT NOT NULL
CONSTRAINT CK_SalaryBand_LowerLimit CHECK (LowerLimit>=0),
UpperLimit INT NOT NULL
CONSTRAINT CK_SalaryBand_LowerUpperLimit CHECK (UpperLimit>LowerLimit OR UpperLimit=0),
Strictly speaking I should have entered a UNIQUE constraint across the LowerLimit and UpperLimit fields.
The reason for these fields is simply due to the fact that salaries and salary bands crop up across the enterprise. If a salary is entered as an absolute value then at least we have a crude means of assigning it to a band appropriate for a particular context.
That is not to say that the absolute salary is discarded, simply that it can be matched to a band.
Sequential Number Bands
This is for reference data where the customer is asked to answer a questions such as "For your main vehicle how many previous owners have there been?" where the answers can be one of the following
- Unknown
- 1
- 2
- 3+
The difference here is that there is a single table where each record represents a reference data set. It is debatable whether this actually does class as reference data but for the sake of my project I included it.
The structure of this table is as shown below
| Field name | DataType | Description |
|---|---|---|
| SequentialRangeBounds | VARCHAR(50) | Primary key and friendly name for the range |
| LowerLimit | TINYINT | The bottom and top of the contiguous range. For example if the range range is for "NumberOfChildren" then the upper and lower range could be 0 and 6 |
| UpperLimit | TINYINT | |
| ValueRepresentingUnknown | SMALLINT | If there is an option for an unknown value then we need a number outside of the contiguous range. |
| HasValueRepresentingUnknown | BIT | Identifies whether or not there is an "Unknown" value. |
| UpperLimitRepresentsPlus | BIT | If our "NumberOfChildren" is supposed to give options where the highest option is 6+ meaning 6 or more children then this flag will be set. |
| ValueRepresentingUpperLimit | TINYINT | If our "NumberOfChildren" upper limit is 6+ then we cannot really say how many children there are. This value is one that indicates that a number greater than 6 was recorded. If the organisation captures "NumberOfChildren" in various forms then this simple facility to map to a unified value is essential |
| Active | BIT | Whether or not the record is currently active |
| ...etc | ||
Useful deviations from standard patterns
Three particular deviations stick out for me
- Salutation Title can also reveal the gender of the participants. For this reason adding a GenderID field to this table can be beneficial
- Relationship in addition to revealling gender may also have an inverse relationship. If it reveals that the primary to secondary relationship was Husband to Wife then reversing the relationship gives Wife to Husband. This means that no matter how you join a "Person" record to this table you will always get a relationship record and possibly a gender.
- Country. ISO3166 has three separate codes representing a country. By storing all three codes for each country you have a useful translation mechanism for any ISO compliant data sources.
If salutation title and relationship can be used to infer gender then it is worth spending the time to determine if any other reference data can also be used to infer useful facts.
Challenge Five - Key values
If we are unifying multiple sources and those sources all have their own keys then the decision to generate a new surrogate key for the unified version of reference data is a fait accompli.
I would advise that a key value be chosen that always means "Unknown". In my particular case, as my data type for the primary key is usually TINYINT this lead me to adopt zero as the default value.
For data where there is an international standard I did consider adopting the international standard key but with the sole exception of Gender I stuck with the policy of issuing surrogate keys for the following reasons:-
- Believe it or not data in international standards can change. South Sudan came into being in July 2011 and the ISO3166-3 digit code for Sudan changed.
- A business specific view of a set of reference data may exist that requires values over and above the international standard
I felt I was on safe ground in keeping the ISO5128 Gender codes as the four values cover everything I can forsee the need for and dovetail with my use of zero to mean "Unknown".
Challenge Six - Supporting metadata tables
In unifying the reference data we need a mechanism for translating from source systems into our unified view of the world. It is here that I made at least one big mistake.
- Mistake One - Not recording precisely where I got the reference data and subsequently failing to build a metadata structure within the database to hold this information
- Mistake Two - I built something horribly like the "One True Lookup Table" solution as the translation mechanism.
Correcting mistake one my supporting metadata tables are shown in the diagram below.
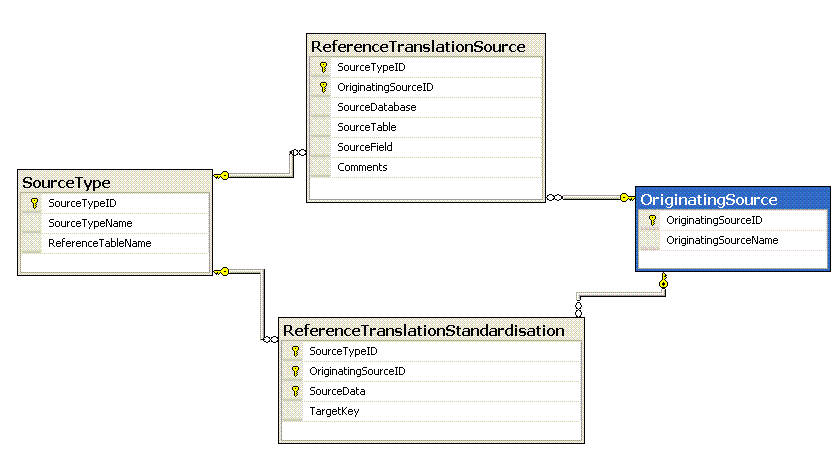
The tables you see above are best described in the following table:-
| Table | Description |
|---|---|
| SourceType | The name for the reference data
Notice that I have added a field to hold the name of the target reference data table. I would also consider adding a field to hold descriptive text for the source type. This description can be used to populate the MS_DESCRIPTION metadata which can be picked up by both Red-Gate SQLPrompt (displayed as tooltip text when hovering over query elements) and Red-Gate SQLDoc (used to produce automated documentation sets. |
| OriginatingSource | The source system or line of business from which the reference data orginates |
| ReferenceTranslationSource | Correction to Mistake One. This allows us to record the precise source of a reference data set for a given line-of-business |
| ReferenceTranslationStandardisation | Allows a key from a source to be translated to the unified target for a reference data set for a given line-of-business |
Why is ReferenceTranslationStandardisation is a mistake?
On the plus side, it works.....for now.
The problems are classic OTLT problems
- As the lines of business going into the warehouse increase in number the table will become a bottleneck
- Data referential integrity with the target tables is not possible therefore the door is open to DRI errors.
In hindsight my solution should have been as follows:-
- A separate translation table for each "SourceType"
- Add a RefereneTranslationTableName field to the SourceType table naming f the appropriate translation table
Lessons learnt early
Populating the "ReferenceTranslationStandardisation" table was extremely laborious and in a normalised form it was very easy to make mistakes in the values being inserted into the table but very hard to proof read them. For that reason I set up a view to present the data as a denormalised dataset and placed an INSTEADOF trigger against it so I could use the view to perform the inserts.
The code for this as as follows:-
CREATE VIEWdbo.TranslationStandardisationMapAS SELECTOS.OriginatingSourceName, ST.SourceTypeName , RTS.SourceData , RTS.TargetKeyFROMdbo.ReferenceTranslationStandardisationASRTS INNER JOIN dbo.SourceTypeASSTONRTS.SourceTypeID = ST.SourceTypeID INNER JOIN dbo.OriginatingSourceASOSONRTS.OriginatingSourceID = OS.OriginatingSourceIDGO CREATE TRIGGERdbo.TranslationStandardisationMap_OnInsertONdbo.TranslationStandardisationMapINSTEAD OF INSERT AS SET NOCOUNT ON INSERT INTOdbo.ReferenceTranslationStandardisation(SourceTypeID, OriginatingSourceID, SourceData, TargetKey)SELECTST.SourceTypeID, OS.OriginatingSourceID, SRC.SourceData, SRC.TargetKeyFROMINSERTEDASSRC INNER JOIN dbo.OriginatingSourceASOSONSRC.OriginatingSourceName = OS.OriginatingSourceName INNER JOIN dbo.SourceTypeASSTONSRC.SourceTypeName = ST.SourceTypeNameGO
This gave a dramatic improvement in the speed and accuracy of the data entry task.
At this stage I should like to point out that for all objects I populated either the MS_DESCRIPTION metadata property or used specially tagged comments so that products such as Red-Gate SQLDoc could scrape and document the database.
Challenge Seven - Populating the reference data and translation mechanism
There is no getting around the fact that populating the database is a laborious task. Could I have done it by matching source data to target data? Possibly but any time saved by taking this approach would have been lost by dealing with the mismatches and exceptions. Sometimes it is best just to grit your teeth and get on with it.
Just as I set up a template/snippet to help create the reference data tables I set up a snippet to help populate the target reference data tables and also the TranslationStandardisationMap view. The snippet is shown below.
----------------------------------------------------------------------------- -- Populate <TableName,SYSNAME,> -----------------------------------------------------------------------------DECLARE@RefSourceTABLE( IDSMALLINTNOT NULLPRIMARY KEY CLUSTERED, NAME varchar(<RefNameSize, TINYINT,50>) NOT NULL )INSERT INTO@RefSource (ID,NAME)VALUESReference.<TableName,SYSNAME,>(<TableName,SYSNAME,>ID, <TableName,SYSNAME,>)-- Enter your values statements hereINSERT INTOSELECTSRC.ID,SRC.NAMEFROM@RefSourceASSRC LEFT JOIN Reference.<TableName,SYSNAME,>ASDESTONSRC.ID = DEST.<TableName,SYSNAME,>IDWHEREDEST.<TableName,SYSNAME,>ID IS NULLRAISERROR('DATA DEPLOYED: %i records inserted into Reference.<TableName,SYSNAME,>',10,1, @@ROWCOUNT)WITH nowaitGO DECLARE@SourceTableTABLE( SourceTypeNameVARCHAR(50) NOT NULL , OriginatingSourceNameVARCHAR(50) NOT NULL , SourceDataVARCHAR(100) NOT NULL , TargetKeyINTNOT NULL,PRIMARY KEY CLUSTERED(SourceTypeName,OriginatingSourceName,SourceData,TargetKey) )INSERT INTO@SourceTable ( SourceTypeName , OriginatingSourceName , SourceData , TargetKey )VALUES-- Enter your values statements hereINSERT INTOdbo.TranslationStandardisationMap ( OriginatingSourceName , SourceTypeName , SourceData , TargetKey )SELECTSRC.OriginatingSourceName , SRC.SourceTypeName , SRC.SourceData , SRC.TargetKeyFROM@SourceTable AS SRC LEFT JOIN dbo.TranslationStandardisationMapASDEST ON SRC.OriginatingSourceName = DEST.OriginatingSourceName AND SRC.SourceTypeName = DEST.SourceTypeName AND SRC.SourceData = DEST.SourceDataWHEREDEST.SourceTypeName IS NULLRAISERROR('DATA DEPLOYED: %i <DataDescription,varchar,> records inserted into dbo.TranslationStandardisationMap',10,1, @@ROWCOUNT)WITH nowait GO
Once again CTRL+SHIFT+M produces a dialogue box as follows
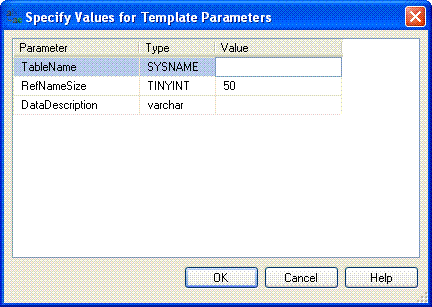
For a SalutationTitle table the population script might look something like the following:-
----------------------------------------------------------------------------- -- Populate Salutation Titles -----------------------------------------------------------------------------DECLARE@SalutationTABLE( SalutationTitleIDTINYINTNOT NULLPRIMARY KEY CLUSTERED, SalutationTitlevarchar(25) NOT NULL , GenderIDtinyintNOT NULL )INSERT INTO@Salutation(SalutationTitleID,SalutationTitle,GenderID)VALUES(0,'Not Known',0), (1,'Miss',2), (2,'Mr',1), (3,'Mrs',2), (4,'Ms',2)--...etcINSERT INTOReference.SalutationTitle(SalutationTitleID,SalutationTitle, GenderID)SELECTSRC.SalutationTitleID, SRC.SalutationTitle,SRC.GenderIDFROM@SalutationASSRC LEFT JOIN Reference.SalutationTitleASDESTONSRC.SalutationTitleID = DEST.SalutationTitleIDWHEREDEST.SalutationTitleID IS NULLRAISERROR('DATA DEPLOYED: %i records inserted into Reference.SalutationTitle',10,1, @@ROWCOUNT)WITH nowait go DECLARE@SourceTableTABLE( SourceTypeNameVARCHAR(50)NOT NULL , OriginatingSourceNameVARCHAR(50)NOT NULL , SourceDataVARCHAR(100)NOT NULL , TargetKeyINTNOT NULL,PRIMARY KEY CLUSTERED(SourceTypeName,OriginatingSourceName,SourceData,TargetKey) )INSERT INTO@SourceTable ( SourceTypeName , OriginatingSourceName , SourceData , TargetKey )VALUES('Salutation Title','Widget System','1',1), ('Salutation Title','Widget System','2',2), ('Salutation Title','Widget System','3',3), ('Salutation Title','Widget System','4',4), ('Salutation Title','Grommet System','A',1), ('Salutation Title','GrommetSystem','B',2), ('Salutation Title','GrommetSystem','C',3), ('Salutation Title','GrommetSystem','D',4), ('Salutation Title','Whojamaflip System','Miss',1), ('Salutation Title','Whojamaflip System','Mr',2), ('Salutation Title','Whojamaflip System','Mrs',3), ('Salutation Title','Whojamaflip System','Ms',4)INSERT INTOdbo.TranslationStandardisationMap ( OriginatingSourceName , SourceTypeName , SourceData , TargetKey )SELECTSRC.OriginatingSourceName , SRC.SourceTypeName , SRC.SourceData , SRC.TargetKeyFROM@SourceTableASSRC LEFT JOIN dbo.TranslationStandardisationMapASDESTONSRC.OriginatingSourceName = DEST.OriginatingSourceName AND SRC.SourceTypeName = DEST.SourceTypeName AND SRC.SourceData = DEST.SourceDataWHEREDEST.SourceTypeName IS NULLRAISERROR('DATA DEPLOYED: %i Salutation records inserted into ReferenceTranslationStandardisation)',10,1, @@ROWCOUNT)WITH nowait GO
Challenge Eight - Implementing the slow changing dimension strategy
If you have a lot of different reference data tables then it can be a laborious task to build the associated Type IV Slow Changing Dimension audit tables. However, as the definition of the reference data follows a pattern we can work out the rules and therefore write code to generate the required object for us.
I decided I needed 3 stored procs accepting the object id for the table and a special schema on which to put the objects which I called ISO27001.
I also decided to stick my audit tables on a separate filegroup called FGAudit as this would allow the data to be placed on low performance storage
- dbo.BuildISO27001AuditTable
- dbo.BuildISO27001AuditUpdateTriggers
- dbo.BuildISO27001AuditDeleteTriggers
I would then need a script to iterate through my reference data tables passing their object id into my three stored procs.
@TableList/* Grab all qualifying objects and put their relevant fact into a table variable. This ensures that there any looping activity is carried out in the local scope and not against any shared objects */DECLARETABLE(IDINTNOT NULL, TableNamesysnameNOT NULL)INSERT INTO@TableList (ID,TableName)SELECTOBJECT_ID(TABLE_SCHEMA+'.'+TABLE_NAME),TABLE_NAMEFROMINFORMATION_SCHEMA.TABLESWHERETABLE_SCHEMA ='Reference'DECLARE@SQLVARCHAR(MAX) , @CRLFCHAR(2)SET@CRLF =CHAR(13)+CHAR(10)/*----------------------------------------------------------------------------- -- Generate SQL to remove all tables on the ISOAudit27001 schema Note that this is purely for use during the development phase and should be removed after the DB enters production. -----------------------------------------------------------------------------*/SELECT@SQL=COALESCE(@SQL+';'+@CRLF,'') +'DROP '+CASETABLE_TYPEWHEN'VIEW'THEN'VIEW 'ELSE'TABLE 'END+ QUOTENAME(TABLE_SCHEMA) +'.'+ QUOTENAME(TABLE_NAME)FROMINFORMATION_SCHEMA.TABLESWHERETABLE_SCHEMA='ISO27001Audit'EXEC(@SQL)-- Comment out to prevent accidentsGO/*----------------------------------------------------------------------------- For any reference table that does not have an equivalent ISO27001Audit table run the 3 building procs. -----------------------------------------------------------------------------*/DECLARE@TableIDINT SET@TableID = 0DECLARE@TableIDListTABLE(TableIDINTNOT NULLPRIMARY KEY CLUSTERED)INSERT INTO@TableIDList(TableID)SELECTOBJECT_ID(QUOTENAME(SRC.TABLE_SCHEMA)+'.'+QUOTENAME(SRC.TABLE_NAME))FROMINFORMATION_SCHEMA.TABLESASSRC LEFT JOININFORMATION_SCHEMA.TABLESASDESTONSRC.TABLE_CATALOG = DEST.TABLE_CATALOG AND SRC.TABLE_NAME = DEST.TABLE_NAME AND DEST.TABLE_SCHEMA='ISO27001Audit'WHERESRC.TABLE_SCHEMA ='Reference'AND SRC.TABLE_TYPE ='BASE TABLE'WHILE@TableID IS NOT NULLBEGIN SELECT@TableID = MIN(TableID)FROM@TableIDListWHERETableID>@TableIDIF@TableID IS NOT NULLBEGIN EXECdbo.BuildISO27001AuditTable @TableIDEXECdbo.BuildISO27001AuditUpdateTriggers @TableIDEXECdbo.BuildISO27001AuditDeleteTriggers @TableIDEND END GO
Stored Proc - dbo.BuildISO27001AuditTable
This table was to build the actual audit table itself, largely by copying the structure of its parent "Reference" table.
CREATE PROCdbo.BuildISO27001AuditTable @TableIDINT--##PARAM @TableID The object_id value of a valid user table not in the ISO27001 schema. The proc will validate the object_id.AS SET NOCOUNT ON BEGIN TRY DECLARE@Schemaname sysname, @ObjectNamesysname@Schemaname = OBJECT_SCHEMA_NAME(@TableID)-- Resolve the supplied @TableID back into an schema and object nameSETSET@ObjectName = OBJECT_NAME(@TableID)IF@ObjectName IS NULLOR@Schemaname IS NULLRAISERROR('*** Cannot identify object_id %i',16,1,@TableID)IF@SchemaName='ISO27001Audit'RAISERROR('*** Object %s.%s is in IS27001Audit schema',16,1,@SchemaName,@ObjectName)IFOBJECTPROPERTY(@TableID,'IsUserTable')=0 OR @ObjectName='sysdiagrams'RAISERROR('*** Object %s.%s not a user table',16,1,@SchemaName,@ObjectName)-- Build field definitionsDECLARE@SQLVARCHAR(8000) , @CRLFCHAR(2)SET@CRLF =CHAR(13)+CHAR(10)SELECT@SQL=COALESCE(@SQL+','+@CRLF,'') + C.name-- field name+' '+ T.name-- datatype name+CASE WHENT.NAME='VARCHAR'and c.max_length = -1THEN'(MAX)'WHENT.NAME='VARCHAR'and c.max_length > -1THEN'('+ CAST(C.max_lengthAS VARCHAR(10))+')'WHENT.NAME='NVARCHAR'and c.max_length = -1THEN'(MAX)'WHENT.NAME='NVARCHAR'and c.max_length > -1THEN'('+ CAST(C.max_length/2AS VARCHAR(10))+')'WHENT.NAME='CHAR'THEN'('+ CAST(C.max_lengthAS VARCHAR(10))+')'WHENT.NAME='NCHAR'THEN'('+ CAST(C.max_length/2AS VARCHAR(10))+')'WHENT.NAME='decimal'THEN'('+ CAST(C.precisionAS VARCHAR(10))+','+CAST(C.scaleAS VARCHAR(10))+')'ELSE''END+' '+CASEC.is_nullableWHEN0THEN'NOT 'ELSE''END+'NULL'-- Handle NULL / NOT NULLFROMsys.columnsASC INNER JOINsys.typesASTONC.system_type_id = T.system_type_idWHEREC.object_id=@TableID AND T.name<>'sysname'-- There will be both a sysname and NVARCHAR(128) datatype in systypes so this eliminates dupes.AND C.name NOT IN ('LastUpdatedUser','CreatedDate','UpdatedDate')-- The ISO27001Audit tables will have their own implementation of theseAND c.is_computed=0ORDER BYC.column_idSET@SQL ='IF NOT EXISTS(SELECT 1 FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME='''+ @ObjectName +''' AND TABLE_SCHEMA=''ISO27001Audit'')'--Does the desired audit table already exist?+ @CRLF +'BEGIN'+ @CRLF +'CREATE TABLE ISO27001Audit.'+ @ObjectName +'('+ @SQL +',OriginalAuthor VARCHAR(128) NOT NULL,AuditTriggeringAuthor VARCHAR(128) NOT NULL,AuditDate DATETIME NOT NULL CONSTRAINT DF_'+ @ObjectName +'_AuditDate DEFAULT CURRENT_TIMESTAMP,OriginalCreateDate DATETIME NOT NULL, AuditAction CHAR(1) NOT NULL CONSTRAINT CK_'+ @ObjectName +'_AuditAction CHECK (AuditAction IN(''U'',''D''))'+ @CRLF +') ON FGAudit'+ @CRLF +'PRINT ''TABLE CREATED: ISO27001Audit.'+ @ObjectName +''''+ @CRLF +'END'+ @CRLF +'ELSE'+ @CRLF +'PRINT ''TABLE ALREADY EXISTS: ISO27001Audit.'+ @ObjectName +''''EXEC(@SQL)END TRY BEGIN CATCH EXECdbo.GetSQLErrorInfoEND CATCHGO
The purpose of the ISO27001Audit table is to capture the previous versions of any record together with the details of who caused the auditing action and when.
If we use our Reference.SalutationTitle example then the difference between the Reference and ISO27001Audit tables is best illustrated below:-
Reference Ordinal Position | ISO27001Audit Ordinal Position | Comment |
|---|---|---|
| SalutationTitleID | SalutationTitleID | Straight copy of the previous record |
| SalutationTitle | SalutationTitle | |
| GenderID | GenderID | |
| Active | Active | |
| DisplayOrder | DisplayOrder | |
| LastUpdatedUser | OriginalAuthor | |
| CreateDate | This is the date on which the original record was created. | |
| UpdatedDate | OriginalCreateDate | Straight copy of the previous record |
| AuditTriggeringAuthor | Defaults to the currently logged on user name revealed by SUSER_SNAME(). This should be the same as the LastUpdatedUser in the main Reference Table | |
| AuditDate | Defaults to the current system date CURRENT_TIMESTAMP. Again, this should be the same as the UpdatedDate in the Reference table | |
| AuditAction | U = Update D = Delete |
dbo.BuildISO27001AuditDeleteTriggers
One again, given a few simple rules each reference data table can have a delete trigger defined on it. The reason I use a trigger rather than embed it in a delete stored proc is that I want the audit action to happen irrespective of whether the reference data record was deleted by a stored proc or direct SQL on the table.
CREATE PROCdbo.BuildISO27001AuditDeleteTriggers @TableIDINT--##PARAM @TableID The object_id value of a valid user table not in the ISO27001 schema for which an audit for deletion trigger will be created. The proc will validate the object_id.AS SET NOCOUNT ON BEGIN TRY DECLARE@Schemanamesysname, @ObjectNamesysnameDECLARE@SQLVARCHAR(8000), @InsertListVARCHAR(8000), @SelectListVARCHAR(8000), @CRLFCHAR(2),-- These cosmetic control characters are used to ensure that the resulting code is@TABCHAR(1)-- easily readableSET@Schemaname = OBJECT_SCHEMA_NAME(@TableID)SET@ObjectName = OBJECT_NAME(@TableID)SET@CRLF =CHAR(13)+CHAR(10)-- For cosmetic purposes onlySET@TAB =CHAR(9)IF@ObjectName IS NULL OR @Schemaname IS NULL-- Make sure the object is validRAISERROR('*** Cannot identify object_id %i',16,1,@TableID)IF@SchemaName='ISO27001Audit'-- Do not attempt to create audit tables on audit tables.RAISERROR('*** Object %s.%s is in ISO27001Audit schema',16,1,@SchemaName,@ObjectName)IFOBJECTPROPERTY(@TableID,'IsUserTable')=0 OR @ObjectName='sysdiagrams'-- Make sure you are not trying to audit system tables.RAISERROR('*** Object %s.%s not a user table',16,1,@SchemaName,@ObjectName)/* Build up the list of columns for which values will be copied */DECLARE @ColumnList TABLE ( ColumnID INT NOT NULL PRIMARY KEY clustered, ColumnName sysname NOT NULL , IsPrimary BIT NOT NULL ) INSERT INTO @ColumnListSELECTC.column_id,C.name,CASE WHENIC.column_id IS NOT NULLTHEN1ELSE0ENDFROMsys.columnsASCLEFT JOINsys.indexesASI ON C.object_id = I.object_id AND I.is_primary_key=1LEFT JOINsys.index_columnsASIC ON I.index_id = IC.index_id AND C.object_id = IC.object_id AND C.column_id = IC.column_idWHEREC.object_id = @TableID AND C.name NOT IN ('LastUpdatedUser','CreatedDate','UpdatedDate') AND c.is_computed=0ORDER BYC.column_idSELECT@InsertList=COALESCE(@InsertList+','+@CRLF,'') + @TAB + C.ColumnnameFROM@ColumnList AS CORDER BYC.columnidSET@InsertList = @InsertList +','+ @CRLF +' OriginalAuthor, AuditTriggeringAuthor, AuditDate, OriginalCreateDate, AuditAction ) SELECT '+ @CRLFSELECT@SelectList=COALESCE(@SelectList+','+@CRLF,'') + @TAB +'D.'+ C.ColumnnameFROM@ColumnList AS CORDER BYC.columnidSET@SelectList = @SelectList +', D.LastUpdatedUser, SUSER_SNAME(), CURRENT_TIMESTAMP, D.UpdatedDate, ''D'''SET@SQL ='IF EXISTS(SELECT * FROM sys.triggers WHERE name = '''+ @ObjectName +'_OnDelete'' AND parent_id='+ CAST(@TableIDAS VARCHAR(10)) +')'+ @CRLF +'BEGIN'+ @CRLF +'DROP TRIGGER '+ @Schemaname +'.'+ @ObjectName +'_OnDelete'+ @CRLF +'PRINT ''TRIGGER DROPPED: '+ @Schemaname +'.'+ @ObjectName +':'+ @ObjectName +'_OnDelete'+ '''' + @CRLF +'END;'EXEC(@SQL)SET@SQL=-- *** START OF AUTO-DOCUMENTATION TAGS - Exclude down to END OF AUTO-DOCUMENTATION TAGS if not using tag based autodocumentation tool ***+'--##SUMMARY Records the original record from '+ @Schemaname +'.'+ @ObjectName +' into ISO27001Audit.'+ @ObjectName +' when records are deleted.'+ @CRLF +'--##HISTORY <strong>'+ REPLACE(CONVERT(CHAR(11),CURRENT_TIMESTAMP,106),' ','-') +'</strong> '+CASE WHENCHARINDEX('\',SUSER_SNAME())>0THENSUBSTRING(SUSER_SNAME(),CHARINDEX('\',SUSER_SNAME())+1,128)ELSESUSER_SNAME()END+' Initial creation'+ @CRLF +'--##ISNEW '+ REPLACE(CONVERT(CHAR(11),CURRENT_TIMESTAMP-30,106),' ','-') + @CRLF-- *** END OF AUTO-DOCUMENTATION TAGS ***+'CREATE TRIGGER '+ @Schemaname +'.'+ @ObjectName +'_OnDelete ON '+ @Schemaname +'.'+ @ObjectName +' FOR DELETE AS'+ @CRLF +'SET NOCOUNT ON'+ @CRLF +'INSERT INTO ISO27001Audit.'+ @ObjectName +'('+ @CRLF + @InsertList + @SelectList + @CRLF +'FROM DELETED AS D'EXEC(@SQL)END TRY BEGIN CATCH EXECdbo.GetSQLErrorInfoEND CATCH GO
If this proc is run against the Reference.SalutationTitle table then the resulting trigger would be as shown below:-
--##SUMMARY Records the original record from reference.SalutationTitle into ISO27001Audit.SalutationTitle when records are deleted. --##HISTORY <strong>25-Nov-2012</strong> David Initial creation --##ISNEW 26-Oct-2012CREATE TRIGGER[reference].[SalutationTitle_OnDelete]ON[reference].[SalutationTitle]FOR DELETE AS SET NOCOUNT ON INSERT INTOISO27001Audit.SalutationTitle( SalutationTitleID, SalutationTitle, GenderID, Active, DisplayOrder, OriginalAuthor, AuditTriggeringAuthor, AuditDate, OriginalCreateDate, AuditAction )SELECTD.SalutationTitleID, D.SalutationTitle, D.GenderID, D.Active, D.DisplayOrder, D.LastUpdatedUser, SUSER_SNAME(), CURRENT_TIMESTAMP, D.UpdatedDate, 'D'FROMDELETEDASDGO
dbo.BuildISO27001AuditUpdateTriggers
The creation of the update trigger uses exactly the same method but is slightly more complicated because it must deal with both the "deleted" and "inserted" tables and also have some logic to check that the relevant fields have actually been updated.
CREATE PROCdbo.BuildISO27001AuditUpdateTriggers @TableIDINT--##PARAM @TableID The object_id value of a valid user table not in the ISO27001 schema for which an audit for update trigger will be created. The proc will validate the object_id.AS SET NOCOUNT ON BEGIN TRY DECLARE@Schemanamesysname, @ObjectNamesysnameDECLARE@SQLVARCHAR(8000), @InsertListVARCHAR(8000), @SelectListVARCHAR(8000), @FromListVARCHAR(8000), @WhereListVARCHAR(8000), @CRLFCHAR(2), @TABCHAR((1)SET@Schemaname = OBJECT_SCHEMA_NAME(@TableID)SET@ObjectName = OBJECT_NAME(@TableID)SET@CRLF =CHAR(13)+CHAR(10)-- For cosmetic purposes onlySET@TAB =CHAR(9)IF@ObjectName IS NULL OR @Schemaname IS NULL-- Make sure the object is validRAISERROR('*** Cannot identify object_id %i',16,1,@TableID)IF@SchemaName='ISO27001Audit'-- Do not attempt to create audit tables on audit tables.RAISERROR('*** Object %s.%s is in ISO27001Audit schema',16,1,@SchemaName,@ObjectName)IFOBJECTPROPERTY(@TableID,'IsUserTable')=0 OR @ObjectName='sysdiagrams'-- Make sure you are not trying to audit system tables.RAISERROR('*** Object %s.%s not a user table',16,1,@SchemaName,@ObjectName)DECLARE@ColumnListTABLE( ColumnIDINTNOT NULL PRIMARY KEY clustered, ColumnNamesysnameNOT NULL , IsPrimaryBITNOT NULL )INSERT INTO@ColumnListSELECTC.column_id,C.name,CASE WHENIC.column_id IS NOT NULLTHEN1ELSE0ENDFROMsys.columnsASC LEFT JOIN sys.indexesASIONC.object_id = I.object_id AND I.is_primary_key=1 LEFT JOIN sys.index_columnsASICONI.index_id = IC.index_id AND C.object_id = IC.object_id AND C.column_id = IC.column_idWHEREC.object_id = @TableID AND C.name NOT IN ('LastUpdatedUser','CreatedDate','UpdatedDate') AND c.is_computed=0ORDER BYC.column_id-- Build the field list for the INSERT INTO(...) statementSELECT@InsertList=COALESCE(@InsertList+','+@CRLF,'') + @TAB + C.ColumnnameFROM@ColumnList AS CORDER BYC.columnid-- This is very important because the INSERT/SELECT statements have to match-- Append the standard fields used by all tables for the INSERT INTO(...) statementSET@InsertList = @InsertList +','+ @CRLF +' OriginalAuthor, AuditTriggeringAuthor, AuditDate, OriginalCreateDate, AuditAction ) SELECT '+ @CRLFSELECT@SelectList=COALESCE(@SelectList+','+@CRLF,'') + @TAB +'D.'-- the D is going to be the alias for the "deleted" table+ C.ColumnnameFROM@ColumnList AS CORDER BYC.columnidSET@SelectList = @SelectList +', D.LastUpdatedUser, I.LastUpdatedUser, CURRENT_TIMESTAMP, D.UpdatedDate, ''U'''/* The @FROMList creates the join statement on the primary key field(s) It will cope with compound primary keys. */SELECT@FROMList=COALESCE(@FROMList+' AND '+@CRLF,'') +'D.'+ C.Columnname +' = I.'+ C.ColumnnameFROM@ColumnList AS CWHEREIsPrimary = 1ORDER BYC.columnidSET@FROMList ='FROM INSERTED AS I INNER JOIN DELETED AS D ON '+ @FROMList/* The @WHEREList differs from the @FROMList as follows:- 1. @FROMList joins on the primary key field(s) and uses the AND clause for compound primary keys 2. @WHEREList compares on anything that is NOT the primary key and uses the OR clause between fields. */SELECT@WHEREList=COALESCE(@WHEREList+' OR '+@CRLF,'') + @TAB +'D.'+ C.Columnname +' <> I.'+ C.ColumnnameFROM@ColumnList AS CWHEREC.IsPrimary = 0ORDER BYC.columnidSET@SQL ='IF EXISTS(SELECT * FROM sys.triggers WHERE name = '''+ @ObjectName +'_OnUpdate'' AND parent_id='+ CAST(@TableID ASVARCHAR(10)) +')'+ @CRLF +'BEGIN'+ @CRLF +'DROP TRIGGER '+ @Schemaname +'.'+ @ObjectName +'_OnUpdate'+ @CRLF +'PRINT ''TRIGGER DROPPED: '+ @Schemaname +'.'+ @ObjectName +':'+ @ObjectName +'_OnUpdate'+''''+ @CRLF +'END;'EXEC(@SQL)SET@SQL=-- *** START OF AUTO-DOCUMENTATION TAGS - Exclude down to END OF AUTO-DOCUMENTATION TAGS if not using tag based autodocumentation tool ***+'--##SUMMARY Records the original record from '+ @Schemaname +'.'+ @ObjectName +' into ISO27001Audit.'+ @ObjectName +' but only if there has been a change in fields not participating in the primary key.'+ @CRLF +'--##HISTORY <strong>'+ REPLACE(CONVERT(CHAR(11),CURRENT_TIMESTAMP,106),' ','-') +'</strong> '+CASE WHENCHARINDEX('\',SUSER_SNAME())>0THENSUBSTRING(SUSER_SNAME(),CHARINDEX('\',SUSER_SNAME())+1,128)ELSESUSER_SNAME()END+' Initial creation'+ @CRLF +'--##ISNEW '+ REPLACE(CONVERT(CHAR(11),CURRENT_TIMESTAMP,106),' ','-') + @CRLF-- *** END OF AUTO-DOCUMENTATION TAGS ***+'CREATE TRIGGER '+ @Schemaname +'.'+ @ObjectName +'_OnUpdate ON '+ @Schemaname +'.'+ @ObjectName +' FOR UPDATE AS'+ @CRLF +'SET NOCOUNT ON'+ @CRLF +'INSERT INTO ISO27001Audit.'+ @ObjectName +'('+ @CRLF + @InsertList + @SelectList + @CRLF + @FromList + @CRLF +'WHERE '+ @CRLF + @WHEREListEXEC(@SQL)END TRY BEGIN CATCH EXECdbo.GetSQLErrorInfoEND CATCH GO
Again, if this proc is run against the Reference.SalutationTitle table then the resulting update trigger would be as shown below:-
--##SUMMARY Records the original record from reference.SalutationTitle into ISO27001Audit.SalutationTitle but only if there has been a change in fields not participating in the primary key. --##HISTORY <strong>25-Nov-2012</strong> David Initial creation --##ISNEW 25-Nov-2012CREATE TRIGGER[reference].[SalutationTitle_OnUpdate]ON[reference].[SalutationTitle]FOR UPDATE AS SET NOCOUNT ON INSERT INTOISO27001Audit.SalutationTitle( SalutationTitleID, SalutationTitle, GenderID, Active, DisplayOrder, OriginalAuthor, AuditTriggeringAuthor, AuditDate, OriginalCreateDate, AuditAction )SELECTD.SalutationTitleID, D.SalutationTitle, D.GenderID, D.Active, D.DisplayOrder, D.LastUpdatedUser, I.LastUpdatedUser, CURRENT_TIMESTAMP, D.UpdatedDate, 'U'FROMINSERTEDASI INNER JOIN DELETEDASDOND.SalutationTitleID = I.SalutationTitleIDWHERED.SalutationTitle <> I.SalutationTitle OR D.GenderID <> I.GenderID OR D.Active <> I.Active OR D.DisplayOrder <> I.DisplayOrderGO
The advantages of autogenerated code
The ability to auto-generate code has an obvious benefit in terms of being able to the volume of code required in the shortest time possible.
Putting together the code in the first place is the time consuming part but by its very nature the code is reusable in a number of cases and therefore should contribute to a DBA's toolkit.
The other advantages as I see it are as follows:-
- Code consistency. Consistent code can be much easier to read
- Fix it once, fix it everywhere. If a bug is discovered in auto-generated code then fixing the auto-generator means that a wide-scale fix can be deployed in seconds.
- Once the benefits are recognised the ability to auto-generate code triggers a thought process of "how can I design such that auto-generation (and therefore code resuse) is more easily achieved"?
Challenge Nine - Keeping the unified set up-to-date
Once again I am kicking myself for not recording precisely where I got the source metadata.
Under "Challenge Three" I mentioned that it might be beneficial to set up type 4 slow changing dimensions on the reference data in the original source system.
The reason being that data is collected from independent systems that have no awareness of the unified dataset. There is little to stop the users of one system changing the source reference data and in the worst case, altering the meaning that is assigned to a particular key. Unless the unified reference data set deals with this scenario then it faces the risk that a lot of hard work will be lost and the dataset will become stale.
The particular challenge here is that each source system can change independently so an automated process isn't going to work.
- Widget System Id 1 = Master
- Grommet System Id 5 = Master
- Unified Reference data set Id 1 = Master (Both preceding records map to Unified Id 1.
What happens if Widget System recodes Id 1 = Mr and Grommet system recodes Id 5 to Ms.
In this simple example you may be able to auto-remap the data as the data is very simple but fundamentally the task is to decide if a change of semantic meaning has taken place.
One possible solution is to store not only the source key but also the source data that the key represents in my dbo.ReferenceTranslationStandardistion table and implement a slow changing dimension strategy on the translation table itself. This convinces me that a single central translation table is a flawed design and can be held up as an example why the one-true-lookup-table is an embuggerance to be avoided.
The ability to see the source data clearly mapped to target data is essential, especially so as the number of tables grow. Thus a translation table per reference data dataset with mandatory DRI enforcement demonstrates its worth.
Challenge Ten - Unified reference data beyond the data warehouse
The original intent of unifying the reference data was to provide a common frame of reference for the customers of the data warehouse/mart.
Of course once the organisation has achieved a common set of reference data the data warehouse the natural evolution is to investigate whether a standard view of the world can be pushed back up into the source systems. This throws up some interesting challenges.
- What do you do if a unified dataset contains more entries than any of the source systems?
- What do you do if the source systems present data differently?
At this stage I would say that you should not accept the challenge or try to initiate such a project unless there is a real and strong non-IT drive for source systems across the enterprise to have a shared view of the world. For a total rewrite it may be possible to adopt a subsetted view of reference data but for brownfield developments it is likely to be more trouble than it is worth. The ability to translate from a source system to a unified view is usually sufficient.
But how would we approach such a challenge in any case?
In my case I proposed a "scenario" based view of the reference data and for this purpose I created a "ReferenceScenario" schema in my database.
Step one: Create a reference table holding a list of scenarios
Using the standard pattern described in "Challenge Four - The structure of the reference data tables" I created my ReferenceScenarioMaster table that held a single record
| ReferenceScenarioMasterId | ReferenceScenarioMaster |
|---|---|
| 0 | Global |
The idea of this "global" entry is that it will represent the enterprise wide desired view of reference data. The tables in the reference schema represent the totality of the reference data including all the mis-keyings, mis-spellings and (worryingly) test data.
Step Two: Create a script and proc to build the "ReferenceScenario" tables
Using exactly the same technique as described in "Challenge Eight - Implementing the slow changing dimension strategy" I generated all the reference data scenario tables.
/*----------------------------------------------------------------------------- Builds a shadow audit table in the ISO27001Audit schema based on the structure of the table in the Reference schema. -----------------------------------------------------------------------------*/DECLARE@TableIDINT SET@TableID = 0DECLARE@TableIDListTABLE(TableIDINTNOT NULLPRIMARY KEY CLUSTERED)-- Grab Reference tables that do not already have a ReferenceScenario equivalentINSERT INTO@TableIDList(TableID)SELECTOBJECT_ID(QUOTENAME(SRC.TABLE_SCHEMA)+'.'+QUOTENAME(SRC.TABLE_NAME))FROMINFORMATION_SCHEMA.TABLESASSRC LEFT JOININFORMATION_SCHEMA.TABLESAS DESTONSRC.TABLE_CATALOG = DEST.TABLE_CATALOG AND SRC.TABLE_NAME = DEST.TABLE_NAME AND DEST.TABLE_SCHEMA='ReferenceScenario'WHERE SRC.TABLE_SCHEMA ='Reference'AND SRC.TABLE_TYPE = 'BASE TABLE' AND SRC.TABLE_NAME <>'ReferenceScenarioMaster'-- The ReferenceScenarioMaster table is a a stand-a-lone reference table-- Loop through all qualifying reference tables generating the ReferenceScenario equivalentWHILE@TableID IS NOT NULLBEGIN SELECT@TableID = MIN(TableID)FROM@TableIDListWHERETableID>@TableIDIF@TableID IS NOT NULLBEGIN EXECdbo.BuildReferenceScenarioTable @TableIDEND END GO
dbo.BuildReferenceScenarioTable
The proc that actually builds the ReferenceScenario table is shown below
CREATE PROCdbo.BuildReferenceScenarioTable @TableIDINT--##PARAM @TableID The object_id value of a valid user table not in the ISO27001 schema. The proc will validate the object_id.AS SET NOCOUNT ON BEGIN TRY----------------------------------------------------------------------------- -- Work out if the supplied ObjectID is a valid user table in one of the -- Reference schemas. -----------------------------------------------------------------------------DECLARE@SchemanameSYSNAME, @ObjectNameSYSNAME, @IndexNameSYSNAME, @NewTableNameSYSNAMESET@Schemaname = OBJECT_SCHEMA_NAME(@TableID)SET@ObjectName = OBJECT_NAME(@TableID)SET@NewTableName = @ObjectName+'Scenario'SET@IndexName ='idx_'+ @NewTableName +'_ScenarioID'IF@ObjectName IS NULL OR @Schemaname IS NULLRAISERROR('*** Cannot identify object_id %i',16,1,@TableID)IF@SchemaName IN('ISO27001Audit','ReferenceScenario')RAISERROR('*** Object %s.%s is in %s schema',16,1,@SchemaName,@ObjectName,@SchemaName) WITH NOWAITIFOBJECTPROPERTY(@TableID,'IsUserTable')=0 OR @ObjectName='sysdiagrams'RAISERROR('*** Object %s.%s not a user table',16,1,@SchemaName,@ObjectName)DECLARE@PKTableTABLE( TABLE_QUALIFIERSYSNAMENOT NULL , TABLE_OWNERSYSNAMENOT NULL , TABLE_NAMESYSNAMENOT NULL, COLUMN_NAMESYSNAMENOT NULL, KEY_SEQTINYINTNOT NULL, PK_NAMESYSNAMENOT NULL )INSERT INTO@PKTableEXECsp_pkeys@ObjectName,@Schemaname-- system stored proc to grab primary keysDECLARE@SQLVARCHAR(8000) , @CRLFCHAR(2), @PKStringVARCHAR(8000), @FKStringVARCHAR(8000)SET@CRLF =CHAR(13)+CHAR(10)----------------------------------------------------------------------------- -- Build up the field definition of the primary key fields in the parent -- Reference schema. -----------------------------------------------------------------------------SELECT@SQL=COALESCE(@SQL+','+@CRLF,'') + C.COLUMN_NAME +' '+ UPPER(C.DATA_TYPE) +CASE WHENC.DATA_TYPE IN('VARCHAR','NVARCHAR','CHAR','NCHAR') and C.CHARACTER_MAXIMUM_LENGTH > -1THEN'('+ CAST(C.CHARACTER_MAXIMUM_LENGTHAS VARCHAR(10))+')'WHENC.DATA_TYPE='decimal'THEN'('+ CAST(C.NUMERIC_PRECISIONASVARCHAR(10))+','+CAST(C.NUMERIC_SCALEASVARCHAR(10))+')'ELSE''END+' NOT NULL 'FROM@PKTable AS PK INNER JOIN INFORMATION_SCHEMA.COLUMNSASC ON PK.TABLE_OWNER = C.TABLE_SCHEMA AND pk.TABLE_NAME = C.TABLE_NAME AND pk.COLUMN_NAME = C.COLUMN_NAMEORDER BYPK.KEY_SEQ-- ensure that the primary key fields are in the same order as the originals.----------------------------------------------------------------------------- -- Build a commas separted list of fields participating in the Primary Key -----------------------------------------------------------------------------SELECT@PKString=COALESCE(@PKString+',','') + PK.COLUMN_NAMEFROM@PKTableASPKORDER BYPK.KEY_SEQ----------------------------------------------------------------------------- -- Build the foreign key DDL utilising the comma separated list of fields -- participating in the Primary Key -----------------------------------------------------------------------------SET@FKString = +','+ @CRLF +'CONSTRAINT FK_Scenario'+ @ObjectName +'_'+ @ObjectName +' FOREIGN KEY ('+ @PKString +') REFERENCES '+ @SchemaName+'.'+@ObjectName +'('+ @PKString +')'----------------------------------------------------------------------------- -- Add the ScenarioID field to the comma delimited list participating in the -- Primary Key and wrap that list up in the DDL necessary to generate the -- new primary key -----------------------------------------------------------------------------SET@PKString = + @CRLF +'CONSTRAINT PK_Scenario'+ @ObjectName +' PRIMARY KEY CLUSTERED('+ @PKString +',ScenarioId)'----------------------------------------------------------------------------- -- Add the mandatory table fields to the DDL that has so far been used -- to create the Primary Key -----------------------------------------------------------------------------SET@SQL = @SQL +','+ @CRLF +'ScenarioID SMALLINT NOT NULL CONSTRAINT FK_'+ @ObjectName +'_ReferenceScenarioMaster FOREIGN KEY REFERENCES Reference.ReferenceScenarioMaster(ReferenceScenarioMasterID),'+ @CRLF +'DisplayOrder SMALLINT NOT NULL CONSTRAINT DF_Scenario'+ @ObjectName +'_DisplayOrder DEFAULT(0),'+ @CRLF +'Active BIT NOT NULL CONSTRAINT DF_Scenario'+ @ObjectName +'_Active DEFAULT(1)'----------------------------------------------------------------------------- -- Wrap DDL up in the appropriate CREATE TABLE statments -----------------------------------------------------------------------------SET@SQL ='IF NOT EXISTS(SELECT 1 FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME='''+ @ObjectName +''' AND TABLE_SCHEMA=''ReferenceScenario'')'+ @CRLF +'BEGIN'+ @CRLF +'CREATE TABLE ReferenceScenario.'+ @ObjectName +'('+ @SQL +','+ @PKString + @FKString + @CRLF +') ON FGReference'+ @CRLF +'PRINT ''TABLE CREATED: ReferenceScenario.'-- Useful when reviewing the output from an automated build+ @ObjectName +''''+ @CRLF +'END'+ @CRLF +'ELSE'+ @CRLF +'PRINT ''TABLE ALREADY EXISTS: ReferenceScenario.'+ @ObjectName +''';'+ @CRLF-- PRINT @SQL -- For debug purposes.EXEC( @SQL)END TRY BEGIN CATCH EXECdbo.GetSQLErrorInfoEND CATCH GO
Step Three: Create "ReferenceScenario" tables for each table in the "Reference" schema
Looking at the ReferenceScenario tables generated from the script above we can see that they are little more than a mapping table between the reference table and ReferenceScenarioMaster as shown below:-
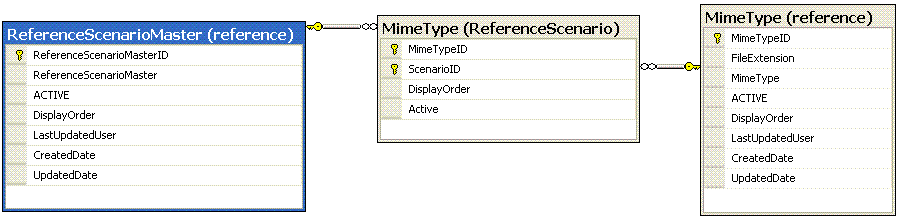
The difference being as follows:-
- The ReferenceScenario tables copy only the primary keys and add their own DisplayOrder and Active flag
- The ReferenceScenario tables add foreign keys between their "Reference" equivalent and "ReferenceScenarioMaster" table.
Challenge Eleven: Programmer access to reference data
The data I have described as reference data is not security sensitive and being in a data warehouse read-only access is appropriate to any legitemate audience.
If the maintenance of the reference data is to be handled by some form of application then the application developers can either use an ORM tool or, given that the reference tables subscribe to a limited set of standard patterns they might opt for a metadata driven approach.
The dbo.SourceType table contains the name of the different reference data sets and the equivalent reference data table. By adopting a pattern to the stored procedure names such as <Verb><Reference Table Name> a very simple user interface can cover a huge number of reference tables.
- AddMaritalStatus
- CopyMaritalStatus
- DeleteMaritalStatus
- GetMaritalStatusByID
- ListMaritalStatus
- SetMaritalStatus
- SetMaritalStatusActivationByID
Although this approach will make any application orientate towards the way an IT person sees data maintenance rather than how a business person would interact with information reference data changes so infrequently that such an approach is acceptable.
Naturally, if we can generate our ISO27001 and ReferenceScenario tables automatically then we can also generate the maintenance stored procedures automatically.
The example below shows the stored proc that generates the <Set><Reference Table Name> stored proc.
CREATE PROCdbo.BuildSetReferenceDataProcs @TableIDINT--##PARAM @TableID The object_id value of a valid user table not in the ISO27001 schema. The proc will validate the object_id.AS SET NOCOUNT ON BEGIN TRY DECLARE@SchemanameSYSNAME, @ObjectNameSYSNAME, @ProcNameSYSNAME, @GeneratingProcNameSYSNAME, @PrefixSYSNAME, @SuffixSYSNAMEDECLARE@SQLVARCHAR(8000), @SetListVARCHAR(8000), @FromListVARCHAR(8000), @WhereListVARCHAR(8000), @WherePKListVARCHAR(8000), @ParamSQLVARCHAR(1000), @CRLFCHAR(2), @TABCHAR(1), @KeyCountTINYINTSET@CRLF =CHAR(13)+CHAR(10)SET@TAB =CHAR(9)SET@GeneratingProcName=OBJECT_SCHEMA_NAME(@@PROCID)+'.'+OBJECT_NAME(@@PROCID)EXECdbo.GetObjectDetails-- Simply returns the schema and object name for a given object id@TableID = @TableID, @SchemaName = @SchemaNameOUTPUT, @ObjectName = @ObjectNameOUTPUTSET@Prefix ='Set'SET@Suffix =''SET@ProcName = @Schemaname+'.'+COALESCE(@Prefix,'')+@ObjectName+COALESCE(@Suffix,'')DECLARE@ColumnListTABLE( IDINTNOT NULLIDENTITY(1,1)PRIMARY KEY CLUSTERED, ColumnNameSYSNAMENOT NULL , DataTypeSYSNAMENOT NULL, IsPrimaryBITNOT NULL, MaximumCharacterLengthSMALLINTNOT NULL )------------------------------------------------------------------------------ -- Identify the primary key columns and their data types ------------------------------------------------------------------------------INSERT INTO@ColumnList( ColumnName, DataType,IsPrimary,MaximumCharacterLength )SELECTC.COLUMN_NAME, UPPER(C.DATA_TYPE) + CASEWHENC.DATA_TYPE IN ('VARCHAR','NVARCHAR') and c.CHARACTER_MAXIMUM_LENGTH = -1 then'(MAX)'WHENC.DATA_TYPE IN ('VARCHAR','NVARCHAR')and c.CHARACTER_MAXIMUM_LENGTH > -1 THEN '('+ CAST(C.CHARACTER_MAXIMUM_LENGTH ASVARCHAR(10))+')'WHENC.DATA_TYPE IN ('CHAR','NCHAR') THEN'('+ CAST(C.CHARACTER_MAXIMUM_LENGTH ASVARCHAR(10))+')'WHENC.DATA_TYPE='decimal'THEN'('+ CAST(C.NUMERIC_PRECISION ASVARCHAR(10))+','+CAST(C.NUMERIC_SCALE ASVARCHAR(10))+')'ELSE''END ASDATA_TYPE, 1ASIsPrimary, ISNULL(C.CHARACTER_MAXIMUM_LENGTH,0)FROMINFORMATION_SCHEMA.CONSTRAINT_COLUMN_USAGEASCU INNER JOININFORMATION_SCHEMA.TABLE_CONSTRAINTSASCON ON CU.TABLE_CATALOG = CON.TABLE_CATALOG AND CU.TABLE_SCHEMA = CON.TABLE_SCHEMA AND CU.TABLE_NAME = CON.TABLE_NAME AND CU.CONSTRAINT_NAME = CON.CONSTRAINT_NAME INNER JOININFORMATION_SCHEMA.COLUMNSASC ON CU.TABLE_CATALOG = C.TABLE_CATALOG AND CU.TABLE_NAME = C.TABLE_NAME AND CU.TABLE_SCHEMA = C.TABLE_SCHEMA AND CU.COLUMN_NAME = C.COLUMN_NAMEWHERECON.TABLE_NAME = @ObjectName AND CON.TABLE_SCHEMA = @SchemaName AND CON.CONSTRAINT_TYPE='PRIMARY KEY'AND COLUMNPROPERTY(@TableID,C.COLUMN_NAME,'IsComputed')=0ORDER BYc.ORDINAL_POSITION/*------------------------------------------------------------------------------ Record the number of fields participating in the primary key If there is only one field (excluding the ScenarioID) then we are going to present this to the developers as parameter @ID and field ID ------------------------------------------------------------------------------*/SET@KeyCount = @@ROWCOUNTIFEXISTS(SELECT1FROM@ColumnListWHEREColumnName='ScenarioID') AND @KeyCount>0SET@KeyCount = @KeyCount-1-- Add the remaining non-primary key columns to our tableINSERT INTO@ColumnList( ColumnName, DataType,IsPrimary ,MaximumCharacterLength)SELECTC.COLUMN_NAME, UPPER(C.DATA_TYPE) +CASEWHENC.DATA_TYPE IN ('VARCHAR','NVARCHAR') and c.CHARACTER_MAXIMUM_LENGTH = -1THEN'(''(MAX)'WHENC.DATA_TYPE IN ('VARCHAR','NVARCHAR')and c.CHARACTER_MAXIMUM_LENGTH > -1THEN'('+ CAST(C.CHARACTER_MAXIMUM_LENGTHASVARCHAR(10))+')'WHENC.DATA_TYPE IN ('CHAR','NCHAR')THEN'(''('+ CAST(C.CHARACTER_MAXIMUM_LENGTHASVARCHAR(10))+')'WHENC.DATA_TYPE='decimal'THEN'(''('+ CAST(C.NUMERIC_PRECISIONASVARCHAR(10))+','+CAST(C.NUMERIC_SCALEASVARCHAR(10))+')'ELSE''END ASDATA_TYPE, 0ASIsPrimary,ISNULL(C.CHARACTER_MAXIMUM_LENGTH,0)FROMINFORMATION_SCHEMA.COLUMNSASCWHEREC.TABLE_NAME = @ObjectName AND C.TABLE_SCHEMA = @SchemaName AND C.COLUMN_NAME NOT IN (SELECTColumnNameFROM@ColumnList) AND C.COLUMN_NAME NOT IN ('UpdatedDate','CreatedDate')-- As these are standard fields we do not need to include themAND COLUMNPROPERTY(@TableID,C.COLUMN_NAME,'IsComputed')=0-- As you cannot update a computed field exclude this from the list.ORDER BYC.ORDINAL_POSITION------------------------------------------------------------------------------ -- Build up the parameter definition, first for PK and then for ordinary. ------------------------------------------------------------------------------SELECT@ParamSQL = COALESCE(@ParamSQL +','+@CRLF,'') + @TAB +CASE WHEN@KeyCount = 1 AND ColumnName<>'ScenarioID'THEN'(''@ID ' + DataTypeELSE'@'+ ColumnName +' '+DataTypeENDFROM@ColumnListWHEREIsPrimary=1/* Any character field with a length>10 will be parameterised as @Name LastUpdateUser is explicitly excluded because SYSNAME fields are NVARCHAR(128) and thus meet the condition above The MimeType table is excluded because it has two character fields (MimeType & Extension) that would meet the condition above */SELECT@ParamSQL = COALESCE(@ParamSQL +','+@CRLF,'') + @TAB+'@'+CASE WHENDatatype LIKE'%char%'AND MaximumCharacterLength>=10 AND ColumnName<>'LastUpdatedUser'AND @ObjectName NOT LIKE'MimeType%'THEN'(''Name 'WHENDataType NOT LIKE'%Char'AND @ObjectName=ColumnNameTHEN'(''Name 'ELSEColumnNameEND+' '+ DataType +' = NULL'-- All non-primary key parameters default to NULLFROM@ColumnListWHEREIsPrimary=0------------------------------------------------------------------------------ -- Build up the Where clause based on the non-primary key fields ------------------------------------------------------------------------------SELECT@WhereList = COALESCE(@WhereList + @CRLF+'OR ',@TAB) + ColumnName +' <> COALESCE('+ CASEWHENDatatype LIKE'%char%'AND MaximumCharacterLength>=10 AND @ObjectName NOT LIKE'MimeType%'THEN'(''@Name'WHENDataType NOT LIKE'%Char'AND @ObjectName=ColumnNameTHEN'(''@Name 'ELSE'@'+ ColumnNameEND+','+ ColumnName +')'FROM@ColumnListWHEREIsPrimary = 0 AND ColumnName<>'LastUpdatedUser'------------------------------------------------------------------------------ -- Build up the Where PK selection clause based on the primary key fields ------------------------------------------------------------------------------SELECT@WherePKList = COALESCE(@WherePKList + @CRLF+'AND ',@TAB) + ColumnName +' = '+CASEWHEN@KeyCount = 1 AND ColumnName<>'ScenarioID'THEN'(''@ID'ELSE'@'+ ColumnNameEND FROM@ColumnListWHEREIsPrimary = 1------------------------------------------------------------------------------ -- Build up the SET clause but ensure that PK columns are always the first item ------------------------------------------------------------------------------SET@SetList = @TAB+'UpdatedDate = CURRENT_TIMESTAMP'SELECT@SetList = COALESCE(@SetList +','+@CRLF+@TAB,'') + ColumnName + CASEWHEN@ObjectName NOT LIKE'MimeType%'AND MaximumCharacterLength>=10 AND columnName<>'LastUpdatedUser'THEN'('' = COALESCE(@Name,'+ColumnName+')'WHEN@ObjectName=ColumnName and DataType NOT LIKE'%Char'THEN'('' = COALESCE(@Name,'+ColumnName+')'ELSE' = COALESCE(@'+ColumnName+','+ColumnName+')'ENDFROM@ColumnListWHEREIsPrimary = 0------------------------------------------------------------------------------ -- Build and execute the T-SQL necessary to detect whether or not the desired -- stored proc already exists or not. ------------------------------------------------------------------------------SET@SQL = dbo.GenerateDropProcSQL(@SchemaName,@ObjectName,@Prefix,@Suffix)--PRINT @SQLEXEC(@SQL)------------------------------------------------------------------------------ -- Build and execute the T-SQL necessary to generate the desired stored proc. ------------------------------------------------------------------------------SET@SQL='CREATE PROC '+ @ProcName + @CRLF + @ParamSQL + @CRLF +'AS'+ @CRLF +'SET NOCOUNT ON'+ @CRLF + @CRLF +'UPDATE '+ @SchemaName +'.'+ @ObjectName + @CRLF +'SET @LastUpdatedUser = COALESCE(@LastUpdatedUser,SUSER_SNAME()),'+ @CRLF + @SetList + @CRLF +'WHERE '+ @WherePKList + @CRLF +'AND ('+ @CRLF + @WhereList +')'+ @CRLF + @CRLF +'RETURN @@ROWCOUNT'-- PRINT @SQL -- Helpful in debuggingEXEC(@SQL)------------------------------------------------------------------------------ -- Build and execute the T-SQL necessary to grant execute permissions. ------------------------------------------------------------------------------SET@SQL='GRANT EXECUTE ON '+ @ProcName +' TO ReferenceAdmin'-- A database role set up explicitly to grant access to reference data maintenance procsEXEC(@SQL)EXEC('PRINT ''PROC CREATED: '+ @ProcName +'''')END TRY BEGIN CATCHEXECdbo.GetSQLErrorInfoEND CATCH GO
An example of a stored procedure produced by the above proc is as follows:-
CREATE PROCreference.SetDoorlockType @IDTINYINT, @NameVARCHAR(60) = NULL, @ActiveBIT= NULL, @DisplayOrderSMALLINT= NULL, @LastUpdatedUserVARCHAR(128) = NULLAS SET NOCOUNT ON UPDATEreference.DoorlockTypeSET@LastUpdatedUser = COALESCE(@LastUpdatedUser,SUSER_SNAME()), UpdatedDate = CURRENT_TIMESTAMP, DoorlockType = COALESCE(@Name,DoorlockType), Active = COALESCE(@Active,Active), DisplayOrder = COALESCE(@DisplayOrder,DisplayOrder), LastUpdatedUser = COALESCE(@LastUpdatedUser,LastUpdatedUser)WHEREDoorlockTypeID = @ID AND ( DoorlockType <> COALESCE(@Name,DoorlockType) OR Active <> COALESCE(@Active,Active) OR DisplayOrder <> COALESCE(@DisplayOrder,DisplayOrder))RETURN@@ROWCOUNTGO
There are a few points to note about this proc
- Single field primary keys will always be mapped to a parameter called @ID
- character fields where their name matches the table name or are the only character field will always be mapped to a table called @Name
- Any NULL parameters will simply cause the data for their field to remain the same.
- The return value will be zero or one.
The important point here is that by sticking to standard names for parameters this gives the option for generic application code.
Concluding thoughts
Producing a unified view of reference data for an organisation is a much larger undertaking than it might at first appear. I made some basic but fundamental mistakes in my design and I would hope to have the opportunity to correct them at a later date.
One of the principal reasons that data warehouse projects fail is that there are no clear requirements and with no clear requirements no clear business stakeholder. Much of this article has described the technical approach however all this will be wasted unless there is a business stakeholder to sponsor the ha'porth of tar to make the unified set as self sustaining as possible.
The concept of SQL that writes SQL (akin to reflection) is extremely useful. To get the most out of such techniques some thought has to be given to the design of the system upon which you wish to implement self-writing code. It is a technique where a lot of work has to be done upfront which limits is applicability so any design compromises to make it feasible have to be carefully balanced with the benefits.
Once again, hindsight is 20:20. Had I known then what I know now I would probably have extended my dbo.SourceType table to be sufficiently rich in metadata that all but the obscure reference data tables could be generated from that metadata.