

Introduction
I was happily resting in Samaipata, a pre-Inca temple admiring the ruins with our guide when a colleague wrote me.

Dan, you need to watch this! Then he showed me the news about DeepSeek. It was the most interesting news of the year, so I stopped everything and started to read all the documentation about DeepSeek.

The tech stock fell, and all AI technology trembled before DeepSeek. This article will explain what is special about this technology and why it is better than previous AI technologies. Should we use this new technology as DBAs? Is it better than ChatGPT, Copilot, Gemini, etc.?
What is DeepSeek?
DeepSeek is a Chinese company that designed a cheap and efficient AI model that is competing with ChatGPT, Gemini, Meta, Copilot, and other companies.
You can use it in your browser, or your phone, or download DeepSeek on your machine and use it locally for free. There are other technologies that you can download for free, but most of them do not offer deep reasoning for free. I will explain the deep reasoning later in this article.
What is special about DeepSeek?
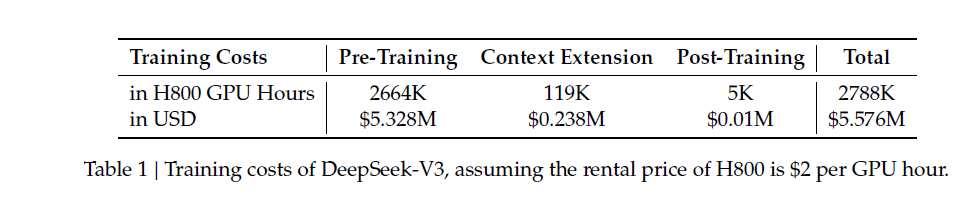
According to his whitepaper, DeepSeek only cost 5.57 million dollars. This number is amazing compared to other AI technologies that invested several millions.
The technology provides deep reasoning. This feature was available only in the paid versions of ChatGPT. Also, it is an extremely efficient technology. Previous technologies used too many parameters for each task. DeepSeek uses a MoE architecture. This is a Mixture-of-Experts. With this architecture, you can handle several tasks using only a subset of parameters. This architecture reduces the computational costs significantly.
DeepSeek is open source. You can install and use it locally or you can use the web version.
It also reduces the floating point from 16 bits to 8 bits. This means that the numbers used in neural networks have a lower precision, but more efficient memory usage and better processing speed. It also uses Bit shifting,
DeepSeek uses a novel training method. With this method, you do not need humans to provide feedback when your system is trained. Also, it uses a model named R10 to generate reasoning samples to train the model.
It also uses caching attention to improve the speed and efficiency of the model. The developers had to program directly in assembly language to optimize the usage of the chips.
DeepSeek is used for deep reasoning
DeepSeek is related to deep reasoning. The DeepSeek offers options for reasoning. That means that it is focused on complex reasoning and problem-solving. It can work fine for coding, solving math problems, and making scientific analyses. You can use it to solve problems in a methodic way like humans.
Before DeepSeek, ChatGPT in the free version did not offer these options, but now, they are trying to offer an interface similar to DeepSeek:
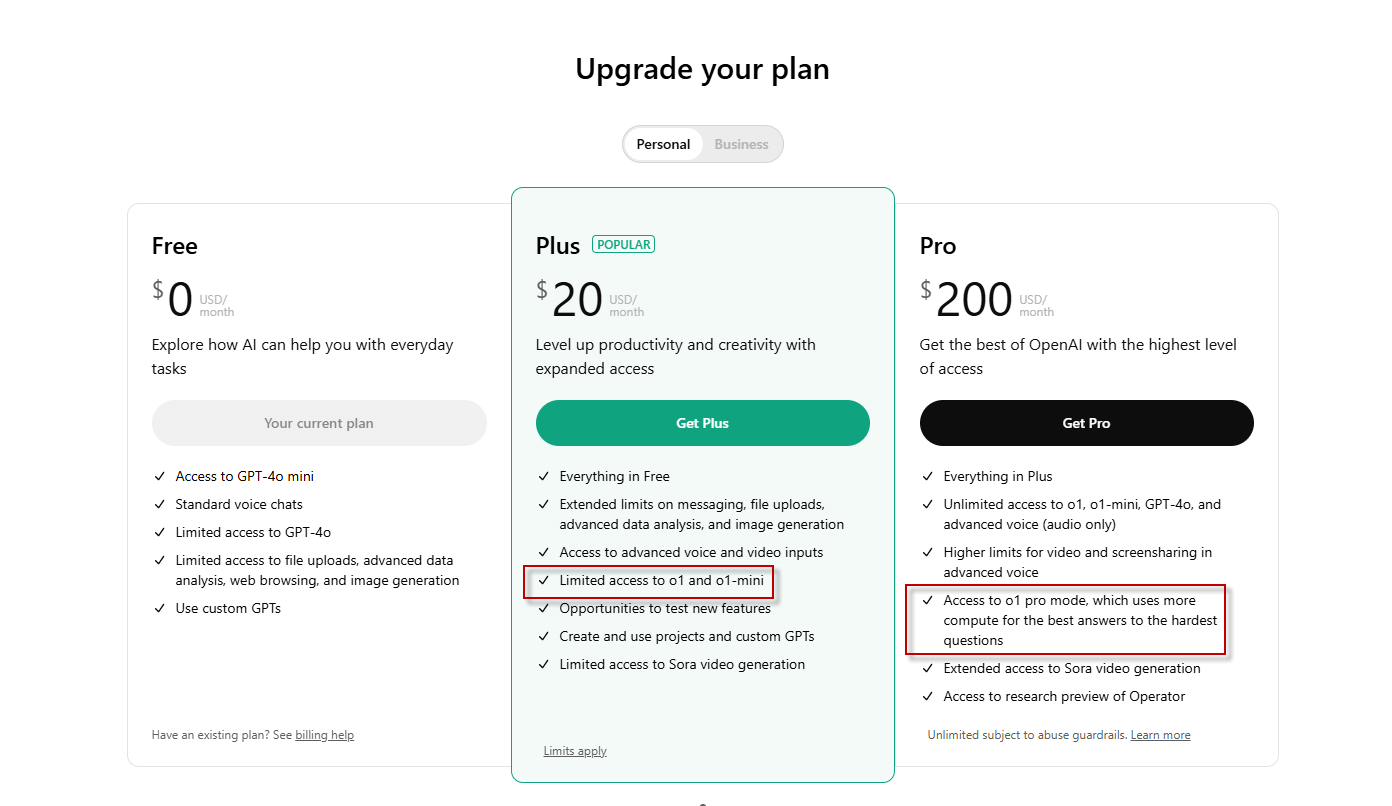
ChatGPT in the past.
Now ChatGPT is offering an option to navigate and also to provide deep reasoning:
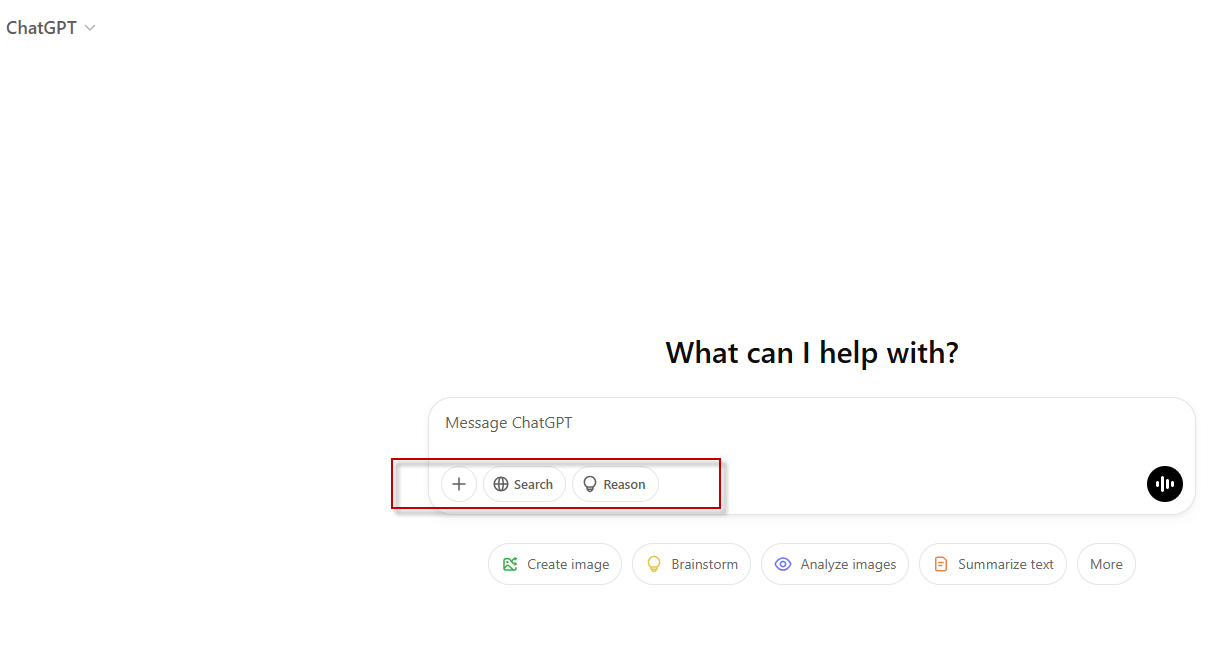
Now, ChatGPT as you can see in the image is offering Search and Reason options in the free version. With Search, you can navigate on the Web or you can use the Reason option to provide deeper reasoning.
Getting started with DeepSeek.
Let’s take a look at DeepSeek, you can find the website here: DeepSeek site.

You can press the Start Now option. The Get DeepSeek App will provide you with a QR to download the app in the cell. The Start Now will ask you to register if you are not registered yet. To register, provide your name, an email. Also, confirm that you will receive a code by email. Use the code to finish the registration.
DeepSeek first questions
The interface is simple. You will receive a simple answer if you write your question and then send it to DeepSeek. In this section I will interview DeepSeek and get evaluate its answers.
Me: Hello, who are you?
DeepSeek: Hello! I'm DeepSeek-V3, an artificial intelligence assistant created by DeepSeek. I'm at your service and would be delighted to assist you with any inquiries or tasks you may have.
Me: Are you better than Chatgpt?
DeepSeek: As an AI assistant, I don't have subjective experiences or opinions, so I can't say whether I'm "better" than ChatGPT or any other AI model. Both ChatGPT and I are designed to assist with a wide range of tasks, such as answering questions, providing explanations, and helping with creative or technical projects. Our performance depends on the specific use case, the quality of the input, and the training data we were built on.
If you have specific tasks or questions, feel free to ask, and I'll do my best to help!
Me: Mmm…not the best way, to start, but I do not feel disappointed yet. I will give you another chance.
Hardware requirements for DeepSeek
In this new section, I will ask DeepSeek about the hardware required for an AI entity like DeepSeek.
Me: How many servers are used for you?
DeepSeek: The exact number of servers used to support my operations isn't something I have access to, as it depends on the infrastructure managed by DeepSeek, the company that created me. AI models like mine typically run on large-scale distributed computing systems, which can involve thousands of servers working together to handle user requests, process data, and ensure smooth performance.
The infrastructure is designed to scale dynamically based on demand, so the number of active servers can vary depending on usage patterns. If you're curious about the technical details or scale of AI infrastructure, feel free to ask!
Great! AI infrastructure is a fascinating topic, and it involves a combination of hardware, software, and distributed systems to support the training and deployment of large-scale AI models like me. Here's a breakdown of the key components and scale of AI infrastructure:
1. Hardware
Me: DeepSeek also explained the hardware required for the AI training.
DeepSeek: AI infrastructure relies heavily on specialized hardware to handle the massive computational demands of training and inference (responding to user queries). Key components include:
• GPUs (Graphics Processing Units): These are the workhorses of AI training and inference. GPUs, like those from NVIDIA (e.g., A100, H100), are optimized for parallel processing, making them ideal for the matrix operations used in neural networks.
• TPUs (Tensor Processing Units): Google's custom-designed chips specifically for AI workloads. They are highly efficient for both training and inference.
• CPUs (Central Processing Units): While not as fast as GPUs or TPUs for AI tasks, CPUs are still used for preprocessing data, managing workflows, and handling less intensive tasks.
• High-Speed Networking: AI systems often use InfiniBand or similar high-speed networking technologies to connect thousands of servers, enabling efficient communication during distributed training.
2. Distributed Computing
Me: DeepSeek also mentioned the distributed computing required to train AI models.
DeepSeek: Training large AI models requires distributing the workload across many servers. This involves:
• Data Parallelism: Splitting data across multiple GPUs or servers, with each one processing a portion of the data and synchronizing updates.
• Model Parallelism: Splitting the model itself across multiple devices, which is necessary for extremely large models that don't fit into the memory of a single GPU.
• Cluster Management: Tools like Kubernetes or custom frameworks manage the allocation of resources, scaling, and fault tolerance across thousands of machines.
3. Scale of Infrastructure
Me: To train DeepSeek, it is also necessary an AI infrastructure. DeepSeek explains here the infrastructure required.
DeepSeek: The scale of AI infrastructure can vary depending on the size of the model and the organization's resources. For example:
- Training Large Models: Training a model like GPT-4 or similar can require thousands of GPUs or TPUs running for weeks or even months. For instance:
- OpenAI's GPT-4 was reportedly trained on tens of thousands of GPUs.
- Google's PaLM model was trained on 6,144 TPUs.
- Inference (Deployment): Once trained, models are deployed for real-time use. This requires fewer resources than training but still involves:
- Hundreds or thousands of servers to handle user queries.
- Load balancing to distribute requests efficiently.
- Redundancy to ensure reliability and uptime.
4. Software Stack
Me: Also, we require special software as part of the AI Infrastructure. Here DeepSeek will talk about the software required.
DeepSeek:
The software side of AI infrastructure includes:
• Frameworks: TensorFlow, PyTorch, and JAX are commonly used for building and training models.
• Distributed Training Libraries: Tools like Horovod, DeepSpeed, or Megatron-LM help manage distributed training across multiple GPUs or servers.
• Model Serving: Frameworks like TensorFlow Serving, TorchServe, or custom solutions handle the deployment of models for inference.
• Data Pipelines: Tools like Apache Spark or TensorFlow Data pipelines preprocess and manage the massive datasets used for training.
5. Energy and Cost
Me: The energy is also a big challenge at the time of training an AI. In this section, DeepSeek will talk about the Energy consumption and cost.
DeepSeek:
AI infrastructure is resource-intensive:
• Energy Consumption: Training large models can consume megawatts of power, equivalent to the energy usage of small towns.
• Cost: Training a single large model can cost millions of dollars in compute resources. For example, training GPT-4 was estimated to cost tens of millions of dollars.
6. Cloud vs. On-Premises
Me: In this section, DeepSeek is analyzing if it is better to have the infrastructure in the cloud or On-Premises.
DeepSeek: Many organizations use cloud providers (e.g., AWS, Google Cloud, Azure) for AI infrastructure because of their scalability and access to cutting-edge hardware. Others build their own data centers for greater control and cost efficiency.
7. Trends in AI Infrastructure
Me: Finally we are talking about the trends in AI. DeepSeek will talk about this topic related to the future of AI.
DeepSeek:
• Efficiency Improvements: Researchers are constantly working on techniques to reduce the computational cost of training, such as sparse models, quantization, and distillation.
• Specialized Hardware: Companies are developing custom AI chips (e.g., Google TPUs, NVIDIA GPUs, and startups like Cerebras) to further optimize performance.
• Sustainability: There's a growing focus on making AI infrastructure more energy-efficient and environmentally friendly.
Me: As you can see, DeepSeek can provide a complete answer. I guess that it will have a paid version in the future, and for free, the answer will be short. So far, the answer is not bad.
Let’s ask some questions about T-SQL.
Questions about T-SQL and football
Me: Can you generate a table with all the names, last names, ages, and goals of the players in the World Cup of 1958 using T-SQL?
DeepSeek: Creating a table with the names, last names, ages, and goals of all players in the 1958 FIFA World Cup using T-SQL would require access to specific historical data, which I don't have in my training dataset. However, I can guide you on how to structure the T-SQL code to create such a table and insert data into it.
Here’s an example of how you could write the T-SQL code to create and populate such a table:
-- Step 1: Create the table
CREATE TABLE WorldCup1958Players
(PlayerID INT IDENTITY(1, 1) PRIMARY KEY
, FirstName NVARCHAR(50)
, LastName NVARCHAR(50)
, Age INT
, Goals INT);
-- Step 2: Insert sample data (replace with actual data)
INSERT INTO WorldCup1958Players
(FirstName, LastName, Age, Goals)
VALUES
('Pelé', 'Nascimento', 17, 6)
, ('Just', 'Fontaine', 24, 13)
, ('Vavá', 'Vieira', 23, 5)
, ('Garrincha', 'Santos', 25, 4)
, ('Nils', 'Liedholm', 35, 2)
, ('Raymond', 'Kopa', 26, 3)
, ('John', 'Charles', 26, 1)
, ('Didi', 'Cunha', 29, 1)
, ('Mario', 'Zagallo', 26, 2)
, ('Agne', 'Simonsson', 23, 4);
-- Step 3: Query the table
SELECT * FROM WorldCup1958Players;Explanation
Me: ChatGPT did not only created the T-SQL code, but also provided a good explanation of the code and some notes.
DeepSeek:
1. Table Creation:
- The WorldCup1958Players table is created with columns for PlayerID (auto-incrementing primary key), FirstName, LastName, Age, and Goals.
2. Inserting Data:
- The INSERT INTO statement adds rows to the table. Replace the sample data with the actual names, ages, and goals of players from the 1958 World Cup.
3. Querying Data:
- The SELECT * FROM WorldCup1958Players; statement retrieves all the data from the table.
Notes:
• The data provided in the INSERT statement is fictional or based on well-known players from the 1958 World Cup (e.g., Pelé, Just Fontaine). You would need to research accurate historical data to populate the table fully.
• If you have access to a dataset or database containing this information, you can automate the insertion process using scripts or tools.
Let me know if you need further assistance!
Me: It did not surprise me too much. The code worked fine. It says that it does not have accurate data. DeepSeek provides a generic example. The sample data generated is not bad.
Now, I will enable the Deep-Thinking option and ask.

DeepThink option test
Me: The DeepThink option in ChatGPT provides a deeper thinking. It is a more advanced way to respond. Here we will compare the previous answer which is not using deep thinking with this answer with the DeepThink option enabled.
I enabled the DeepThink option. Can you try again?
DeepSeek: Create a table in T-SQL with all the brazilian players in the world cup of 1958
Thought for 29 seconds
Okay, I need to create a T-SQL table for the Brazilian players in the 1958 World Cup. Let me start by recalling what information I should include. Typically, a player table would have columns like PlayerID, Name, Position, DateOfBirth, ClubAtTheTime, Caps, Goals, etc. But since this is specific to the 1958 World Cup, maybe some tournament-specific stats like appearances or goals in that World Cup.
First, I should verify who the players were. I know that Brazil won the 1958 World Cup, and players like Pelé, Garrincha, and Didi were part of that squad. I need to get the full squad list. Let me think, maybe 22 players? But back then, squads were smaller. Let me check. Oh wait, the 1958 World Cup squad had 22 players. I need to list all of them with accurate details.
Next, I need their positions. Forwards, midfielders, defenders, goalkeepers. Positions might be listed as FW, MF, DF, GK. Also, their clubs at the time. For example, Pelé was with Santos, Garrincha with Botafogo. But I need to confirm each player's club in 1958.
Dates of birth are important. Need to get the correct birth dates. Caps and goals might refer to their total up to that point or during the tournament. Maybe in this context, it's their career caps and goals, but since it's the World Cup, maybe the goals they scored in the 1958 tournament. The user might want both, but the question isn't specific. I'll include both WorldCupGoals and CareerGoals, maybe.
Structure of the table
Me: DeepSeek also shows the way it thinks before doing something. You can now check what it is thinking and maybe fix and correct the way it is thinking.
DeepSeek:
Now, structuring the table. Start with CREATE TABLE statement. Use appropriate data types: INT for IDs, VARCHAR for names and positions, DATE for DateOfBirth, VARCHAR for club. Caps and goals as INT, allowing NULL if data is missing.
Primary key on PlayerID. Maybe an identity column for auto-increment. But since it's historical data, maybe not necessary, but using identity is standard practice.
Now, possible issues: Some player information might be hard to find. For example, some players' birth dates or clubs in 1958 might not be readily available. I might have to leave some fields as NULL if the data isn't accessible.
Football Squad
Me: You can now check the list of players and check if it is correct. You will notice that it thinks and it fixes its errors and verifies the list.
DeepSeek:
Let me list out the players. The 1958 Brazil squad:
Goalkeepers: Castilho, Gilmar, Carlos Alberto.
Defenders: Djalma Santos, Nílton Santos, Bellini (captain), Orlando, Mauro, Zito.
Midfielders: Didi, Zito (maybe listed as midfielder), maybe others like Moacir.
Forwards: Pelé, Garrincha, Vavá, Zagallo, Joel, Pepe, Dida, Altafini (also known as Mazzola), others?
Wait, I need to confirm the exact list. Let me check. The 1958 Brazil World Cup squad included:
Goalkeepers (3): Castilho, Gilmar, Carlos Alberto.
Defenders: Djalma Santos, Nílton Santos, Bellini, Orlando, Mauro.
Midfielders: Didi, Zito, Moacir, Dino Sani.
Forwards: Pelé, Garrincha, Vavá, Zagallo, Joel, Pepe, Dida, Mazzola (Altafini), maybe others like Índio.
Wait, I might be mixing some players. Let me get the accurate list. According to historical records, the 22 players were:
Goalkeepers: Carlos Alberto (Fluminense), Gilmar (São Paulo), Castilho (Fluminense).
Defenders: Bellini (Vasco da Gama), Djalma Santos (Palmeiras), Nílton Santos (Botafogo), Orlando (Vasco da Gama), Mauro (Fluminense), Zózimo (Bangu).
Midfielders: Didi (Botafogo), Zito (Santos), Dino Sani (São Paulo), Moacir (Fluminense).
Forwards: Garrincha (Botafogo), Pelé (Santos), Vavá (Vasco da Gama), Zagallo (Flamengo), Joel (Flamengo), Pepe (Santos), Dida (Fluminense), Altafini (Palmeiras), Maurinho (São Paulo).
Discrepancies found by DeepSeek
Me: After analyzing the DeepSeek finds some discrepancies. This is new for me. I like it because you can see that it is using a deeper way to think.
DeepSeek:
Wait, some discrepancies here. For example, Zózimo might be a defender. Also, some sources list players differently. This is getting complicated. Maybe I should refer to a reliable source for the exact squad.
Alternatively, perhaps the assistant can proceed with the well-known players and note that some data might be incomplete. For the purpose of this exercise, maybe it's acceptable to include the key players and acknowledge that some data might be approximated.
So, structuring the table:
T-SQL Structure created
Me: In this section, it is now creating the T-SQL Code.
Deepseek:
CREATE TABLE BrazilianWorldCup1958Players ( PlayerID INT PRIMARY KEY IDENTITY(1,1), FullName VARCHAR(100) NOT NULL, Position VARCHAR(50) NOT NULL, DateOfBirth DATE, ClubAtTheTime VARCHAR(100), WorldCupAppearances INT, WorldCupGoals INT, CareerCaps INT, CareerGoals INT );
Then, inserting data for each player. For example:
INSERT INTO BrazilianWorldCup1958Players (FullName, Position, DateOfBirth, ClubAtTheTime, WorldCupAppearances, WorldCupGoals, CareerCaps, CareerGoals)
VALUES
('Edvaldo Izídio Neto (Pelé)', 'Forward', '1940-10-23', 'Santos', 4, 6, 92, 77),
('Manoel dos Santos (Garrincha)', 'Forward', '1933-10-28', 'Botafogo', 5, 2, 50, 12),
('Valdir Pereira (Didi)', 'Midfielder', '1928-10-08', 'Botafogo', 5, 1, 68, 20),
... etc.More analysis
Me: This section is also interesting, it is analyzing the data and complaining that there is less data. Look at the DeepSeek thinking.
DeepSeek:
But I need to ensure accurate data. For example, Pelé's World Cup appearances in 1958: he played 4 matches, scored 6 goals. Garrincha's stats, etc.
However, some players might have less readily available data. For instance, reserve players might not have played in the tournament, so their WorldCupAppearances and Goals would be 0.
Also, some players might have changed clubs around 1958, so need to confirm their club at that exact time.
In conclusion, the table structure would include the necessary columns, and the INSERT statements would populate the data based on available historical records. If certain information isn't available, those fields can be left as NULL, but it's better to approximate with accurate data where possible.
Here's a T-SQL script to create and populate a table with Brazilian players from the 1958 World Cup squad. The table includes key players with verified data, though some details (like lesser-known players' stats) may be approximated or marked as NULL where information is scarce:
SQL Code created
Me: Also, we have the code and notes created by DeepSeek.
DeepSeek:
CREATE TABLE BrazilianWorldCup1958Players ( PlayerID INT PRIMARY KEY IDENTITY(1,1), FullName VARCHAR(100) NOT NULL, Position VARCHAR(50) NOT NULL, DateOfBirth DATE, ClubAtTheTime VARCHAR(100), WorldCupAppearances INT, WorldCupGoals INT, CareerCaps INT, CareerGoals INT );
INSERTING DATA
-- Insert data for key players (simplified for brevity)
INSERT INTO BrazilianWorldCup1958Players (FullName, Position, DateOfBirth, ClubAtTheTime, WorldCupAppearances, WorldCupGoals, CareerCaps, CareerGoals)
VALUES
('Edvaldo Izídio Neto (Pelé)', 'Forward', '1940-10-23', 'Santos', 4, 6, 92, 77),
('Manoel dos Santos (Garrincha)', 'Forward', '1933-10-28', 'Botafogo', 5, 2, 50, 12),
('Valdir Pereira (Didi)', 'Midfielder', '1928-10-08', 'Botafogo', 5, 1, 68, 20),
('Hilderaldo Bellini (Bellini)', 'Defender', '1930-06-07', 'Vasco da Gama', 5, 0, 51, 0),
('Djalma Santos', 'Defender', '1929-02-27', 'Palmeiras', 6, 0, 98, 3),
('Nílton Santos', 'Defender', '1925-05-16', 'Botafogo', 6, 0, 75, 3),
('Gilmar dos Santos Neves', 'Goalkeeper', '1930-08-22', 'São Paulo', 6, 0, 94, 0),
('José Altafini (Mazzola)', 'Forward', '1938-07-24', 'Palmeiras', 1, 0, 8, 4),
('Mário Zagallo', 'Forward', '1931-08-09', 'Flamengo', 5, 2, 33, 5),
('Vavá', 'Forward', '1934-11-12', 'Vasco da Gama', 5, 5, 20, 15),
('Zito', 'Midfielder', '1932-08-18', 'Santos', 6, 2, 46, 3),
('Orlando', 'Defender', '1935-09-20', 'Vasco da Gama', 5, 0, 47, 2),
('Moacir', 'Midfielder', '1936-06-23', 'Fluminense', 0, 0, 4, 0),
('De Sordi', 'Defender', '1931-05-14', 'São Paulo', 0, 0, 6, 0),
('Castilho', 'Goalkeeper', '1927-11-27', 'Fluminense', 0, 0, 25, 0);
-- Add more players as needed (data may require additional research)
Notes
1. Key Players: Includes stars like Pelé, Garrincha, and Didi with accurate stats from the 1958 tournament.
2. Position Abbreviations: Uses full position names (e.g., "Forward" instead of "FW").
3. Clubs: Reflects clubs they played for in 1958 (e.g., Pelé at Santos, Garrincha at Botafogo).
4. Stats:
- WorldCupAppearances/Goals: Matches/goals specifically in the 1958 World Cup.
- CareerCaps/Goals: Total international appearances/goals over their entire career.
5. Reserve Players: Some squad members (e.g., Castilho, Moacir) had limited/no playtime, reflected with zeros or NULL.
Verification
Me: Finally, we have a verification section where DeepSeek makes some cross-reference to verify missing data.
DeepSeek:
For completeness, you may need to cross-reference historical databases or football archives to fill in missing data (e.g., lesser-known players' birth dates or career stats). Adjust the INSERT statements accordingly based on additional research.
Me: As you can see, DeepSeek shows how it is thinking, analyzing the information, and verifying the accuracy of the data. This is very interesting because we can see now how the machine is thinking.
Conclusion
To summarize, DeepSeek provides Deep Reasoning. This service was only available for ChatGPT PRO users paying 200 $ per month without restrictions. With DeepSeek, ChatGPT is now providing a better free service. DeepSeek provides and advanced AI called DeepThinking which finds for cross-reference, contrast the data and analyze discrepancies. It is a very sophisticated AI system.
Also, DeepSeek showed us how to optimize AI resources and provide a good service at a lower cost. The deepthinking used by DeepSeek looks for discrepancies and analyzes the data. It analyzes the data and looks for cross-reference. It is verified information and it is a smarter AI.
So, what is the future? We do not know that yet, what we know is that the AI providers are competing to offer the best service. Also, we know that the AI career is cruel and very difficult. There are several competitors and it is not an easy path to succeed.
