

Recently I faced a task, as a part of regular maintenance, to rebuild all the indexes in the databases. Nothing special, but that instance of SQL Server has anywhere between 200 and 400 databases. Each of them is fairly small but it takes hours to rebuild indexes manually or even using an automated script if performed sequentially. Our company has a 24x7 operation schedule and the less time lost for maintenance processes the better.
So I’ve decided to try to use a multi–process approach and do in an automated fashion.
The basic idea behind this solution is to start a number of parallel processes and have each one to pickup a predefined list of the databases. Because of the fact that the number of databases in the server vary, a process should pickup it’s own unique databases so no processes are interfering with each other. It means that each process should define database names for rebuilding the indexes independently but without duplication. I have developed a stored procedure which can accept multiple parameters and rebuild the indexes. (Procedure for index rebuilding on a single database can be found in article ‘Checking Your Database Fragmentation Level’ by Nicholas Cain, published on 6/4/2004).I’ve decided to test it first using the update statistics command and set it up as a weekly maintenance job for the server.
SET QUOTED_IDENTIFIER ON
GO
SET ANSI_NULLS ON
GO
CREATE procedure dbo.p_updatestats
@db_start int = null,
@db_end int = null,
@howmanyprocesses int = null,
@process_no int = null
as
begin
declare @minid int,@maxid int,@cmd Nvarchar(2000), @errmsg varchar(50)
SET NOCOUNT ON
declare @tmpdbnm table (id int identity(1,1), dbnm varchar(128))
-- insert all databases
insert into @tmpdbnm(dbnm)
select name
from master..sysdatabases
where name not in ('tempdb','pubs','northwind','model','master','msdb')
order by name
IF (@db_start is null)
set @db_start = 0
IF (@db_end is null)
set @db_end = 10000
IF ( @howmanyprocesses > 0)
BEGIN
IF ( ( @process_no is null ) OR ( @process_no <= 0 ))
begin
select @errmsg = 'Error: @process_no is null, less, or equal 0'
goto ERROR
end
IF ( @process_no > @howmanyprocesses )
begin
select @errmsg = 'Error: @process_no bigger than @howmanyprocesses'
goto ERROR
end
-- get start and end point.Last process always picks from start point to the
-- end of all databases
select @db_start = (Floor(count(1)/@howmanyprocesses) * (@process_no - 1)) + 1
, @db_end = CASE
WHEN @howmanyprocesses = @process_no THEN 10000
ELSE ( Floor(count(1)/@howmanyprocesses) * @process_no )
END
from @tmpdbnm
END
delete from @tmpdbnm
where id < @db_start
or id > @db_end
select @minid = min(id), @maxid = max(id) from @tmpdbnm
WHILE (@minid <= @maxid)
BEGIN
-- start loop while
-- update statts for ONE DATABASE AT A TIME
-- start - replaceable part for various processes
select @cmd = '
USE ' + DBNM +
'
declare @cmd1 nvarchar(500)
declare @dt datetime
set @dt = getdate()
print '' Start update statistics for the database ' + dbnm + ' '' + cast(@dt as varchar) + ''
''
select @cmd1 = ''exec sp_updatestats ''
EXEC sp_executesql @cmd1
set @dt = getdate()
print ''End update statistics for the database ' + dbnm + ' '' + cast(@dt as varchar)
print ''************************************************************
''
'
FROM @tmpdbnm
where id = @minid
-- end - replaceable part for various processes
exec (@cmd)
select @minid = @minid + 1
END
-- end loop while
goto END_PROC
ERROR:
select @errmsg = 'Error inproc ' + isnull(@errmsg,' ')
raiserror (@errmsg, 16, 1)
END_PROC:
end
GO
SET QUOTED_IDENTIFIER OFF
GO
Parameters are:
@db_start – starting database number for the index rebuilding process
@db_end – ending database number for the index rebuilding process
If @db_start is NULL and @db_end is NULL the process will issue a command on all databases. If db_start is NULL but @db_end has a value then process will issue a command for the databases between 1 and @db_end. If @db_start has a value but @db_end is NULL then the command will be invoked starting from @db_start for all remaining databases.
These parameters facilitate issuing a command sequentially for the specific number of databases.
The other 2 parameters facilitate parallel processing.
@howmanyprocesses – declare how many processes will run in parallel
@process_no – shows the process number for this one
If parameter @howmanyprocesses exists procedure will ignore @db_start and @db_end, divide all databases between processes and pickup databases based on the @process_no. For example, the system will run 6 processes in parallel. Then parameter values can be
Exec p_reindex
@db_start = null, @db_end = null, @howmanyprocesses = 6, @process_no = 2
Parameter @howmanyprocesses should be 6 and @process_no can be 1,2,3,4,5,6.
The next task is how to make them run in parallel automatically. There are few options. VBS can be used to program 6 parallel calls to the procedure. Query analyzer can be used to run 6 parallel processes manually. I’ve chosen to use DTS packages to accomplish my goal. See diagrams below.
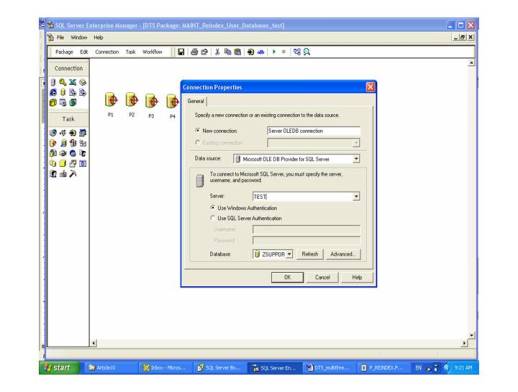
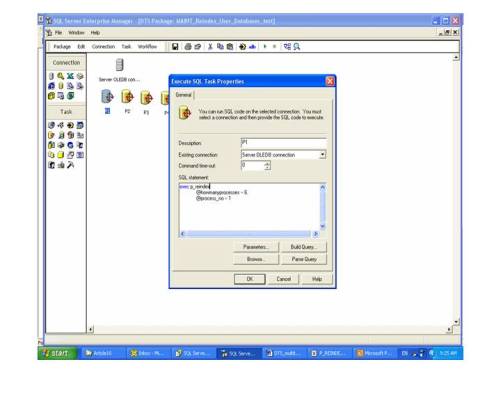
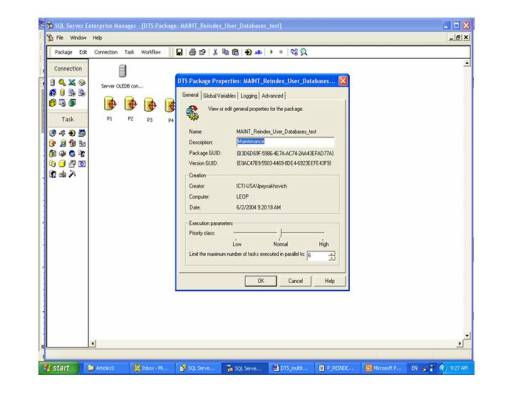
The DTS package has a connection object (see diagram 1). To setup a number of parallel processes use property of the DTS package ‘Limit the number of tasks running in parallel’ (see diagram 3). Then create the same number of SQL Tasks for the DTS package (see diagram 2). Save DTS. Now you can manually run the DTS package or schedule it for execution.
The source code for the process of rebuilding indexes on all databases is in stored procedure P_REINDEX.TXTand it works the same way as described above.
In my case for the databases re-indexing, I was able to get the process time down to 1 hour from 4 hours. The total elapsed time is not proportional to the number of databases because the CPU is utilized much more efficiently by the parallel processes. It is not recommended to make more than 5-6 parallel processes for this specific task because a higher number may cause a heavy load on the server CPU and may drive it to 100% utilization. As a DBA you need to find the optimal compromise between the server load and a number of running processes. I found that 4-6 are good numbers that allow me not only re-index databases but run some other tasks as well.
For sake of readability the procedure’ source code doesn’t include an error handler, some validation checks, and some advanced features. It is, however, fully tested and remains completely usable.
Conclusion
I have demonstrated here only 2 samples of how to use the process, but the same technique can be used for any other task that requires running processes in parallel. For example, I am using it to expedite recompilation of all stored procedures for all databases, and run some other DBCC commands. And as I mentioned above, the number of processes that are running in parallel should be carefully chosen. The stored procedure shown in the article can be used as a wrapper for all such processes.