

One of the new features that came with SQL 2005 was the ability to disable an
index. On the surface that sounds interesting, but in practice I'm not sure it's
a something many of us will use often. Today we'll explore the topic and see
what you think.
We'll start by reviewing what it does:
- Disabling a non clustered index leaves the current index on disk but
marks it so that it is no longer maintained (no savings in disk space,
savings from not maintaining it as rows change)
- Disabling a clustered index makes the table unavailable (a neat trick,
but useful?)
- You cannot disable a primary key (which is enforced using an index) if
the table is published as part of a transactional replication publication
- If you disable an index on an indexed view the index data is deleted
(different than for standard clustered/non clustered as above)
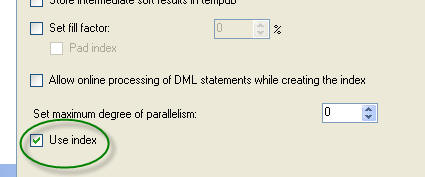
- To enable an index we have to rebuild it (or check the 'use index' box
on the index options table, which also triggers a rebuild)
So why use it?
- A service pack may disable an index and warn you so that you can rebuild
when it's complete it it cannot guarantee the data is valid (niche scenario
I think)
- Work around a disk IO error on an index page
- Removing the index because you think you no longer need it
- Rebuilding an index when space is short because this way we don't keep
the original copy on disk, freeing up that space
Of those the only one I think we might find interesting on a day to day basis
is to disable an index for troubleshooting. If you were using SQL 2000 and
thought that there was index that was no longer needed, the typical DBA response
was to script out the index and then drop it. Scripting it out first was our
safety net in case we were wrong! In SQL 2005 we can substitute the use of
disable to achieve the same thing, as long as we remember to return to delete
the index once we know all is well. Otherwise the next DBA will be wondering if
the index is supposed to be disabled or should it be dropped.
The other reasons aren't compelling; we can achieve the same effect by
dropping the index and recreating it (the exception being the behavior of the
service pack). My first thought when I heard about the behavior was that it
would be interesting for bulk load scenarios where we would typically remove all
the indexes. Rather than having to generate the drop and create statements, we
could just disable all the indexes, load, and then rebuild all at the end. But
disabling the clustered index doesn't really work because it makes the table
unavailable. If I have to script out one index I can just as easily script them
all out.
There are a few different ways to set an index to disabled. Believe it or
not, the first way is when you create the index in Management Studio. This is
the option tab:
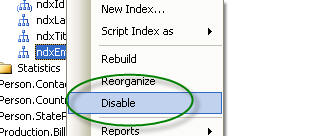
Once an index has been created the easiest way to disable it is by just right
clicking on the index, then selecting disable:
Or we can use TSQL:
alter
index ndxEmailAddress on Person.Contact disable
Attemping to disable the clustered index does bring up a nice warning dialog:
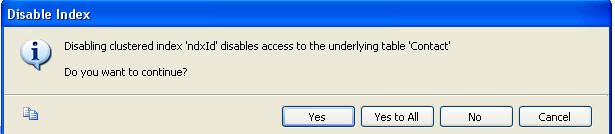
If we proceed and then follow up with a select against the table, we get this
nice error message:

Strangely there is no corresponding 'enable' function on the right click
menu, nor do the indexes show as disabled in the Object Explorer view (at least
on my machine!), though we can easily see which indexes have been disabled by
running this query:
select * from sys.indexes where is_disabled = 1
As mentioned earlier to bring an index back online (enabled) it is necessary
to rebuild it. That may sound bad, but it's no more work than would have been
required if we dropped the index and then decided to add it back later.
So that's a quick run through of a feature that doesn't turn out to be all
that useful to me. What about you, do you prefer disabling over dropping just as
a way to do a task, or have you found a more interesting point of view that
leads you to prefer disabling? Comments welcome in the attached discussion
forum!
I blog frequently at
http://blogs.sqlservercentral.com/andy_warren/default.aspx, come visit.
