

Relational Databases are known for their atomic, consistent, independent and durable properties (ACID). The first version of Apache Spark was released in 2014 However, the tables in the hive catalog did not have any ACID properties at that time. That was because the hive catalog stored the schema for reading the source files at run time. Databricks released the Delta file format in 2019 which changed how big data engineers inserted, updated, and deleted data within a data lake.
The image below was taken from Mathew Powers’ article on delta lake time travel. It shows how Spark SQL statements (insert, update, and delete) are related to files. In short, a Delta table is composed of parquet files that contain rows of data and JSON files that keep track of transactions (actions). If we execute large transactions, then the number of files that are generated is kept to a minimum. However, many small transactions can cause performance issues due to the large number of files that are created.
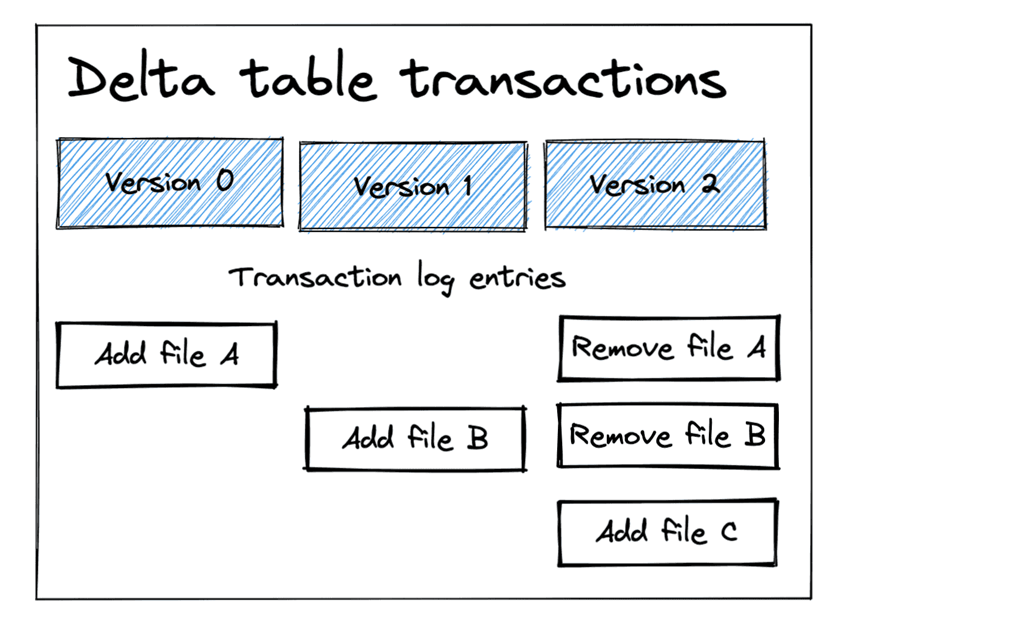
Business Problem
Our manager has asked us to research why small batches can cause performance problems with the Delta file format. Next, the same code will be rewritten to use large batches which will eliminates the performance issue.
Technical Solution
I have used the trial by division algorithm to find the prime numbers from 2 to 5 million. This algorithm is a great way to bench mark a system since it uses both the computation unit as well as the storage system of the cluster. Please see the Wikipedia page for details on algorithms to find prime numbers. But first, we need to understand how the Delta file format works.
Today, we are going to use Microsoft Fabric. However, the code should work on any modern-day Spark system. First, we need to create a lakehouse (database) to contain our schema (table).
Second, we need to create a table to store our results. The Spark SQL code below creates the prime_numbers table. Please note the magic command (%%sql) tells the notebook that the code is Spark SQL instead of Python.
%%sql -- -- prime_numbers - hive table to hold integers -- -- del tbl DROP TABLE IF EXISTS prime_numbers; -- add tbl CREATE TABLE IF NOT EXISTS prime_numbers ( pn_value long, pn_division long, pn_entered timestamp );
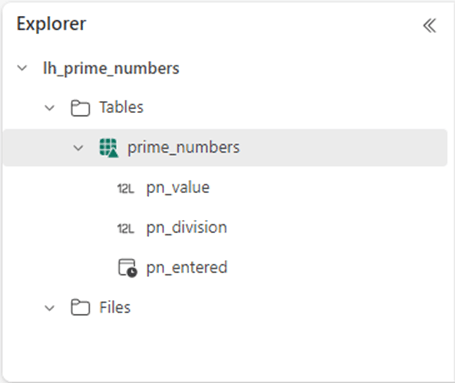
The image below was taken from the lakehouse explorer. It depicts our new table with three fields: pn_value – the prime number, pn_division – how many divisions are performed to determine if the number is prime and pn_entered – the timestamp when the result was entered into the table.
Delta Tables + Spark SQL
Only Delta tables support ACID properties. In this section, we are going to review what happens when we execute data manipulation statements (DML) against a Delta table in Microsoft Fabric.
We want to INSERT the first prime number into our table. Please execute the Spark SQL code now.
%%sql -- -- insert record -- INSERT INTO prime_numbers (pn_value, pn_division, pn_entered) VALUES (2, 1, CURRENT_TIMESTAMP);
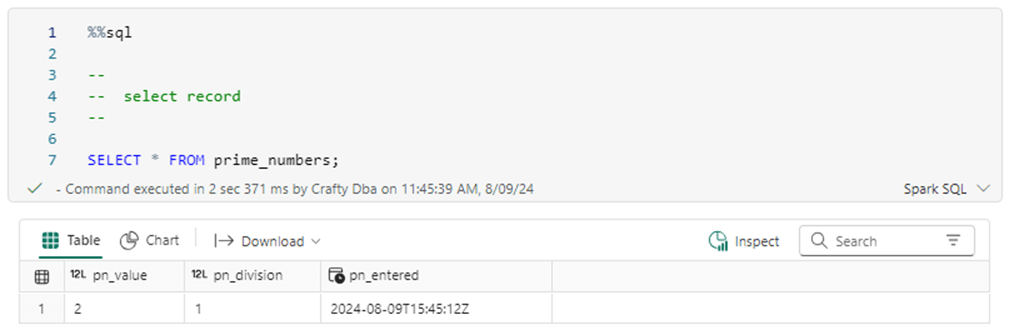
The image below shows the one row of data in the table. We will be using the SELECT statement repeatedly to inspect the contents of the table after an action.
The output from an UPDATE statement displays how many records have been updated. Since there is only one record in the table, the execution results in one row being modified.
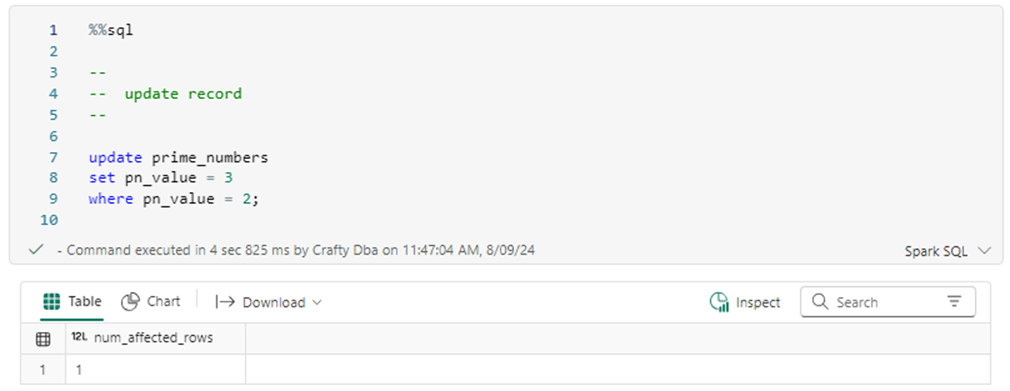
The image below shows the one row of data in the table has been updated from the value of 2 to 3.
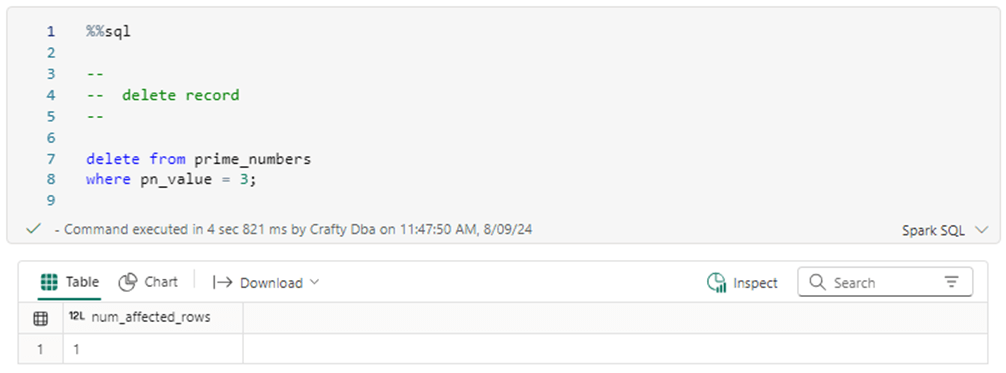
The last DML action to test is the DELETE statement. The output from a DELETE statement displays how many records have been updated. Since there is only one record in the table, the execution results in one row being removed from the table.
If we perform one more SELECT query, we can see the table is empty.
But the real question is “How did the Spark SQL statements translate into the creation of files?”. I am going to focus on the data (parquet) files, but there are corresponding transaction (JSON) files. The describe history statement will give us the actions that were performed on the table. See the image below for details.
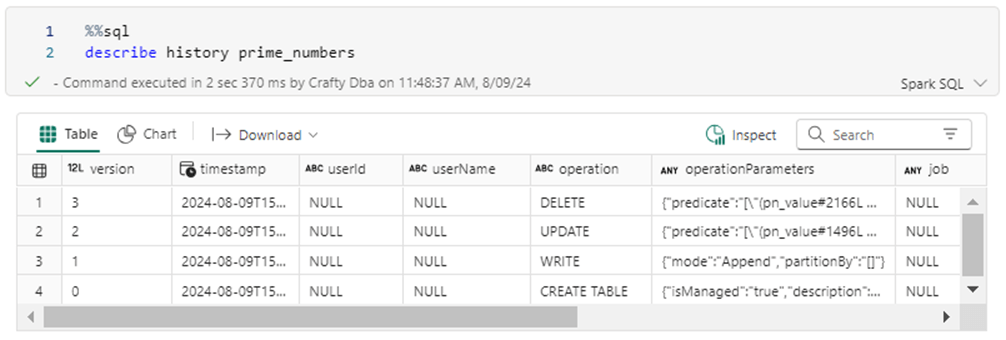
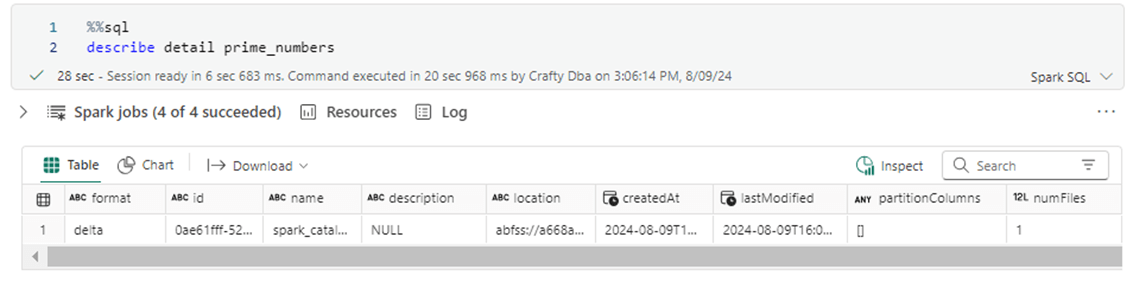
The describe detail statement shows the number of files and their storage location. This is the Azure Data Lake Storage location used by Microsoft Fabric. Copy this location from the cell to Windows Notepad since we will need it for the next bit of code.

We can use the mssparkutils library to list out the files associated with our prime_numbers table. A file was created for each DML action. This is a very important point since writing to storage is slow. The image below shows the 3 parquet files that were created and are part of the Delta Table.
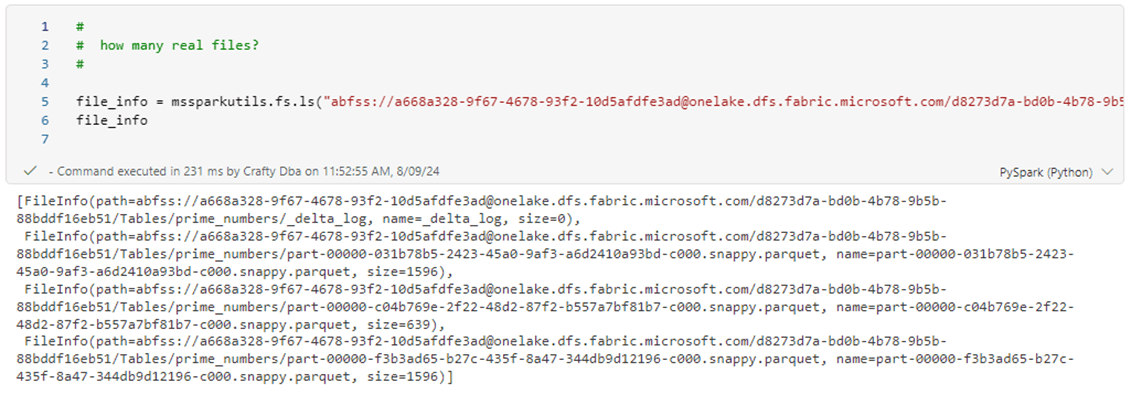
In a nutshell, the Delta file format supports Spark SQL statements by creating parquet and JSON files. You can see by the output of the mssparkutils.fs.ls command that there are 3 parquet files and the _delta_log files which is JSON. Let’s write some Python functions in the next section to determine if a number is prime and search/store prime numbers for a given range.
First Coding Effort
We need to create a function that will determine if a candidate number is prime by division. Prime numbers are only divisible by one and by themselves. The function below returns an array. The first element is a boolean that tells if the number is prime. The second element is the number of divisions used to determine this fact.
#
# is_prime - use brute for division to determine
#
import math
def is_prime(num):
# not a prime number
if (num == 1):
return [0, 1]
# is a prime number
if (num == 2):
return [1, 1]
# set index
idx = 2
# trial division
while idx <= math.sqrt(num):
# zero modulo = not a prime
if ((num % idx) == 0):
return [0, 0]
# increment index
idx = idx + 1
# is a prime number
return [1, idx - 1]
A sample call to the functions shows that the number 19 is prime. We had to divide it by 2, 3, 4, and 5 to determine that fact.

The second Python function we need to write will find the prime numbers from 2 to N and store the results in the Delta table. Dynamic Spark SQL will be created to store each prime number as it is found. This technique works great for a given relational database management system (RDBMS) but will cause performance issues with the Delta table format.
#
# store_primes - save prime numbers, row by row to delta table
#
def store_primes(alpha, omega):
# set index
idx = alpha
# search range (a, o) for primes
while idx <= omega:
# test candidate for prime
ret = is_prime(idx)
# insert into delta table
if (ret[0] == 1):
stmt = f"""
insert into prime_numbers
(
pn_value,
pn_division,
pn_entered
)
values
(
{idx},
{ret[1]},
current_timestamp()
);
"""
df = spark.sql(stmt)
# increment
idx = idx + 1
Our first call to the store_primes function takes 8 seconds to investigate the first 8 numbers. We can see already this solution will not scale!
# # Test for 8 numbers - 8 secs # store_primes(2, 10)
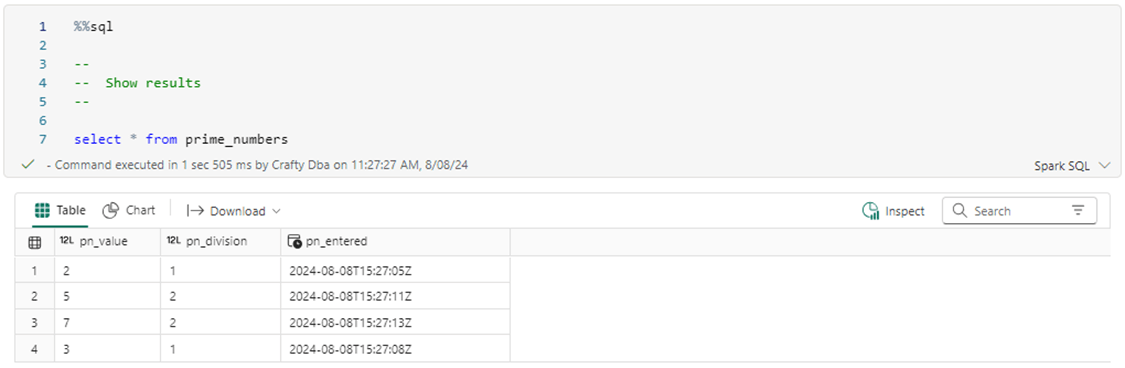
The image below displays the first four prime numbers.
Our second call to the store_primes function calculates the prime numbers from 11 to 2500. The processing time is ten and a half minutes.
# # Test for 2500 numbers - 10 m 24 s # store_primes(11, 2500)
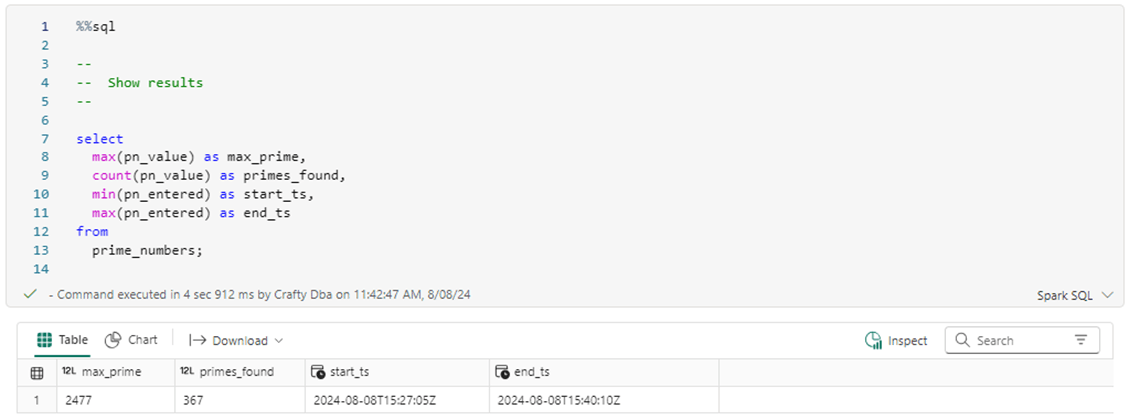
The query below shows some statistics about the prime numbers table. The overall time elapsed between the start and end time are off since I took screen shots of the first call versus the second call.
We can get a directory listing of the Delta table location. This count is always one more than the number of files. That additional directory is used for logging of the transactions.

In this section, we blindly recorded a prime number algorithm that works fine with relational databases since they are geared to handle online transaction processing (OLTP). However, the Delta table format works by creating both parquet and JSON files. Since storage is slow, we were only able to search for primes up to 2,500 in ten minutes instead of the typical 5,000,000 numbers. How can we re-write the algorithm to be more performant?
Second Coding Effort
At this time, please run the first code block of Spark SQL to drop and re-create the prime_numbers table. Instead of writing each prime number to the Delta table as we find it, we will batch up the results into an array of dictionaries. This array will be converted into a Spark Dataframe and merged into the existing table. Let’s talk about the two libraries that we need to import. The datetime library is needed to capture the current time stamp as a string that is compatible with Spark. The delta.tables library is needed to merge the source (results) dataframe into the target (existing lakehouse table).
#
# store_primes2 - calc prime numbers and merge into delta table
#
import datetime
from delta.tables import *
def store_primes2 (alpha, omega):
# set index
idx = alpha
# empty list
lst = []
# search range (a, o) for primes
while idx <= omega:
# test candidate for prime
ret = is_prime(idx)
# append dict to list
if (ret[0] == 1):
ts = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
rw = {"pn_value": idx, "pn_division": ret[1], "pn_entered": ts}
lst.append(rw)
# increment
idx = idx + 1
# convert list to spark df
src = spark.createDataFrame(lst)
# grab path to delta table
path = "Tables/prime_numbers"
path = "abfss://a668a328-9f67-4678-93f2-10d5afdfe3ad@onelake.dfs.fabric.microsoft.com/d8273d7a-bd0b-4b78-9b5b-88bddf16eb51/Tables/prime_numbers"
# merge computed and existing table
trg = DeltaTable.forPath(spark, path)
trg.alias("trg").merge(src.alias("src"), 'trg.pn_value = src.pn_value').whenMatchedUpdateAll().whenNotMatchedInsertAll().execute()
At this time, please run the code block below. I first coded the store_primes2 function to return just a dataframe instead of updating the Delta table. It took less than 1 second to find the prime numbers. However, adding the merge of the results into the Delta table took a total of 24 seconds.
# # Test for 2500 numbers - < 1 sec runtime, 24 upsert time # store_primes2(2, 2500)
We can see that the last 5 prime numbers took 49 trial divisions to figure out their uniqueness.
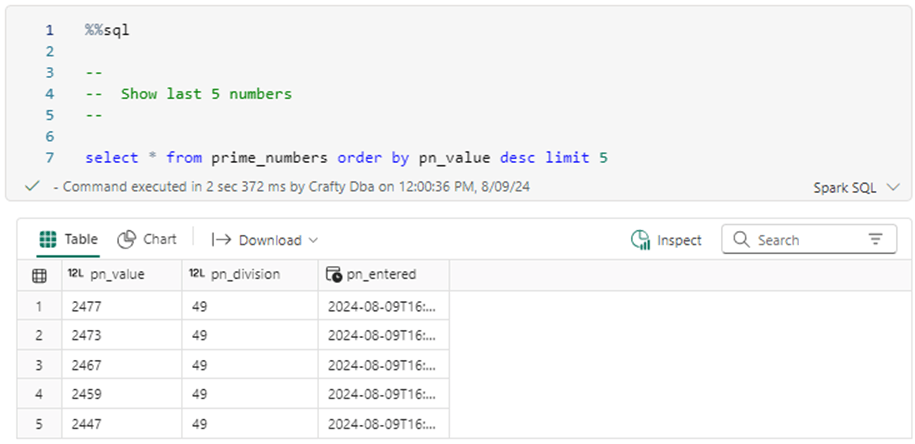
We can see that a total of 367 prime numbers were found within the first 2500 numbers.
The main difference between the first and second program is the total number of parquet files. We can see we only have 1 file created instead of 367 files.
Summary
Today, we learnt that the Delta table is composed of parquet (data files) and transaction files (JSON files). Because writing to Azure Data Lake Storage is expensive, we want to reduce the number of files that are created by our Spark Notebooks. The first program we wrote used a Spark SQL insert statement which resulted in a very large execution time. The second program we wrote used a Spark Dataframe to capture the results of our data processing and wrote one batch of data to the Delta file. The execution times were night and day for the two algorithms.
Many new data engineers think that Delta tables are awesome. I also think they are awesome given the right use case. For instance, we might want to write a metadata driven ingestion framework to get data from on premise SQL Server to a data lake. We might decide to log each notebook action to a Delta table. This would not be a good design due to the overhead. A better design would be to keep track of the execution log in a dictionary and write the complete log either on failure or success.
Next time, I am going to talk about the concurrency update problem that you might encounter with Delta tables. Today, we decided to drop and rebuild the Delta table after the first test. However, in production systems we might need to reduce the file fragmentation by calling the optimize and vacuum statements. There is an impact to time travel when a vacuum is performed. This might be fine if you do not need to go “back to the future”.